Ken Yap
Ken Yap-
How the SDCC register allocator works
06/09/2020 at 13:21 • 0 commentsOk, this is subject to amendment, but I think I understand how the register allocator in SDCC works.
I did not find any score assignments to alternative code generation paths. In retrospect, this was to be expected as usually there is just one and at most a small number of ways a particular operation can be done. If the code calls for an arithmetic shift left, you can implement this with the arithmetic left shift operation or alternatively by add. And you see this reflected statically in the code generator, the programmer choses which instruction is better for a given situation. But if the code calls for an unsigned shift right, you just have to use the logical shift right instruction because there is no cheap divide by two instruction.
What the allocator does is try to find the best registers to leave intermediate results at every stage. It does this by doing a dry run pass over the iCode and optimising for a measure. In the case of the SDCC, which is targeted at Small Devices, the measure is code size.
So what the code generator writer has to do for each mapping from an iCode to machine instructions is to cope with the previous state. If the previous iCode left the intermediate result in register C and you now need the result in register L for the current iCode, you generate a move. If it's already in L, then you don't generate a move. The allocator will then, if all other things are equal, prefer to leave the result in L, for the previous iCode. Similarly if there is a register with an intermediate result to be preserved for later use you generate a spill which will increase the code size. So the act of providing alternate paths with different costs will make the allocator self-optimise in the dry run pass. That explains why in my dumps of the iCode, usually the result was left in C, as C is the first candidate considered and I provided no preference gradient. What Philipp Klaus Krause showed in his thesis is that this allocation can be done in polynomial time rather than a worst-case exponential time.
-
Added support in sdasz80 for 8085
06/03/2020 at 16:09 • 0 commentsFollowing a suggestion by Alan Cox I looked at the 8085 undocumented instructions. They actually make the 8085 a halfway decent target for stack argument passing, as well as handling subtraction and right shifts of 16-bits. So I added support to those instructions in sdasz80 but with Z80 style mnemonics as the first step.
If I ever target the 8085 I'm inclined to start the code generator from scratch as the hack of the Z80 code generator for 8080 could be unmaintainable even if I get the right shift working. Many of the library routines require reentrancy so it will be necessary at some point to turn back on stack argument passing and suffer the horrible inefficiency and wake up latent bugs. ☹️
-
Working on the code generator again
06/03/2020 at 16:01 • 0 commentsAfter a long hiatus, I've found time to look at this again.
The first problem is still how to interface the builtin routines that do the right shifts that are too hard to do inline. The additional builtin routines expect inputs in particular register (pairs) and leave the output in a particular register (pair). However the code leading up to the call and after the call don't know this. It doesn't seem to be a matter of tellng the code generator we need those registers, it appears to be already decided at an earlier stage, as this dump of the code generated by the C statement
uchar0 = (uchar0<<1) | (uchar0>>7);
shows:
181 ;rotate4.c:28: uchar0 = (uchar0<<1) | (uchar0>>7); 182 ;ic:2: iTemp0 [k3 lr3:4 so:0]{ ia0 a2p0 re0 rm0 nos0 ru0 dp0}{signed-char fixed}[a ] = (signed-char fixed)_uchar0 [k2 lr0:0 so:0]{ ia0 a2p0 re0 rm0 nos0 ru0 dp0}{unsigned-char fixed} 183 ; genCast 184 ;fetchLitPair 000F 21r05r00 [10] 185 ld hl, #_uchar0 0012 7E [ 7] 186 ld a, (hl) 187 ;ic:3: iTemp1 [k4 lr4:6 so:0]{ ia0 a2p0 re0 rm0 nos0 ru0 dp0}{signed-char fixed}[a ] = iTemp0 [k3 lr3:4 so:0]{ ia0 a2p0 re0 rm0 nos0 ru0 dp0}{signed-char fixed}[a ] << 0x1 {signed-char literal} 188 ; genLeftShift 0013 87 [ 4] 189 add a, a 190 ;ic:4: iTemp2 [k5 lr5:6 so:0]{ ia0 a2p0 re0 rm0 nos0 ru0 dp0}{unsigned-char fixed}[c ] = _uchar0 [k2 lr0:0 so:0]{ ia0 a2p0 re0 rm0 nos0 ru0 dp0}{unsigned-char fixed} >> 0x7 {const-int