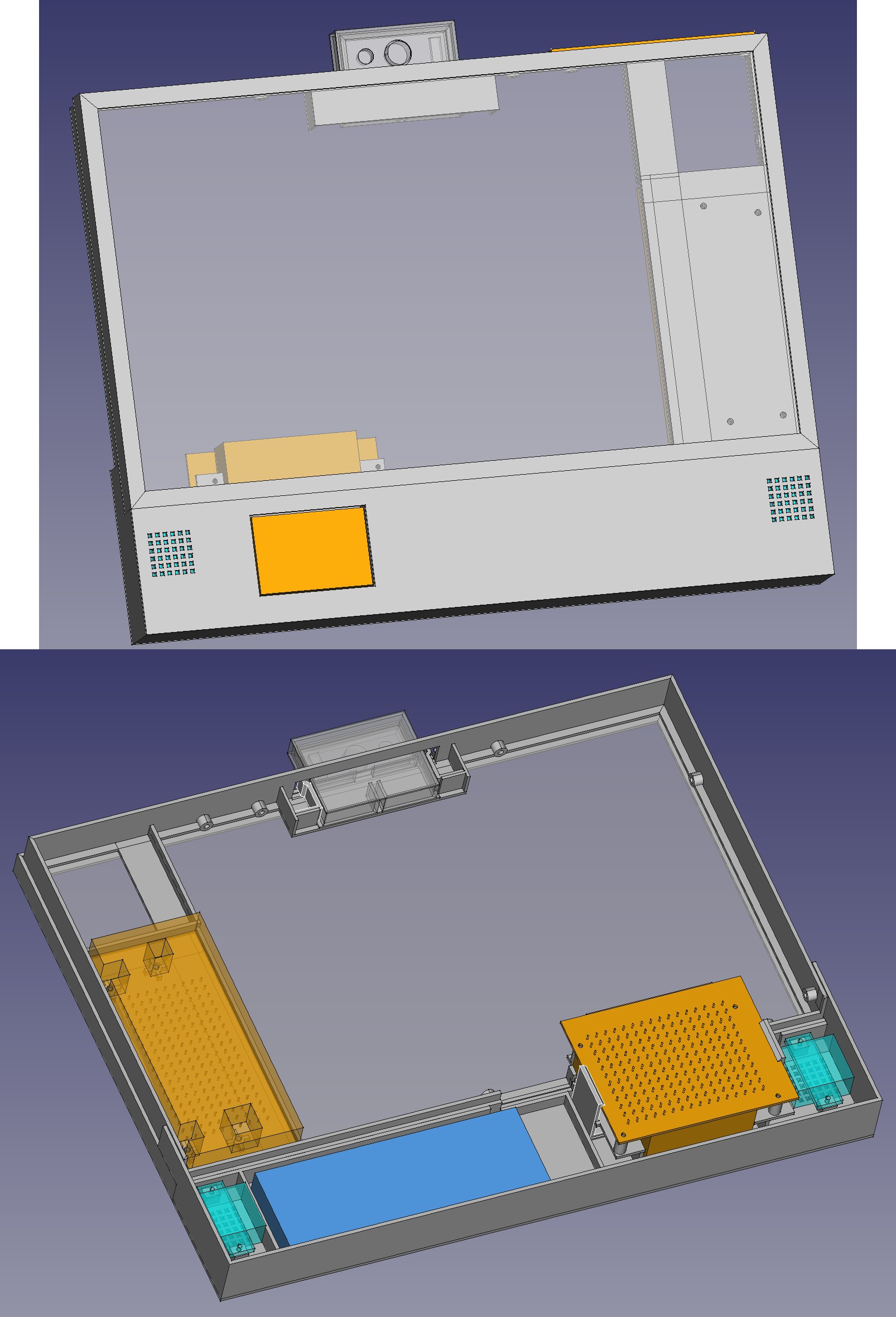
Stacking the LCD & electronicals side by side started gaining favor. The mane reason is it's always going to be on the floor. The electronicals would give it a pedestal. The problem is transporting it.
The thinnest possible LCD thickness results in a gigantic base with the battery on top of the HDMI. There's also a speaker which needs to go in the base.
