-
faster sqrt (or so it seems on single point precision)
09/19/2019 at 22:41 • 0 commentsi'm working on reducing solve times for sqrt and div that i can not eliminate. currently the times for sqrt of all 768 cells are less than 100000 microseconds. now i'm trying to remove division and where it still is needed reduce time down drastically. for example there are 2 division operations that take most of the time and limit performance of detailed Temp measurement of 768 cells upsampled to 3072 cells at ~0.6 seconds at latest build . still not uploaded as it requires a lot of checks for modes, features and multiple processor testing. but it will be.
ok. back on point reducing sqrt root.
i have discussed this here:
https://hackaday.io/project/167533-faster-speed-how-optimize-math-and-process-tasks
and have implemented the choice to use it in the algorithms for the mlx90640, but i was also able to eliminate one of the sqrt(sqrt(x)) loops from the sensor math. but here is the sqrt function i'm using. it has an error rate average of less than 1%, but with some numbers it could go to 3%. it is more accurate than the original float i found that uses this method. there also is a fast method that corrects for the rounding error but i need to look at that in more detail. this one here is more based on my base 10 thinking.
if USE_FAST_SQUARERT_METHOD will need to be set as true.
float Q_rsqrt( float val ) //a good enough square root method.
if not enabled in Z_memManagment then it will work as regular sqrt and use math library
{
#if USE_FAST_SQUARERT_METHOD == true
float invertDivide=0.66666666666 ;// ~1/1.5 rounded down to float precision single float
long tmp = *(long *)&val;
val*=0.22474487139;//number that keeps precision detail by keeping remainder. (base 10 thinking. prob //better to think in base2
long tmp2 = *(long *)&val;
tmp -= 127L<<23; //* Remove IEEE bias from exponent (-2^23) */1065353216
tmp2 -= 127L<<23; //* Remove IEEE bias from exponent (-2^23) */1065353216
tmp = tmp >> 1; //* divide by 2 *
tmp2 = tmp2 >> 1; //* divide by 2 *tmp +=1065353216; /* restore the IEEE bias from the exponent (+2^23) */
tmp2 +=1065353216; /* restore the IEEE bias from the exponent (+2^23) */
float offset=*(float *)&tmp2;
val= *(float *)&tmp;
return (val+offset)*invertDivide;
#else
//we do the more accurate but slower method if it is set
return sqrt(val);
#endif
} -
syncing the line numbers and adding START,END for exporting programs
09/13/2019 at 02:41 • 0 commentsthese updates will come with the changes i'm releasing 9/13/19. (not released it is 9/19 and still testing )
I'm adding some extra stuff that makes sending data to another program easier. this is the low res ascii output but the same will be done for the raw data output (raw data output will be able to be 32x24 or 64x48) . when the frame is started it sends out a 'start' and when it ends it sends out 'END" and each line is numbered. this reduces the chance of a data error corrupting more than one line from scan. and it helps keep the data in sync on another device.
![]()
-
buffering ram data from serial (it will be compressed for terminal output)
09/12/2019 at 13:57 • 0 commentsi had to use the atmega with 8k of ram just so i could test the concept of caching all the ram data in the serial cache. i can do it with compression and get the same output speed as teensy-lc. part of the issue with serial data is that it is all sent after each mem read and calculation of To. in either process the mem read is not yet the fastest. I plan to optimize the mem Calculations as well.
this is only visual. the main interest for this project is to get it outputting to lcd.
anyway before i compress serial output, i wanted to see how much improvement it would have at output uncompressed.
these are done on 16mhz arduino 1280. with 8k of ram. uncompressed buffer is 3072 bytes. i will get the data output down to 96 bytes. but before i do that work, i wanted to be sure it improved output to serial terminal.
unbuffered
buffered faster output to display. (my hand was cold from walking the dog outside. so fingers dont show up that good. lol. sorry.)
-
a lot faster in image mode, but it only works if you normalize it
09/12/2019 at 02:24 • 0 commentsill release code that does normalizing of image data 9/13
image mode is a lot faster, but you need to adjust the sensitivity and figure out how the range should apply. in my case i want it to work in a similar range as the deg C. it will have some cells still out of reasonable range, but this is ok for image data.
here is a nano, using a 328p, the same chip class as the uno running image mode
with normalizing. at first few frames it is saturated, but it self adjusts. then i do the hand count in front of sensor. then i give the sensor a high five pose.
here is how to normalize the sensor automatically.
