-
Instability Followup and Resolution
03/30/2022 at 15:36 • 0 commentsThe OSD instability I encountered after the kernel update persisted though with less frequency. I've finally determined that cause is a confluence of small issues that amplify each other:
- Power Supply Aging - The 5V 10A supplies have lost a small amount of their output headroom with age.
- CPU Governor Changes - The ondemand CPU governor is no longer as aggressive at reducing the CPU frequency
- CPU Aging - The CPU and PCIe controller appear to have become more prone to core undervoltage.
I've remediated the instability by underclocking the CPU. Underclocking was insufficient on its own, so I've also applied slight overvoltage as well. The OSD RPi's have been holding steady after applying both changes.
Here's the current state pf my usercfg.txt:
# Place "config.txt" changes (dtparam, dtoverlay, disable_overscan, etc.) in # this file. Please refer to the README file for a description of the various # configuration files on the boot partition. max_usb_current=1 over_voltage=2 arm_freq=500These changes have not appeared to impact my Ceph performance.
-
Unstable Kernel (5.4.0-1041-raspi)
08/24/2021 at 16:42 • 0 commentsThe linux-image-5.4.0-1041-raspi version of the Ubuntu linux-image package appears to be unstable. I've had two of the OSD RPi boards randomly lockup. The boards recover on their own once power-cycled, but this is the first time I've observed this behavior. There no messages in the system logs. The logs simply stop at the time of the lockup, and resume on reboot. I've upgraded all of the RPis to the latest image version (1042) which should hopefully resolve the issue.
-
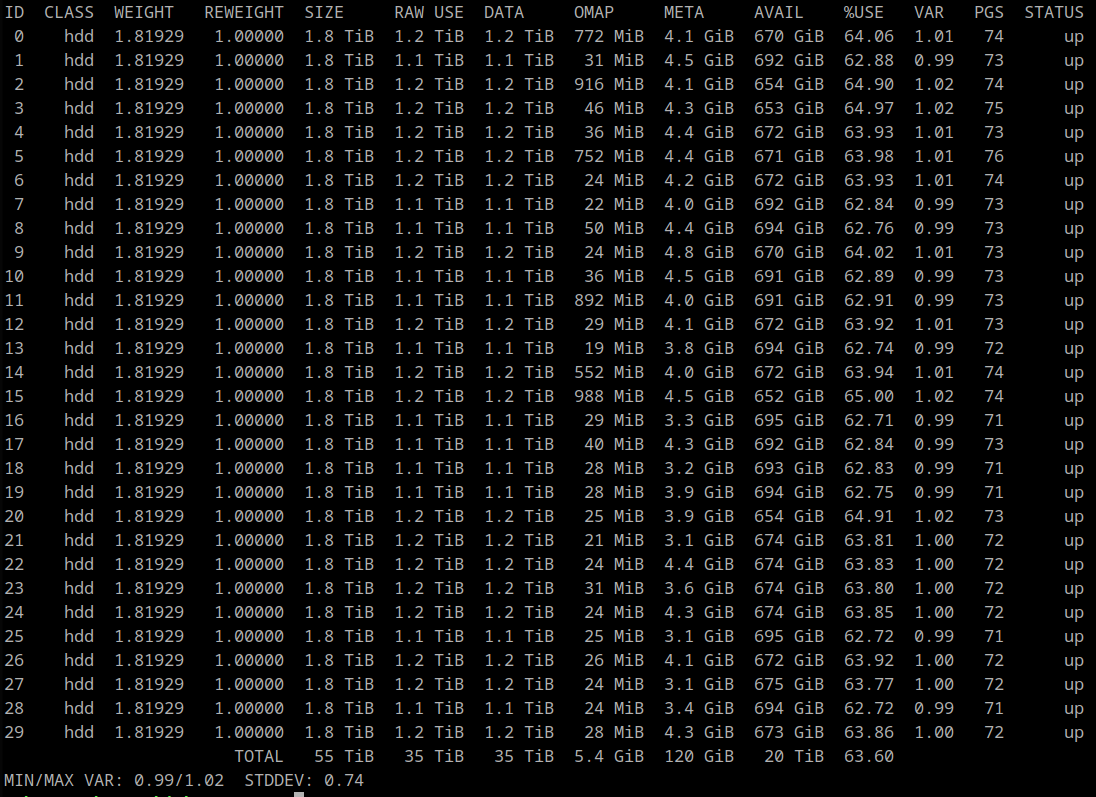
Rebalance Complete
06/28/2021 at 14:26 • 0 comments -
Two More OSDs
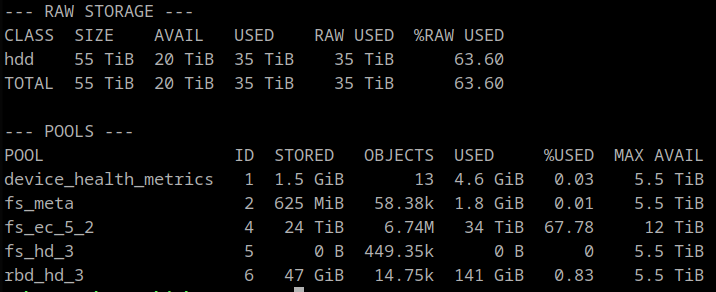
06/17/2021 at 01:40 • 0 commentsI've added the last two drives for this round of expansion which brings the total for the cluster to 34 HDDs (OSDs). Amazon would not allow me to purchase more of the STGX2000400 drives, so I went with the STKB2000412 drives instead. They have roughly the same performance, but cost about $4 more per drive. The aluminum top portion of the case should provide better thermal performance though.