A compromise thickness has the jetson, speaker, & battery on the bottom. The HDMI & buck converters go behind the LCD. The trick is the jetson has to be upside down for the ports to be accessible. The total bottom extension would be the width of the battery or 50mm. This might be the most efficient layout.
The imac to this day still has a large space under the screen even though it has no battery & it's razor thin.
The imac doesn't get any love anymore. There are few reviews & teardowns. Anyone wanting that level of computing power is using a macbook air. It's going the way of the ipod, but it represents a cheap way of integrating a display & confuser.
The jetson going all out is going to suck 1A at 12V. The monitor is going to suck another 1.5A. It'll last maybe 90 minutes at full frame rate. $1000 gaming laptops seem to be hitting 60 minutes. The lion kingdom's 5 year old one had a reduced frame rate on battery power & was prone to overheating. Another one from 2004 was the same. The internet isn't going to say if the newest ones are any better.
Verified the HDMI board has an amplified speaker output & it's quite loud. This is used by the rep counter.
A lion can model 1 module per day at most. The mane problem is splitting it up into pieces that fit on the printer. The webcam is right where it would ideally be split. That top edge should be split into 3 sections.
The split for the bottom section should be next to the LCD rather than the bottom of the LCD.
The general idea was a tablet thing with detachable modules.
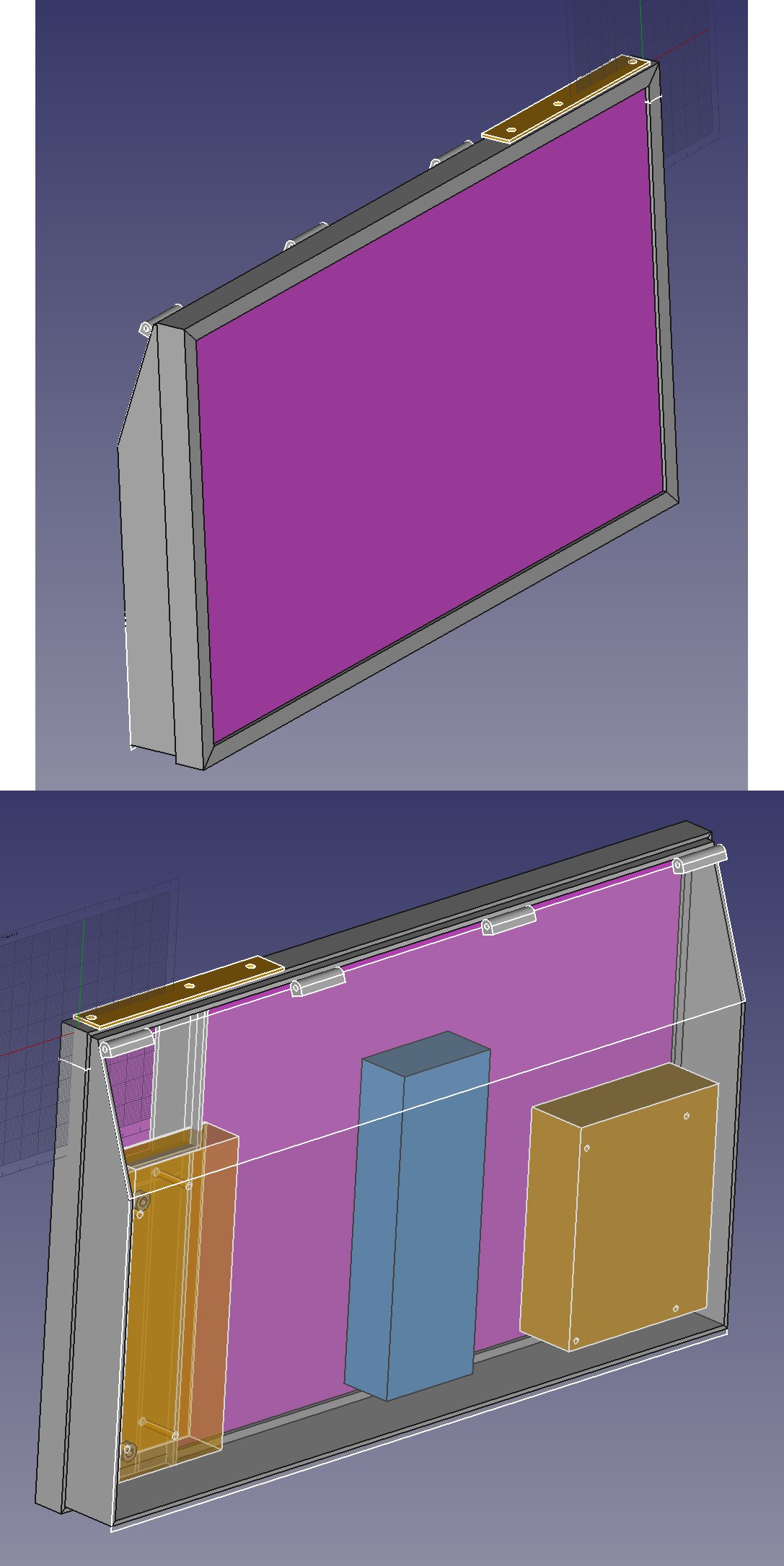
The permanent part of the tablet would be the HDMI driver, buttons, & a 12V splitter. The splitter feeds the LCD, confuser, & flash.