literal} 191 ; genI80RightShift 192 ; Dump of Right: type AOP_LIT size 2 193 ; Dump of Result: type AOP_REG size 1 194 ; reg = c 195 ; Dump of Left: type AOP_HL size 1 196 ;fetchPairLong 197 ;fetchLitPair 0014 21r05r00 [10] 198 ld hl, #_uchar0 0017 6E [ 7] 199 ld l, (hl) 0018 26 00 [ 7] 200 ld h, #0x00 201 ;fetchPairLong 202 ;fetchLitPair 001A 01 07 00 [10] 203 ld bc, #0x0007 001D F5 [11] 204 push af 001E CDr00r00 [17] 205 call sru1 0021 F1 [10] 206 pop af 207 ;ic:5: _uchar0 [k2 lr0:0 so:0]{ ia1 a2p0 re0 rm0 nos0 ru0 dp0}{unsigned-char fixed} = iTemp1 [k4 lr4:6 so:0]{ ia0 a2p0 re0 rm0 nos0 ru0 dp0}{signed-char fixed}[a ] | iTemp2 [k5 lr5:6 so:0]{ ia0 a2p0 re0 rm0 nos0 ru0 dp0}{unsigned-char fixed}[c ] 208 ; genOr 0022 B1 [ 4] 209 or a, cLlines 187 and 190 show that the intermediate result of the left shift by 1 is left in A. My generated call to sru1() doesn't know any of this and leaves its result in HL, when the result is expected in C to be ORed with the previous A, which gets destroyed in the routine.
To understand how the SDCC register allocator works, I turned to the papers published by its author Philipp Klaus Krause. The first is Optimal Register Allocation in Polynomial Time. In Compiler Construction - 22nd International Conference, CC 2013, Volume 7791 of Lecture Notes in Computer Science, pages 1–20. Springer, 2013. Also of interest is Bytewise Register Allocation in SCOPES '15: Proceedings of the 18th International Workshop on Software and Compilers for Embedded Systems. They are quite heavy reading but the take away for me is that the register allocator has to know the costs and requirements of my right shift routines that fill deficiencies in the 8080 instruction set. One idea would be to look at how specialsed instructions like mult that have no alternatives and only work with particular registers are handled.
For some simple cases of shifting right by a literal, we can use the existing generation of inline assembler instructions. Then an issue is how to have different allocation behaviour between the cheaper and more expensive cases.
At the same time I've updated the sources not pertinent to the 8080 to the most recent SVN version so as not to fall too far behind.
-
Validation
10/14/2019 at 00:31 • 2 commentsThis log may change as I understand better how it works.
Now we come to the key step which the backend must pass otherwise it's useless — checking that the code generated is correct. SDCC comes with a formidable suite of regression tests. The procedure is simple, compile a test program, run it in a simulator (sz80), and output messages for failing tests. The test programs look like this made up example:
i = 2; if ((i + i) != 4) error("Failed add");Of course a whole range of code from the simple up to the complex like pointer access is tested. A test harness runs all the tests and summarises the results. It should be automated so that continuous integration can check that a code change hasn't made things worse.
But how is error() implemented? We could make it equivalent to a printf(), but what if we aren't sure that we have a working printf()? The solution is to generate a trap instruction for the error() which is handled by the simulator and ensures that we always see output. Unless the program crashes, in which case the output won't match either.
As an aside, there are compiler options to output the original source lines and iCode as comments in the assembler code so when a test fails one can look at the generated code and work out what were the incorrect assumptions.
So TODO number 3 is to get the 8080 backend to pass the regression tests, and with various options. That sentence means a lot of iterated work!
That's the end of the logs for the moment. I just have to collect some round tuits, roll up my sleeves and work on the TODOs.
-
Runtime
10/09/2019 at 23:41 • 0 commentsA binary compiled from C needs some additional code to work. These are the runtime library routines. Typically they consist of utility routines such as character and string functions that many C programmers expect as part of the environment. Even in embedded environments a rudimentary stdio library may be provided that at the bottom calls a couple of routines, getchar() and putchar(), which must be provided by the developer for a particular embedded platform say by talking to a serial interface.
