ziggurat29
ziggurat29-
Truth In Numbers
06/20/2018 at 17:07 • 0 commentsJun-16 12:09 PM
With the two new mechanisms available, it was time to test. Since the motivation for the activity was to get a feel for the improvements, I decided to test a little differently. This time I did not use the profiler, but rather added a simple stopwatch around the execution of the program. The test program was intended to be run forever, so I altered it to run for just 10 generations and then exit. Since I was running this on Windows, I used the QueryPerformanceCounter() api to make my stopwatch:
int main(int argc, char* argv[]) { LARGE_INTEGER liFreq; //... so chic LARGE_INTEGER liCtrStart, liCtrEnd; QueryPerformanceFrequency ( &liFreq ); QueryPerformanceCounter ( &liCtrStart ); //setup to execute program. ubasic_init ( _achProgram, false ); //run the program until error 'thrown' do { if ( !setjmp ( jbuf ) ) ubasic_run(); else { printf ( "\nBASIC error\n" ); break; } } while ( ! ubasic_finished() ); QueryPerformanceCounter ( &liCtrEnd ); double dur = (double)(liCtrEnd.QuadPart - liCtrStart.QuadPart) / (double)liFreq.QuadPart; printf ( "duration: %f sec\n", dur ); return 0; }This should give the 'bottom line' numbers on how these two improvements worked out. Plus I wanted to visually see it!
Also, I wanted to subtract off the contribution of screen I/O. Screen I/O on Windows console is quite slow, and having that contribute to the numbers would be meaningless for the target platform, since it has a completely different I/O system (SPI LCD? I don't know). This was easy, fortunately, since the I/O from the BASIC is character oriented -- I simply put a conditional compile around the actual output routines:
//this lets us suppress screen output, which skews timing numbers //towards console IO away from our program's computation time //#define NO_OUTPUT 1 //write null-terminated string to standard output uint8_t stdio_write ( int8_t * data ) { #if NO_OUTPUT return 0; #else return (uint8_t) puts ( (const char*)data ); #endif } //write one character to standard output uint8_t stdio_c ( uint8_t data ) { #if NO_OUTPUT return data; #else return (uint8_t)_putch ( data ); #endif }Testing time! I created 4 test scenarios:
- no modifications (other than what was required to run on the desktop)
- improved tokenizer only
- improved goto logic only
- improved tokenizer and goto logic
I also created two flavors: suppressed screen output, and included screen output.
I ran each configuration a few times and used the 'best of three' timing for each. I used 'best of three' because wall-clock timing this way can be affected by all sorts of other stuff coincidentally going on in the operating system at the time, so I wanted to have a little insulation from that.
With screen output suppressed:
- baseline implementation
duration: 5.244856 sec
relative speed: 1 - improved tokenizer
duration: 0.450086 sec
relative speed: 11.653 - improved goto logic
duration: 1.494159 sec
relative speed: 3.510239 - both improved tokenizer and goto logic
duration: 0.130637 sec
relative speed: 40.14831
And to observe how much the screen I/O contributes to runtime in my test program:
- baseline implementation
duration: 7.029072 sec
relative speed: 1 - improved tokenizer
duration: 1.969379 sec
relative speed: 3.569181 - improved goto logic
duration: 3.020004 sec
relative speed: 2.327504 - both improved tokenizer and goto logic
duration: 1.592177 sec
relative speed: 4.414755
So there is was! It turned out my intuition about improving the tokenizer did indeed yield the biggest improvement, and my later intuition that focusing on improving the goto logic instead was wrong. But both improvements are worthwhile, and if you use them together, even in this simple way, you can expect a 40x improvement in program speed. 40x. I'll take it!
Also, running with the screen I/O in, you can see that it is indeed rather slow, and swamps out a lot of the BASIC improvement gains. In this case, the screen I/O incurred about a 1.4 sec fixed cost to the total execution time. These particular numbers don't mean much for the target platform, but it's probably worth keeping in mind.
I wrote up the final results and sent it off to [my correspondent on the project]. It was suggested that I write up the process in this project form, that someone might find it interesting, hence this blog.
Project complete!
-
Line Number Cache
06/20/2018 at 16:53 • 0 commentsJun-16 12:09 PM
As mentioned before, the core 'goto' implementation is in jump_linenum(), and works by restarting parsing of the entire program until the desired line if found. Here is a compacted form:
static void jump_linenum(int linenum) { tokenizer_init(program_ptr); while(tokenizer_num() != linenum) { do { //... eat tokens; emit an error if we reach end-of-stream } while(tokenizer_token() != TOKENIZER_NUMBER); } }I was not wanting to do a major re-engineering of the ubasic, so I decided to keep the rest of the system as-is, and only rework this method.
The strategy I used here was to make a 'cache' of line-number-to-program-text-offset mappings. Then, when this function is invoked, the cache is consulted to find the offset into the program, and set the parser up there. Because tokenizer_init() is a cheap call, I used it to do the setting up of the parser by simply pretending that the program starts at the target line we found, rather than try to fiddle with the internals of the parser state. A hack, but a convenient one, and ultimately this exercise was to prove the concept that improving jump_linenum() would have a material impact, and how much.
For simplicity, my 'cache' was simply an array of structs, and my 'lookup' was simply a linear search. Also, I simply allocated a fixed block of structs. In a production system, this could be improved in all sorts of ways, of course, but here I just wanted to see if it was a worthwhile approach.
