lion mclionhead
lion mclionhead-
Efficientdet lite-1 Disaster
08/10/2024 at 08:44 • 0 commentsThe last use of this system was back in May & it was so bad, it just got forgotten.
![]()
The mane problems were mis detections of columns, more trees, near sightedness because of the fisheye lens. The only thing doing any tracking was the histogram feature extraction.
Machine tracking lost a lot of appeal over the years. It takes a lot of power & produces boring shots when it works. For it to be justified, you have to dance around the camera like stuttering skater but dancing around the camera exposes the trouble spots.
The way to proceed might be to continuously train the network on a growing library of failed images. Sadly, the raw footage was deleted out of frustration. It might be necessary to crop in on the fisheye lens to give it more range. It's still much easier to use even if it ends up not seeing any more than the keycam.
Most of the footage that day was hard mounted.
-
Optimization
05/05/2024 at 02:33 • 0 commentsFull tracking with efficientlion-lite1 was going at 11fps & recording the raw video brought it down to 9fps. It was a mystery why the webcam would be 11fps while reading from a file would be 12fps. The webcam reads at 15fps. It could get up to a hair below 12fps by decoding all the JPEG's in the video capture thread. It means a lot of decoding is thrown away. It's faster if the defishing is done in the mane thread. It seems to be an optimum balance between the 2 threads. It was a shocker to find JPEG decompression being a bottleneck on the rasp 5.
The traditional way to beat JPEG is to keep it in YUV, then convert to RGB only when copying to the input layer. If only lions knew this in 1999. That got efficientlion-lite1 up to 14.8 fps. Recording drops it to 11fps.