The jetson + buck converter would be a detachable module which also went in the truck. The IR/servo board would be another module. The webcam for rep counting would be a module. All the ports could be recessed from the side. There could be a right angle HDMI connector. The battery would have to be external.
The framework laptop uses sliding rails with a spring loaded button to attach modules so that would be the goal. The modules would slide in from the rear & PLA springs would lock them in. There would be a big rear panel covering everything. It would swing on a hinge on top & double as a stand. The stand needs to work on wood as well as carpet.
An unsatisfying 1st attempt looked like lunchbox or a suitcase.
The dimensions are manely imposed by the battery & heat sink. They bring it to 48x363x215mm. An ordinary laptop would have been half the size. It'll definitely weigh less than a laptop but be flimsier. The only advantages are the cost & reuse of the module in the truck. A laptop would be over $1000 but could also train the network.
The mane turnoff from a laptop is the amount of money required to do just 1 thing & not support the truck. It's just needed for rep counting & model shoots. Manely, it's just rep counting.
Never did a generation that lived 40 years ago expect confusers to have no speed increase for 3 years while increasing in price, yet meme currency achieved the impossible.
After 3 years out of production, a product page showed an offer too good to be true. By applying for another amazon credit card, they'd reduce it to what it was 3 years ago: $100.
It was a scam. You're not getting that kind of confusing power for $150 anymore. There was another updated listing in China.
Of course, a lion who is part monkey can't let go of the fruit. Now a 3 week delay wasn't too much to find out if the Chinese listing was also a scam. The justification was manely to stop using the junk laptop lions had used daily since 2018 for rep counting. Pay now & maybe you'll get your order in a month.
Bezos's $50 discount was refunded as a gift card balance so the total cost was still $100. Lions had other Bezos credit cards in the past. It seems they eventually expire & don't get renewed, at which time you can apply for another one & get another discount.
To be fair, the $100 4GB Jetson nano never shipped until 2023. They only had a $50 2GB version 3 years ago.
2 weeks later, it was real. The mane trick is the SDK image had to be written to a 32 gig card. It didn't work with a 64 gig card & it's too big for a 16 gig card. It might need a manually created partition table to use a 64 gig card. The mount command works with the raw image when providing -o offset= but not when using the partition table.
Setup has to be done with the ttyACM device. It's a pain. 1st, you have to view the output from UART RXD, UART TXD to find out when it has booted. Then you have to connect to ttyACM0 & hit enter a few times.
No terminal program could render the text. It was a matter of reading a terminal capture file to read the prompts & planning on fixing any errors from the command line.
Once setup, logins are provided on all the UARTs & ttyACM, but only UART RXD, UART TXD allows a root login.
Most animals connect a keyboard, mouse, & monitor to use the graphical setup.
Then came disabling a bunch of programs by renaming them .bak.
The mane thing is verifying it really has 4GB. By default, it has some kind of compressed swap space in RAM by using a /dev/zram device. Having the CPU & GPU share the same RAM doesn't leave as much room as you thought. Sadly, it's only useful for running neural networks but not training them. It shows how insanely expensive AI has been & probably always will be.
