zpekic
zpekic-
More controllers implemented in microcode!
09/16/2021 at 04:03 • 0 commentsWhat is the difference between a "controller", and "dedicated CPU"? Essentially nothing - from the perspective of microcoded design they can be developed, debugged and operated in the same way. Here are two additional controllers from my other project:
- HEX2MEM - processes ASCII character stream in real time (interpreted as Intel HEX file), to write to RAM
- MEM2HEX - read up to 64k of RAM/ROM, and generate ASCII stream (in Intel HEX format).
Note that both of these are written with an updated, less buggy version of microcode compiler.
-
Boilerplate VHDL code generation from microcode
11/15/2020 at 07:28 • 0 commentsAs I started working on a new design, I realized quite a bit of VHDL code needed could be generated by the microcode compiler itself.
Typically, a micro-coded CPU/controller contains:
- control unit (generated using .controller statement)
- microcode store (generated using .code statement)
- instruction mapper store (optional, generated using .mapper statement)
- various registers that need to be updated from different sources (register + MUX)
- internal components (such as ALUs) fed from different sources (MUX)
- various lookup tables / ROMs
- other combinatorial logic
The guiding principle behind my microcode compiler and associated hardware is a pattern and template oriented approach as a trade off between increased productivity and quality vs. somewhat less flexibility and compactness. To keep with that design philosophy I improved the compiler so that in addition to 1. - 3. above it can also generate boilerplate for .4. and 5.
Basic idea is to generate a (commented) boilerplate VHDL code which developer can choose to copy and paste into the design and modify there as needed.
While there is an extra copy/paste step, the beauty of this approach that no tooling updates or touches the human developed code, they remain independent.
Below are some examples:
run "mcc CDP180X.mcc" to generate:
Condition codes
The control unit requires a single bit to determine if the then or else instruction will be executed. This is described in the microcode using .if instruction:
seq_cond: .if 4 values true, // hard-code to 1 mode_1805, // external signal enabling 1805/1806 instructions sync, // to sync with regular machine cycle when exiting tracing routine cond_3X, // driven by 8 input mux connected to ir(2 downto 0), and ir(3) is xor cond_4, // not used cond_5, // not used continue, // not (DMA_IN or DMA_OUT or INT) continue_sw, // same as above, but also signal to use switch mux in else clause cond_8, // not used externalInt, // for BXI (force false in 1802 mode) counterInt, // for BCI (force false in 1802 mode) alu16_zero, // 16-bit ALU output (used in DBNZ only) cond_CX, // driven by 8 input mux connected to ir(2 downto 0), and ir(3) is xor traceEnabled, // high to trace each instruction traceReady, // high if tracer has processed the trace character false // hard-code to 0 default true;This results in VHDL code that can be copied into control unit instantiation and hooked up to the various test points in the design (note how "true" and "false" have been recognized and turned into '1' and '0'):
---- Start boilerplate code (use with utmost caution!) ---- include '.controller <filename.vhd>, <stackdepth>;' in .mcc file to generate pre-canned microcode control unit and feed 'conditions' with: -- cond(seq_cond_true) => '1', -- cond(seq_cond_mode_1805) => mode_1805, -- cond(seq_cond_sync) => sync, -- cond(seq_cond_cond_3X) => cond_3X, -- cond(seq_cond_cond_4) => cond_4, -- cond(seq_cond_cond_5) => cond_5, -- cond(seq_cond_continue) => continue, -- cond(seq_cond_continue_sw) => continue_sw, -- cond(seq_cond_cond_8) => cond_8, -- cond(seq_cond_externalInt) => externalInt, -- cond(seq_cond_counterInt) => counterInt, -- cond(seq_cond_alu16_zero) => alu16_zero, -- cond(seq_cond_cond_CX) => cond_CX, -- cond(seq_cond_traceEnabled) => traceEnabled, -- cond(seq_cond_traceReady) => traceReady, -- cond(seq_cond_false) => '0', ---- End boilerplate codeMUX, 2 to 1
alu_cin: .valfield 1 values f1_or_f0, df default f1_or_f0; // f1_or_f1 will generate 0 for add, and 1 for subtractbecomes (note the pattern to check when clause for non-default):
---- Start boilerplate code (use with utmost caution!) -- alu_cin <= df when (cpu_alu_cin = alu_cin_df) else f1_or_f0; ---- End boilerplate codeMUX, 2^n to 1
sel_reg: .valfield 3 values zero, one, two, x, n, p default zero; // select source of R0-R15 addressbecomes (note the attempt to recognize "zero" as all zeros):
---- Start boilerplate code (use with utmost caution!) -- with cpu_sel_reg select sel_reg <= -- (others => '0') when cpu_zero, -- default value -- one when cpu_one, -- two when cpu_two, -- x when cpu_x, -- n when cpu_n, -- p when cpu_p; ---- End boilerplate codeRegister, single update source
reg_in: .regfield 1 values same, alu_y default same; // 8 bit instruction registerSingle update source means there is a 2-to-1 mux in front of the register, and one of these sources "recirculates" the value, meaning no change of value:
---- Start boilerplate code (use with utmost caution!) -- update_reg_in: process(clk, cpu_reg_in) -- begin -- if (rising_edge(clk)) then -- if (cpu_reg_in = reg_in_alu_y) then -- reg_in <= alu_y; -- end if; -- end; -- end process; ---- End boilerplate codeObviously, the design may be triggered on falling edge of the clk, which must be changed after pasting the snippet. Note the double comments around start/end, pasting and uncommenting the selection will keep these as a warning if needed.
Register, 2^n - 1 update sources
If there is a 2^n MUX in front of a register, then 1 out of these must be used for "no change" selection. This is usually done by denoting this "same" or "nop" option as default:
reg_r .regfield 3 values same, zero, r_plus_one, r_minus_one, yhi_rlo, rhi_ylo, b_t, - default same;This option is present in the boilerplate code, but double commented to leave a simple choice to either handle it as the "others => null" case, or put it back explicitly:
---- Start boilerplate code (use with utmost caution!) -- update_reg_r: process(clk, cpu_reg_r) -- begin -- if (rising_edge(clk)) then -- case cpu_reg_r is ---- when reg_r_same => ---- reg_r <= reg_r; -- when reg_r_zero => -- reg_r <= (others => '0'); -- when reg_r_r_plus_one => -- reg_r <= r_plus_one; -- when reg_r_r_minus_one => -- reg_r <= r_minus_one; -- when reg_r_yhi_rlo => -- reg_r <= yhi_rlo; -- when reg_r_rhi_ylo => -- reg_r <= rhi_ylo; -- when reg_r_b_t => -- reg_r <= b_t; -- when others => -- null; -- end case; -- end; -- end process; ---- End boilerplate codeIn addition to "zero", the compiler also recognized "inc", "dec", "neg" and "com" to generate assumed increment, decrement, negate and 2's complement expressions.
-
Microcode Compiler quick manual
07/05/2020 at 04:58 • 0 commentsDisclaimer: The work on the MCC is still ongoing / evolving, so the current state on github may deviate from the description below.
There is no install package for mcc.exe - it is a simple command line utility which will work on most versions of Windows, and can probably be also recompiled for other platforms that have .net and C# ported.
INVOKING THE COMPILER
Starting with -h command line argument lists the usage:
>mcc.exe -h -------------------------------------------------------- -- mcc V0.9.0627 - Custom microcode compiler (c)2020-... -- https://github.com/zpekic/MicroCodeCompiler -------------------------------------------------------- Compile mode (generate microcode, mapper and control unit files): mcc.exe [relpath|fullpath\]sourcefile.mcc Convert mode (generate sourcefile.coe, .cgf, .mif, .hex, .vhd files): mcc.exe [relpath|fullpath\]sourcefile.bin [addresswidth [[wordwidth [recordwidth]]] addresswidth ... 2^addresswidth is memory depth (integer, range: 0 to 16, default: 0 which will infer from file size) wordwidth ... memory width (integer, values: 8, 16, 32 bits, default: 8 (1 byte)) recordwidth ... used for .hex files (integer, values: 1, 2, 4, 8, 16, 32 bytes, default: 16) For more info see https://hackaday.io/project/172073-microcoding-for-fpgasThe convert mode allows usage as a handy utility to convert memory file formats that often come up in FPGA or other embedded system development. The focus here will be on the usage to generate elements of the microcoded design ("compile mode").
GENERAL SYNTAX RULES FOR SOURCE.MCC
The mcc source file is a text file with extension .mcc with few general rules:
- each statement must end with ;
- statements can go into multiple lines (encouraged for clarity)
- if the statement is a microinstruction, a comma delimits a microcode field, and semicolon the instructions, meaning "1 semicolon = 1 microcode cycle"
- labels end with colon (by convention, but not enforced), and follow the usual rules (can start with _ or alpha characters, but may contain no special characters except _)
- labels starting with _ cannot be jumped to (this is useful to explicitly forbid some jump destinations)
- everything is case-insensitive (but lowecase is encouraged)
- comments - everything after // until end of line is ignored. Currently, no multi-line comments are supported
- constants can be given as decimal, hex (0x...), octal (0o...), or binary (0b...). In some cases (for example .org), the binary/octal/hex can contain ? wildcard, which indicated 1, 3, or 4 "don't care" bits. In addition 'char' constant will be represented by its basic ASCII code.
- from the compiler perspective, source.mcc contains only:
- statements (keywords starting with dot)
- microinstructions
STATEMENTS
Following statements are currently recognized by mcc.exe:
Design definition statements:
.code depth, width, filelist, bytewidth;
Reserves memory for microcode:
- 2^depth will be the number of words
- each word will be <width> words wide - this must be equal or bigger than the sum of all the field widths
- successful compile will produce all the files in the <filelist>, they will all contain same data but described according to file format
- <bytewidth> will be used for .hex file format to have that record size (must be equal or greater than <width>
Example: generate 5 files describing the 64 * 32 memory containing the generated microcode:
.code 6, 32, tty_screen_code.mif, tty_screen_code.cgf, tty:tty_screen_code.vhd, tty_screen_code.hex, tty_screen_code.bin, 4;.mapper depth, width, filelist, bytewidth;
Reserves memory for mapper - this is the lookup memory that accepts bit patter from instruction register as address, and outputs the starting address of microcode implementing that instruction. The arguments are same like for .code statement
Example: generate 5 files describing the 128 * 6 memory containing the generated mapper:
.mapper 7, 6, tty_screen_map.mif, tty_screen_map.cgf, tty:tty_screen_map.vhd, tty_screen_map.hex, tty_screen_map.bin, 1;.controller code.vhd, stackdepth[, rising|falling];
- Currently, only .vhd output file format is supported
- stackdepth must be between 2 and 8 (inclusive)
Example: generate standard microcode controller, with 4 level stack depth, rising edge clock:
.controller tty_control_unit.vhd, 4;Microcode field definition statements:
label: .if width values conditionlist default defaulcondition;
For width of N, 2^N conditions need to be defined in the conditionlist, which a list of comma delimited symbols
By convention, condition 0 is "true" and condition 2^N-1 is "false"
"true" condition is usually designated as default which allows handy default "next" without writing anything.