![]()
-
Additional Storage
06/09/2021 at 01:32 • 0 commentsAdded the first two of four additional drives. I plan to add the other two once the rebalance completes.
-
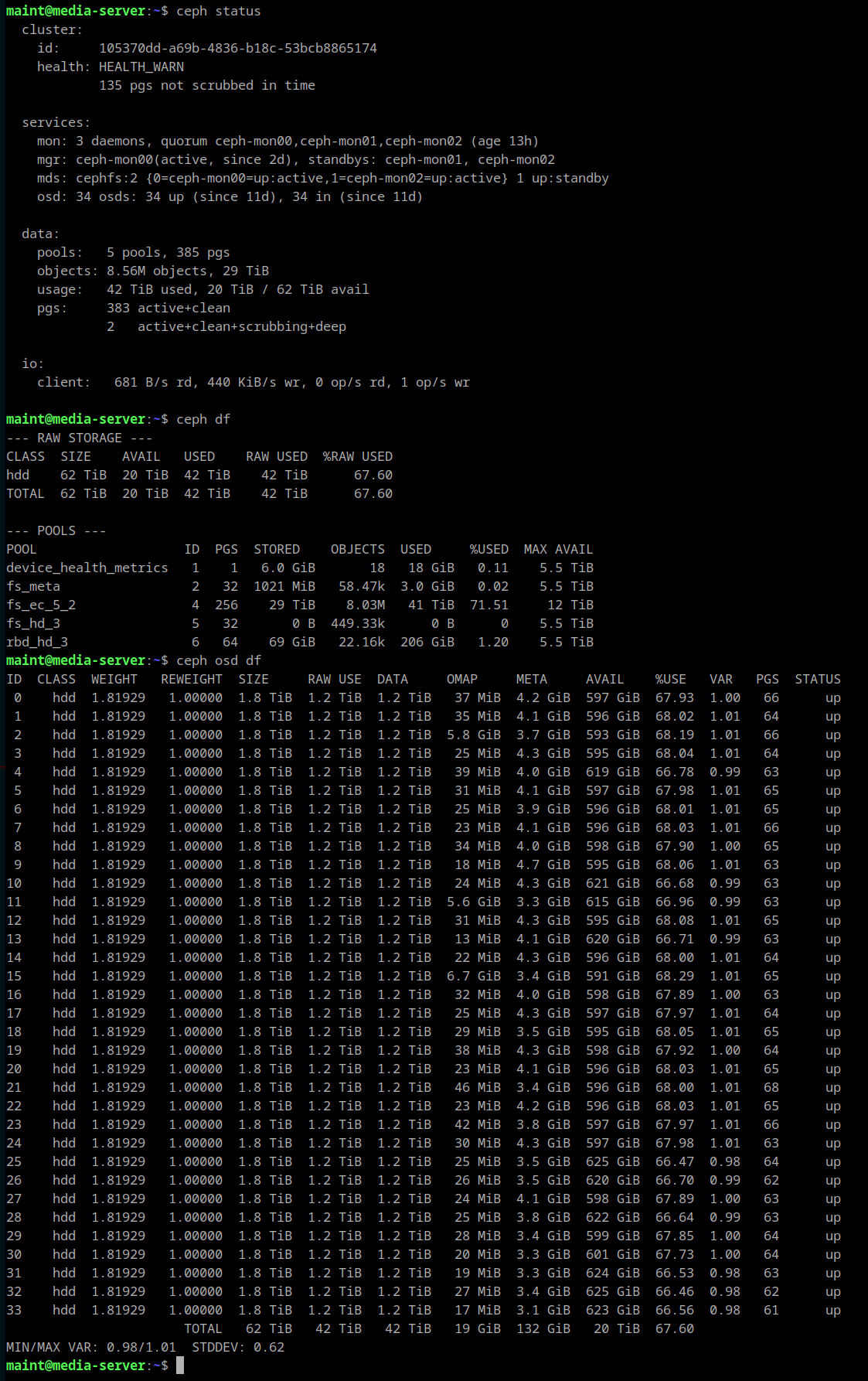
OSD Recovery Complete
05/19/2021 at 03:24 • 0 commentsOnce the failed drive was replaced, the cluster was able to rebalance and repair the inconsistent PGs.