Pretty common project, but once again, he uses a computer which was discontinued 5 years ago & now costs $200. The results are better tracking of teddy bears than lions.
The future depends on low cost analog solutions more than neural networks. Low cost neural networks are never going to happen. They're going to be relegated to $100,000 cars.
Nowadays, external GPUs are another option gaining prominence over jetson nanos. Unlike PCIE over an M2 connector, EGPUs encapsulate PCIE in a thunderbolt or USB variant which is fast enough to do the job. Not sure what happens when the connection glitches.
The GPD Win Max 2 is a $900 laptop with EGPU support. It's hard to beat the good old jetson even at $300. It's a lot of money & space for just a tracking camera, but maybe not if inflation continues at 10% for another 30 years.
This $700 package would be the standard way of building an embedded neural network, nowadays. It doesn't show the power supply.
It's amazing how much the cost of computing rose in the last 5 years. The skydio represented a time when low cost neural networks were going to become ubiquitous, using only a $50 confuser back in 2018. It was a different age.
What's needed is a bigger application besides rep counting & tracking to justify the higher cost.
Canon's entry in the tracking camera space is the Powershot Pick, a very low quality OBSBOT webcam clone. Kind of a reversal of roles that Canon makes toys while DJI makes the only trackers which support a DSLR.
It uses the same low power face tracking & object tracking as the others.
Embedded GPUs have gone the way of the dinosaur, but there was a guy who got a single board confuser to support a PCI card GPU. This one was a
The stock drivers & games seemed to work. All in, it was at least $600 with no guarantee CUDA will work. A vintage jetson can actually be bought for under $300.
A PCI card is a lot more confusing power than the lion kingdom's ancient laptop, but the system wouldn't be as portable as either the laptop or vintage jetson.
There are some less portable mini PC's which use 19V laptop power supplies. The $600 elitemini B550
conceptually has a purpose built dock for a PCI GPU but it's not manufactured. Of course, the lion kingdom can't afford any of these options, but the portable confusing power is out there.
Trying it with some sacrilegious videos playing on a monitor, the mane point is it falls apart when 2 humans are close together in a scene. There's a lot more noise in the positions. The accuracy is definitely worse than when tracking a single lion standing up. It would be constantly moving around like an unstabilized phone cam.
The windowing algorithm creates a lot of noise & causes the hits to move around even when the video is paused.
Normally, it only detects 1 of the 2 humans or it detects both humans as a single very noisy hit. It probably detects only 1 human when they're together & the hit oscillates between the 2 humans.
The most desirable horizontal body positions aren't detected at all. It's a bigger problem in practical video because most of the poses are horizontal.
Lowpass filtering & optical flow could suppress some of the noise, but the servos already provide a lot of lowpass filtering. The lion kingdom has long dreamed of running a high fidelity model at 1fps & scanning the other frames with optical flow. This would entail a 1 second lag for that high fidelity model. Every second, after getting an inference, it would have to use optical flow to fill in 1 second of frames to catch up to the present. It might be doable with low res images.
Face tracking might give better results, but it would lose the ability to center on the body.
The Intel Movidius is the only embedded neural engine still made. It's a lot more expensive than the equivalent amount of computing power 3 years ago, but that might be a fair price if computing power is permanently degraded.
The only useful benchmark lions could find showed it getting 12fps on an undisclosed efficientdet model. It can be implied from the words "up to 12fps" in his sales pitch that it's the fastest efficientdet model. That's 50% faster than the fastest efficientdet in software, not really enough to improve upon the quality seen.
All GPU systems are all or nothing. They can't split the work between the CPU & the GPU. They could allow a 2nd face detection model or optical flow to be run concurrently on the CPU. That would give more like a 250% increase.
The best rule with efficientdet_lite0 has been hard coding the number of animals in frame & making sure that number is always visible so it doesn't get false positives. Tracking just the highest score would oscillate between 2 animals. Since lions are poor, testing would require either printing out a 2nd animal or just testing with 1 animal & living with errors.
Been finding efficientdet to be not accurate enough to have any deadband. The mane rule has been to keep the top of the box 7% from the top of the frame with no deadband. If the total height of the box is under 75% of the screen height, center the entire box in the frame regardless of head position.