The library may also contain assist functions to do operations not supported by the processor, such as multiplication and division. In our case right shift routines fall into this category. Incidentally have you ever wondered how the user is prevented from writing C functions and global variables that may override and interfere with these assist functions and variables? Originally in Unix this was done simply by prepending an underscore (_) to every external symbol. In other words, the C programmer can only create symbols in the object files starting with underscore. Assist functions and variables do not start with an underscore so cannot be overriden. If the user writes in assembler to be linked with the objects from C, then there is no barrier. In that case the user is assumed to know what she is doing.
Other things in the runtime library are routines written in assembler for speed, for example block copies and compares, accessed for example via bcopy() and bcmp().
But the one thing the runtime library must contain is the startup module. Traditionally this was named crt0.o in Unix (C runtime zero). This module accepts control from the OS, or from the boot vector and sets up the registers as necessary for the payload to run. The program counter is of course taken care of when the startup jumps to the payload. Other registers that must be set up include the stack pointer, any segment pointers, and interrupt vectors, this last for embedded environments. The C environment also stipulates that unintialised variables must contain binary zero. These variables are stored in the BSS area, typically above the code and initialised variables (read-only in recent C standards), but below the heap. The stack typically extends downward from the top of RAM. So one of the jobs the startup must do is zero the BSS.
Since embedded environments vary, there is no one size fits all crt0. Typically the compiler package provides a standard crt0, but the developer is expected to take the source and customise for the hardware configuration that will be used. In SDCC, like in traditional C compilers, it is possible to tell the linker to omit the provided crt0.o and then the developer ensures that the first file handed to the linker is her customised crt0.o.
The runtime library contains a mix of C and assembler. Assembler is used where C cannot or efficiency is crucial.
So TODO number 2 is to take the assembler routines that are written in Z80 code and produce equivalents in 8080 code for the 8080 runtime library. As an example, the Z80 startup will use the Z80 block assign opcodes to zero the BSS. The 8080 code should do this the longer way.
-
Right, shift!
10/03/2019 at 20:51 • 0 commentsC supports bit operations on integers of various widths, including left and right shift. Unfortunately on the 8080, shifts are only supported on the accumulator and comes in two varieties, shift using and not using the carry bit. The former is needed for two byte (int) and four byte (long) shifts to carry the leaving bit from one byte to enter the next.
Left shift is the less troublesome operation and is already supported in the code generator for the general case which also works for the 8080. Some shifts can be turned into doubling operations as a single left shift is a doubling. Some shifts which are not powers of two can be more efficiently composed from two or more shifts instead of using a loop. Some shifts by multiples of 8 on multibyte data are just byte shifts.
Note that the above applies for shifts by constants. For a shift by a variable a loop needs to be generated. The case of shifting a constant by a constant should not happen as the compiler would have eliminated this by constant folding. This happens often due to macro expansion, less from the programmer writing it.
Right shift is harder because while you can add something to itself to double it, there is no corresponding opcode to halve something.
I was stuck here for months agonising over how to generate the (possibly unrolled) loops to right shift. Eventually taking the lead from the Amsterdam Compiler Kit, I decided to fob right shifts off to library routines. Perhaps later I might inline some simple cases like right shift by one. Get something working first.
A note here on efficiency: There are two aspects: code size and machine cycles. For code size, except in the simplest cases such as a shift by one on a byte, less instructions will be generated because a bunch of inline instructions is replaced by subroutine calls and returns. For machine cycles, there is the overhead of the call and return, but again, except for the simplest cases, the proportion of time spent in the call and return is not significant compared to the time doing the shifting as the shift gets larger. There is no stack variable access overhead as the library routines expect arguments in registers. (Reentrancy is not an issue as these routines are leaf routines.) Anyway as I wrote, get something general working first, then optimise as necessary.
Six routines are needed, for signed and unsigned shifts for char, int, and long. In signed shifts the sign bit is preserved. In unsigned shifts there is no sign bit. Operands are expected in registers. These routines were tested separately, but the backend routines to plug them into the code stream have not been completed. TODO number 1 Unfortunately there is scant documentation on the backend routines I need to call to go from the iCode (the internal representation of the C code) to assembler code. I just have to work it out by trial and error. ☹️
-
Modifying the backend
09/23/2019 at 22:25 • 0 commentsBy this time you're getting impatient and wondering when I'm going to hack the backend, in particular the monster file gen.c.