The struct I used was simple, and there was added a 'setup' method that was called during program initialization time to populate the cache:
//HHH a line number lookup cache; this is just proof-of-concept junk typedef struct { uint16_t _nLineno; //the line number uint16_t _nIdx; //offset into program text } LNLC_ENT; LNLC_ENT g_nLines[1000]; //mm-mm-mm. just takin' memory like it's free, and limiting the program to 1000 lines int g_nLineCount = -1; #define COUNTOF(arr) (sizeof(arr)/sizeof((arr)[0])) void __setupGotoCache(void) { tokenizer_init(program_ptr); g_nLineCount = 0; //the beginning is a very delicate time while ( tokenizer_token () != TOKENIZER_ENDOFINPUT ) { int nLineNo; const char* pTok; const char* __getAt (void); //(added to tokenizer.c) //we must be on a line number if ( tokenizer_token () != TOKENIZER_NUMBER ) { g_nLineCount = -1; //purge 'goto' cache sprintf ( err_msg, "Unspeakable horror\n" ); stdio_write ( err_msg ); tokenizer_error_print (); longjmp ( jbuf, 1 ); } //remember where we are nLineNo = tokenizer_num (); pTok = __getAt (); //create an entry g_nLines[g_nLineCount]._nLineno = nLineNo; g_nLines[g_nLineCount]._nIdx = pTok - program_ptr; //whizz on past this line while ( tokenizer_token () != TOKENIZER_ENDOFINPUT && tokenizer_token () != TOKENIZER_CR ) { tokenizer_next (); } if ( TOKENIZER_CR == tokenizer_token () ) { tokenizer_next (); } //next entry ++g_nLineCount; //too many lines? if ( g_nLineCount >= COUNTOF ( g_nLines ) ) { g_nLineCount = -1; //purge 'goto' cache sprintf ( err_msg, "Program too long to cache!\n" ); stdio_write ( err_msg ); tokenizer_error_print (); longjmp ( jbuf, 1 ); } } //did we get anything? if not, purge 'goto' cache if ( 0 == g_nLineCount ) //pretty boring program! g_nLineCount = -1; //purge 'goto' cache //be kind, rewind tokenizer_init ( program_ptr ); }So, we simply whizz through the program, tossing away tokens (much like the original jump_linenumber() implementation), and take note of the text offset when we reach a start-of-line. But... we do this only once, instead of every time there is a transfer-of-control.
The jump_linenumber() implementation was altered thusly:
/*static*/ void jump_linenum(int linenum) { //alternative implementation uses line number lookup cache int nIdx; for ( nIdx = 0; nIdx < g_nLineCount; ++nIdx ) { //binary compare is better than if ( g_nLines[nIdx]._nLineno == linenum ) { //our hacky 'goto' implementation is to re-init the tokenizer //at the start of the line we found. This works, and saves a //lot of haquery in the tokenizer module to reposition within //the existing program image. tokenizer_init ( &program_ptr[g_nLines[nIdx]._nIdx] ); break; } } if ( nIdx == g_nLineCount) { sprintf(err_msg,"Unreachable line %d called from %d\n",linenum,last_linenum); stdio_write(err_msg); tokenizer_error_print(); longjmp(jbuf,1); // jumps back to where setjmp was called - making setjmp now return 1 } }Ta-da!
So, obviously there are numerous improvements that can/should be made. Some that come to mind are:- the fixed allocation of the lookup structure is probably sub-optimal. I arbitrarily chose 1000 entries, which is wasteful and limiting. Some memory management is probably worthwhile.
- it would be interesting to compare this against a trivial implementation that does not have a lookup cache, but instead simply does not tokenize to discard the line. Maybe using something like strchr() to find the end of line.
- a different lookup structure other than a linearly searched list might be worthwhile.
- ...?
But this should be good enough for now. On to quantifying the impact of this stuff...
-
Proper Parsing with RE2C
06/20/2018 at 15:55 • 0 commentsJun-16 12:09 PM
It's a little inconvenient for the construction of this back-formed log, but chronologically I had started investigating a potential way of replacing the get_next_token() implementation just prior to the events of the last log entry, wherein I had discovered some data anomalies that changed my opinion about what work would result in the biggest gains for the least costs. But having got past that diversion, I was now more resolved to actually implement and measure results.
My background is not in Computer Science -- I am self-taught in software engineering -- and consequently there are holes in my understanding of various formal Computer Science topics. Amongst these is all the theory around the construction of language processors. But I'm at least cursorily familiar with their existence, and I can construct useful web queries.
Parsing is one of my least favorite activities, right up there with keyboard debouncing and bitblt routines. Doubtlessly this is because I have always hand-crafted parsers. You can get by with that for simple stuff, but it rapidly becomes an un-fun chore. Many years back I decided to bite-the-bullet and learn about 'regular expressions' as the term applies to software, which are a computerification of some stuff that Noam Chomsky and others did ages ago in the field of linguistics.
https://en.wikipedia.org/wiki/Regular_language
Suffice it to say that regular expressions (or 'regexes') are a succinct way of express a pattern for matching against a sequence of symbols. Most will be familiar with a very simple form of pattern matching for doing directory listings; e.g. 'ls *.txt' to list all files that end with '.txt'. Regexes are like that on steroids.
My boredom with parsing is evidently something of a cultural universal, because there have been tools created to automate the generation of parsers since time immemorial, and they pretty much all use regexes for the first part: 'lexing', or breaking stuff up into tokens ('lexemes'). I.e., exactly what we are trying to do in get_next_token(). (The second part is applying grammar, which we are leaving in the existing ubasic implementation). There are a lot of tools for all the usual reasons: folks make new versions with modern capabilities, folks make versions with more power, folks make versions suited to different execution environments. So, time for shopping...
I didn't spend a lot of time researching options, but I did spend a little, and I'll spare you the shopping tales. I decided on using 're2c' to generate the lexer/tokenizer.
This tool is pretty simple in what it does: take a list of regular expressions associated with a chunklette of C code to invoke when they match. It doesn't really even create a complete piece of code, but rather is expected to have it's output spewed into the middle of a function that you write, that is the lexical scanner. The code that it generates is a monster switch statement that represents a compiled and optimized Deterministic Finite Automata (DFA)
https://en.wikipedia.org/wiki/Deterministic_finite_automaton
for all the patterns that you have specified. It is held in high regard, and apparently results in more efficient code than some alternative approaches, such as the table-driven approach used in Lex/Flex. It is also minimalistic in that it just spews out pure C code, with no particular library dependencies (not even stdlib, really) since you are expected to do all the I/O needed to provide symbols to it. So it seemed a good match, and a-learnin' I did go.
I had not used this tool before, so I did the usual cut-and-paste of the most simple examples I could find for it, and then find the 'hole' where I stick in my regexes. I figured that out fairly quickly, so then I needed to see how to marry all this with the existing ubasic code.
There was a prevailing desire to not re-engineer ubasic, but rather to surgically replace the sub-optimal component. Helpfully, the ubasic codebase was simple, and moreover had a separate component called 'tokenizer' which did all the tokenizing work. Nice!