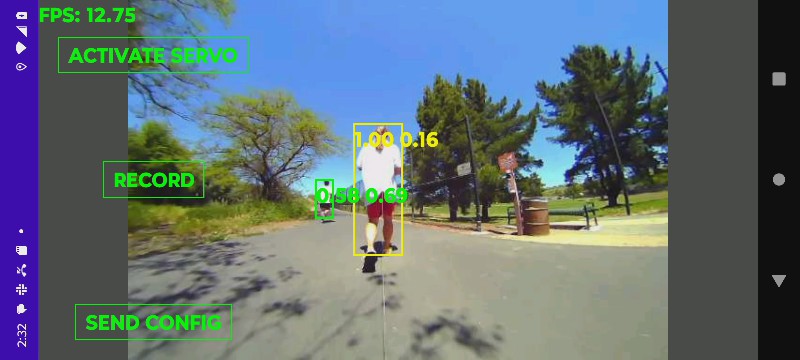
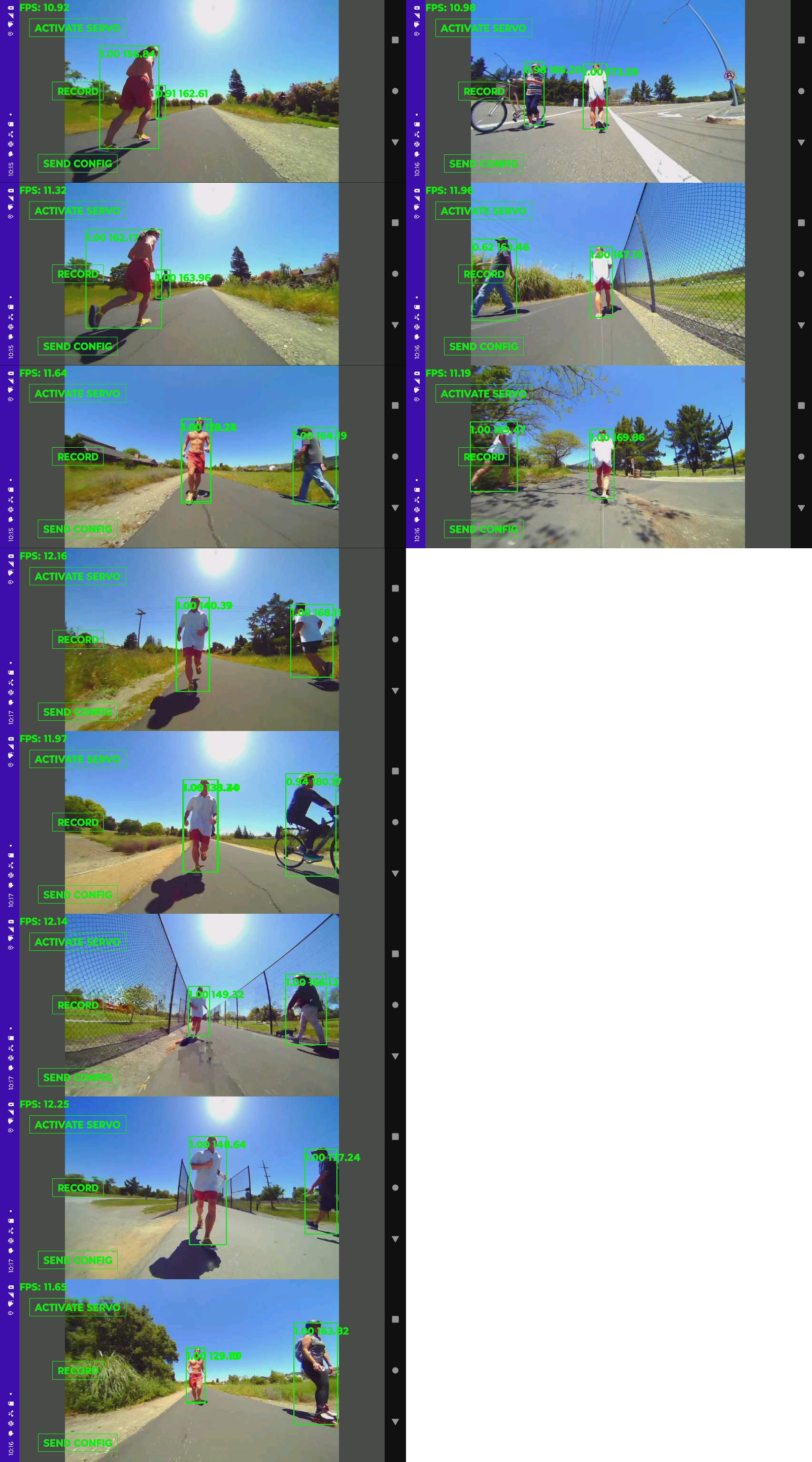
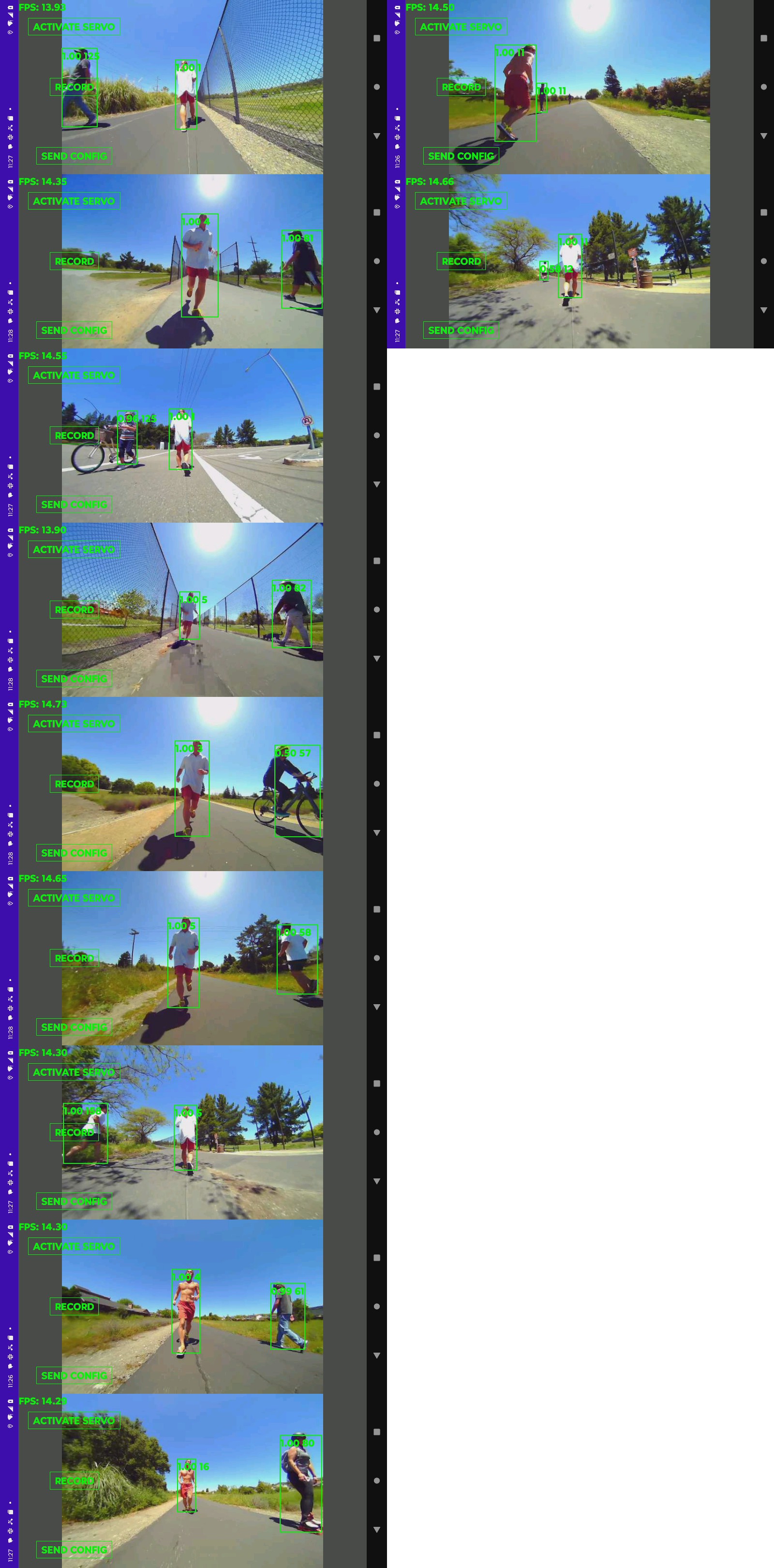
Got a production video with the new tracker.
![]()
![]()
![]()
It's incredibly noisy with the fan on & uses 15W. There are dreams of underclocking it to run it without the fan & burn less power, but it's near sighted with the fisheye lens. It needs a higher resolution detector or maybe smarter tiling with a lower resolution detector.
The 1st output from the new system revealed lots of invalid hit boxes which were being masked by the color histogram feature extraction. It could probably work with good old body_25 & its preference for trees but it would be slow.
-
Color histogram feature extraction
05/04/2024 at 03:26 • 0 commentsBased on what's working, the ideal method would be absolute differencing every new box against the previous best box. That would require a scale invariant method or the matches would be pretty bad. The next best idea is histogram feature extraction. All a histogram does is increase the number of target colors to compare.
![]()
![]()
That fixed 5 cases where the single color comparison failed, but added 1 new failure.
![]()
Helas, success highly depends on the number of frames averaged. 15 frames fixes the bad case. 20 frames fails it because it weighed more data from outside the shade. Histogram feature detection was better in every case, with the same averaging time. It could be 1 second of averaging is the ideal amount, but it would have still failed if the lion entered the shade 5 frames later. All the other cases weren't affected by the averaging time. There's a compromise between responding quickly to lighting changes & washing out detections of the wrong animal. There could be a rule where differences under .01 have to revert to largest box or get rejected.