Example: microcode controller unit consuming 8 conditions:
seq_cond: .if 3 values true, // hard-code to 1 char_is_zero, cursorx_ge_maxcol, cursory_ge_maxrow, cursorx_is_zero, cursory_is_zero, memory_ready, false // hard-code to 0 default true;label: .then width values targetlist default defaulttarget;
- width must match the microcode depth
- targetlist can contain:
- predefined commands (next, repeat, return, fork) - if the order of these is changed, the generated controller.vhd file must be updated
- @ meaning any valid label for jump
- range (from .. to) - useful to allow reuse of field to bring in constants to microinstruction, for example if condition is "false" then obviously "then" field will never be used so its width can be reused for a constant value to be consumed by the microinstruction.
Example: 6 bits are reserved for target if condition is met, which can be either one of 4 predefined controller actions or branching to any valid label. Obviously, this design must have microcode depth of 64 words to be able to reach any location with 6 bits target address.
seq_then: .then 6 values next, repeat, return, fork, @ default next;label: .else width values targetlist default defaulttarget;
Exactly the same as "then" but consumed when the condition is false. Given that usually the default condition is true, and default target is "next" this field is more often used to contain a constant.
Example: just about anything is allowed in else:
seq_else: .else 8 values next, repeat, return, fork, 0x00..0xFF, @ default next; // any value as it can be a trace charlabel .regfield width values valuelist default defaultvalue;
regfields assume that the design drives a "register" (of any length, from 1 to x bits) that will be updated at the end of the current microinstruction cycle. This is indicated with <= assignment. Compiler will enforce using the regfield only with <= assignment.
Valuelist can contain any combination of:
- alphanumeric symbols (symbol will be assigned to a value based on order encountered)
- range (value assigned will be checked to be in the range)
- dash (-) meaning that value in the order is forbidden to be assigned
Example: register can be updated by 3 possible values, or stay the same. 4 additional possibilites are undefined, but not forbidden:
reg_d: .regfield 3 values same, alu_y, shift_dn_df, shift_dn_0 default same; // 8 bit accumulatorIt is important to note, that if microinstruction does not contain reg_d <= value, that will mean reg_d <= same ("register recirculated").
One measure of microinstruction efficiency is how many such "default nops" do they contain - ideally, as many as possible elements of the design should be engaged in a single microinstruction to boost parallelism.
label .valfield width values valuelist default defaultvalue;
valfields assume driving signals in the design available immediately at the output of the microcode memory (just memory propagation delay), during the current microinstruction cycle. This is indicated by the = assignment. Compiler will enforce using the valfield only with = assignment.
Syntax of valuelist is same as for .regfield
Example: 2 valfields controlling MUXs bringing values to ALU. If not specified, ALU will operate on value of t register and data bus:
alu_r: .valfield 2 values t, d, b, reg_hi default t; alu_s: .valfield 2 values bus, d, const, reg_lo default bus; // const comes from "else" valueMicroinstructions typically contain many fields, which need to be specified together for an useful action to emerge. For clarity and to avoid bugs by omission, it is very useful to provide a shortcut for those. During the compilation, the label will be replaced verbatim therefore the end result of all the replacement must meet the syntax and logic rules.
It is allowed to define an alias based on previously defined aliases.
Example: allow writing "trace CR" or "trace LF" which will cause calling "traceChar" routine while carrying ASCII constant which will be loaded into the reg_trace register at the end of current cycle:
CR: .alias 0x0D; LF: .alias 0x0A; trace: .alias reg_trace <= ss_disable_char, if true then traceChar else;Microcode placement statements:
These are very similar to usual .org statements in assemblers - they define the location in the microcode memory where the next microinstruction will be placed. Following rules apply:
- location can be any between 0 and 2^depth - 1
- locations can be defined in increasing order only, gaps are allowed, going back isn't
- location value cannot contain wildcards
- at least one .org must be present (usually .org 0 to set the location for microinstruction executed at reset)
Example: simple startup sequence lasting 4 microinstruction cycles. However, first cycle could jump to any given place, but no instruction can jump to first 4 locations, as their addresses share the values with next, repeat, return, fork (that's why their labels start with _)
.org 0; // First 4 microcode locations can't be used branch destinations // --------------------------------------------------------------------------- _reset: cursorx <= zero, cursory <= zero; _reset1: cursorx <= zero, cursory <= zero; _reset2: cursorx <= zero, cursory <= zero; _reset3: cursorx <= zero, cursory <= zero;This statement establishes the link between an instruction and its start address. Rules are:
- pattern can be any value between 0 to 2^mapper depth - 1
- pattern can contain wildcards if specified as hex, binary or octal
- order of map statement is important! Most generic map statements (with most wildcard bits) must be put first, and more restrictive after. This way mappings can be targeted to specific instruction register bit combinations.
- multiple map statements can be put one after the other - this means multiple instruction patterns will map to same microcode entry point.
Example: 1802 supports LDN R1...RF but not LDN R0, that op-code is reserve for IDL instruction. Therefore, first the generic LDN map is defined with wildcards for register number, and then overwritten with specific code for IDL:
.map 0b0_0000_????; // D <= M(R(N)) LDN: exec_memread, sel_reg = n, y_bus, reg_d <= alu_y, if continue then fetch else dma_or_int; .map 0b0_0000_0000; // override for LDN 0 IDL: noop; // dead loop until DMA or INT detected if continue then IDL else dma_or_int;MICROINSTRUCTIONS
Every non-empty, non-comment line which has no .keyword is assumed to be a microinstruction. The format is:
[label:] field [<]= value [, field [<]= value [...]][, if condition then target [else target];
- Field and value are given when describing the microcode fields (.regfield or .valfield)
- The number of field/values can be from 1 to total number of fields in the design, but each can only be used once
- If field/value is not specified, the default is used (that is why selecting right defaults is crucial for a good microcode design!)
- For readability, it is useful to put each field/value in own line, end it with comma, and if/then/else on last line with semicolon
- any number of field/value and also if/then/else can be replaced with symbol defined in .alias
Here is a 3 microinstruction routine that illustrates the above:
RNX: reg_extend <= zero, sel_reg = n, reg_t <= alu_y, y_lo; // T <= R(N).0 sel_reg = n, reg_b <= alu_y, y_hi; // B <= R(N).1 sel_reg = x, reg_r <= b_t, // R(X) <= B:T if continue then fetch else dma_or_int;- label and alias (y_lo) is used, but there is no if/then/else, meaning that by default rules if true then next else next; will be executed by the microcode controller (execution will go to next microinstruction)
- no label, alias, both reg and value assignment used, all in same line, note that field ordering can be arbitrary (sel_reg = ... appears in different place)
- if statement explicitly specified, in separate line (still 1 microinstruction though) - "fetch" is a special microcode controller statement, while dma_or_int is a label
VERSION UPDATES
(Note: last 4 digits of version are month and day, other is pretty arbitrary, will go to 1.0.XXXX when sufficiently tested on other designs)
1. Support for overlapping microcode fields:
fieldname .regfield startfield..endfield
fieldname .valfield startfield..endfield
Obviously startfield and endfield need to defined before. The compiler will throw an error if that's the case, or .if / .then fields are being redefined.
This is an EXTREMELY useful feature as it allows even horizonal microcode a level of compactness. For example, it is common to have constant microcode fields, but usually only some microinstructions use it. With clever design (and extra select bit somewhere), such field can be reused for other purposes, with the right name to facilitate code readability / maintainability.
2. Support for floating point constants
32-bit value of single precisionIEEE754 representation will be instered in the specified microinstruction field. This is done in a very lazy implementation: if parsing as binary / octal / hex / decimal integer fails, there will be a ParseFloat() attempt. This means:
reg <= 1E3, ... // reg will be loaded with 0x000001E3
but:
reg <= 1.E3, ... // reg will be loaded with 0x447a0000
-
Microcode compiler in FPGA toolchain
06/14/2020 at 00:56 • 0 commentsTL;DR
In case you want to skip much theory below and dig-in in a practical way, follow this guide: https://hackaday.io/project/182959-custom-circuit-testing-using-intel-hex-files/log/201614-micro-coded-controller-deep-dive
The following diagram above illustrates the high-level code / project flow that uses mcc microcode compiler. Details are elaborated below.

source.mcc
Microcode source code file is a simple text file that typically contains following sections:
- code memory description (.code statement)
- mapper memory description (.mapper statement)
- microinstruction word description containing:
- sequencer description (.if .then .else)
- values available in current microinstruction clock ( .valfield)
- values available in next microinstruction clock (captured at next clock: .regfield)
- simple macros (.alias)
- microcode statements. These are:
- put into specific microcode locations using .org statement
- mapped to specific instruction patterns using .map statement
- containing any number of value and/or register assignment, but only up to 1 if-then-else statement
- commas can be read as "simultaneous in 1 clock cycle", and 1 semicolon maps to 1 cycle
A single statement can go into any number of lines for clarity, but last one must be terminated by a ;
Labels can stand in front of aliases to be used ("expanded") in code later, or in front of microcode statements, to be used as target to goto/gosub (except _ starting labels to prevent that on purpose, for example first 4 cycles after reset)
mcc.exe
This is a 2-pass, in-memory compiler written in pretty straightforward C# / .Net that should make it portable to other platforms (although this has not been evaluated)
There are 2 modes to use it:
- compile (mcc.exe source.mcc) to generate code/mapper memory files
- convert (mcc.exe source.bin [addresswidth] [wordwidth] [recordwidth])
Both will produce extensive warning and error list on the console, as well as source.log file with detailed execution log.
Currently, only conversion from bin (for example, EPROM image) is supported, but I plan to add other file formats too. Conversion parameters are:
- addresswidth - integer (default = 0 (auto-size)) - number of locations in the memory block
- wordwidth - integer (default = 8) - number of bits in one word
- recordwidth - integer (default = 16) - number of bytes per line in .hex file output
Generated files
In order to facilitate ease of use in standard vendor or open-source FGPA toolchain downstream, multiple data format files are generated. All contain same information though!
The .code, .mapper, .controller statements describe the files generated:
.code 6, 32, tty_screen_code.mif, tty_screen_code.cgf, tty:tty_screen_code.vhd, tty_screen_code.hex, 4; .mapper 7, 6, tty_screen_map.mif, tty_screen_map.cgf, tty:tty_screen_map.vhd, tty_screen_map.hex, 1; .controller cpu_control_unit.vhd, 8;This will generate:
A code memory block of 64 words 32 bits wide, and store it to following files:
- tty_screen_code.mif - useful for Altera/Intel tools
- tty_screen_code.cgf - for Xilinx
- tty_screen_code.coe - for Xilinx (not specified in the statements above so not generated, link is to equivalent file from CDP180X.mcc)
- tty_screen_code.vhd - a "VHDL Package" good for all FPGA compilers, can be included in the list of project files (the "tty" prefix allows any number of microcoded design to be included into same FPGA project, differentiated by this prefix)
- tty_screen_code.hex - useful for any tools, including possibly loading into the FPGA ("dynamic microcode!") during runtime. The paramer "4" indicates 4 bytes per line (usually is 16 for .hex files)
A mapper memory block 128 words, 6 bits wide, files similar to above.