The only function I required to replace was get_next_token() as per my profiling results. However looking over the tokenizer.c's implementation, this seemed like it might be an awkward task since it had some coupling with neighboring function's implementation. On the other hand, the module as a whole had a relatively simple interface defined in tokenizer.h:
//this sets up pointers to start the process, and implicitly sets up to return the first token void tokenizer_init(const char *program); //this advances to the next token (if possible) void tokenizer_next(void); //this gets the token ID of current token int tokenizer_token(void); //this interprets the current token as an integer int tokenizer_num(void); //this interprets the current token as a variable name, returned as an index 0-25 (A-Z) int tokenizer_variable_num(void); //this interpretst the current token as a quoted string, with the quotes removed void tokenizer_string(char *dest, int len); //this indicates that we are done with the input symbol stream int tokenizer_finished(void); //this causes the implementation to spew out some debug info, if it is a debug build void tokenizer_error_print(void);I decided it would be easier to simply re-implement those methods in terms of the new lexical scanner I would be creating. A little more work, but not much. Less work relative to trying to preserve carnal assumptions within the implementation of those public methods.
The re2c tool takes an input file of your creation, conventionally named with an '.re' suffix, and injects generated code into a space demarcated by a special comment. The result is your C code with a state machine stuck into a hole you created. Most of the .re file I created was some definitions of a structure of my creation named 'Scanner', which contained the scanner's state. This state consisted of a bunch of pointers into 'where are we now', 'where were we when we started this token', 'some scratch stuff that re2c needs if it needs to back up', 'what token did we find', etc.
typedef struct Scanner { const char* top; //start of token const char* _pchCur; //cursor; will be just past token when emitting tokens const char* ptr; //used by re2c to store position for backtracking const char* pos; // const char* _pchBackup; //if we need to do backup from a lookahead int line; //line no in source file int current_token; } Scanner;also needed are some macros that re2c expects to exist. These macros are what allows re2c code to interface to your code in a well-defined way so that you can adapt all sorts of I/O mechanisms (e.g. serial ports, whatever) as a source of data into the scanner in a uniform way. In this case it's really easy, since all the program text is in one contiguous memory region, so even I can code that correctly!
#define YYCTYPE char #define YYCURSOR s->_pchCur #define YYMARKER s->ptr #define YYCTXMARKER s->_pchBackupWhat does all that mean? Use the docco!
http://re2c.org/manual/manual.html
anyway, the rest of the file was the C code that provides the implementation of the public functions that are being replaced. I won't bore you with that here, just take it as read that they were relatively simple implementations that worked off the state data in 'struct Scanner', of which there was defined a global instance. The tasty bits are the re2c patterns that make up your lexer. Again, the full definition is long, so I'm just going to show a piece of it:
int scan(Scanner* s) { regular: if ('\0' == *s->_pchCur) { return TOKENIZER_ENDOFINPUT; } s->top = s->_pchCur; /*!re2c re2c:yyfill:enable = 0; /*buffer contains all text, so 'no'*/ whitespace = [ \t\v\f]+; dig = [0-9]; any = [\000-\377]; */ /*!re2c dig+ { return (TOKENIZER_NUMBER); } ["]([^"]+)["] { return (TOKENIZER_STRING); } [a-zA-Z] { return (TOKENIZER_VARIABLE); } "\r\n"|"\n" { s->pos = s->_pchCur; s->line++; return (TOKENIZER_CR); } "," { return (TOKENIZER_COMMA); } ";" { return (TOKENIZER_SEMICOLON); } "+" { return (TOKENIZER_PLUS); } //... more symbols 'let' { return (TOKENIZER_LET); } 'print' { return (TOKENIZER_PRINT); } 'println' { return (TOKENIZER_PRINTLN); } 'if' { return (TOKENIZER_IF); } 'then' { return (TOKENIZER_THEN); } 'else' { return (TOKENIZER_ELSE); } //... more keywords whitespace { goto regular; } any { printf("unexpected character: %c\n", *s->_pchCur); return (TOKENIZER_ERROR); } */ }So, you can see that the tool works by having a conventional C comment block with a special token '!re2c' that demarcates some stuff that the re2c tool should process. You can have as many of these blocks as you like, wherever you like. Of course, it only really makes sense in the context of a scanner function.
The first '!re2c' block contains some directives and 'character class' definitions. Really, much of this scanner came cut-and-paste from an example I found, and I hacked it down to the minimum I needed. Hence the label 'regular' exists because there used to be some other labels for some different scanner states I didn't need. Similarly is the case with the inconsistent naming of member variables in the 'struct Scanner'. Since this was a proof-of-concept exercise, I didn't devote as much time to polishing for posterity.
Anyway, most of the interesting stuff is that you use regexes to define patterns to match abstract things, like 'text enclosed in quotation marks' or 'a well-formed number' or 'a case-insensitive string to match'. These patterns, when matched, result in some code that is executed. Usually, this code is simply to emit the token id. But it can be arbitrary things, too. For example, the CRLF or LF pattern match will emit the TOKENIZER_CR code, but before it does, it will increment a line counter, and set the current position to be after the found pattern. This was done to support some debug output -- it's not required for what we are doing, but I used it in a testing function I created that barfs out all the parsed tokens for the input program. I very much needed this to validate that my patterns were working correctly. And similarly, the 'whitespace' match does a goto 'regular:' to effectively ignore whitespace matches.
Before moving on from the re2c syntax, some things seem worth mentioning:- enclosing a text sequence in " will match a literal sequence of characters in a case-sensitive manner. Similarly, a text sequence in ' will match case-/in/sensitive. Other regex schemes do not use such a convention, but trying to express these sorts of patterns in traditional schemes -- though possible -- is extremely awkward. This provision is a boon to defining language parsers.
- re2c will emit tokens with 'maximal munch'; i.e., as much input that can be consumed as possible. So feel free to define a pattern 'if' and 'iff'. The generated lexer will not match 'if' as a sub-sequence before matching 'iff'.