//this is code that adjusts the sensitivity. it has 10 in between values so it does not oscillate back and forth.
void Normalize(){
if (autoNormalizeAdjust>50){ autoNormalizeAdjust=50;} //this is the max level
if (autoNormalizeAdjust>255){ autoNormalizeAdjust=0;}// was backed up to far and rolled around
if (autoNormalizeAdjust==0){RamstoreNormalizeImageValue=(float)1/8;}
if (autoNormalizeAdjust==10){RamstoreNormalizeImageValue=(float)1/16;}
if (autoNormalizeAdjust==20){RamstoreNormalizeImageValue=(float)1/32;}
if (autoNormalizeAdjust==30){RamstoreNormalizeImageValue=(float)1/64;}
if (autoNormalizeAdjust==40){RamstoreNormalizeImageValue=(float)1/128;}
if (autoNormalizeAdjust==50){RamstoreNormalizeImageValue=(float)1/256;}
}
uint8_t shownormilzeMode(){
return autoNormalizeAdjust;
}to determine if image is over exposed, or needs to be normalized, i check 5 pixels.
* * it samples 5 cells. the total count needs to be odd, and still it could cause
* oscillation, this is why i have 10 numbers between changing sensativity.
* * it does take a few seconds for sensor to find its range however only during startup
if (pixelNumber == 32*12+16 ||pixelNumber ==0 ||pixelNumber ==31 || pixelNumber ==767 ||pixelNumber ==767-32){//we only do this on center pixel and top and bottom
here is how it knows it is saturated. image is the float value that holds the calculated value for return from get_image routine
#if autoNormalizeImageMode == true
if (Analog_resolution== 16){image=image*0.00003051757*RamstoreNormalizeImageValue;}
if (Analog_resolution== 17){image=image*0.00001525878*RamstoreNormalizeImageValue;}
if (Analog_resolution== 18){image=image*0.00000762939*RamstoreNormalizeImageValue;}
if (Analog_resolution== 19){image=image*0.00000381469*RamstoreNormalizeImageValue;}
if (pixelNumber == 32*12+16 ||pixelNumber ==0 ||pixelNumber ==31 || pixelNumber ==767 ||pixelNumber ==767-32){//we only do this on center pixel and top and bottom
if (image+25 <24){autoNormalizeAdjust++;Normalize();}
if (image+25>26){autoNormalizeAdjust--;Normalize();}
}
#else //this is if it is not auto and we use value in Z_MemManagement.h
if (Analog_resolution== 16){image=image*0.00003051757*NormalizeImageValue;}
if (Analog_resolution== 17){image=image*0.00001525878*NormalizeImageValue;}
if (Analog_resolution== 18){image=image*0.00000762939*NormalizeImageValue;}
if (Analog_resolution== 19){image=image*0.00000381469*NormalizeImageValue;}
#endif
return image+25; -
i explained why i'm reducing i2c cache from 64 words to 32 words here
09/10/2019 at 13:37 • 0 commentswith i2c buffer set at 32,
here is the current microseconds used to output 768 reads to terminal (it would be faster to spi lcd)
but most of the time taken is from the math of the To calc function
+145000 getting cal values
complex math in To is 500000 math
so total time is 645000 +getting ram from i2c.
850000 microseconds 32words buffer
770000 64 word buffer
790000 128 word buffer //we are above the range of benefit here.what i want to do is
1) buffer serial data so it instantly shows on screen.
2) use extra ram for LCD display functions.
i use the mlx90640 sensor to store its ram values until i need them. the ram values always are updating so they need to be requested at each frame no matter what. i can read one ram cell at a time or all of them, but here is why you would only need to read between 32-64 at a time (assuming it all is with one capture and you are getting data quickly, or the sensor is in step mode)
each word has an average of ~20,000 microseconds for my project. (with overhead of my code)
in the mlx90640 sensors case, each read of i2c requires a minimum of 7bytes +(2bytes each ram)
reading more than one byte at a time is more efficient.