The .controller statement will generate a .vhd file with the integer parameter giving the depth of the "hardware stack" - 8 is probably the most reasonably used, simpler designs can get away with 4 or even 2.
An example of generated controller vhd file for stack depth of 4:
-------------------------------------------------------- -- mcc V0.9.0627 - Custom microcode compiler (c)2020-... -- https://github.com/zpekic/MicroCodeCompiler -------------------------------------------------------- -- Auto-generated file, do not modify. To customize, create 'controller_template.vhd' file in mcc.exe folder -- Supported placeholders: [NAME], [STACK_DEF], [STACK_PUSH], [STACK_POP]. -------------------------------------------------------- library IEEE; use IEEE.STD_LOGIC_1164.all; use IEEE.numeric_std.all; entity tty_control_unit is Generic ( CODE_DEPTH : positive; IF_WIDTH : positive ); Port ( -- standard inputs reset : in STD_LOGIC; clk : in STD_LOGIC; -- design specific inputs seq_cond : in STD_LOGIC_VECTOR (IF_WIDTH - 1 downto 0); seq_then : in STD_LOGIC_VECTOR (CODE_DEPTH - 1 downto 0); seq_else : in STD_LOGIC_VECTOR (CODE_DEPTH - 1 downto 0); seq_fork : in STD_LOGIC_VECTOR (CODE_DEPTH - 1 downto 0); cond : in STD_LOGIC_VECTOR (2 ** IF_WIDTH - 1 downto 0); -- outputs ui_nextinstr : buffer STD_LOGIC_VECTOR (CODE_DEPTH - 1 downto 0); ui_address : out STD_LOGIC_VECTOR (CODE_DEPTH - 1 downto 0)); end tty_control_unit; architecture Behavioral of tty_control_unit is constant zero: std_logic_vector(31 downto 0) := X"00000000"; signal uPC0, uPC1, uPC2, uPC3 : std_logic_vector(CODE_DEPTH - 1 downto 0); signal condition, push_then_jump: std_logic; begin -- uPC holds the address of current microinstruction ui_address <= uPC0; -- evaluate if true/false condition <= cond(to_integer(unsigned(seq_cond))); -- select next instruction based on condition ui_nextinstr <= seq_then when (condition = '1') else seq_else; -- check if jump or one of 4 "special" instructions push_then_jump <= '0' when (ui_nextinstr(CODE_DEPTH - 1 downto 2) = zero(CODE_DEPTH - 3 downto 0)) else '1'; sequence: process(reset, clk, push_then_jump, ui_nextinstr) begin if (reset = '1') then uPC0 <= (others => '0'); -- reset clears top microcode program counter else if (rising_edge(clk)) then if (push_then_jump = '1') then uPC0 <= ui_nextinstr; uPC1 <= std_logic_vector(unsigned(uPC0) + 1); uPC2 <= uPC1; uPC3 <= uPC2; else case (ui_nextinstr(1 downto 0)) is when "00" => -- next uPC0 <= std_logic_vector(unsigned(uPC0) + 1); when "01" => -- repeat uPC0 <= uPC0; when "10" => -- return uPC0 <= uPC1; uPC1 <= uPC2; uPC2 <= uPC3; uPC3 <= (others => '0'); when "11" => -- fork uPC0 <= seq_fork; when others => null; end case; end if; end if; end if; end process; end;FPGA project files
At this point, any tooling / editor can be used to develop the FPGA design using any methodology. But if the microcoded design is to be included then following must be included in the project:
1 standard control unit VHD per microcoded controller / CPU (see above for generated example)
-- AND --
At least 1 of the files describing code memory block (e.g. .coe or vhd etc.)
-- AND (OPTIONALLY BUT USUALLY)
At least 1 of the files describing mapper memory
Including the files above in the project generates a dependency between microcode source and final FPGA .bit file - after changing the .mcc file, compiler must be run, which triggers update of files in main project, which requires a rebuild of project to create a new file.
Note that it is possible to have microcoded design without the mapper, but not without microcode. However is it possible to "misuse" the compiler to produce complex lookup memory maps by using the .mapper and .org directives.
Future improvement plans
- Support "include" files in source.mcc
- Support .hex, .mif, .coe, .cgf for conversion source file type
- Simple expression evaluation for values
- Conditional compile (#ifdef / #ifndef / #else / #endif)
-
Debugging microcoded designs
06/14/2020 at 00:53 • 0 commentsMicrocoding as a technique is very much aligned with "test-driven development" concept. Essentially it means first to build the scaffolding needed to test the circuit, and then the circuit itself. Just like the microcoding itself, the advantage here is customized debugging tailored to the exact needs for the circuit, yet following a standardized methodology.
In the CPD180X CPU, 3 main debugging techniques have been used:
- variable clock rate, including 0Hz and single-step
- visualizing the microcode / microcode controller state
- visualizing the controller circuit state (tracing)
- breakpoints
Any combination of the above can be used in any circuit, including none which would be appropriate for a mature well-tested design (and freeing up resources on FPGA and microcode memory). Let's describe them in more detail:
(1) CLOCK RATE / SINGLE STEPPING
Just like most circuits in FPGAs, microcode driven ones can operate from frequency 0 to some maximum determined from the delays in the system. At any frequency, the clock can be continuous, or single-stepped or triggered. In the proof of concept design, a simple clock multiplexer and single step circuit is used:
-- Single step by each clock cycle, slow or fast ss: clocksinglestepper port map ( reset => Reset, clock3_in => freq25M, clock2_in => freq1M5625, clock1_in => freq8, clock0_in => freq2, clocksel => switch(6 downto 5), modesel => switch(7), -- or selMem, singlestep => button(3), clock_out => clock_main );(clock_out drives the CPU, from 2Hz to 25MHz frequency, either continous (modesel = '0') to single step (modesel = '1'))
Determining the maximum possible / reliable clock frequency is a complex exercise which is helped by most FPGA vendors providing their tools to analyse and optimize timings. From the perspective of microcoded control unit this boils down to single statement:
At the end of the current microcode instruction, uPC must capture the correct address for next instruction.
This further breaks down into 2 cases:
- If next instruction does not depend on any condition, the length of cycle must be greater than the delay through microcode memory (address to date propagation) + microcode controller multiplexor.
- If next instruction depends on the condition, then it must be greater than delay above + delay to determine the condition.
For example, let's say microcode with cycle time t has to wait for a carry out from a wide ripple carry ALU with settle time of 4t - this means executing 3 NOPs ("if true then next else next") and then finally a condition microinstruction ("if carry_out then ... else ...")
(2) MICROCODE STATE
Each microcoded design developed using this tooling and method will have the same "guts" - they will all have current uPC state, next uPC state, outputs of mapper and microcode memory blocks, current condition etc. To make sure all is connected and working as expected it is useful to bring them out and display - for example on 7seg LED displays most FPGA development boards contain.
This boils down to a MUX of required length, in1802 CPU design, 8 hex digits are "exported" out:
-- hex debug output with hexSel select hexOut <= ui_nextinstr(3 downto 0) when "000", ui_nextinstr(7 downto 4) when "001", ui_address(3 downto 0) when "010", ui_address(7 downto 4) when "011", reg_n when "100", reg_i when "101", reg_ef when "110", nEF4 & nEF3 & nEF2 & nEF1 when "111";The MUX is hooked up to additional "port" on the CPU entity (hexOut below), and simply driven by LED display clock (hexSel below), and the 4-bit nibble is decoded using standard hex-to-7seg lookup to display:
instruction register : current uPC : next uPC address : other (EF flags on pins and captured)
entity CDP180X is
Port ( CLOCK : in STD_LOGIC;
nWAIT : in STD_LOGIC;
nCLEAR : in STD_LOGIC;
Q : out STD_LOGIC;
SC : out STD_LOGIC_VECTOR (1 downto 0);
nMRD : out STD_LOGIC;
DBUS : inout STD_LOGIC_VECTOR (7 downto 0);
nME : in STD_LOGIC;
N : out STD_LOGIC_VECTOR (2 downto 0);
nEF4 : in STD_LOGIC;
nEF3 : in STD_LOGIC;
nEF2 : in STD_LOGIC;
nEF1 : in STD_LOGIC;
MA : out STD_LOGIC_VECTOR (7 downto 0);
TPB : buffer STD_LOGIC;
TPA : buffer STD_LOGIC;
nMWR : out STD_LOGIC;
nINTERRUPT : in STD_LOGIC;
nDMAOUT : in STD_LOGIC;
nDMAIN : in STD_LOGIC;
nXTAL : out STD_LOGIC;
-- not part of real device, used to turn on 1805 mode
mode_1805: in STD_LOGIC;
-- not part of real device, used for debugging
A : out STD_LOGIC_VECTOR (15 downto 0);
hexSel : in STD_LOGIC_VECTOR (2 downto 0);
hexOut : out STD_LOGIC_VECTOR (3 downto 0);
traceEnabled: in STD_LOGIC;
traceOut : out STD_LOGIC_VECTOR (7 downto 0);
traceReady : in STD_LOGIC);
end CDP180X;(3) CIRCUIT STATE
