 Cassio Batista
Cassio BatistaAs stated by the World Health Organisation (WHO) on the book WHO Global Disability Action Plan 2014-2021, approximately 15% of the whole population of the globe has some kind of disability. This number really speaks volumes, since it reveals that in a population of 7.6 billion people, around one out of seven (over 1 billion people) is a disabled person. In Brazil, regarding visual disability in particular, from its 190.7 million impaired people, approximately 35.8 million (18.8%) has some kind of problem in their sight, according to the last census of the Brazilian Institute of Geography and Statistics (IBGE) in 2010.
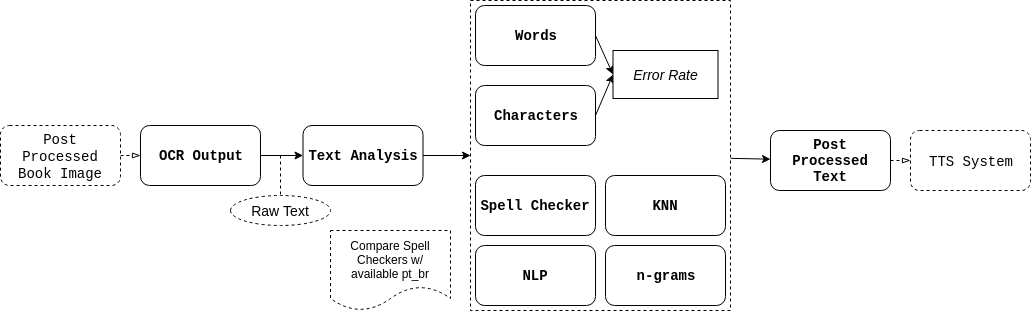
Given that the availability of haptical written mechanisms such as Braille are not always plentiful, solutions under the concept of assistive technology must be constantly explored for people with low vision or total blindness not being prevented from accessing reading textual content. We believe technologies such as optical character recognition (OCR), as well as automatic speech recognition and text-to-speech synthesis (ASR and TTS, respectively), when combined, enhance human-computer interaction while turning resources accessible to people with visual impairments (assuming their speech and hearing apparatus are preserved). OCR refers to the system that receives a digital image as input, extracts and recognises textual content, and generates a string of characters at the output. This string might serve as input to a TTS system, which is responsible for synthesising a digital speech signal. Finally, an ASR system processes some digital speech signal given as input and translates it into digital text.
Therefore, this project aims at developing an automatic reading machine with audible response and speech commands support for the visually impaired. The OCR-TTS pipeline may be used as a standalone, automatic reader which, given pictures taken from book pages, can read aloud the words contained in it. ASR itself can be used to convey commands to the system, thus avoiding the use of mechanisms that force the use of hands such as push-buttons or keyboards. Advanced usage of ASR might be employed in dictation tasks where the user can write full texts using solely speech, at the expense of requiring a large amount of data for it to work reliably. Command and control systems, on the other hand, are the fittest for underrepresented languages and work well for a limited set of sentences.
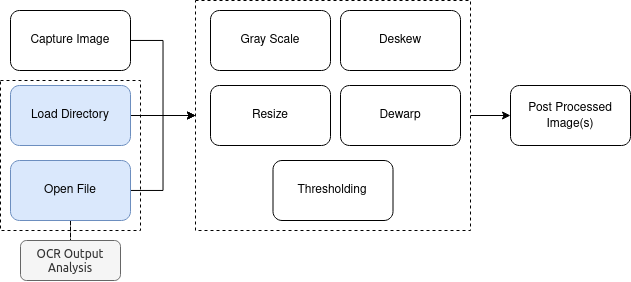
The system must be configured as a portable device over a Raspberry Pi development board. Systems are relatively computationally intensive and power hungry, which requires a quad-core processor with a considerable amount of memory (4 GB recommended). Multilingual OCR can be obtained through the Tesseract open-source engine. Speech recognition will be primarily developed in Brazilian Portuguese over the open-source Kaldi package using the corpora from the FalaBrasil Research Group. Speech synthesis can be quickly achieved with the eSpeak library, but some effort must be employed to build something over Kaldi (most likely over Idlak) or HTS engines, both open-source, also using FalaBrasil resources. Images can be taken by the Raspberry Pi NoIR camera, which works pretty well especially under low light environments, while speech can be captured by a USB microphone. A regular 4 Ohm or 8 Ohm speaker can be used to reproduce the synthesised speech generated by the TTS system.





 Anhong Guo
Anhong Guo
 Tanishq
Tanishq
 James Gibbard
James Gibbard
An automatic reading machine would be a huge energy saver for summarizing "Bleak House." With its ability to quickly scan and analyze the dense novel, it would save time and help capture the essence of the story. This device would allow students to focus on deeper analysis and interpretation, enhancing the academic experience. The automatic reading machine has the potential to revolutionize how we approach complex texts, providing confidence and mastery.I remember how I stumbled across this bleak house summary accidentally and I never was more happy than the day I found that site.I feel that the technologies are moving in the right direction.Keep up the good work!