cluster: id: 105370dd-a69b-4836-b18c-53bcb8865174 health: HEALTH_OK services: mon: 3 daemons, quorum ceph-mon00,ceph-mon01,ceph-mon02 (age 33m) mgr: ceph-mon02(active, since 13d), standbys: ceph-mon00, ceph-mon01 mds: cephfs:2 {0=ceph-mon00=up:active,1=ceph-mon02=up:active} 1 up:standby osd: 30 osds: 30 up (since 9d), 30 in (since 9d) data: pools: 5 pools, 385 pgs objects: 8.42M objects, 29 TiB usage: 41 TiB used, 14 TiB / 55 TiB avail pgs: 385 active+clean io: client: 7.7 KiB/s wr, 0 op/s rd, 0 op/s wrAfter poking around on the failed drive, it looks like the actual 2.5" drive itself is fine. The USB-to-SATA controller seems to be culprit, and randomly garbles data over the USB interface. I was also able to observe it fail to enumerate on the USB bus. A failure rate of 1 in 30 isn't bad considering the cost of the drives.
-
OSD Failure
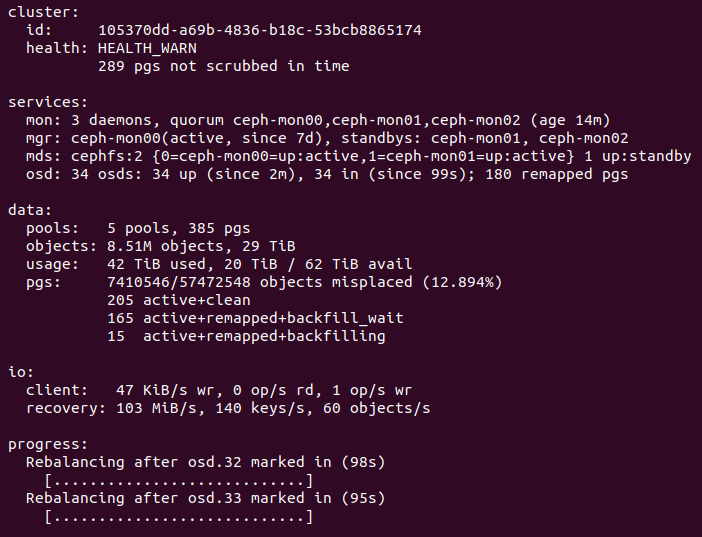
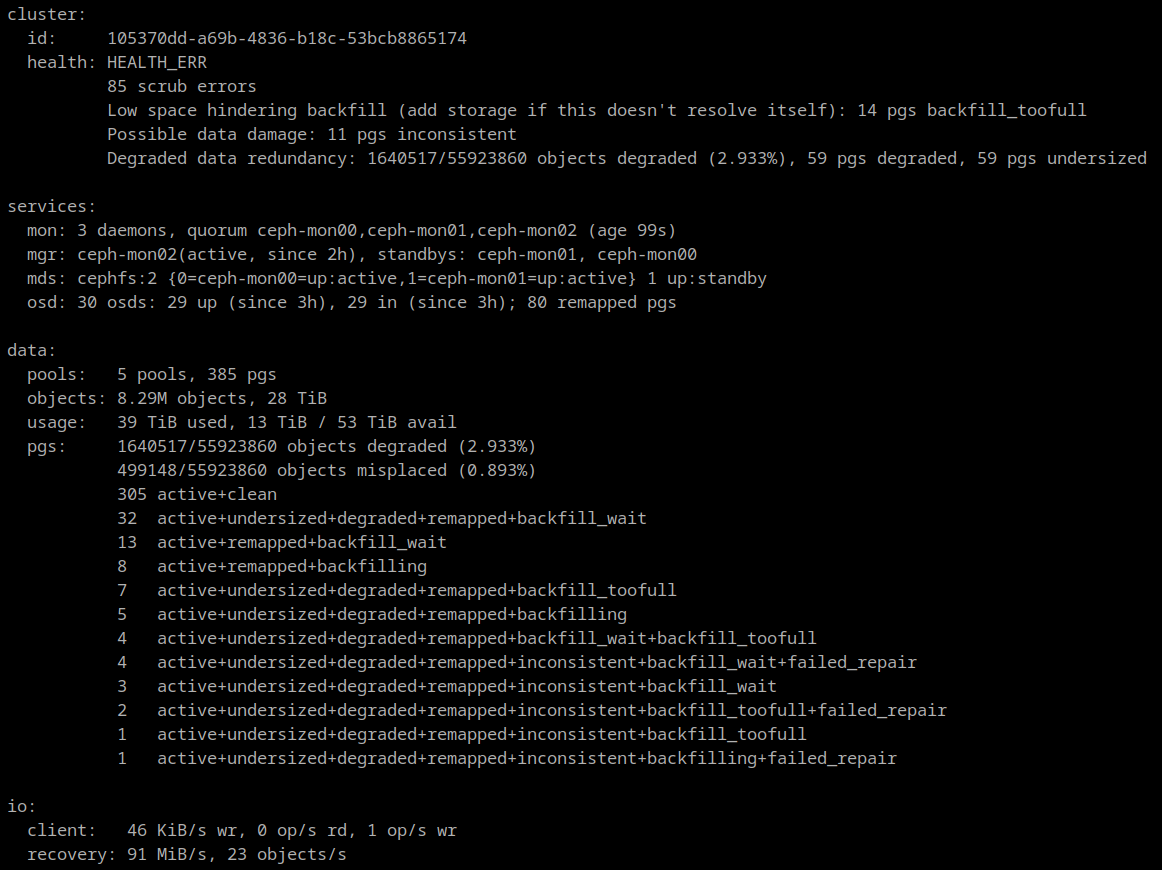
05/04/2021 at 19:13 • 0 commentsThe deep scrubs turned up a few more repairable inconsistencies until a few days ago when they grew concerning. It turned out that one of the OSDs had unexplained read errors. Smartctl showed that there were no read errors recorded by the disk, so I initially assumed it was just the result of a power failure. It became obvious that something was physically wrong with the disk when previously clean or repaired PGs were found to have new errors.
As a result I've marked the suspect OSD out of the cluster and I have ordered a replacement drive. The exact cause of the read errors is unknown, but since it is isolated to a single drive, and the other OSD on the same RPi is fine, it's most likely just a bad drive.
Ceph is currently rebuilding the data from the bad drive, and I'll post an update once the new drive arrives.
The inconsistent PGs all have a single OSD in common: 2147483647 (formerly identified as 25)
-
Inconsistent Placement Group
04/08/2021 at 16:54 • 0 commentsThe OSD deep scrubbing found an inconsistency in one of the placement groups. I've marked the PG in question for repair, so hopefully it's correctable and is merely a transient issue. The repair operation should be complete in the next few hours.
[UPDATE]
Ceph was able to successfully repair the PG. -
Zabbix Monitoring
01/22/2021 at 00:30 • 0 commentsI decided I have enough nodes that some comprehensive monitoring was worth the time, so I configured Zabbix to monitor the nodes in the ceph cluster. I used the zbx-smartctl project for collecting the smart data.