While the microcode guts are the same, the actual circuit/CPU/controller itself can be vastly different, and this exactly where microcoding shines as easy way to customize what wants to be seen. Classic example of this would to trace the state of most important internal registers during program execution:
6502: A, X, Y, S, PSB, PC, IR
8080: AF, BC, DE, HL, SP, PC, IR
9900: PC, WP, ST, IR
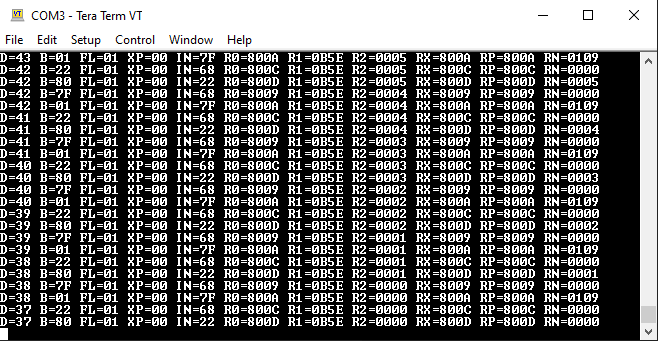
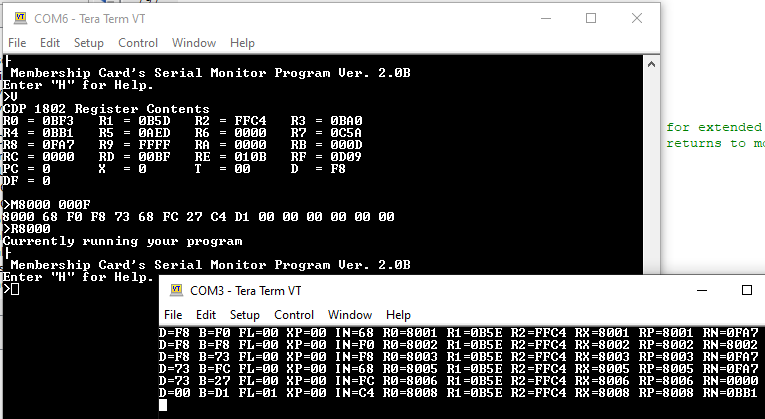
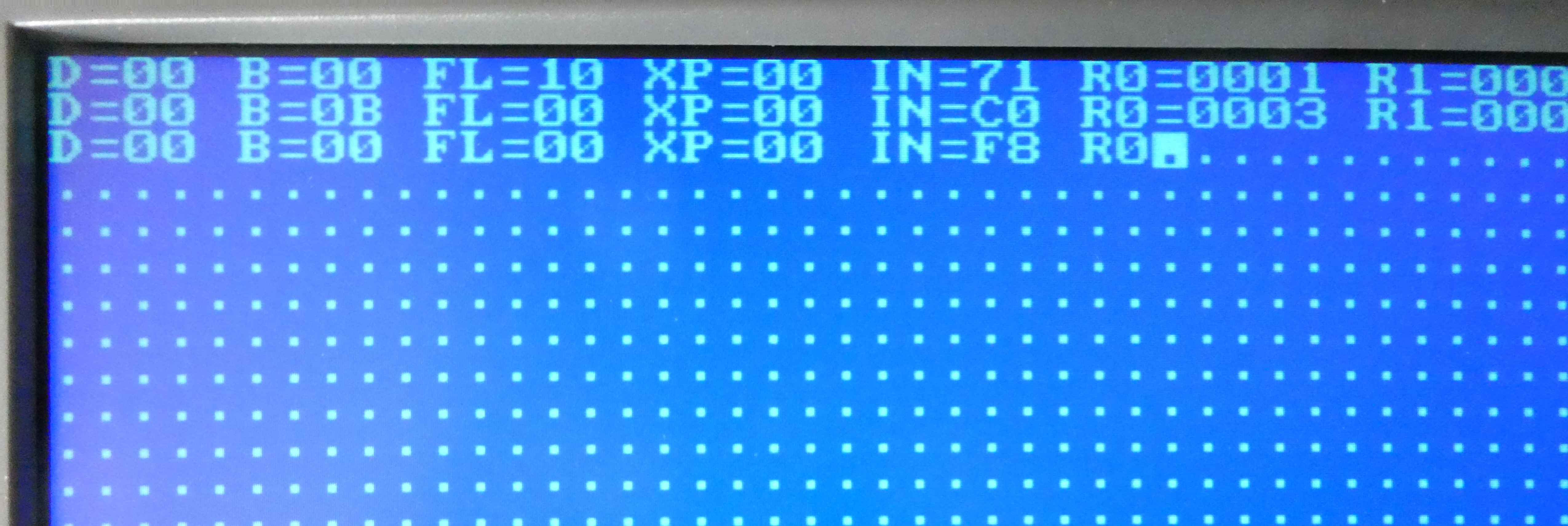
1802: D, B, FL, XP, IN, R0, R1, R2, RX, RP, RN
As can be seen above, after the instruction register (IN) is loaded with the new instruction, and before it is executed, a microcode routine is run to dump out all relevant internal state:
// Read memory into instruction register // --------------------------------------------------------------------------- fetch: fetch_memread, sel_reg = p, reg_in <= alu_y, y_bus, reg_inc; // Given that instruction register is loaded late, execute 1 more cycle before forking. It is useful to load B <= M(X) // ---------------------------------------------------------------------------- load_b: exec_memread, sel_reg = x, reg_b <= alu_y, y_bus, if traceEnabled then traceState else fork;traceState condition is true if a "pin" is raised in the debug port, and in that case instead of "forking" to execute the instruction, the routine to dump internal state will be entered.
Note that trace characters can come in two flavors:
- ASCII code given by program (such as "D=" or CR/LF at the end of line)
- 0-F ASCII code, but coming from the actual state of the register.
Let's see how both are coded:
// Output internal state in following format: // D=?? B=?? FL=?? XP=?? IN=?? R0=???? R1=???? R2=???? RX=???? RP=???? RN=????<cr><lf> // trace mux selection is: // 0XXXXXXX ... 7 bit ASCII character in XXXXXXX // 1XXXRRR0 ... internal register, low nibble // 1XXXRRR1 ... internal register, high nibble // ----------------------------------------------------------------------------- traceState: trace 'D'; trace '='; trace 0b1000_0111; trace 0b1000_0110; trace ' ';Characters "D" and "=" will have bit 7 = '0' so they will go directly through output MUX, but if bit 7 = '1' then then MUX will select an output of another MUX (yes, 99% of everything is a MUX) that will pick up the higher or lower nibble of the flags register (there is no such thing in 1802, but it is useful to clump together DF and IE flags into a virtual flags register for display purposes):
-- tracer -- tracer works by sending ascii characters to TTY type output device, such as simple text display or serial -- there is a protocol both need to follow: -- 1. CPU outputs 0 to tracer port, DEVICE detects 0, does not nothing but asserts traceReady = 1 -- 2. CPU outputs ascii to tracer port, DEVICE detects != 0, starts displaying the char, traceReady = 0 indicating busy -- 3. CPU waits until traceReady = 1 -- 4. goto step 1 with cpu_seq_else(3 downto 0) select hexTrace <= reg_t(3 downto 0) when "0000", reg_t(7 downto 4) when "0001", "000" & reg_df when "0010", "000" & reg_mie when "0011", -- TODO: add other interrupt enable flags here reg_b(3 downto 0) when "0100", reg_b(7 downto 4) when "0101", reg_d(3 downto 0) when "0110", reg_d(7 downto 4) when "0111", reg_n when "1000", reg_i when "1001", reg_lo(3 downto 0) when "1010", reg_lo(7 downto 4) when "1011", reg_hi(3 downto 0) when "1100", reg_hi(7 downto 4) when "1101", reg_p when "1110", reg_x when "1111";Now the only remaining mystery is what does "trace <value>" do? This is not a special microinstruction, essentially it is a redefined "load and jump" microinstruction:
trace: .alias reg_trace <= ss_disable_char, if true then traceChar else;Note that there is nothing after "else" - that is where MCC will insert the ASCII code or MUX selector parameter. Because each of these is an unconditional "call" into routine that pushes out the trace character, the "else" part is unused and can be repurposed to hold either the ASCII code of trace character, or the MUX selector.
Finally, the output routine has to synchronize with VGA tracer or UART tracers, both of which can be much slower than the CPU. This is done by waiting on their "ready" signal:
traceChar: if traceReady then next else repeat; // wait until tracer indicates processed character reg_trace <= ss_disable_zero, return; // sending NULL to tracer readies it for next characterreg_trace is output register holding the ASCII character to present to external circuits (VGA or TTY, but could easily be a memory writer too). In addition to 8 bit for character, it has the 9th bit to indicate if single stepping is enabled. This is convenient as it is annoying to single step through the tracer routine, usually developer is only interested in stepping through the code implementing the circuit:
traceOut <= reg_trace(7 downto 0); -- reg_trace(8) can be used internally to enable/disable single stepping -- update TRACER register update_tracer: process(UCLK, cpu_reg_trace, cpu_seq_else) begin if (rising_edge(UCLK)) then case cpu_reg_trace is when reg_trace_ss_enable_zero => -- enable single stepping, no char to trace reg_trace <= "100000000"; when reg_trace_ss_disable_zero => -- disable single stepping, no char to trace reg_trace <= "000000000"; when reg_trace_ss_disable_char => -- disable single stepping, ascii char to trace if (cpu_seq_else(7) = '0') then reg_trace <= '0' & cpu_seq_else; -- ascii char is in the microcode else reg_trace <= '0' & hex2char(to_integer(unsigned(hexTrace))); end if; when others => null; end case; end if; end process;Note that with some additional formatting, and simple external code or tools, the output can be captured in CSV (Excel) or any other data format for easy off-line analysis later, or comparison with well-known data set.
(4) BREAKPOINTS
Given that the circuit functionality is described by running code, it is easy to see that code can have breakpoints which can help immensely with debugging and troubleshooting. This a huge advantage over FSMs where such technique is not readily available.
Breakpoints can come in two different forms:
- Triggered internally - this can be any condition set up in the design (for example A != valid BCD and arithmetic mode is BCD), or when reaching an unexpected or given uPC address ("stray code execution"), etc. At that point tracing or single stepping can be "tripped", and CPU can go into "debug mode"
- Triggered externally - some external condition triggers the single step, or tracing circuit, allowing execution to proceed in "debug mode"
Here is the illustration of the "external" breakpoint. To debug extended "1805/6" instructions, the tracer is triggered, and then when return to monitor is detected, then stop tracing. This way, the execution of "DADI" instruction (add immediate BCD mode") is tested (73 + 27 = 100 in BCD!!)
The circuit for this watches for:
- if tracer is turned off, fetching of 0x68 "extended" op-code (Z80 fans: think 0xCB, 0xCD, 0xED, 0xFD codes), and if in 1805 mode, turns it on
- if tracer is turned on, watches for "SEP R1" instruction (0xD1 opcode) which returns to monitor to turn it off
fetch <= not (nMRD or SC(1) or SC(0)); fetch_extended <= fetch when (D = X"68") else '0'; -- escape for extended instructions in 1805 mode fetch_sep_r1 <= fetch when (D = X"D1") else '0'; -- SEP R1 returns to monitor set_traceExtended: process(TPB, D, nMWR, SC) begin if (reset = '1') then traceExtended <= '0'; else if (falling_edge(TPB)) then if (traceExtended = '0') then traceExtended <= sw_1805mode and fetch_extended; else traceExtended <= not (fetch_sep_r1); end if; end if; end if; end process; -
Standardized control unit and microcode layout
05/30/2020 at 18:01 • 0 commentsHISTORY
Complex digital circuits can be described in different ways for the purpose of (re) creating them in FPGAs. One way that was curiously absent is the practice of microcoding. Looking at the history of computing in the last 70 years, this approach has been very popular for all sorts of devices from custom controllers to CPUs. This article describes the history of microcoding and its applications very well:
https://people.cs.clemson.edu/~mark/uprog.html
Coming to the era of particular interest to retrocomputing hobbyists (60, 70ies and 80ies), microcoding was extremely widespread technique. Most minis and mainframes of the era used it,for example PDP-11:
When the microprocessor revolution started, some of the early 8-bit CPUs were using "random logic" to implement their control unit (6502, Z80, 1802), but in order to build something more flexible and faster, microcoding was the only game in town. One could almost say that the microcoding was the standard "programmable logic" way of the day, just as today FPGAs are.