Did I study the file carefully and make surgical changes? Hahaha, I wish. What I actually did was run the compiler across the selection of test programs in the regression directory, note any illegal code produced and change the generator to fix, and repeat. (It turns out that the regression directory isn't the real test suite but nonetheless as good a place to get my hands dirty as any.)
The changes fell into several categories:
Relative jumps JR had to be changed to absolute jumps JP. And DJNZ had to be done the long way. Straightforward.
Bit operations have to be done the long way by using the accumulator as an intermediate register. Fortunately the accumulator is regarded as volatile. Some bit tests, e.g on the top bit can be done with testing for negative instead of using AND.
Moves and compares that used the block instructions have to be done the long way.
Right shifts, as Alan Cox astutely noted years ago, have to be done the long way as the 8080 is terribly incapable in this area. All the remaining unhandled cases fell into this category. This deserves an entire log to itself, coming up.
-
Function parameter passing convention and reentrancy
09/06/2019 at 14:52 • 0 commentsWe normally don't think hard about how parameters are passed to functions (a procedure is simply a function that doesn't return a result, or returns void in C parlance), we just trust the magic. However this has a critical effect on how functions work, as well as the efficiency of the code.
The canonical way of passing parameters is on the stack. Each invocation of a function receives its own copy of the parameters. Here's how it usually works in C:
- The function caller saves any registers that must remain unchanged if caller saves convention is in effect.
- The parameters are pushed last first onto the stack.
- The function is called, pushing the return address and any other information like flags on the stack.
- A frame pointer register is made to point to the first argument. This is optional, compilers often allow this to be omitted by a compilation directive. More further down.
- The function allocates space on the stack for locals.
- The function saves any registers that must remain unchanged if the callee saves convention is in effect.
- The body of the function runs.
- At the return statement the function restores any registers that were saved by the callee, adjusts the stack to remove the locals, then returns to the caller.
- The caller adjusts the stack pointer to get rid of the passed arguments.
- The caller restores any registers that were saved by the caller.
Firstly note that only one of caller saves or callee saves needs to be implemented. There are pros and cons.
In caller saves:
- The caller knows which registers must be preserved.
- There needs to be as many save and restore sequences as there are calls.
In callee saves:
- The callee has to figure out which registers get used in the function and must be preserved, even if the caller doesn't care about some of them.
- There needs to be as many save and restore sequences as there are functions.
SDCC implements caller saves by default for the Z80 backend.
Incidentally why last first? C has variadic functions, of which printf may be the best known. By pushing the first parameter last, this puts it at a fixed position from the stack pointer. Some compilers have done it the other way, and then they have to do some contortions to handle printf.
Secondly, the frame pointer is actually redundant because the compiler knows at each point in the function the offset of the required parameter or local from the current value of the stack pointer. However the FP has value when using a debugger since the offset from the FP is always the same for a given parameter or local.
In CPUs that are lacking in registers, the FP is usually omitted at the cost of more work in the code generator to get the right offset.
Finally there are some hybrid schemes that pass say the first few (say 1 or 2) arguments in registers and the rest on the stack.
Whatever scheme is chosen for paramter passing above, all runtime libraries used for a given port must be compiled with the same scheme. This in addition to any opcode differences. So no mixing of Z80 and I80 libraries.
Note that we assume we can access a parameter or local at an offset from the stack pointer. Even this is tortuous for benighted CPUs like the 8080, as there is no indexed addressing mode. We have to emit instructions to calculate the effective address of the parameter, involving getting the SP into a register, then adding to it. The Z80 has the IX and IY registers for indexing, a great advance, but this is limited to offsets that fit in a signed byte. This suffices for the vast majority of parameter and local lists but greater offsets (say if you pass a large structure by value, or have large locals) have to be handled too.