The result of running the .re file through the tool is a C language file (ostensibly named '*.c' (or '.*\.c' if you want to get regexy with it)). You're not meant to scrutinize that file, but it's interesting to take a gander to see how the sausage is made. Here's some excerpts:
int scan(Scanner* s) { regular: if ('\0' == *s->_pchCur) { return TOKENIZER_ENDOFINPUT; } s->top = s->_pchCur; { YYCTYPE yych; unsigned int yyaccept = 0; yych = *YYCURSOR; switch (yych) { case '\t': case '\v': case '\f': case ' ': goto yy54; case '\n': goto yy23; case '\r': goto yy25; case '"': goto yy4; case '%': goto yy42; case '&': goto yy34; case '(': goto yy44; case ')': goto yy46; case '*': goto yy38; case '+': goto yy30; case ',': goto yy26; case '-': goto yy32; case '/': goto yy40; case '0': case '1': case '2': case '3': case '4': case '5': case '6': case '7': case '8': case '9': goto yy2; case ';': goto yy28; case '<': goto yy48; case '=': goto yy52; case '>': goto yy50; case 'A': case 'B': case 'D': case 'H': case 'J': case 'M': case 'Q': case 'V': case 'X': case 'Y': case 'Z': case 'a': case 'b': case 'd': case 'h': case 'j': case 'm': case 'q': case 'v': case 'x': case 'y': case 'z': goto yy6; case 'C': case 'c': goto yy8; case 'E': case 'e': goto yy9; case 'F': case 'f': goto yy10; case 'G': case 'g': goto yy11; case 'I': case 'i': goto yy12; case 'K': case 'k': goto yy13; case 'L': case 'l': goto yy14; case 'N': case 'n': goto yy15; case 'O': case 'o': goto yy16; case 'P': case 'p': goto yy17; case 'R': case 'r': goto yy18; case 'S': case 's': goto yy19; case 'T': case 't': goto yy20; case 'U': case 'u': goto yy21; case 'W': case 'w': goto yy22; case '|': goto yy36; default: goto yy56; } yy2: ++YYCURSOR; yych = *YYCURSOR; goto yy216; yy3: { return (TOKENIZER_NUMBER); } //... more stuff yy215: ++YYCURSOR; yych = *YYCURSOR; yy216: switch (yych) { case '0': case '1': case '2': case '3': case '4': case '5': case '6': case '7': case '8': case '9': goto yy215; default: goto yy3; } }So, you can see that the first part is stuff copied verbatim from our input file, as expected. Then the tool squirts in it's own stuff. That stuff comprises a state machine that traverses the paths defined by the sequences of symbols towards a completed match, at which point they invoke the code we defined in the .re file.
For example, if we started with pulling a digit, then we would goto label yy2: that would pull another character and proceed to label yy216: that would test to see if it is also a digit. If it is, it would proceed to yy215: that pulls another character and falls though to yy216: that checks for digits. Ultimately, a non-digit will be pulled, that will cause transfer to yy3: that will emit the TOKENIZER_NUMBER symbol. Pointers in the 'struct Scanner' instances will be maintained along the way that can be used to demarcated where the matched pattern begins and ends.
Why is this useful?
An obvious benefit is that you can express the things you want in terms of patterns, rather than literal code. In this case, much of tokenizer.c was matching against a list of string literals for keywords -- that is easy. But there was also special code to match against quote enclosed strings, variable names, and numeric sequences. Those were manually coded. For ubasic, this was easy enough, but what if we supported anything fancier, e.g. floating pointer numbers, or scientific notation. What a bear!
A perhaps less obvious benefit is that this is much more efficient that sequentially strcmp()'ing against a list of literals. Not so much because of the magic of regular expressions, but more because of the magic of having a constant set of patterns against which to match (the language, lol). Consider this pseudo-language:
"AND"
"AMOS"
"ANDY"If one were to use the strcmp-and-loop approach, what would happen would be something like:
- check for 'A', then 'N', then 'D'. emit TOK_AND if all of them else FALSE
- if no match then check for 'A', then 'M', then 'O' then 'S'. TOK_AMOS or FALSE
- if no match then check for 'A', then 'N', then 'D' then 'Y'. TOK_ANDY or FALSE
- if FALSE then FALSE else whatever token
The salient point being is that we compared the first character to 'A' three times. And the second and third to 'ND' twice. If all this testing were reconfigured as a tree of possible symbol sequences, then those comparisons can be factored, and done fewer (and often once) times.
So, in a way, you can look at the individual patterns as defining a little symbol sequence graph, and the lexer generator tool as a mechanism for merging a collection of those graphs into a master graph. After having done so, there are there are algorithms that may be applied for further reducing the complexity of that aggregate graph.
For anything of more than minor complexity, you probably should reconsider hand coding this stuff. There are exceptions, of course. With this tool in particular, there is probably going to be a code size burden that is higher than looping over a list of string literals and repeatedly calling a stdlib routine. But how much of a burden? I suspect that this tool would be hard-pressed to generate anything useful for a PIC18, but I also suspect that it could generate usable code for a LPC1114.
In the end, the re2c-generated lexer was emitted, and verified against the test program by checking the the generated token sequence. It took a few iterations to get all the patterns right. But because I was newly hot on the trail improving the jump_linenum() logic, I proceeded towards that implementation before setting down to profile this one.
-
Autobogotiphobia
06/20/2018 at 01:56 • 0 commentsJun-15 8:01 PM
When writing, I try to edit, but I have know that I will fail and there will be silly typos. I have gotten over this. Less so with errors in facts. And so it was the case when I was looking at the data again, and noticed that some things did not quite jibe.
For one thing, the time taken for strncmp was shown to be zero, even though it was called 125 million times. Somehow I doubt that. get_next_token()'s implementation for the most part is looping over a list of keywords and calling strncmp(). So it seemed that strncmp()'s execution time was being somehow sucked up into get_next_token()'s.
Another thing was that jump_linenum() was being called an awful lot. Doing a quick cross-reference to the call sites for this method, I discovered that it is used for 'goto', but also 'gosub', 'return', 'next', 'if', 'then' -- pretty much anything that changes flow-of-control other than sequentially forward. That makes some sense. But then I noticed the implementation details, and things really made sense:
static void jump_linenum(int linenum) { tokenizer_init(program_ptr); while(tokenizer_num() != linenum) { do { do { tokenizer_next(); } while(tokenizer_token() != TOKENIZER_CR && tokenizer_token() != TOKENIZER_ENDOFINPUT); if(tokenizer_token() == TOKENIZER_CR) { tokenizer_next(); } if (tokenizer_token() == TOKENIZER_ENDOFINPUT) { sprintf(err_msg,"Unreachable line %d called from %d\n",linenum,last_linenum); stdio_write(err_msg); tokenizer_error_print(); longjmp(jbuf,1); // jumps back to where setjmp was called - making setjmp now return 1 } } while(tokenizer_token() != TOKENIZER_NUMBER); DEBUG_PRINTF("jump_linenum: Found line %d\n", tokenizer_num()); } }So, the first thing that caught my eye is "tokenizer_init(program_ptr);". That means any time we are changing flow-of-control, we are re-initializing the parsing of the entire program from the beginning. The init call itself is not expensive -- it just sets up some pointers -- but it makes it clear that any time one does a transfer of control, that we are setting up to scan the whole program to find the target line number.