-------------------------------------------------------------------------------------------------------------------------
![]()
Was surprised to discover the higher number of bins giving greater separation. It was always assumed the chi square calculation wouldn't overlap higher numbers of bins but in reality, it seems to store more spatial information.
Sadly, that mall scene with so many lighting changes was brutal. 256 bins fell over in some parts while improving others. After much dialing of values, 32 bins & 15 frames got all the way through that 1 scene without any glitches. There still is some potential for chi squared to misalign higher numbers of bins & some need for the moving average to keep up with lighting changes. The best this algorithm can do is shoot for a middle ground. The captured frame rate was 15 so it probably needs 12 frames of averaging during realtime tracking.
![]()
![]()
These are worst case scenarios. The typical empty bike path hasn't had problems in dog years.
![]()
The hardest one on the bike path got lucky because the lion was in a more stable lighting while the wild animal was in & out of shadows.
Thus came a compilation video of color histogram feature extraction passing all the test cases.
-
Nearest color algorithm
05/02/2024 at 22:40 • 0 commentsThe latest efficientlion-lite1 model worked perfectly, once the byte order was swapped. imwrite seems to require BGR while efficientlion requires RGB. It's a very robust model which doesn't detect trees & works indoors as well is it does outside. It seems to handle the current lens distortion. It definitely works better with the fisheye cam than the keychain cam, having legs & a sharper image.