Here is a C file:
#include <stdio.h> extern int rand(int); int foo(int i, int j) { int k; k = (j == rand(i)); return k - 7; } void main() { int i, j; i = rand(2); j = foo(24, 42); printf("%d %d\n", i, j); }and the generated Z80 assembler, annotated:
;foo.c:5: int foo(int i, int j) ; --------------------------------- ; Function foo ; --------------------------------- _foo:: ;foo.c:9: k = (j == rand(i)); pop bc ;bc = parameter j pop hl ;hl = parameter i push hl ;5. local k push bc push hl ;2 call _rand ;3. pop af ;9. ld c, l ld b, h ld iy, #4 ;access local k add iy, sp ld a, 0 (iy) sub a, c jr NZ,00103$ ld a, 1 (iy) sub a, b jr NZ, 00103$ ld a, #0x01 .db #0x20 00103$: xor a, a 00104$: ld c, a ld b, #0x00 ;foo.c:10: return k - 7; ld a, c add a, #0xf9 ld c, a ld a, b adc a, #0xff ld b, a ld l, c ld h, b ;foo.c:11: } ret ;foo.c:13: void main() ; --------------------------------- ; Function main ; --------------------------------- _main:: ;foo.c:17: i = rand(2); ld hl, #0x0002 push hl ;2. call _rand ;3. ;foo.c:18: j = foo(24, 42); ex (sp),hl ;9. ld hl, #0x002a push hl ;2. ld l, #0x18 push hl ;2. call _foo ;3. pop af ;9. pop af ;9. pop de ;foo.c:19: printf("%d %d\n", i, j); ld bc, #___str_0+0 push hl ;2. push de ;2. push bc ;2, call _printf ;3. ld hl, #6 ;9. add hl, sp ld sp, hl ;foo.c:20: } ret ___str_0: .ascii "%d %d" .db 0x0a .db 0x00Now you understand why compiler writers want to hug the CPU architect when they see a well-designed indexed addressing mode. Ask anyone who has enjoyed the 6809 instruction set after enduring the 6800 one.
However for some CPUs like the 8051 this stack scheme is not available or has to be used sparingly because something is lacking, for example sufficient RAM space for the stack. In this case SDCC offers another way of passing parameters and allocating locals. The parameters and locals are actually static locations in RAM, for each function. The caller fills the locations then jumps to the function. Given that the 8080 has poor stack variable handling, can we use this?
"Yes but what will you do about recursive calls?"
"Ok ok I promise not to write any eight queens or tower of Hanoi programs."
"What will you do about bsort and qsort library routines?"
"Maybe we can make an exception for those and do it the hard way for the CPUs that can grudgingly?" (This is actually what is done, with the reentrant special keyword.) "Anything else?"
"Yes, you realise that if an interrupt routine calls a function that is also used in the main line it can trample over parameters and locals?"
"Ah, I guess we'll have to avoid that then."
Nonetheless for the beginning at least I have set --stack-auto to false in the 8080 profile and will turn it on later to see whether the code generator will cope.
-
Are you game, boy?
09/01/2019 at 12:50 • 0 commentsThe one factor that makes the 8080 target even remotely tractable for me is the included port to the Gameboy Z80 by Philipp Klaus Krause. The GBZ80 is a cut down version of the Z80 that has more in common with the 8080 than the Z80. A good treatise can be found here. A quick summary: All the DD, ED, FD prefixed instructions are missing so no extended instructions, or IX/IY instructions. However the CB prefixed bit instructions are still there and this will cause most of the headaches later on. The I/O instructions are also absent but this doesn't affect the code generator, only library routines in assembler that use them.
In the code there are various macros of the form IS_<port>, e.g. IS_GB. These expand to a test on the machine subtype. I added another constant SUB_I80, the corresponding macro IS_I80, and a new macro IS_GB_I80 which is IS_GB || IS_I80.
So can we just s/IS_GB/IS_GB_I80/ throughout? Not so fast. As mentioned before the bit instructions are still present, and there are some features the GBZ80 has that the Z80 and 8080 don't. So these cannot use the test IS_GB_I80. In addition the GB uses DE then HL for function results instead of HL then DE, presumably as this is the convention for other GB software. The upshot is that every occurence of IS_GB has to be inspected to see if it's relevant to the I80 also.
Furthermore the Z80 and GBZ80 have some instructions the 8080 doesn't like DJNZ so code to do this the long way has to be added. This cannot be found by searching for GB.
There are other major differences which will be described in other logs.