The next thing that caught my eye were the loops within. Essentially, they are tokenizing the program, and throwing away all the tokens, except for the end-of-line. This is used to sync the parser to the start of the line (with the line number being the first parsed value) to test if it is the target line number. That's when I had a realization: that probably the reason there is so much time spend in the tokenizer routine 'get_next_token()' is because all transfer-of-controls imply re-parsing the program text up to the target line.
In retrospect, maybe this should have been a bit obvious looking at the numbers from the profiler, the 17,186 jump_linenum calls being related to 5,563,383 get_next_token calls, but I didn't think much of it at the time.
So, I suddenly got a sinking feeling that I had given bad advice in recommending focusing on improving get_next_token(). That that function still could benefit from improvement, but the real gains might be in simply having it called far less often.
The other thing that puzzled me was the apparently free calls to strncmp that were made 125 million times. Now that would be some magic. Having freshly studied jump_linenum(), I hit upon an intuition: maybe information is being lost behind the 'static' declaration. This warrants a little explaining...
'static' is an odd C keyword in that is overloaded to mean either of:- 'private': not visible outside this source file ('translation unit') -- not even via an 'extern' declaration, when applied to functions and global variables.
- 'durable': having a lifetime beyond lexical scope, when applied to local variables.
In this case it means 'private'. Compilers are free to realize this capability however they like, and it is done differently in gcc and msc, but either way, the result is to remove some semantic information from the resulting object code. Could the 'static' specifier be warping my profiler results?
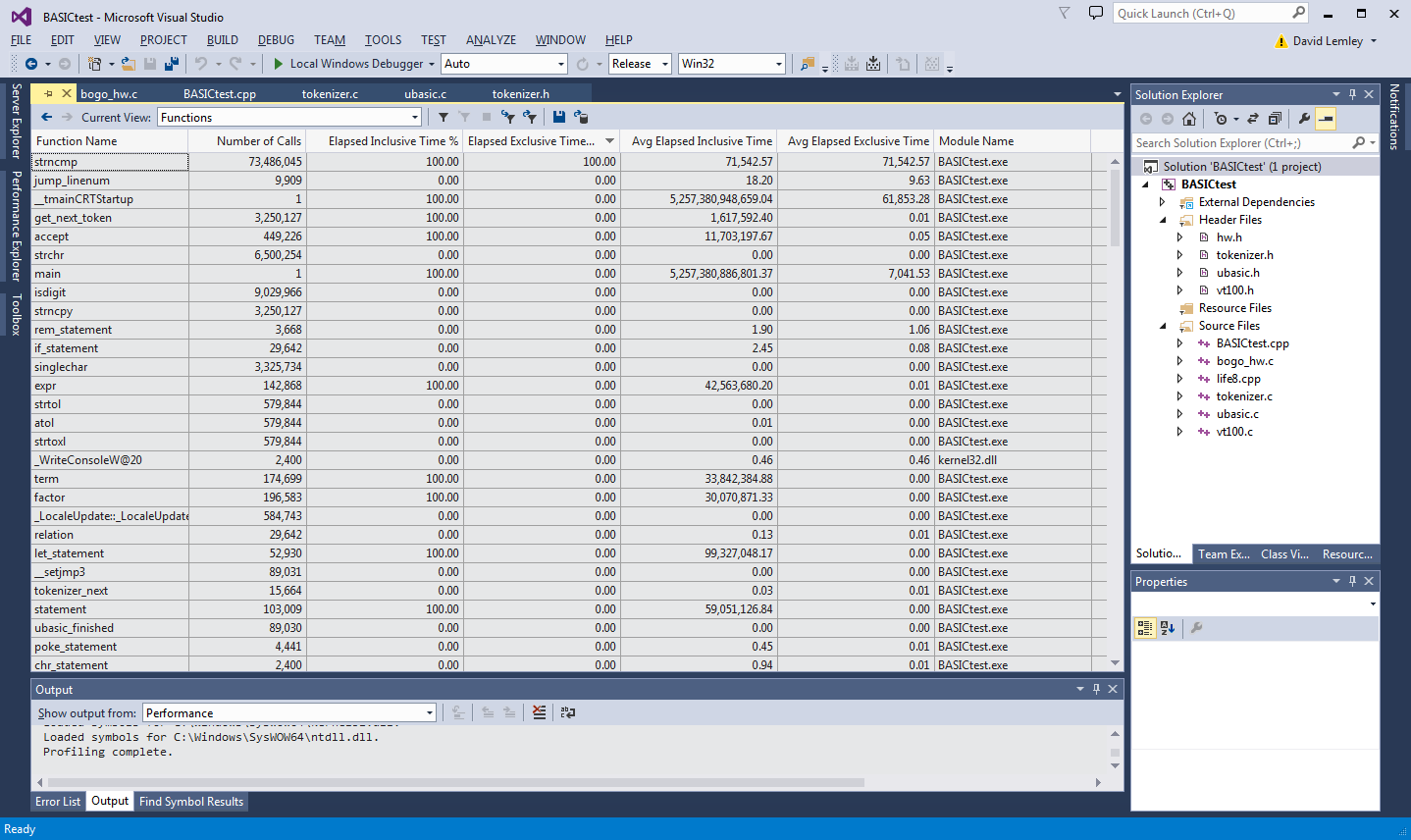
Well, that was just a /*...*/ away, so I removed the 'static' specifier from jump_linenum() and re-profiled. Now my data look like:
![]()
That is a little more sane! Now I can see that the nearly 100% of the time is spent in strncmp -- more or less as expected, since that is how this tokenizer is implemented: a loop over a list of keywords, comparing against each. Really, I should strip all 'static' and re-run, but I think I've got enough of a view from just this one change.
Ugh, I hate it when I do that. Aside from some embarrassment at being wrong, I was more concerned that maybe someone could be off on a wild goose chase based on faulty advice. The likelihood of that was low, but I felt I needed to convey the updated findings.