1 word is at 22% efficient
16 words 80% efficient or 3.6 times faster than 1 byte
32 words is 90% efficient. 4.1 times faster than 1 byte
64 words is 94% efficient 4.3 times faster than 1 byte
128 words is 97% efficient 4.4 times faster than 1 byte
btw here is the efficiency based on how many words are i2c cached.
efficiency overhead. data received at a time. efficiency level
7(bytes) overhead 0word(0bytes):::::::::0
7(bytes) overhead 1word(2bytes):::::::::0.2222222222222222
7(bytes) overhead 2word(4bytes):::::::::0.36363636363636365
7(bytes) overhead 3word(6bytes):::::::::0.46153846153846156
7(bytes) overhead 4word(8bytes):::::::::0.5333333333333333
7(bytes) overhead 5word(10bytes):::::::::0.5882352941176471
7(bytes) overhead 6word(12bytes):::::::::0.631578947368421
7(bytes) overhead 7word(14bytes):::::::::0.6666666666666666
7(bytes) overhead 8word(16bytes):::::::::0.6956521739130435
7(bytes) overhead 9word(18bytes):::::::::0.72
7(bytes) overhead 10word(20bytes):::::::::0.7407407407407407
7(bytes) overhead 11word(22bytes):::::::::0.7586206896551724
7(bytes) overhead 12word(24bytes):::::::::0.7741935483870968
7(bytes) overhead 13word(26bytes):::::::::0.7878787878787878
7(bytes) overhead 14word(28bytes):::::::::0.8
7(bytes) overhead 15word(30bytes):::::::::0.8108108108108109
7(bytes) overhead 16word(32bytes):::::::::0.8205128205128205
7(bytes) overhead 17word(34bytes):::::::::0.8292682926829268
7(bytes) overhead 18word(36bytes):::::::::0.8372093023255814
7(bytes) overhead 19word(38bytes):::::::::0.8444444444444444
7(bytes) overhead 20word(40bytes):::::::::0.851063829787234
7(bytes) overhead 21word(42bytes):::::::::0.8571428571428571
7(bytes) overhead 22word(44bytes):::::::::0.8627450980392157
7(bytes) overhead 23word(46bytes):::::::::0.8679245283018868
7(bytes) overhead 24word(48bytes):::::::::0.8727272727272727
7(bytes) overhead 25word(50bytes):::::::::0.8771929824561403
7(bytes) overhead 26word(52bytes):::::::::0.8813559322033898
7(bytes) overhead 27word(54bytes):::::::::0.8852459016393442
7(bytes) overhead 28word(56bytes):::::::::0.8888888888888888
7(bytes) overhead 29word(58bytes):::::::::0.8923076923076924
7(bytes) overhead 30word(60bytes):::::::::0.8955223880597015
7(bytes) overhead 31word(62bytes):::::::::0.8985507246376812
7(bytes) overhead 32word(64bytes):::::::::0.9014084507042254
7(bytes) overhead 33word(66bytes):::::::::0.9041095890410958
7(bytes) overhead 34word(68bytes):::::::::0.9066666666666666
7(bytes) overhead 35word(70bytes):::::::::0.9090909090909091
7(bytes) overhead 36word(72bytes):::::::::0.9113924050632911
7(bytes) overhead 37word(74bytes):::::::::0.9135802469135802
7(bytes) overhead 38word(76bytes):::::::::0.9156626506024096
7(bytes) overhead 39word(78bytes):::::::::0.9176470588235294
7(bytes) overhead 40word(80bytes):::::::::0.9195402298850575
7(bytes) overhead 41word(82bytes):::::::::0.9213483146067416
7(bytes) overhead 42word(84bytes):::::::::0.9230769230769231
7(bytes) overhead 43word(86bytes):::::::::0.9247311827956989
7(bytes) overhead 44word(88bytes):::::::::0.9263157894736842
7(bytes) overhead 45word(90bytes):::::::::0.9278350515463918
7(bytes) overhead 46word(92bytes):::::::::0.9292929292929293
7(bytes) overhead 47word(94bytes):::::::::0.9306930693069307
7(bytes) overhead 48word(96bytes):::::::::0.9320388349514563
7(bytes) overhead 49word(98bytes):::::::::0.9333333333333333
7(bytes) overhead 50word(100bytes):::::::::0.9345794392523364
7(bytes) overhead 51word(102bytes):::::::::0.9357798165137615
7(bytes) overhead 52word(104bytes):::::::::0.9369369369369369
7(bytes) overhead 53word(106bytes):::::::::0.9380530973451328
7(bytes) overhead 54word(108bytes):::::::::0.9391304347826087
7(bytes) overhead 55word(110bytes):::::::::0.9401709401709402