The pendulum swung back to color histogram feature extraction for recognition. The latest idea was whenever there was just 1 hit to update the target color based on the 1 hit. It would use a lowpass filter so the hit could be the wrong object for a while. It might also average many frames to try to wash out the background.
They use the chi squared method to reduce the difference between histograms to a single score. Semantic segmentation might give better hit boxes than efficientdet. It goes at 7fps on the rasp 4. The highest end models that could be used for auto labeling might be:
https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/Segmentation/MaskRCNN
https://github.com/NVlabs/SegFormer
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Meanwhile in the instance segmentation department, the latest yolo model is yolov9. yolov5 has been good enough as the lion kingdom's auto labeler for over 2 years. Yolov9 is probably what Tesla uses.
Lions feel the most robust method is going to be manually picking a color in the phone & picking the hit box with the closest average color to that color. This would only be used in cases of more than 1 hit box. It wouldn't automatically compute a new color for the user.
![]()
Average color difference would only eliminate 2/3 of the hits in this case.
![]()
Average color distance varies greatly when we're dealing with boxes.
![]()
Straight hue matching doesn't do well either.
Since most of the video is of a solo lion with short blips of other animals, recomputing a new target color in every frame with 1 hit might work, but it needs to cancel overlapping boxes.
![]()
This algorithm fixed all the test cases which would have caused the camera to track the wrong animal. It definitely fixed all the cases where the 2022 algorithm would have failed, since that tracked the largest box.
The only failures would not have caused the camera to track the wrong animal. The other animal was always converging with the lion & a very small box when it failed. The small boxes create a very high variation of colors. It should use the defished resolution for color calculations. Another idea is to recompute the target color when multiple boxes are present.
The big failure modes are if the lion is in a very small box & another animal is in a big box, the color variation could be enough for it to track the wrong animal. If the tracker doesn't detect the lion or if the lion is momentarily behind another animal, it would replace its target color. There could be a moving average to try to defeat dropped lion boxes but this adds a failure mode where the target color doesn't keep up with the lion. In a crowd, the target color is going to drift & it's going to lose the subject.
This might be the algorithm DJI uses, but with semantic segmentation. No-one ever shows DJI in a crowd.
![]()
Another test in more demanding environments with more wild animals still overwhelmingly worked. A few near misses & more difficult scenes were shown.
1 trouble spot was a wild animal with similar colored clothing. It had a lot of false detections. A forest environment with constantly changing shadows made the target color very erratic but also created differentiating lighting for different subjects. It was computing a new target color from the best match in every frame, but averaging 15 frames of target color so the failures might have been recoverable if the lion didn't go out of frame.
A red shirt is your biggest ally in this algorithm, until
![]()
It somehow missed just 1 frame in this one.
![]()
Typical results have large margins. In the heat of battle, the results are never typical though. Surprising how this algorithm causes whatever it sees 1st to become what it follows most of the time, like an animal which identifies its 1st companion as its parent.
Semantic segmentation might improve the results, but it would be a lot of work. It's possible that the extra background information in the hit boxes helps it differentiate objects. A grey shirt might show how important the background information is. There's also matching nearest histogram instead of nearest average color.
-
Facenet with fisheye cam on rasp 5
05/01/2024 at 06:57 • 0 commentsAt least 1 attempt at this needs to happen. Facenet needs the highest resolution it can get, which requires defishing at least 810x540. That's the limit of the useful resolution from the elp fisheye. Then there would be a 2nd step to downscale it to efficientlion size.
The last of the code which used movenet, the HDMI cam & the keychain cam was moved to truckflow.*.posenet
![]()
The higher resolution for facenet really needs smooth defishing. The defish smoothing only works when it's not scaling. It should probably defish at 1620x1080.
Opencv dropped support for the original yunet.onnx after 2022. There's now a 16 bit face_detection_yunet_2023mar.onnx you have to track down. An 8 bit derivative doesn't work.
opencv_zoo/models/face_detection_yunet/face_detection_yunet_2023mar.onnx at main · opencv/opencv_zoo
AT 810x540, it goes at 5fps with efficientlion-lite1 going. It drops to 2fps at 1620x1080. 810x540 goes at 8fps alone. Efficientlion-lite0 might be worth it. The age old problem still exists where you have to look at the camera head on. The fisheye lens doesn't do much for it.