I quickly crafted and sent an amended statement, this time suggesting that maybe focusing on improving jump_linenum() might be the big win, rather than squeezing blood from a turnip with get_next_token().
So my moral duty was done. A little bit frustrated with myself for having not scrutinized the data more closely before formulating advice, I decided to actually try to implement the recommendations so I could measure the impact.
-
Getting Down to Business
06/19/2018 at 17:17 • 0 commentsJun-12 3:10 PM - Jun-12 6:01 PM
I was eager to get some empirical validation (or negation) of these hypotheses (and maybe even get some new ones). However, I didn't have the actual hardware. On the one hand, you can't draw conclusive inferences when testing on a non-normative platform, but on the other hand, what else can I use. So I decided to go ahead and port the program to a desktop application, and just try to be careful to avoid measuring anything that was not CPU related (like screen I/O), and even then, take the results with a grain of salt.
Mostly because of personal familiarity, and partially because of expedience, I decided to port the ubasic into a Windows application. The reasons were:
- I have a bunch of Windows build systems on-hand
- I have familiarity with using Developer Studio's profiler. Well, mostly.
It seems that Microsoft has significantly dumbed-down the profiler in VS, in the past few years. On the upside, it's much easier to start up, but I do miss the granularity of control that I had before. Maybe I'm a masochist. Anyway, for this exercise, I'm using Developer Studio 2013 Community Edition. (Old, I know, but I use virtual machines for my build boxes, and I happened to have one already setup with this version in it.)
But first things first: building an application.
The needed changes were relatively straightforward, thanks to the clean effort of the [project's authors] -- especially considering how quickly they built this system. Mostly, I needed to do some haquery to simply stub out the hardware-specific stuff (like twiddling gpio), since my test program didn't use those, and then change the video output to go to the screen. Fortunately, since those routines were character-oriented at the point where I was slicing, it was easy for me to change those to stdio things like 'putc' and 'puts'. It still took about 3 hours to do, because you need to also understand what you're cutting out when you're doing the surgery.
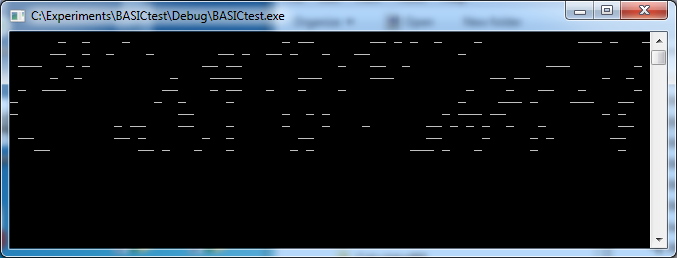
After that, I was able to run the sample BASIC life program. The screen output was garbage, so maybe it wasn't working, but I could see screen loads of output, followed by a pause, followed by more screen loads of output. Nothing crashed. This is a pretty good indication that things are more-or-less working.
![]()
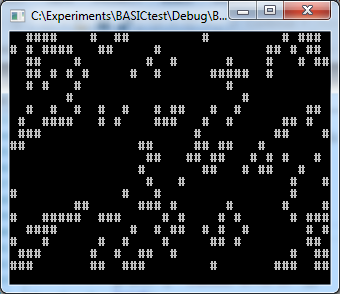
Just looking at the output change during the run showed that it was pretty slow. This was running on my 2.8 GHz desktop machine and it was slow, so I can only imagine the experience on the 48 MHz embedded processor. To make it visually look a little better, I tweaked the source code to output a different character, and implemented the 'setxy' function to actually set the cursor position, and then had Windows remember the screen size, which I set to 40x21 (I added a row because doing a putc to the last character position would stimulate a screen scroll). Now it looks a little more like 'Life'.
![]()
OK, that's enough play time. We should be ready to do a profiling run. As mentioned, this is more easily launched in current Visual Studios. In the case of VS 2013, it is under the DEBUG menu as 'Performance and Diagnostics. (check the docco for your version if different; they move it from time-to-time.)
![]()
Which will lead to the opening screen.
![]()
And when you click 'start' you'll get into the 'performance wizard', which is just a sequence of dialog boxes with options.
![]()
There's several ways to profile. The default is a low-impact sampling method. In retrospect, I probably should have used this to start with -- it usually presents a reasonably accurate view, and it is low-impact. But I was going for precision out of habit, and I chose 'Instrumentation'. This has associated costs.
The 'CPU sampling' method presumably works by periodically interrupting the process and seeing where it is, and taking notes. The 'Instrumentation' method does a special link activity, where every function [well, almost! as we'll see in a subsequent post] gets a little prologue and epilogue injected, which reports time taken in that function. As you can imagine, 'Instrumentation' is more exact, but incurs a big overhead. It also generates voluminous data -- like gigabytes for just a couple generations of Life. [This is one reason I liked the old profiler system: I had control over what sections of the application to profile, so I didn't incur these impacts across the whole thing.]