7(bytes) overhead 56word(112bytes):::::::::0.9411764705882353
7(bytes) overhead 57word(114bytes):::::::::0.9421487603305785
7(bytes) overhead 58word(116bytes):::::::::0.943089430894309
7(bytes) overhead 59word(118bytes):::::::::0.944
7(bytes) overhead 60word(120bytes):::::::::0.9448818897637795
7(bytes) overhead 61word(122bytes):::::::::0.9457364341085271
7(bytes) overhead 62word(124bytes):::::::::0.9465648854961832
7(bytes) overhead 63word(126bytes):::::::::0.9473684210526315
7(bytes) overhead 64word(128bytes):::::::::0.9481481481481482
7(bytes) overhead 65word(130bytes):::::::::0.948905109489051
7(bytes) overhead 66word(132bytes):::::::::0.9496402877697842
7(bytes) overhead 67word(134bytes):::::::::0.950354609929078
7(bytes) overhead 68word(136bytes):::::::::0.951048951048951
7(bytes) overhead 69word(138bytes):::::::::0.9517241379310345
7(bytes) overhead 70word(140bytes):::::::::0.9523809523809523
7(bytes) overhead 71word(142bytes):::::::::0.9530201342281879
7(bytes) overhead 72word(144bytes):::::::::0.9536423841059603
7(bytes) overhead 73word(146bytes):::::::::0.954248366013072
7(bytes) overhead 74word(148bytes):::::::::0.9548387096774194
7(bytes) overhead 75word(150bytes):::::::::0.9554140127388535
7(bytes) overhead 76word(152bytes):::::::::0.9559748427672956
7(bytes) overhead 77word(154bytes):::::::::0.9565217391304348
7(bytes) overhead 78word(156bytes):::::::::0.9570552147239264
7(bytes) overhead 79word(158bytes):::::::::0.9575757575757575
7(bytes) overhead 80word(160bytes):::::::::0.9580838323353293
7(bytes) overhead 81word(162bytes):::::::::0.9585798816568047
7(bytes) overhead 82word(164bytes):::::::::0.9590643274853801
7(bytes) overhead 83word(166bytes):::::::::0.9595375722543352
7(bytes) overhead 84word(168bytes):::::::::0.96
7(bytes) overhead 85word(170bytes):::::::::0.96045197740113
7(bytes) overhead 86word(172bytes):::::::::0.9608938547486033
7(bytes) overhead 87word(174bytes):::::::::0.9613259668508287
7(bytes) overhead 88word(176bytes):::::::::0.9617486338797814
7(bytes) overhead 89word(178bytes):::::::::0.9621621621621622
7(bytes) overhead 90word(180bytes):::::::::0.9625668449197861
7(bytes) overhead 91word(182bytes):::::::::0.9629629629629629
7(bytes) overhead 92word(184bytes):::::::::0.9633507853403142
7(bytes) overhead 93word(186bytes):::::::::0.9637305699481865
7(bytes) overhead 94word(188bytes):::::::::0.9641025641025641
7(bytes) overhead 95word(190bytes):::::::::0.9644670050761421
7(bytes) overhead 96word(192bytes):::::::::0.964824120603015
7(bytes) overhead 97word(194bytes):::::::::0.9651741293532339
7(bytes) overhead 98word(196bytes):::::::::0.9655172413793104
7(bytes) overhead 99word(198bytes):::::::::0.9658536585365853
7(bytes) overhead 100word(200bytes):::::::::0.966183574879227
7(bytes) overhead 101word(202bytes):::::::::0.9665071770334929
7(bytes) overhead 102word(204bytes):::::::::0.966824644549763
7(bytes) overhead 103word(206bytes):::::::::0.9671361502347418
7(bytes) overhead 104word(208bytes):::::::::0.9674418604651163
7(bytes) overhead 105word(210bytes):::::::::0.967741935483871
7(bytes) overhead 106word(212bytes):::::::::0.9680365296803652
7(bytes) overhead 107word(214bytes):::::::::0.9683257918552036
7(bytes) overhead 108word(216bytes):::::::::0.968609865470852
7(bytes) overhead 109word(218bytes):::::::::0.9688888888888889
7(bytes) overhead 110word(220bytes):::::::::0.9691629955947136
7(bytes) overhead 111word(222bytes):::::::::0.9694323144104804
7(bytes) overhead 112word(224bytes):::::::::0.9696969696969697
7(bytes) overhead 113word(226bytes):::::::::0.9699570815450643
7(bytes) overhead 114word(228bytes):::::::::0.9702127659574468
7(bytes) overhead 115word(230bytes):::::::::0.9704641350210971
7(bytes) overhead 116word(232bytes):::::::::0.9707112970711297