One company in particular made fame and fortune using microcoding: AMD. The Am29xx family of devices was the way to create custom CPUs and controllers, or re-create minis from previous era and shrink them from small cabinet to a single PCB. Alternatively, well-known CPUs could be recreated but much faster. For example:
(note: based on the well documented design above, I coded it in VHDL and got 8080 monitor to run, see link in main project page)
Once the complexity of single - chip CPUs rose, microcoding again gained prominence, and is present from the first iterations of 68k and 8086 processor families until now (for example, description of 68k microcode: https://sci-hub.st/https://doi.org/10.1145/1014198.804299 )
HELPFUL ANALOGY
The problem is, so many variations of microcoding design obfuscate the beautiful simplicity of it all, which essentially boils down to:
That's right:
- the circumference of the cylinder is the depth of the microcode memory - the bigger it is the more complex the tune / instruction set. However it is always limited and hard-coded (unless one replaces the cyclinder, which is also possible in microcoding)
- the length of the cylinder determines the complexity of the design - more "notes" can be played at the same time (inherent parallelism)
- turning the crank faster is equivalent to increasing the execution frequency of the microinstruction, up to the point where the vibrating metal cannot return to the neutral position to play the right tune any more (meaning that the cycle is faster than the latency paths in the system)
The only missing part in the picture above would be the ability to disengage the cylinder, rotate to a specific start position ("entry point of instruction execution"), then engage and play to some other rotation point for a complete analogy.
DESIGN FOR SIMPLICITY
To capture the simplicity, I opted for a parametric design design pattern where the structure is always the same but its characteristics can be varied widely using parameters U, V, W, S, C. These parameters are given as microcode compiler statements. Let's look at the those:
.code U, W ..
.mapper V, U ...
.controller S
. if C ...
.then U
.else U
This will generate:
- mapper memory with V address lines (2^V words) and width U
- code memory with U address lines (2^U words == circumference of cylinder above) and width W (length of cylinder above)
- microprogram controller with S microprogram counters ("stack"), which can:
- select from 2^C conditions
- branch to U - 4 locations in the code memory
- execute following 4 special instructions: next, repeat, return, fork
Here is a schematic representation rendered using highly sophisticated state of the art tools:
The constraints of parameters are:
- Given that 2U + C bits will be consumed by the microprogram controller, that means W > (2U + C) to leave at least some useful control bits to drive the design
- The mapper memory address is usually directly connected to the output of "instruction register" - which means that V <= [instruction register width].
- Meaningful U is >= 4 (yes, 16 micro-instructions are sufficient for some simple designs)
- Meaningful C is >= 2 (4 conditions, true, false and two additional ones)
- V can be 0 (some designs don't need any mapper)
Let's look at two set of these parameters in practice:
1802 CPU (microcode):
.code 8, 64, cdp180x_code.mif, cdp180x_code.cgf, cdp180x_code.coe, cpu:cdp180x_code.vhd, cdp180x_code.hex, cdp180x_code.bin, 8; .mapper 9, 8, cdp180x_map.mif, cdp180x_map.cgf, cdp180x_map.coe, cpu:cdp180x_map.vhd, cdp180x_map.hex, cdp180x_map.bin, 1; .controller cpu_control_unit.vhd, 8;- microcode memory of 256 (2^U) words, 64 (W) bits each
- mapper memory of 512 (2^V) words, 8 (U) bits each
- controller with 8 levels deep stack (S)
The controller is driven by following description of if (cond) then / else):
seq_cond: .if 4 values true, // hard-code to 1 mode_1805, // external signal enabling 1805/1806 instructions sync, // to sync with regular machine cycle when exiting tracing routine cond_3X, // driven by 8 input mux connected to ir(2 downto 0), and ir(3) is xor cond_4, // not used cond_5, // not used continue, // not (DMA_IN or DMA_OUT or INT) continue_sw, // same as above, but also signal to use switch mux in else clause cond_8, // not used externalInt, // for BXI (force false in 1802 mode) counterInt, // for BCI (force false in 1802 mode) alu16_zero, // 16-bit ALU output (used in DBNZ only) cond_CX, // driven by 8 input mux connected to ir(2 downto 0), and ir(3) is xor traceEnabled, // high to trace each instruction traceReady, // high if tracer has processed the trace character false // hard-code to 0 default true; seq_then: .then 8 values next, repeat, return, fork, @ default next; // any label seq_else: .else 8 values next, repeat, return, fork, 0x00..0xFF, @ default next; // any value as it can be a trace charIt can be seen that 20 (C + U + U = 4 + 8 + 8) bits from 64 will be used by the controller, leaving 44 bits to drive the rest of the CPU logic.
These 44 bits are comprised of fields, each field has name, width and set of allowed / disallowed values. There are 2 types of fields:
- "registered" fields which are assumed to cause state to be captured at the end of the microinstruction cycle
- "value" fields which are assumed to directly drive some control signal during this microinstruction cycle.
Good illustration of this is controlling the 16*16 register file. The address value is a "value field" which selects where the address is coming from but does not need to persist, the new value of the register needs to persist based on the "regfield" selection:
// 16 * 16 register file sel_reg: .valfield 3 values zero, one, two, x, n, p default zero; // select source of R0-R15 address reg_r .regfield 3 values same, zero, r_plus_one, r_minus_one, yhi_rlo, rhi_ylo, b_t, - default same;Based on the above, it is clear that:
sel_reg = two, reg_r <= zero ... R(2) <= 0
sel_reg = p, reg_r <= r_plus_one ... R(P) <= R(P) + 1
sel_reg = n, reg_r <= yhi_rlo ... R(N).1 <= Y, R(N).0 <= R(N).0
etc.
However:
reg_r <= same, sel_reg <= <any of 8 values> ... NOP
The above instruction never has to be written by the programmer, that is the purpose of "default" - it will be assumed by the compiler, meaning that if the design is implemented properly, the register will be unaffected.
TTY to VGA controller (microcode):
.code 6, 32, tty_screen_code.mif, tty_screen_code.cgf, tty:tty_screen_code.vhd, tty_screen_code.hex, tty_screen_code.bin, 4; .mapper 7, 6, tty_screen_map.mif, tty_screen_map.cgf, tty:tty_screen_map.vhd, tty_screen_map.hex, tty_screen_map.bin, 1; .controller tty_control_unit.vhd, 4; ... seq_cond: .if 3 values true, // hard-code to 1 char_is_zero, cursorx_ge_maxcol, cursory_ge_maxrow, cursorx_is_zero, cursory_is_zero, memory_ready, false // hard-code to 0 default true; seq_then: .then 6 values next, repeat, return, fork, @ default next; // any label seq_else: .else 6 values next, repeat, return, fork, 0x00..0x3F, @ default next; // any value as it can be a trace char ...- microcode memory of 64 (2^U) words, 32 (W) bits wide
- mapper memory of 128 (2^V) words (maps to 7 bit ASCII), 6 (U) bits wide
- microcode controller with stack depth of 4 (S), consuming 15 (C + U + U = 3 + 6 + 6) bits out of 32, leaving 17 bits to drive the rest of the circuit
-
Proof of concept - TTY to VGA
05/30/2020 at 18:00 • 0 commentsThis component serves 2 purposes:
- illustrates that microcoding can easily be used for non-CPU circuits such as display, I/O, disk, or any other custom controllers
- useful in the project to trace main CPU instructions executing for debugging or illustration purposes
(screenshot tracing first 3 instructions on VGA screen: DIS (0x71), LBR (0xC0), LDI (0xF8))
Discussion below refers to:
VHDL: https://github.com/zpekic/Sys_180X/blob/master/TTY_Screen/tty_screen.vhd
MCC: https://github.com/zpekic/MicroCodeCompiler/blob/master/Microcode/tty_screen.mcc
The circuit spends most time waiting for the CPU to send it a character (8-bit ASCII) to display on the screen. While the character code is 0, it is interpreted as no printing needed, and the TTY keep the ready bit high ('=' assignment):
waitChar: ready = char_is_zero, data <= char, if char_is_zero then repeat else next;Note that at the end of the microcode cycle, the character input will be loaded into the internal data register ('<=' assignment). char_is_zero is a condition presented to the control unit which is true ('1') when char is 0, and if so, uPC (microprogram counter) won't be incremented ("repeat"). As soon as it becomes != 0, "next" will be executed, which simply means increment uPC by 1.
Right after that, we have a classic "fork" - the trick here is that ASCII code is interpreted as "instruction":
0x00 - NOP
0x01 - home (cursor to top, left)
0x02 - clear screen
0x0A - line feed
0x0D - carriage return
0x20-0x7F - printable
if true then fork else fork; // interpret the ASCII code of char in data register as "instruction"
if true then fork else fork; // interpret the ASCII code of char in data register as "instruction"What does "fork" actually do? It is nothing more that loading uPC from a look-up table. The MCC will create this lookup table automatically by the help of .map instructions. This can be seen how the printable char routine is implemented. All locations x20 to x7F will point to the address of this routine:
.map 0b???_????; // default to printable character handler main: gosub printChar; cursorx <= inc; if cursorx_ge_maxcol then next else nextChar; cursorx <= zero, goto LF;Few tricks here:
1. character is defined as 7-bit, not 8 - bit 7 is ignored and in VGA hardware it is hooked up to produce "inverse" characters (dark font or light background). This also cuts mapper memory from 256 to 128 entries
2. map instruction is a match all - all seven bits are '?'. When MCC sees this, it will fill all mapper memory locations with the address of "main". However subsequent .map which are more specific / targeted will override those mapper locations.
The "main" routine above executes in 4 microinstructions (= 4 clock cycles, each ';' denotes 1 cycle)
1. goto to printChar routine (there is no difference between goto and gosub, remember the built-in hardware stack)
2. increment cursorx register. "inc" has no meaning - it is just a label MCC will mantain with a value, it is up to the VDHL to interpret it correctly:
update_cursorx: process(clk, tty_cursorx, cursorx, maxcol) begin if (rising_edge(clk)) then case tty_cursorx is when cursorx_zero => cursorx <= X"00"; when cursorx_inc => cursorx <= std_logic_vector(unsigned(cursorx) + 1); when cursorx_dec => cursorx <= std_logic_vector(unsigned(cursorx) - 1); when cursorx_maxcol => cursorx <= maxcol; when others => null; end case; end if; end process;How this all comes together is through code.vhdl file that MCC produces:
-- -- L0023.cursorx: 3 values same, zero, inc, dec, maxcol default same -- alias uc_cursorx: std_logic_vector(2 downto 0) is ucode(15 downto 13); constant cursorx_same: std_logic_vector(2 downto 0) := "000"; constant cursorx_zero: std_logic_vector(2 downto 0) := "001"; constant cursorx_inc: std_logic_vector(2 downto 0) := "010"; constant cursorx_dec: std_logic_vector(2 downto 0) := "011"; constant cursorx_maxcol: std_logic_vector(2 downto 0) := "100";This is a "package" VHDL source code file generated by MCC which should be included in the main VHDL project. Obviously, there is a dependency - after MCC runs and updates this file with new values, VHDL project must be recompiled too to pick it up.