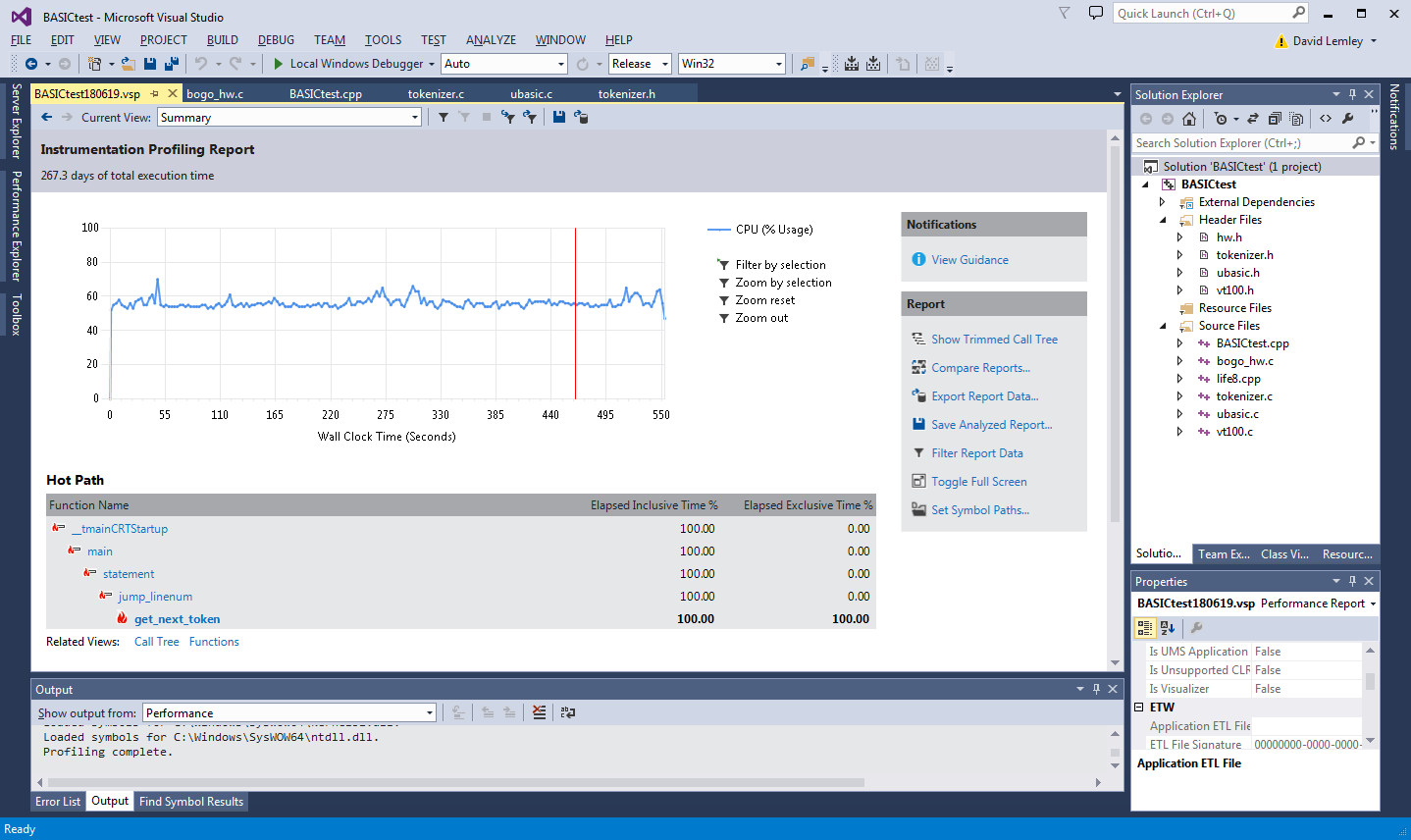
So, now the program is REALLY slow, and needs some baby sitting. I let it get through a couple generations while I did other things, and then exit it to stop profiling. It generated over 7 GB or data, so know this before you start. It also takes quite a while for the profiler to collate that data after your program ends. So there's another opportunity for a coffee break. Afterwards, you are rewarded with a pretty summary screen:
![]()
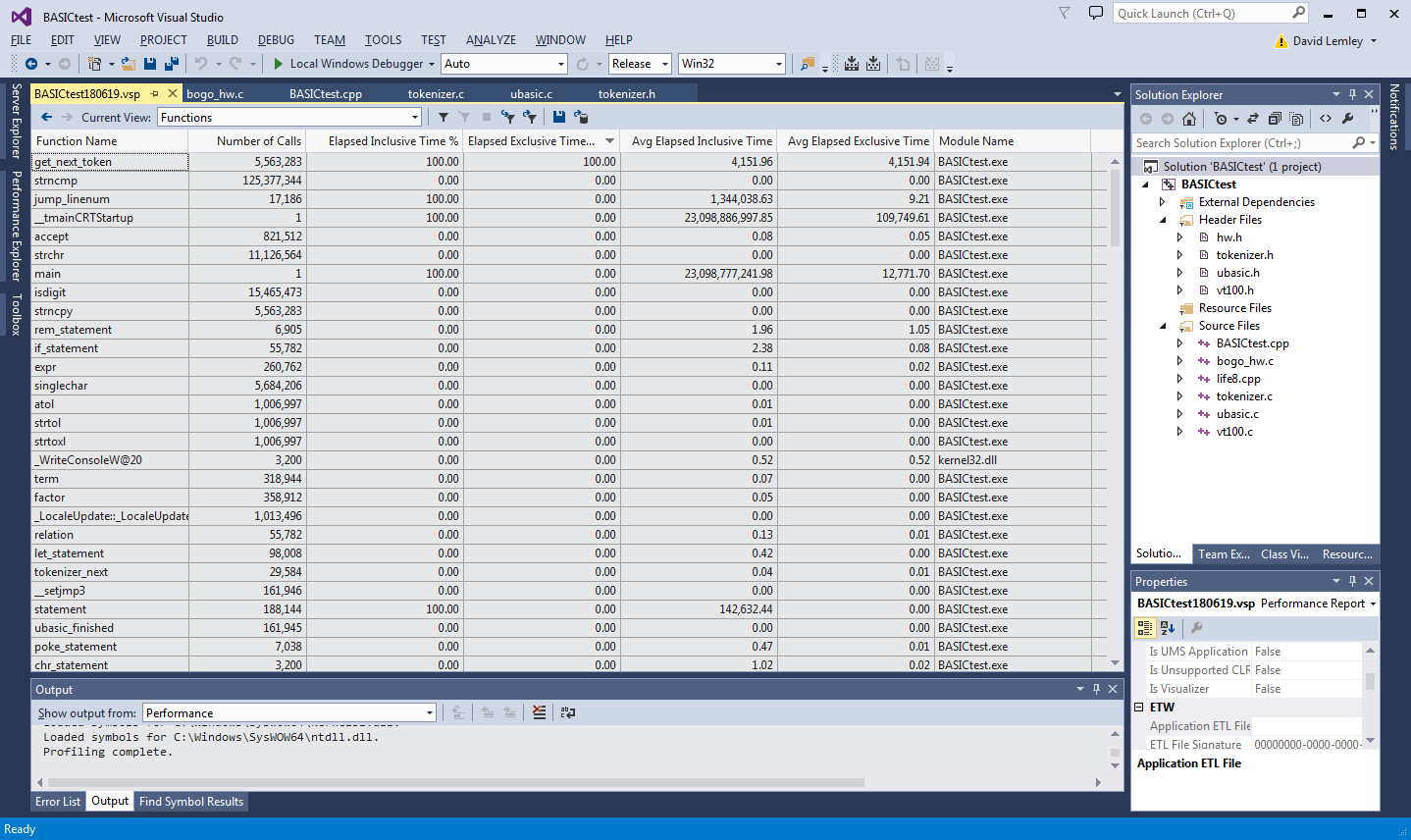
It conveniently determines the 'hot path' through your application, but that is just a summary, I like to look at the gory data. In the 'Functions' view, you get a spreadsheet-esque table listing the various functions profiled, and their 'Inclusive' and 'Exclusive' times, amongst other things:
![]()
The 'Inclusive' time is the time spent in this function, and all the functions it called. The 'Exclusive' time is the time spent just in this function, disregarding that in the functions it calls. I usually first focus on the 'Exclusive' time, because that tells me where some code can be directly modified that has a performance impact, but 'Inclusive' is also important because that can indicate opportunities in reducing the number of child function calls. Like in loops.