7(bytes) overhead 117word(234bytes):::::::::0.970954356846473
7(bytes) overhead 118word(236bytes):::::::::0.9711934156378601
7(bytes) overhead 119word(238bytes):::::::::0.9714285714285714
7(bytes) overhead 120word(240bytes):::::::::0.97165991902834
7(bytes) overhead 121word(242bytes):::::::::0.9718875502008032
7(bytes) overhead 122word(244bytes):::::::::0.9721115537848606
7(bytes) overhead 123word(246bytes):::::::::0.9723320158102767
7(bytes) overhead 124word(248bytes):::::::::0.9725490196078431
7(bytes) overhead 125word(250bytes):::::::::0.9727626459143969
7(bytes) overhead 126word(252bytes):::::::::0.972972972972973
7(bytes) overhead 127word(254bytes):::::::::0.9731800766283525
7(bytes) overhead 128word(256bytes):::::::::0.973384030418251 -
reduced math time down further by about 50,000 microseconds on uno
09/09/2019 at 07:11 • 0 commentsshaved another 50,000 microseconds off of math time for arduino 328p chip. it does however use 4 more bytes. as it requires another float to store the fractional result
i recently posted a a project about different optimization techniques here
https://hackaday.io/project/167533-math-optimizations-with-specific-tasks-and-ranges
one of my guide rules was whenever possible fractionally multiply instead of divide.
i have broken down the math to its basics, so i can simplify and cache.
i have determined that the first sub_calc_To (my version of the math) still eats up 500,000 microseconds time to process.
this is how the code looks after it has been modified to be simpler
![]()
and here is how it looks now with a time savings of 50,000 microseconds
there are some notes and references to the data in the comments. this is more for me.
any way the division has been cached, and the result turned into a fraction, and applied two times.
notice the above version divides twice. the version below divides 1 time. division is at minimum 4 times slower and in many cases a lot longer. multiplication even with floats is faster. this is because even the most basic cpus contain logic for multiplication usually just an extended length register. division is harder beast to incorporate hardware for, so it is done in software very slowly.
![]()
removing the division to speed things up. we still need to do it once however. now i just need to check to see if this value happens more than one time! i have noticed that the time it takes to solve increases when more heat is on the cells. i'll look into it more.....
-
trying to resolve the bottleneck on cpu processors for cycles improvements.
09/09/2019 at 02:27 • 0 commentsi'm using Arduino IDE 1.8.9. my main focus is speed on the uno and nano but this also improves performance on any cpu.
i have broken down problems, created fast math optimizations and cached ares for better performance. now it is time to look at the engine closer:
these two areas eat all the cpu cycles on nano. higher clock rate on any processor will improve performance
sub_calc_irData 145,000
the first sub_calc_To calculation 500,000
i have troubleshoot_optimize set to true, it outputs some more stuff so i can make things work faster.
i tried moving one of the progmem tables to ram. it only reduce cycle counts by 5000 microseconds
this is caching the 1 /2^x table in ram and the 2^x table in ram only save about 5000 microseconds over 768 reads. this is below the variation of +/- 10,000 per frame 760,000 micro seconds on arduino nano so it could just be noise. moving on to next area. the progmem tables are fast enough. they are faster than the switch(x) {..} i had used earlier.
below is a sample frame using ram cached values. the process time goes up and down depending on pixel information.
set Replace_detailed_calc_with_image_data false will allow testing of detaled To mode output of pixels.