3. Check if cursor_x reached max screen column (80 in this case for 80*60 VGA screen), if not go back to loop waiting for another printable character, and if yes then continue ("next")
4. set cursor_x to 0 (again, "zero" has no meaning it a label resolved into value 1, and then then MUX loading the cursor_x is supposed to pass 0 at that selection), and proceed with executing the "linefeed" sequence (this may lead to screen scroll up if cursor_y is at lowers row already)
On the "outgoing" side of TTY to VGA, there is the VGA video memory. This memory can be only written too when VGA beam is outside visible range (between rows or frames). At that point the controller can take over the address and data bus from VGA controller, and have access to write to memory. This is done by simply using the VGA "busy" signal as a condition to microcode, and waiting ("repeat") until it becomes free. This is a simple but effective way of synchronizing two independent circuits:
printChar: if memory_ready then next else repeat; mem = write, xsel = cursorx, ysel = cursory, return;the above executes in 2 + wait cycles:
1. wait in loop until memory is ready (VGA is not using the video memory bus)
2. generate memory write signal, present data register to video memory data bus, and address will be generate by cursor x and y.
-- memory interface mwr <= tty_mem(1); mrd <= tty_mem(0); x <= cursorx when (tty_xsel = xsel_cursorx) else altx; y <= cursory when (tty_ysel = ysel_cursory) else alty; dout <= data;As you have guessed it, again "write" is just a simple label with will be resolved to value "10" meaning that write signal is "1" and read signal is "0" (most FPGA logic is "positive", as opposed to many real IC devices with are "negative" ( /RD /WR /CS etc.))
In case of screen scroll-up, the video memory has to be read too - each row from 1 to max is read and written to row above. Reading video memory is similar to writing:
readMem: if memory_ready then next else repeat; mem = read, xsel = cursorx, ysel = cursory, data <= memory, return;The "read" label now simply resolves to "01" (write signal is asserted), and data mux label "memory" should be coded to connect to VGA memory data bus:
update_data: process(clk, tty_data, char, din) begin if (rising_edge(clk)) then case tty_data is when data_char => data <= char; when data_memory => data <= din; when data_space => data <= X"20"; when others => null; end case; end if; end process;Remember that MCC programmer has to keep in mind what is "goto" vs. "gosub" - both readMem and writeMem end with "return" - that simply means that it is assumed that the execution will resume with next instruction after the invocation. That's why the invocation is written as "gosub". For the microcode control unit there is no difference - each "jump" pushes return to hardware stack (until exhausted), and it is up to code to reuse it ("return") or ignore it with another jump.
-
Proof of concept - CDP1802 compatible CPU
05/30/2020 at 18:00 • 1 commentBefore digging into the implementation which can be found here, why 1802?
- A very original CPU design, quite different from other processors of the era
- While a distant third in the 70/80ies hobby computing boom, it was popular and still has dedicated fans in the retrocomputing community
- Original was not microcoded, so it was an extra interest and challenge to re-implement as microcoded design
- While there are many great FPGA implementations of Z80, 6502, and other processors (including my attempt at Am9080), there are few of 1802 and I don't know of any which is microcoded
- I wanted to go beyond 1802 and implement 1805, because there is none of the latter (as far as I know) and also to illustrate the ease how processors can be extended using this technique (as opposed to try to extend 8080 into Z80 or 6502 into 65C02 using standard FSM approach)
For better understanding of the 1802 CPU from the "black box" perspective (and especially to understand its states during each instruction execution) it is useful to look at the data sheets as a refresher:
http://www.cosmacelf.com/publications/data-sheets/cdp1802.pdf
http://datasheets.chipdb.org/Intersil/1805-1806.pdf
Going inside the box, here is the great reverse engineering description:
http://visual6502.org/wiki/index.php?title=RCA_1802E
SAMPLE INSTRUCTION EXECUTION
One way to explain how microcode-driven CPU works is to follow the execution of a single instruction. for example SDB:
SUBTRACT D WITH BORROW SDB 75 M(R(X)) - D - (NOT DF) → DF, D
Note that it executes in machine 2 states ( == 16 clock cycles):
S0 FETCH MRP → I, N; RP + 1 → RP MRP RP 0 1 0
S1 7 5 SDB MRX - D - DFN → DF, D MRX RX 0 1 0
(1) Execution starts with fetch microinstruction:
// Read memory into instruction register // --------------------------------------------------------------------------- fetch: fetch_memread, sel_reg = p, reg_in <= alu_y, y_bus, reg_inc;fetch_memread ... this is an alias to set the bus_state = fetch_memread; fetch_memread is nothing more that an symbolic name for a location in a look-up table:
signal state_rom: rom16x8 := ( -- SC1 SC0 RD WR OE NE S1S2 S1S2S3 "01000011", -- exec_nop, // 0 1 0 0 0 0 1 1 "01100011", -- exec_memread, // 0 1 1 0 0 0 1 1 "01011011", -- exec_memwrite, // 0 1 0 1 1 0 1 1 "01010111", -- exec_ioread, // 0 1 0 1 0 1 1 1 "01100111", -- exec_iowrite, // 0 1 1 0 0 1 1 1 "10100011", -- dma_memread, // 1 0 1 0 0 0 1 1 "10010011", -- dma_memwrite, // 1 0 0 1 0 0 1 1 "11000001", -- int_nop, // 1 1 0 0 0 0 0 1 "00100000", -- fetch_memread, // 0 0 1 0 0 0 0 0 "00000000", "00000000", "00000000", "00000000", "00000000", "00000000", "00000000" );As expected, this will drive the S1, S0, nRD, nWR, N CPU signals to the right levels / values. Note that OE ("output enable") of D bus is 0 meaning it will be in hi-Z state, therefore input.
sel_reg = p ... value of P register will be presented as address to the 16*16 register stack:
-- Register array data path with cpu_sel_reg select sel_reg <= X"0" when sel_reg_zero, X"1" when sel_reg_one, X"2" when sel_reg_two, reg_x when sel_reg_x, reg_n when sel_reg_n, reg_p when sel_reg_p, sel_reg when others; reg_y <= reg_r(to_integer(unsigned(sel_reg)));reg_y signal (16 bits) will show the value of the P (program counter). The simple beauty of 1802 is that this will go directly to the A outputs, no loading of separate MAR (memory address register) is needed, as such register doesn't even exist.
reg_inc ... this is the alias (== shortcut) for:
reg_inc: .alias reg_r <= r_plus_one;
Important is to notice the <= notation - that means there will be a register updated at the end of the cycle, in this case R(P) (value of reg_y in snippet above) will be added 1:
update_r: process(UCLK, cpu_reg_r, reg_r, sel_reg, reg_b, reg_t, alu_y, alu16_y) begin if (rising_edge(UCLK)) then case cpu_reg_r is when reg_r_zero => reg_r(to_integer(unsigned(sel_reg))) <= X"0000"; when reg_r_r_plus_one => reg_r(to_integer(unsigned(sel_reg))) <= std_logic_vector(unsigned(reg_y) + 1); when reg_r_r_minus_one => reg_r(to_integer(unsigned(sel_reg))) <= std_logic_vector(unsigned(reg_y) - 1); when reg_r_yhi_rlo => reg_r(to_integer(unsigned(sel_reg))) <= alu_y & reg_lo; when reg_r_rhi_ylo => reg_r(to_integer(unsigned(sel_reg))) <= reg_hi & alu_y; when reg_r_b_t => reg_r(to_integer(unsigned(sel_reg))) <= reg_b & reg_t; when others => null; end case; end if; end process;Finally, the IN (instruction register must be loaded):
reg_in <= alu_y, y_bus,
<= again indicates state change ("load") at the end of the cycle - IN will be loaded from the output of ALU:
-- update IN (instruction) register update_in: process(UCLK, cpu_reg_in, alu_y) begin if (rising_edge(UCLK)) then case cpu_reg_in is when reg_in_alu_y => reg_in <= alu_y; when others => null; end case; end if; end process;and the ALU will pass through the D (data bus) value (see ALU description below for more details):
y_bus: .alias alu_f = pass_s, alu_s = bus;In summary, the fetch microinstruction engaged multiple elements of the CPU to orchestrate a read cycle to memory, addressed by the register designated as program counter, and at the end of cycle update the instruction register with the value loaded from memory, and incrementing the program counter.
(2) Next is to load the memory addressed by X
This cycle is very similar to fetch, except:
- register is selected by X not P
- destination register is B, not IN
- machine state is "execute" not fetch:
// Given that instruction register is loaded late, execute 1 more cycle before forking. It is useful to load B <= M(X) // ---------------------------------------------------------------------------- load_b: exec_memread, sel_reg = x, reg_b <= alu_y, y_bus, if traceEnabled then traceState else fork;The interesting part is what happens next - in regular CPU execution would proceed with the routine implementing SDB, but with microcoded design it is very convenient to code the trace / debug routine in the same microcode - the "traceEnabled" is simply an external pin which when pulled high will cause the tracer routine to dump the state of all the registers (see here) . If low, the "fork" will be activated.
What does "fork" do? It simply loads the address of the implementation routine into the microprogram counter. The MCC compiler will automatically generate the lookup table ("mapper memory") for all the instructions given by their instruction format pattern. In this case, the location 0x75 (code of SDB) in mapper memory will contain value of 0x90 (144) which is the entry point to execute SDB:
-- L0412@0090.SDB: reg_df <= alu_cout, reg_d <= alu_y, alu_f = r_plus_ns, alu_r = b, alu_s = d, alu_cin = df,if continue then fetch else dma_or_int -- bus_state = 0000, if (0110) then 00000100 else 00010000, reg_d <= 001, reg_df <= 11, reg_t <= 00, reg_b <= 00, reg_x <= 00, reg_p <= 00, reg_in <= 0, reg_q <= 00, reg_mie <= 00, reg_trace <= 00, reg_extend <= 00, sel_reg = 000, reg_r <= 000, alu_r = 10, alu_s = 01, alu_f = 101, alu_cin = 1, ct_oper = 0000; 144 => X"0" & X"6" & X"04" & X"10" & O"1" & "11" & "00" & "00" & "00" & "00" & '0' & "00" & "00" & "00" & "00" & O"0" & O"0" & "10" & "01" & O"5" & '1' & X"0",This pattern can be easily seen if inspecting the contents of generated mapper file - it can be easily seen how all PLO, PHI, LDN, GLO, GHI all map to same locations, but for example IDL is unique etc.