-
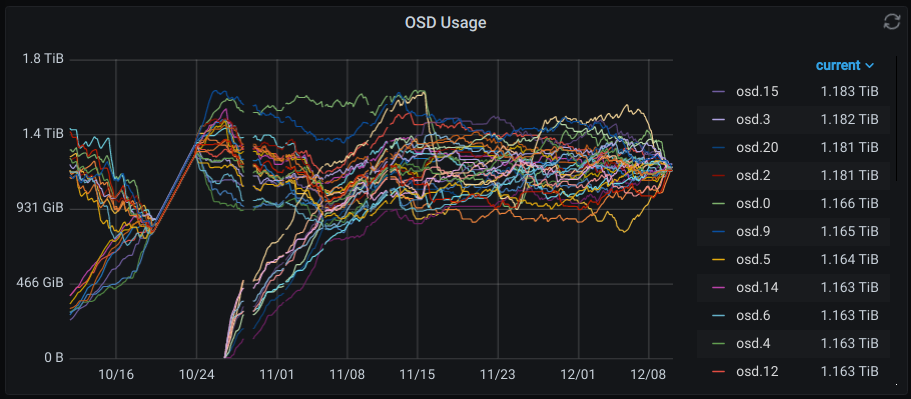
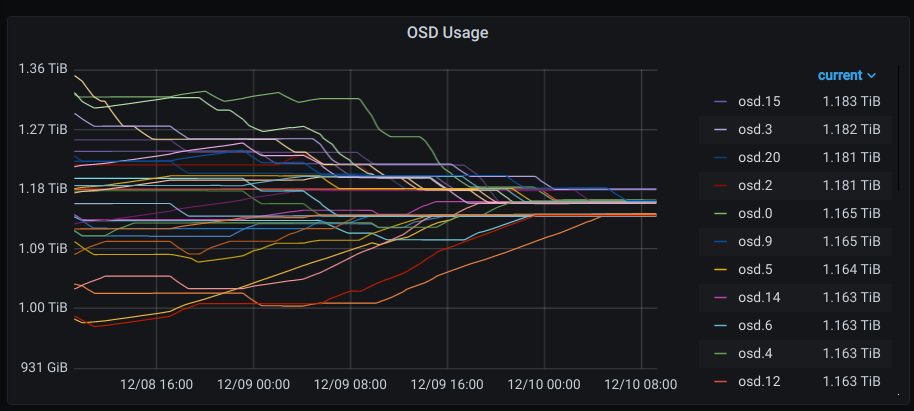
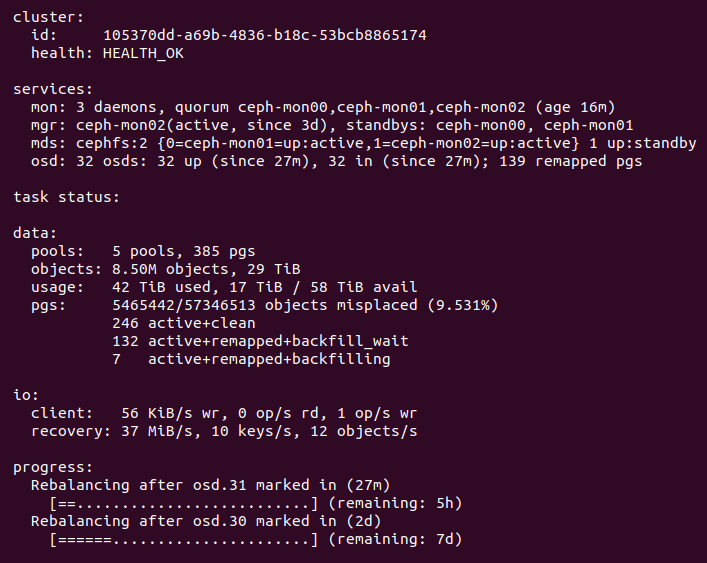
Rebalance Complete
12/10/2020 at 15:15 • 0 commentsThe rebalance finally completed. I had to relax the global mon_target_pg_per_osd setting on my cluster to allow the PG count increase and the balancer to settle. Without setting that parameter to 1, the balancer and PG autoscaler were caught in a slow thrashing loop
Raspberry Pi Ceph Cluster
A Raspberry Pi Ceph Cluster using 2TB USB drives.

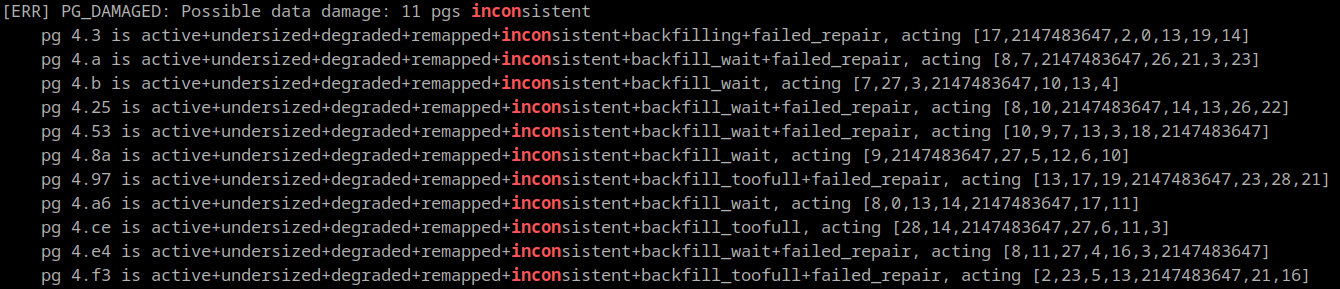 The inconsistent PGs all have a single OSD in common: 2147483647 (formerly identified as 25)
The inconsistent PGs all have a single OSD in common: 2147483647 (formerly identified as 25)