![]()
just for comparing here is with the image mode of sensor read
set Replace_detailed_calc_with_image_data true will allow testing of image mode
![]()
this tells me two things
1) the detailed calcs in the To eat up around 300000 microseconds on uno. teense-lc runs faster
2) that there is some other part of the system functions eating up a lot of cycles.
3) that there is something outside of the math calc of the temperature that is using a lot of cpu time
in the MLX90640_CalculateToRawPerPixel(uint16_t pixelNumber ) my own version of the routine that returns 1 pixel at a time to help save ram on processor and utilize storage on sensor, there are several areas of note for cpu cycles
also i moves some of the math values at the start down further so i could easily make sense of caching them.
what i did to look at areas of function where things slow down was
return 5; so it exited the function and returned something in this case 5. later on after some math functions are done i return some of those results. then time how long it takes to complete the function to that point.
my code in this function is really dirt right now. i'm trying to simplify and make redundant processes improve. so everything is being broken down
this is on nano. faster cpu will have different results.
running thru all of To function ~760,000 cycles +/- 10000
i took the line that reads the ram info and had the number replaced with 1.5
sub_calc_irData = 1.5;//RamGetStoredInLocal(pixelNumber) ;
this lowered the time per frame about 20,000 cycles. seems the read currently is not the culprit
i then had it again take values from ram and turned off my i2c cache reads. it took 840,000 cycles to complete. turning off the store of i2c cache slowed it down 80,000 cycles. so the cache is helping. currently i cache 64 i2c reads. and use about 128 bytes of ram for it.
the memory reads with cache enabled per cell is 20,000 cycles. this is acceptable and is not the main bottleneck
i then took out the serial write time, by disabling serial output but still loading its buffer. it only takes 690,00 cycles to complete a savings of ~60,000 microseconds. caching of serial is for output to update to screen faster. so it will be redone anyways but it is not the main bottleneck
then i did it without sending serial data except for time counts output and turned off doubleres
without double res and without serial send of text it is 640000 microseconds.
this is useful info it states that double resolution currently takes about 50,000 microseconds to complete and this is ok as it needs to pull ram values and store its own cache of ram. i'll see if i can make it work better, but 50,000 for 4 memory reads seems really good when 1 memory read is 20,000. this also means that the i2c data cache is working and that the buffer cache in the doubleres is improving performance.
so on average a full 768 cells penalty for the following currently takes
50,000 to 60,000 nonfloat vs float cycles for the double res and it outputs 3072 pixels spaces
serial output to screen takes 50,000 (when output 3072 pixels ascii text graphics
ok, so now i removed the To loop for testing its cpu time. this is useless other than testing its time
MLX90640_CalculateToRawPerPixel(uint16_t pixelNumber ) {
return 5;//just number i used.
... all other data not process }
total process time is about 90,000 microseconds....
so all my work should now focus in this function and its processes
the first half of the To functions are already cached and only updated at the first pixel read.
it is something like this if (pixelNumber == 0){//we only do this on start of page
i disabled this cache part to see what times would be if each pixel processed all the raw values
it takes 1300000 microseconds. about twice as long. so this caching of data is working.
timing of data to page cache is 95,000 microseconds. so 5000 more
![]()
so this top part is already really efficient. this entire part only takes 5000 microseconds for processing all 3072 interpolated pixels. (this part only processes the raw pixels.) the entire process from capture to processing and outputting to display takes 95,000. this will be a concern later but it is not what is eating up cycles. you'll notice i have some caching going on. although since this loop is run once per 768 it might not have been needed.
I found the first major slow down in the process it is here and it takes 210000-65,000 cycles to complete.
at this point of the function it takes 210,000 to complete. before the code i have below it takes only 65,000. it makes sense it is a math intensive area with multiplication.