Latencies in the circuits and esp. analysing the maximum latency part are crucial to make any of them work. This comes to play in big way in the "fork" too, as the latency is:
mapper memory address (== IN contents) to data propagation
+
control unit then/else MUX propagation
+
control unit next address MUX propagation
Given that the IN register became valid at the end of previous cycle, there is not enough time for the next cycle to have the proper fork address. That's why regardless of the instruction the B <= M(X) cycle is inserted. This way the fork propagation goes on in parallel with the useful memory read. This presents a problem though as it causes this particular design to be NOT CYCLE ACCURATE - all instructions will read M(X) but only a subset such will use it. This causes a certain loss of perfomance (which is offset by less cycles executing some other instructions though).
In most CPUs this is not a problem, 1 clock cycle delay is sufficient for the propagation, but 1802 has rigid 8 to 1 clock/machine cycle timing so the simplest solution was to insert the B <= M(X) at this point.
(3) Finally, execute:
With memory data in B register, executing is simple:
.map 0b0_0111_0101; SDB: reg_df <= alu_cout, reg_d <= alu_y, y_b_minus_d, alu_cin = df, if continue then fetch else dma_or_int;Two registers will be updates, as indicated by "<=":
DF ... should get its value from ALU carry-out:
-- update DF (data flag == carry) register update_df: process(UCLK, cpu_reg_df, alu_cout, reg_d) begin if (rising_edge(UCLK)) then case cpu_reg_df is when reg_df_d_msb => reg_df <= reg_d(7); when reg_df_d_lsb => reg_df <= reg_d(0); when reg_df_alu_cout => reg_df <= alu_cout; when others => null; end case; end if; end process;D ... should get its value obviously from the ALU output:
-- update D (data == accumulator) register update_d: process(UCLK, cpu_reg_d, alu_y, reg_df) begin if (rising_edge(UCLK)) then case cpu_reg_d is when reg_d_alu_y => reg_d <= alu_y; when reg_d_shift_dn_df => reg_d <= reg_df & reg_d(7 downto 1); when reg_d_shift_dn_0 => reg_d <= '0' & reg_d(7 downto 1); when others => null; end case; end if; end process;The ALU operation is described below, but for it to work, proper values need to be presented to ALU inputs R and S (D and B registers). This is accomplished by a pair of MUXs driven by following microcode fields:
// 8-bit ALU for arithmetic and logical operations // the binary / decimal mode comes directly from instruction bit 8 (reg_extend) as 68XX arithmetic instructions are all decimal alu_r: .valfield 2 values t, d, b, reg_hi default t; alu_s: .valfield 2 values bus, d, const, reg_lo default bus; // const comes from "else" valueMCC will generate the code to help pull it together:
-- -- L0076.alu_r: 2 values t, d, b, reg_hi default t -- alias cpu_alu_r: std_logic_vector(1 downto 0) is cpu_uinstruction(11 downto 10); constant alu_r_t: std_logic_vector(1 downto 0) := "00"; constant alu_r_d: std_logic_vector(1 downto 0) := "01"; constant alu_r_b: std_logic_vector(1 downto 0) := "10"; constant alu_r_reg_hi: std_logic_vector(1 downto 0) := "11"; -- -- L0077.alu_s: 2 values bus, d, const, reg_lo default bus -- alias cpu_alu_s: std_logic_vector(1 downto 0) is cpu_uinstruction(9 downto 8); constant alu_s_bus: std_logic_vector(1 downto 0) := "00"; constant alu_s_d: std_logic_vector(1 downto 0) := "01"; constant alu_s_const: std_logic_vector(1 downto 0) := "10"; constant alu_s_reg_lo: std_logic_vector(1 downto 0) := "11";The only thing remaining for the developer to do is simply to use the values generated and implement the 2 MUXs - the whole design is pretty much on "rails" which minimized the chances of bugs:
-- ALU data path with cpu_alu_r select r <= reg_t when alu_r_t, reg_d when alu_r_d, reg_b when alu_r_b, reg_hi when alu_r_reg_hi; -- R(sel_reg).1 TODO with cpu_alu_s select s <= data_in when alu_s_bus, -- data bus input reg_d when alu_s_d, cpu_seq_else when alu_s_const, -- "constant" is reused else field reg_lo when alu_s_reg_lo; -- R(sel_reg).0 TODO with cpu_alu_cin select alu_cin <= cpu_alu_f(1) or cpu_alu_f(0) when alu_cin_f1_or_f0, -- this will be 0 for add (no carry) and 1 for substract (no borrow) reg_df when alu_cin_df;(4) What to do after execution?
There are two possibilities:
if continue then fetch else dma_or_int;
If "continue" conditional input is true, then loop back to execute next fetch / execute (remember, R(P) now points to next instruction already)
If "continue" conditional input is low, then service DMA or INT request.
At specific moments of machine cycles, the state of DMAOUT, DMAIN and INT are captured, and in addition INT is conditioned on the state of MIE (master interrupt enable flag):
-- capture state of interrupt capture_int: process(nINTERRUPT, cycle_di, state_s1s2) begin if (falling_edge(cycle_di) and (state_s1s2 = '1')) then reg_int <= reg_mie and (not nINTERRUPT); end if; end process; -- capture state of dma requests capture_dma: process(nDMAIN, nDMAOUT, cycle_di, state_s1s2s3) begin if (falling_edge(cycle_di) and (state_s1s2s3 = '1')) then reg_dma <= (not nDMAIN) & (not nDMAOUT); end if; end process; continue <= not (reg_int or reg_dma(1) or reg_dma(0)); -- no external signal receivedSo at the end of instruction, a decision can be made if to proceed to service these async requests.
HANDLING DMA AND INT
1802 establishes the following priority of requests:
(1) DMA IN
(2) DMA OUT
(3) INTERRUPT
It would be simple to respond to these as consecutive "if request then ... else ..." microcode instructions, but that would mean delay to start servicing INTERRUPT even if there is no DMA IN/OUT request. Clearly, what is needed is a "switch" - like statement that checks for 8 possible states of these 3 requests and in 1 machine cycle starts executing the request.
This is accomplished by "injecting" a special branch destination to the "else" branch if the condition is "seq_cond_continue_sw":
-- "switch statement" for 8 possible combinations of DMA and INT states seq_else <= ("0001" & reg_dma & reg_int & '1') when (to_integer(unsigned(cpu_seq_cond)) = seq_cond_continue_sw) else cpu_seq_else;The branch destinations will be:
0x11 - when there is no request
...
0x1F -when all requests come in simultaneously
The "switch value" is injected on positions 3 downto 0, so that there is place for 2 microinstructions for each case. Now the only thing code needs to do is to respond to the highest received request, ignore the others (first 4 cases below):
// Respond to DMA or INT requests (using simple switch mechanism) // These requests are honored at the end of each instruction execution // -------------------------------------------------------------------------- .org 0b0001_0000; dma_or_int: if continue_sw then fetch else dma_or_int; // else mux is else(7 downto 3) & dma_in & dma_out & int & '1' .org 0b0001_0001; // no special cycle needed, start a new fetch fetch1: fetch_memread, sel_reg = p, reg_in <= alu_y, y_bus, reg_inc, goto load_b; .org 0b0001_0011; // INT int_ack: int_nop, y_const, reg_t <= xp, reg_x <= alu_yhi, reg_p <= alu_ylo, // T <= XP, X <= 2, P <= 1 reg_mie <= disable, if true then fetch else 0x21; .org 0b0001_0101; // DMA_OUT dma_out: dma_memread, sel_reg = zero, reg_inc, // DEVICE <= M(R(0)), R(0) <= R(0) + 1 if continue then fetch else dma_or_int; .org 0b0001_0111; // DMA_OUT, INT ignored dma_memread, sel_reg = zero, reg_inc, // DEVICE <= M(R(0)), R(0) <= R(0) + 1 if continue then fetch else dma_or_int;Note that after INT is acknowleged, at least 1 more instruction will be executed ("if true then fetch"), this is a bug as according to state diagram, from INT it is possible to get directly to DMA IN/OUT without executing any instruction. The fix will be to replace with "if continue then fetch else dma_or_int".
EXECUTING EXTENDED INSTRUCTIONS
Many successful CPUs had successors implementing enhanced instructions / capabilities. The canonical example is Z80 which enhanced 8080 with new registers and instructions following the "escape codes" 0xCB, 0xDD, 0xED, 0xFD. 1802 is no exception, the successors 1804, 05, 06 introduced new instructions with escape code 0x68 which was a NOP in original 1802.
For CPUs implemented as state machines, extending the instruction set effectively means re-writing the state machine. This is a huge advantage of microcoded designs, where this task becomes a matter of another "if" microinstruction. Here is the implementation of 0x68 op-code:
.map 0b0_0110_1000; // override for INP 0 is the linking opcode for extended instructions EXTEND: if mode_1805 then next else NOP; fetch_memread, sel_reg = p, reg_in <= alu_y, y_bus, reg_extend <= one, reg_inc, goto load_b;2 microinstructions can be seen:
(1) if not in 1805 mode (the control pin is down) then interpret as a NOP, otherwise continue
(2) flip the reg_extend bit to 1 and execute fetch of the next op-code
The reg_extend bit is treated as bit 8 (9th bit) of the instruction register, which makes sense as the 1805 op-code matrix is 2*256 entries. That is the reason why the mapper memory has 512 entries (9 address bits depth):
.code 8, 64, cdp180x_code.mif, cdp180x_code.cgf, cdp180x_code.coe, cpu:cdp180x_code.vhd, cdp180x_code.hex, cdp180x_code.bin, 8; .mapper 9, 8, cdp180x_map.mif, cdp180x_map.cgf, cdp180x_map.coe, cpu:cdp180x_map.vhd, cdp180x_map.hex, cdp180x_map.bin, 1; .controller cpu_control_unit.vhd, 8;With 9th bit flipped to 1, it is easy to map extended instructions, for example DBNZ (0x68, 0x2X):
.map 0b1_0010_????; DBNZ: reg_extend <= zero, sel_reg = n, reg_dec, if alu16_zero then skip2 else next; // zero detection is connected to the output of the incrementer/decrementer exec_memread, sel_reg = p, reg_b <= alu_y, y_bus, reg_inc; // B <= M(R(P)), R(P) <= R(P) + 1 exec_memread, sel_reg = p, reg_r <= rhi_ylo, y_bus; // R(P).0 <= M(R(P)) sel_reg = p, reg_r <= yhi_rlo, y_b, // R(P).1 <= B if continue then fetch else dma_or_int;It is obviously important to flip the reg_extended bit back to '0' before next fetch otherwise instruction interpretation would go terribly awry.
Interestingly, in 1805 BCD instructions are mapped to exact same opcodes as their binary counterparts. No doubt, internally in the original CPU this was done for a reason to simplify the control unit. In case of microcode, this means 2 op-codes mapped to same execution (e.g ADI and DADI):
.map 0b0_1111_1100; .map 0b1_1111_1100; // "bcd mode" will be 1 because reg_extend == 1 therefore BCD add will be executed ADI: exec_memread, sel_reg = p, reg_b <= alu_y, y_bus, reg_inc, goto ADD;Side note about the instruction above: recall that each instructions starts with M(R(X)) loaded in B. For immediate value instructions that is not useful, so B <= M(R(P)) must be executed in first microinstruction, with R(P) incremented at the end of the same microinstruction to point to the next opcode. After that, there is no longer a difference between ADI and ADD (or SMI and SM etc.) so simply jump and proceed there.