Minimum distance from the top must be greater than the deadband or it won't tilt up. Another problem is if the box is under 75% but the head is above the frame, it won't tilt up in some cases. That might be a matter of deadband. If the difference between 75% & 7% is too low, the box will oscillate between being 75% of the screen height & 7% from the top.
Most of the time, the box is the full frame height, so it uses the head rule. To get under 75% of the screen height, the error rate has to go up.
Ideally, efficientdet could be trained on videos which have been labeled with COCOv5, but all the videos with the desired body positions are shot in sleezy hotel rooms & they're very addicting to edit. The neural net needs a wide variety of backgrounds besides hotel rooms to isolate the human forms.
5 hours on the GTX 970M yielded a new model trained just on hotel videos. It was a total failure compared to the COCO training set.
Animals have long dreamed of software that could synthesize unlimited amounts of a certain type of video. That's basically why there are so many attempts at making synthetic videos which are so bad, they're called neural network dream generators. The best we can do is software that points the camera.
The lion kingdom believes the pose tracker can run fast enough on a raspberry pi if it's reduced to tracking just 4 keypoints. It currently just uses head, neck, hip, & foot zones to drive camera tilt. These are fusions of 3-6 keypoints. 1 way is to reduce the movenet_multipose model itself to 4 keypoints. Another way is to try training efficientdet_lite on the 4 objects for the 4 keypoints.
The mane point of the 4 keypoints is tracking when the complete body isn't visible. A full body bounding box can't show if the head or the feet are visible & can't detect anything if it's too close.
Sadly, there's no source code for training the fastest model, movenet_multipose. There's source code for another pose estimator based on the COCO2017 dataset:
Key variables are defined in config.py: NUM_KP, NUM_EDGES, KEYPOINTS
1 keypoint applies to both sides. The other 16 have a left & right side which seem to be unnecessary.
The mane problem is consolidating multiple keypoints into 1. It's looking for a single point for every keypoint & COCO defines a single point for every keypoint instead of a box. Maybe it can accept an average point in the middle of multiple keypoints or it can accept the same keypoint applying to multiple joints in different images.
It's still a mystery to lions how the neural network goes from recognizing objects to organizing the hits into an array of coordinates. There's not much in model.py. The magic seems to happen in resnet_v2_101, a pretrained image classification model which presumably knows about the heirarchy of keypoints & persons. The results of the image classification get organized by a conv2d model. This seems to be very large, slow process, not a substitute for movenet.
Defining tensorflow models seems to be a basic skill every high school student knows but lions missed out on, yet it's also like decoding mp3's, a skill that everyone once knew how to do but now is automated.
The lion kingdom observed when efficientdet was trained on everything above the hips, it tended to detect only that. If efficientdet was trained just above shoulders & below shoulders, it might have enough objects to control pitch. It currently just has 3 states: head visible but not feet, feet visible bot not head, both visible. It can probably be reduced to head & body visible or just body visible. If head is visible, put it in the top 3rd. If head is invisible but body is visible, tilt up.
The mane problem is training this dual object tracker. Openpose could maybe label all the heads & bodies. It's pretty bad at detecting sideways bodies. The head has to be labeled from all angles, which rules out a face detector.
There's a slight chance tracking would work with a general body detector. Fuse the 2 largest objects. It would tilt up if the object top was above a certain row. Tilt down if the object bottom was above a certain row & the object top was below a certain row.
The mane problem is the general body detector tiles the image to increase the input layer's resolution. It can't tile the image in portrait mode.
There was an attempt to base the tracker on efficientdet_lite0 tracking a person. It was bad. The problem is since there are a lot more possible positions than running, it detects a lot of false positives. It might have to be trained using unholy videos. Another problem is the tilt tends to oscillate. Finally, it's become clear that the model needs to see the viewfinder & the phone is too small. It might require porting to Android 4 to run on the lion kingdom's obsolete tablet or direct HDMI on the pi with a trackpad interface.
The best results with the person detector came from just keeping the top of the box 10% below the top of the frame with a 5% deadband. There's not enough information to have it center the subject based on the paw position. A full pose tracker does a much better job than a person detector at composing the shot. So far, it's not worth paying for a photo shoot.
 lion mclionhead
lion mclionhead