![]()
it is this here: it takes 145000 microseconds to run on nano currently
sub_calc_irData = sub_calc_irData - ExtractOffsetParametersRawPerPixel(pixelNumber)*
(1 + ExtractKtaPixelParametersRawPerPixel(pixelNumber)*(sub_calc_ta_MINUS_25))*
(1 + ExtractKvPixelParametersRawPerPixel(pixelNumber)*(sub_calc_vdd - 3.3));and now for the next large cycle time item: 500,000 microseconds
![]()
i was curious why this line didn't take any cycles:
sub_calc_irData = sub_calc_irData - tgc * sub_calc_irDataCP[sub_calc_subPage];
the answer is it is removed from compiler. tgc normally is set to 0. document melexis section 11.1.16.
wasn't sure why this wasn't taking time either
sub_calc_Sx = SimplePow(sub_calc_alphaCompensated, 3) * (sub_calc_irData sub_calc_alphaCompensated * sub_calc_taTr);
sub_calc_Sx = Q_rsqrt(sub_calc_Sx) ;
sub_calc_Sx =sub_calc_Sx * ksTo[1];ill look into it but the big culprit of processing time is the following below.
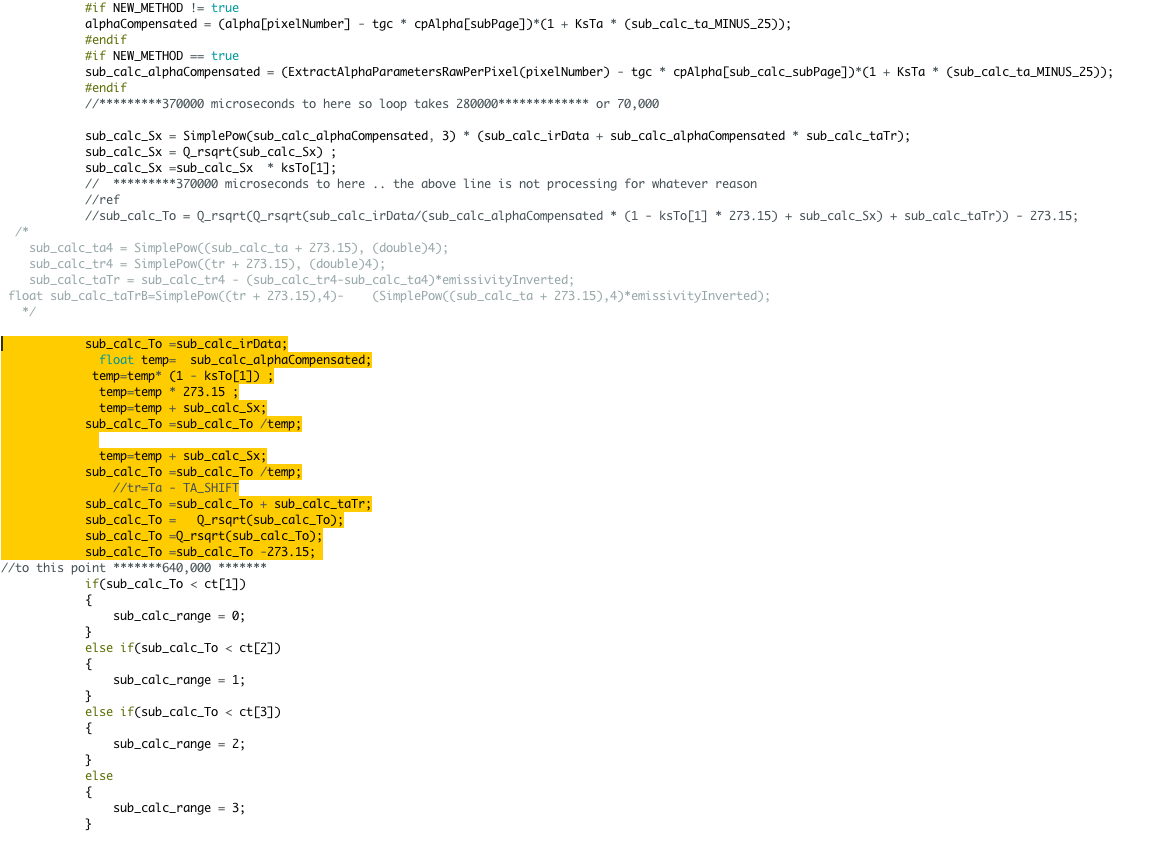
i have broke it down into sections this entire process is the complex equation for To calc.