If it scans just the hit boxes from efficientlion, it goes at 8fps with 1 hit box. It depends on the size & number of hit boxes. The worst case would be slower than just scanning the entire frame.
It would have to scrap tracking the largest box & use the nearest box to the last box with the matching face instead. It also needs to dedup the hit boxes. The problem with deduping is 1 hit box might have a face while another might not. It's no guarantee. What's really needed is a way to play recorded footage through the algorithm in place of the live camera & record the output without the phone.
![]()
Rough go of it with the training footage. The face detector didn't hit anything. It definitely works but the truck is too low. Efficientlion-lite1 hit a lot of trees but might have just been common randomness. It was about as bad as tensorrt.
The efficietlion-lite0 model from 2022 had fewer false hits but also failed to detect anything in a lot more frames. It might be worth running lite0 in FP16 & lower resolution.
-
ELP fisheye review
04/28/2024 at 02:46 • 0 commentshttps://www.amazon.com/dp/B00LQ854AG
Finally burned the $50 on it, 7 years after scrimping & burning only $30 for a terrible 808 keychain cam. It has a breakaway PC board for a smaller enclosure. It does the advertised resolutions & frame rates using JPEG or slower frame rates using raw YUV. The highest 4:3 resolution it does is 1280x1024. It doesn't do any 1:1 resolutions.
![]()
The sensor doesn't cover the top & bottom. The 4:3 modes chop off the sides. The amount of cropping in the 4:3 modes changes based on resolution. 640x480 crops the most. 1024x768 crops the least. The biggest field of view is from 1920x1080.
It has a fully automatic & fully manual mode but it doesn't have an exposure setting. The manual mode just locks in whatever the last auto exposure was & allows a manual setting for white balance. The auto mode adjusts the exposure & overrides the manual white balance. Gamma, gain, saturation, brightness, contrast, sharpness, backlight compensation are always manual. It would take quite the fussing to use manual white balance. The best game for the chroma keying might be an auto exposure duty cycle of 5 seconds every 60 seconds or whenever a software metering goes over a threshold. Otherwise, it needs to be in auto.
![]()
![]()
The big question is what angle to point it, what cropping & defishing to apply. Defishing fills the black areas & the useless areas of the corners with useful data. It seems pointing it up 10 deg will compensate for its height above ground. Scanning the full height of the frame will give it more body parts to detect.
![]()
This is with aspect ratio & radius set to 1. Defishing & cropping the center 4:3 still covers a very wide angle without making the center ridiculously squeezed. Ideally, all horizontal positions would be squeezed equally, giving a map of where things are. Considering how much is being cropped by defishing, 640x480 might be a wide enough field of view but the most detail is still going to come from 1920x1080 after defishing.
![]()
Simulated tile position. At this point, it became clear that the optimum size for 2 tiles depends on how wide the animal is.
![]()
![]()
![]()
![]()
For a lion who occupies 1/3 of a tile, it should be a 3:2 or 576x384. Then the tiles overlap by 1/3. Some amount of barrel distortion seems to be required for a wider angle & to keep objects the same proportions in every location. The object of the game is to reduce barrel distortion enough to fill the frame with data.
![]()
![]()
![]()
![]()
![]()
The mounting is quite an improvement since the keychain cam.
![]()
Never had realtime FPV video from a decent camera so this was quite an experience. The latency & range were too awful to drive by.
The defishing process, higher camera resolution took a bite out of efficientlion-lite1. It only did 12fps. Invalid hits seemed pretty low compared to the keychain cam. Range was pretty limited because of the wider field of view. A slower interpolated defishing might improve the range. The improved picture quality renewed dreams of running facenet.
![]()
A minimal interpolator took away another 1 fps & didn't make any useful difference.
-
Enclosure 2
04/22/2024 at 00:46 • 0 comments![]()
![]()
![]()
A new bolt-on enclosure for just the confuser & not the servo controller. Still don't have a buck converter for it.
The new twist with this is the fan is part of the enclosure so it needs a plug. It was easiest to plug it into USB.
![]()
Noted improved tracking with 300 epochs. Both models were prone to an invalid hit box in the same place but it was rarer with 300 epochs.
More importantly, the VIDIOC_S_CTRL ioctl stalls randomly for 5 seconds. If it isn't called for every frame, saturation reverts when the camera experiences a loss of brightness & the tracking degrades. When this happens, VIDIOC_G_CTRL doesn't read back the new value. Saturation may not be an option with this camera. Another option might be saturation in software.