In this case I notice get_next_token is being indicated as taking up practically 100% of the execution time ('Exclusive'), whereas nothing else seems to matter at all.
As mentioned before, I take the numbers with a grain of salt when I am profiling a hacked test harness application like this, especially cross platform, and especially cross CPU. But given these number are so wildly skewed towards this particular function ('get_next_token'), and because this is simple C code, I feel pretty sure that this gives a reasonably accurate picture of what's the root cause of the performance problem. And on the positive side, it looks like improving this one function will have a tremendous benefit to performance overall!
At this point I did overlook some things, but I'm not going to describe that here, since that is the subject of a subsequent post.
I announced these findings to [the original inquirer], and suggested that some low-hanging fruit would be to look at the implementation of get_next_token(). Further, since it represents nearly 100% of the execution time, net gains will initially be directly proportional to gains in this function alone. E.g. speeding the function to take 50% of the time will make the app as a whole take 50% of the time. This is only true at the beginning -- every gain you make will cause the other functions' times to increasingly dominate -- so the margins will decrease. But it will be great at the beginning.
-
To Truly Know, You Must Measure
06/19/2018 at 02:50 • 0 commentsJun-11 7:17 PM - Jun-11 9:50 PM
Initially, I described some speculative causes for 'slowness':
- a cursory desk-check of the code showed that the implementation was parsing plaintext BASIC for each line each time it was executed. This isn't 'wrong', but I know that BASIC's back in the day (70s-80s) typically used 'tokenization' to save space and parsing effort at runtime. I.e., at program entry time, for each line submitted, it was parsed for keywords, and they were replaced with a single byte representing that keyword. This avoided re-parsing at runtime, and saved space. Maybe tokenization was worth the effort? That would involve significant work, though (in my opinion).
- similarly, line numbers were stored as text along with their associated code. BASICs back in the day often stored line numbers as binary in a little 'header', and also often had a forward pointer to the next line. This allowed skipping about through the program to happen quicker.
- I also mentioned that all of this was CPU bound, but screen I/O (and any other I/O) might be worth considering. In my TRS-80 project, I initially reused some existing code for doing the video, including font support. For whatever reason, that code stored fonts in column-major order, whereas row-major was much more natural for the underlying hardware implementation. When I had re-generated the font to be row-major (and also with an endianess that matched the SPI ordering), then I was able to blit rows of pixels at a time, instead of setting them dot-by-dot (and with the added overhead of function calls). This dramatically increased performance for my project.
I asked what does 'slow' mean in this context, because there really was no baseline: it was a bespoke project unlike any other. It just 'felt' slow at some intuitive level. I asked if I could have a sample BASIC program that felt slow, and that I would take a looky-loo.
The sample program happened to be an implementation of Conway's game of Life, and I was familiar with that. They were super popular in the 70s-80s, and I had run one at least once on my actual TRS-80 back in the day, with it's screaming hot ~1.77 MHz Z-80. And Z-80's took 4-23 clocks to do one instruction, so I would think that, yeah, a 48 MHz MIPS could probably do a little better.
Now, I had no reason to believe that the video thing I mentioned was relevant here, but I did want to point out that sometimes it's not where you think it is. In that case, you could 'optimize' the BASIC until it took zero CPU time, and that still would not get you improvements to deal with an I/O bound bottleneck, or even a CPU bottleneck that is not where you are looking. Believe me, I have made this mistake before.
Speculation is useful as a heuristic to formulate hypotheses, but you really need to test empirically. Not measuring risks wasting development time chasing wild aquatic fowl, and that is itself a kind of speed optimization.
-
In the Beginning, there was the BASIC, and it was formed and without voids
06/19/2018 at 01:47 • 0 commentsJun-6 4:20 PM - Jun-11 12:44 PM
[MS] had reached out asking about a project of mine, the [TRS-80 on a PIC32], and if it was considered stable. I believed it was -- it's an older project of mine, and now it's in enhancement/maintenance mode (though interesting bugs are still found from time-to-time by users!) At length, the reason for the inquiry is that they were thinking about replacing an existing BASIC interpreter that seemed slow with an emulation of a TRS-80. They did a little research and so came across my project.
However, as flattered as I was at the notion of porting my emulator to another hardware platform (which I would enjoy), I had to ask: wouldn't a native implementation be faster than an implementation on an emulated CPU? And has there been any analysis done on where the slowdown might be.
[The guys involved in the project] had been running at break-neck speed to get it completed for an event, and really hadn't had time to dig into the speed problem. (I know, I saw the commit history -- it was very impressive what was done in such a small time. Integrating this BASIC was just a small part of the overall project.) Since that event was over, there was a little time to come up for breath and look at possible improvements.
I had taken a peek at the BASIC implementation. It was straightforward: just 2 C-language modules (4 files, header and implementation), and didn't have any funky library dependencies. The code was originally written by an Adam Dunkels [http://dunkels.com/adam/ubasic/] as a personal challenge to himself to speed-code a functioning BASIC, and he released it unto the world for anyone to use if they liked. [The project team] had extended it with a bunch of new keywords, and of course adapting to their board's I/O subsystems.
OK, those that know me, know that I have a fetish for disassembly. I'd check myself into Betty Ford if they had one for reversers. I don't know why it is -- it just is. It's yielded some good things professionally, but not often enough to slake my thirst. A distant third or fourth place is for code optimization, so for someone to say they have a speed problem in some straightforward C source code... That's going to be a... 'distraction', for me. I guess it's best just to take a look and get it over with....
UBASIC And The Need For Speed
I basic, 'ubasic', they basic, we basic; wouldn't you like a speedy BASIC, too?