As an optimization, 1 machine cycle could be saved by avoiding "goto ADD" and simply duplicating that microinstruction instead.
DEFINING MACHINE CYCLES
A unique characteristic of 1802 CPUs is the relationship between machine and clock cycles:
1 machine cycle = 8 clock cycles
As an additional complication, signal changes do not occur always on the same transition during those 8 cycles - sometimes they are on L->H and sometimes on H->L. I solved this by combining the 8 counter values (in 1 machine cycles) with CLK state to achive 16 states, which drive a simple lookup table that hard-codes the values of bus control signals:
type rom16x8 is array(0 to 15) of std_logic_vector(7 downto 0); signal cycle_rom: rom16x8 := ( "00100011", -- 00 MA_HIGH EF UC "00100011", -- 01 MA_HIGH EF UC "10100011", -- 10 TPA MA_HIGH EF UC "10110001", -- 11 TPA MA_HIGH RD UC "00110001", -- 20 MA_HIGH RD UC "00010001", -- 21 RD UC "00010001", -- 30 RD UC "00010001", -- 31 RD UC "00010001", -- 40 RD UC "00010001", -- 41 RD UC "00011001", -- 50 RD WR UC "00011001", -- 51 RD WR UC "00011101", -- 60 RD WR DI UC "01011101", -- 61 TPB RD WR DI UC "01011001", -- 70 TPB RD WR UC "00000000" -- 71 );One can read the timing of signals (for example TPA == bit 7) from top to bottom as the machine cycle unfolds.
The microcode doesn't know or care about it. It advances on UC (bit 0) which pulses low in state "71".
However, each microinstruction brings its own "machine cycle state", which in effect from state 00 to 71. For example INP:
.map 0b0_0110_1???; INP: exec_ioread, sel_reg = x, y_bus, reg_d <= alu_y, if continue then fetch else dma_or_int;exec_ioread is an index into another lookup table ("state_rom") which has RD enabled and WR disabled (and obviously N MUX selecting bits 3..0 from instruction register, instead of 000). This will be combined with the cycle table to produce the exact timing of the pulses:
-- machine cycle (8 clocks, fixed) cnt16 <= cnt8 & CLOCK; cycle <= cycle_rom(to_integer(unsigned(cnt16))); -- CPU state (driven by microcode) state <= state_rom(to_integer(unsigned(cpu_bus_state))); -- driving output control signals, which are a combination of cycle and state TPA <= cycle_tpa; TPB <= cycle_tpb; Q <= reg_q; N <= reg_n(2 downto 0) when (state_ne = '1') else "000"; -- note that 60 and 68 will still generate N=000 SC <= state_sc; -- ADDRESS BUS - always reflects currently selected R(?), R(?).1 in first 5 periods, R(?).0 in remaining 11 MA <= reg_hi when (cycle_ahi = '1') else reg_lo; A <= reg_y; -- READ/WRITE at specific timing in the cycle, if enabled by CPU state nMRD <= not (state_rd and cycle_rd); nMWR <= not (state_wr and cycle_wr); -- DATA BUS - drive and capture at specific moments in the cycle DBUS <= alu_y when ((state_oe and cycle_wr) = '1') else "ZZZZZZZZ";ALU
Arithmetic - logic units are obviously important part of any CPU, and they can vary a lot in capabilities and complexities. The one in 1802 would be one of the simplest, using straightforward 2's complement binary adder with few binary operations thrown in. However 1805 adds a complications - 8-bit BCD add/substract, with carry / borrow obviously.
Inspecting the 1802/05 instruction set, the following operations are needed, and described in the microcode:
alu_f: .valfield 3 values xor, and, ior, pass_r, r_plus_s, r_plus_ns, nr_plus_s, pass_s default xor; // f2 selects logic/add, f1 and f0 flip r/sThis translates to autogenerated VHD:
-- -- L0087.alu_f: 3 values xor, and, ior, pass_r, r_plus_s, r_plus_ns, nr_plus_s, pass_s default xor -- alias cpu_alu_f: std_logic_vector(2 downto 0) is cpu_uinstruction(7 downto 5); constant alu_f_xor: std_logic_vector(2 downto 0) := "000"; constant alu_f_and: std_logic_vector(2 downto 0) := "001"; constant alu_f_ior: std_logic_vector(2 downto 0) := "010"; constant alu_f_pass_r: std_logic_vector(2 downto 0) := "011"; constant alu_f_r_plus_s: std_logic_vector(2 downto 0) := "100"; constant alu_f_r_plus_ns: std_logic_vector(2 downto 0) := "101"; constant alu_f_nr_plus_s: std_logic_vector(2 downto 0) := "110"; constant alu_f_pass_s: std_logic_vector(2 downto 0) := "111";(read: 3 control bits names "cpu_alu_f" spanning bit positions 7 to 5 of the current microinstruction determine the ALU operation)
The implementation is pretty apparent - it boils down to a 8-bit wide 8-to-1 MUX:
with cpu_alu_f select alu_y <= r xor s when alu_f_xor, r and s when alu_f_and, r or s when alu_f_ior, r when alu_f_pass_r, add_y when alu_f_r_plus_s, add_y when alu_f_r_plus_ns, add_y when alu_f_nr_plus_s, s when alu_f_pass_s;The interesting part is that 3 out of 8 combinations above pass the result of adder. cpu_alu_f(1 downto 0) also control the "complement" of the adder to implement subtract operation. This is handy to implement
SD (hint: check what y_b_minus_d alias resolves into)
.map 0b0_1111_0101; SD: reg_df <= alu_cout, reg_d <= alu_y, y_b_minus_d, alu_cin = f1_or_f0, // cin = 1 if continue then fetch else dma_or_int;vs.
SM (see y_d_minus_b alias, it is obviously flip of the one used for SD)
.map 0b0_1111_0111; .map 0b1_1111_0111; // "bcd mode" will be 1 because reg_extend == 1 therefore BCD add will be executed SM: reg_extend <= zero, reg_df <= alu_cout, reg_d <= alu_y, y_d_minus_b, alu_cin = f1_or_f0, // cin = 1 if continue then fetch else dma_or_int;It is not useful to have both inputs complemented ("Y = -R - S") so that combination is discarded, and instead a convenient "Y = S" bypass is implemented (alu_f_pass_s).
For purely 1802, simplest adder with 2 8-bit XORs inverting the inputs would suffice, but because 1805 has BCD, that would not work because BCD needs to be corrected within 4 bits and the so-called "half carry" passed between BCD digits.
Many processors implement this using a special "DAA" (decimal adjust accumulator) step which is either an extra instruction (8080, 8085, Z80), or executed as extra step for special BCD operations (which is the approach 1805 uses, the machine cycle listing for example for DADD (0x68F4) instruction and others like that makes it clear that last cycle is a "DAA".)
That cycle can be saved if inspiration can be taken from 6502 processor, which has a "D" flag - when set, all ADD/SUB become BCD operations instead of binary, as described in the following classic patent #3991307 by Peddle et al. The difference is that I used lookup tables (clean way for FPGAs) instead of logic to implement BCD add and substract (as explained below)
Looking at 1805 instruction set, it becomes obvious that all ADD/SUB operations are BCD in the extended instruction set, and binary in the regular 1802 set. Which means that the extra instruction bit (reg_extend of the instruction register) can be used as the "D" flag bit:
adder_lo: nibbleadder Port map ( cin => alu_cin, a => r(3 downto 0), b => s(3 downto 0), na => cpu_alu_f(1), nb => cpu_alu_f(0), bcd => reg_extend, -- all 68XX add/sub is in BCD mode y => add_y(3 downto 0), cout => cout ); adder_hi: nibbleadder Port map ( cin => cout, a => r(7 downto 4), b => s(7 downto 4), na => cpu_alu_f(1), nb => cpu_alu_f(0), bcd => reg_extend, y => add_y(7 downto 4), cout => alu_cout );The "cout" (carry out) from lower nibble is passed as carry in to upper nibble as expected - but the trick is that this half carry will depend on the mode:
07
07
----
0E -- binary, there was no half carry
07
07
---
14 - decimal, half carry was generated in the lower nibble
How is the "nibbleadder" implemented?
First, each input (S and R) can be in passed in:
- unchanged (binary and BCD add)
- 1's complemented (binary subtract - done using simple XOR with "1111")
- 9's complemented (BCD substract - this is done using a lookup table)
with sel_r select r <= a when "00", -- binary add a xor X"F" when "01", -- binary sub a when "10", -- bcd add a_compl9(to_integer(unsigned(a))) when "11"; -- bcd subThen, the 2 6-bit numbers (why 6? this is the usual FPGA trick - on the LSB side the operand side is extended to capture the carry in, and on the MSB side with "0" so that the resulting sum reflects the generated carry-out in MSB of the result) when operands are added.
sum_bin <= std_logic_vector(unsigned('0' & r & '1') + unsigned('0' & s & cin));The sum and carry is also used to lookup in BCD correction table (so for example E with carry out of 0 becomes 4 with carry out of 1, and the maximum possible BCD value of 9 + 9 + 1 = 3 carry out 1, becomes 9 with cary out of 1)
sum_bcd <= adcbcd(to_integer(unsigned(sum_bin(5 downto 1))));Finally, if the ALU is in the BCD mode, the corrected result (sum and carry out) is MUXed to the output, otherwise the binary addition result is.
y <= sum_bin(4 downto 1) when (bcd = '0') else sum_bcd(3 downto 0); cout <= sum_bin(5) when (bcd = '0') else sum_bcd(4);Similar to 6502 (but not to 8080 and its descendants), the 1802 DF (= carry) flag has the "natural" state of the 2's complement borrow bit preserved. This means that for binary and BCD substract operations DF = 1 means no borrow has occured, and DF = 0 means there is a borrow. That also means that DF should be set to "1" for operations that start the subtract chain (SD), and to "0" which start the add chain (ADD). Therefore following carry in options are needed:
- 0 for ADD, ADI
- 1 for SD,SM, SMI, SBI
- DF for ADC, ADCI (DF means "carry")
- DF for SDB, SMB, SDBI, SMBI (DF means "borrow")
With some "cleverness" this boils down to just 2 options - either DF directly, or the OR of the low 2 bits of the function because if any of those is "1" means it is a subtract therefore 1 must be passed in as carry in, and if both are 0, that is an "add" so by default carry in should be 0:
alu_cin: .valfield 1 values f1_or_f0, df default f1_or_f0; // f1_or_f1 will generate 0 for add, and 1 for subtract
Microcoding for FPGAs
A microcode compiler developed to fit into FPGA toolchain and validated to develop CDP1805-like CPU and text-based video controller