this section alone takes 500,000 cycles to complete
sub_calc_To =sub_calc_irData;
float temp= sub_calc_alphaCompensated;
temp=temp* (1 - ksTo[1]) ;
temp=temp * 273.15 ;
temp=temp + sub_calc_Sx;
sub_calc_To =sub_calc_To /temp;
temp=temp + sub_calc_Sx;
sub_calc_To =sub_calc_To /temp;
//tr=Ta - TA_SHIFT
sub_calc_To =sub_calc_To + sub_calc_taTr;
sub_calc_To = Q_rsqrt(sub_calc_To);
sub_calc_To =Q_rsqrt(sub_calc_To);
sub_calc_To =sub_calc_To -273.15;so the two things i'll try to optimize further are
sub_calc_irData 145,000
the first sub_calc_To calculation 500,000
-
let my mistake make you 20$.
09/08/2019 at 11:26 • 0 commentsI had the pleasure of someone who claims to be from melexis management asking me to verify what i though was an error in the documentation of the melexis 90640 documentation. this person was very professional, and i think they just registered on github so that they could respond to me. lol.
If all you want is the 20$ read last paragraph. i'll pay it in paypal to whoever can confirm errors. not everyone just the first person. I don't have a tree growing cash in my yard, so 20$ total. thats it. thats all.
In all it ended up I could not verify what i said about the documented errors. I could not find them again, and it is possible that It could have been me. read thru the document, and i think you will understand. there is a lot going on, things are very similar, and so on.
anyone who has read any of my blogs, or seen my videos or read my project logs, know that when i have made a mistake, i like to share it, because we all learn from them. even if i'm a little embarrassed. no process or design can ever be perfect, and looking at things from the standpoint that things can always be made better and or improved within reason of resources and ability, it opens one self up to feedback for corrections. even though this sensor blog with over 27 logs has only received about 1.8k views.
I am always happy to improve processes, and i felt it was fair of them to ask me to provide corrections, since i said in forum space that i though there were errors. I spent what i thought was a reasonable time going thru the documentation again.
here is the documentation i referenced:
https://cdn.hackaday.io/files/1614996909573216/MLX90640%20driver.pdf
It takes a long time to go thru the documentation. it is easy to verify different documents side by side, but the issues i thought were in section 11, and section 11.2.2.2 that showed an example of sensor setup.
I have apologized to the manager of the melexis company, and told them if i did find errors i would let them know directly. In my comments i also offered 20$ of my own money to anyone that is the first to find errors. i'll pay thru paypal.
if anyone wants to read the comments they are here:
https://github.com/sparkfun/SparkFun_MLX90640_Arduino_Example/issues/7
If it no longer is avail i have a pdf of comments i'll upload. i was mainly trying to let sparkfun know that i have a version of code that works on the 328
-
some math changes and i2c buffering. better performance
09/07/2019 at 19:06 • 0 commentshere is the output of the data from increased performance. the version currently uploaded and in /updates folder is https://github.com/jamesdanielv/thermal_cam_mlx90640
it includes the start of math optimizations and a i2c cache. the i2c cache has less of a boost than i thought it would so i'm looking into it. if you were to read thru the MLX90640_CalculateToRawPerPixel section in the MLX90640_API.cpp it would look messy right now. i'm breaking down the math problems to the basic blocks, and looking for ways to cache areas and solve others more quickly.
also from the better performance there seems to also be noise introduced. this is normally filtered as part of the gain and voltage calc, so i suspect that i need to sync the frame data w the ram info. also it is about time i have the device run in step mode again. this will probably solve it as well. so this version has more noise, but it will be cleaned up. adding a capacitor across leads going to sensor should help as well.
below. there is a built in delay between frames, but look at how much faster data is sent to display. this is on teensy-lc that is lacking special math ability. optimizations also have a 2x performance boost on arduino. I'm still working on improving the serial output to terminal. teensy-lc does not use serial data.
before i started focusing on optimizations:
after start of optimizations:
mlx90640 sensor works w 800 bytes
Everywhere i read people are excited to get mlx90640 working. here are examples using arduino w 800bytes ram, and 1k with calibrated DEG C