-
Preparing the driver
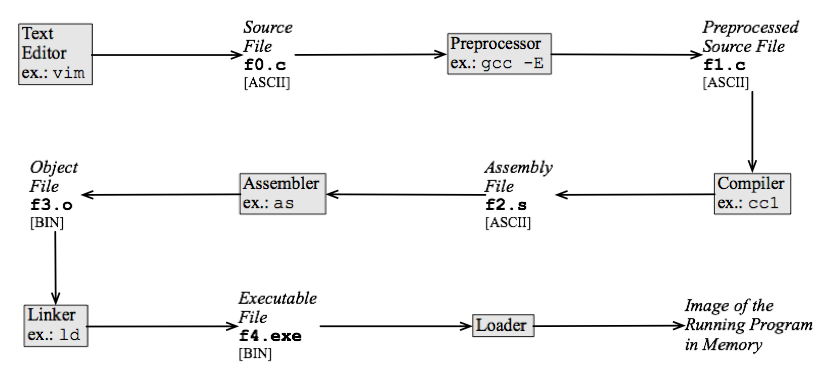
08/30/2019 at 12:14 • 0 commentsAs aficionados of Unix know, the classic C compiler is actually a chain of programs that take C source and generate various files, in the longest case, to an executable, classically a.out format, but for a long time now, usually ELF format. Here is the chain in block diagram form, taken from Wikibooks:
![]()
By Agpires - Own work, CC BY-SA 3.0, Link
SDCC is no different. However I only need to concern myself with the box labelled Compiler in the above diagram. For the 8080, as for the Z80, aslink generates Intel Hex format.
SDCC calls each distinct processor target a model, which is passed to the compiler driver sdcc as an argument, for example:
sdcc -mz80 hello.c -o hello.ihxAll related models share a backend, for example all the 8051 targets use the same backend. Since the 8080 is closely related to the Z80, this is the backend I'm modifying.
Each variant processor is included in SDCC by including a pointer to a PORT structure. It's a large structure which describes many aspects of that port, including, but not limited to, the characteristics of the C implementation such as the sizes of various data types, the names of various sections in the generated assembler code, and the programs and libraries that are used in the chain. Here is an excerpt from it:
PORT i80_port = { TARGET_ID_I80, "i80", "Intel 8080", /* Target name */ NULL, { glue, FALSE, NO_MODEL, NO_MODEL, NULL, /* model == target */ }, { /* Assembler */ _z80AsmCmd, NULL, "-plosgffwy", /* Options with debug */ "-plosgffw", /* Options without debug */ 0, ".asm", NULL /* no do_assemble function */ }, { /* Linker */ _z80LinkCmd, //NULL, NULL, //LINKCMD, NULL, ".rel", 1, _crt, /* crt */ _libs_i80, /* libs */ }, { /* Peephole optimizer */ _i80_defaultRules, NULL, NULL, NULL, NULL, NULL, NULL, NULL, z80symmParmStack, }, /* Sizes: char, short, int, long, long long, near ptr, far ptr, gptr, func ptr, banked func ptr, bit, float */ { 1, 2, 2, 4, 8, 2, 2, 2, 2, 2, 1, 4 },Fortunately I could copy a lot of the fields from the Z80 port. But some parameters, such as for optimisation, may need tweaking later.
The structure refers to a mapping.i file which is used as a sort of macro expansion mechanism to generate many lines of code from a single line of pseudo-code. For example this entry:
{ "enterx", "add sp, #-%d" },generates an instruction to adjust the stack from a single mnemonic.
Also referred to are the peephole rules for optimising short sequences of assembler lines. For example:
replace restart { ld %1, %1 } by { ; peephole 1 removed redundant load. } if notVolatile(%1)removes an unneeded assembler instruction. I took the Z80 rules and removed those which did not apply to the 8080.
Finally we need to spit out the .8080 directive to the assembler output at the beginning. This is done in the file SDCCglue.c:
else if (TARGET_IS_I80) fprintf (asmFile, "\t.8080\n");All in all about half a dozen files were modified to prepare the framework to handle the 8080 backend. The real work is yet to begin.
Targeting SDCC to the 8080
Writing a code generator for the 8080 microprocessor for Small Device C Compiler (SDCC)