Kind of frustrating how many invalid hit boxes it gets.
Lite0 seems to get less invalid hit boxes. The rasp 4 algorithm centered 1 tile on the hit box so the animal was always
in the center, but it was more prone to tracking the wrong animal. The rasp 5 algorithm usually has a hit on the edge of the 2 side tiles, so this is believed to be causing invalid hit boxes. Efficiendet is better at classifying objects than determining their position. It could go to lite2 & go back to the rasp 4 algorithm.Because the servo is also tracking, the servo is trying to push the lone tile off the subject. The rasp 5 algorithm should be more robust by not fighting the servo.
![]()
A few more stills of lite 1 with color coded tiles showed it getting invalid hits regardless of the position inside a tile. .64 1 was in the middle of tile 1.
There's also going to a single fixed tile or 2 tiles * 2 cores.
-----------------------------------------------------------------------------------------------------------------------------------
Lite4 needs 12 minutes per epoch & goes at 4.4fps on 1 tile with 4 threads. Input resolution is 640x640.
Lite3 needs 6 minutes per epoch & runs at 9.2fps on 1 tile, 4 threads. 5.3fps on 2 tiles * 2 threads. Resolution is 512x512Lite2 needs 4 minutes per epoch & runs at 15.3fps on 1 tile, 4 threads. 9.3fps on 2 tiles * 2 threads. 6fps on 3 tiles * 1 thread. Resolution is 448x448
Lite 1 goes at 20.7fps on 1 tile * 4 threads, 13.5fps on 2 tiles * 2 threads, 8.8fps on 3 tiles * 1 thread. Resolution is 384x384
Lite0 goes at >30fps on 1 tile * 4 threads, 21fps on 2 tiles * 2 threads, 14.6fps on 3 tiles * 1 thread. Resolution is 320x320
The highest pixel throughput is usually happening at 2 tiles * 2 threads. Other users have discovered the 4 gig rasp is faster than the 8 gig rasp. Stepping it up to 2.666 Ghz gets lite2 to to an erratic 9.3-9.9 fps on 2 tiles * 2 threads & sucks another 200mA it seems. It might thermally limit the speed.
Seem to recall efficientdet can't handle letterboxing. It definitely can't handle any animorphic modes.
----------------------------------------------------------------------------------------------------------------------------------------------------------------------
![]()
Well, it was 7 years of battling the $30 keychain cam but the saturation issue was the last straw. The ELP fisheye cam strangely existed at the same time but it wasn't the gopro replacement lions were looking for & $45 was too expensive. Lions preferred to wait for sales tax to grow from 7.25 to 8.75. Just 1 year earlier, any USB fisheye camera was $300. Strangely, no USB fisheye cameras showed on the goog in 2019 so lions burned money on an Escam Q8.
It's hard to believe anything could be worse than that keychain cam. Mounting it, cable routing, turning it on, the lack of any configurability, the 16:9 aspect ratio were heavy prices to pay for a slightly wider field of view than a logitech.
-
Chroma keying ideas
04/15/2024 at 03:32 • 0 commentsThe 1 thing making the tracker basically worthless has been its preference for humans instead of lions in crowds. Pondered chroma keying some more. No matter what variation of chroma keying is used, the white balance of the cheap camera is going to change. The raspberry 5 has enough horsepower to ingest a lot more pixels from multiple cameras, which would allow using better cameras if only lions had the money.
https://www.amazon.com/ELP-180degree-Fisheye-Angle-Webcam/dp/B01N03L68J
https://www.amazon.com/dp/B00LQ854AG/
This is a contender that didn't exist 6 years ago.
Maybe it would be good enough to pick the hit box with the closest color histogram rather than a matching histogram. The general idea is to compute a goal histogram from the largest hit box, when it's not tracking. Then pick the hit box with the nearest histogram when it's tracking.
It seems the most viable system is to require the user to stand in a box on the GUI & press a button to capture the color in the box. Then it'll pick the hit box with the most & nearest occurrence of that color. The trick is baking most & nearest into a score. A histogram based on distances in a color cube might work. It would have a peak & area under the peak so it still somehow has to combine the distance of the peak & the area under the peak into a single score. Maybe the 2 dimensions have to be weighted differently.
Doesn't seem possible without fixed white balance. We could assume the white balance is constant if it's all in daylight. That would reduce it to a threshold color & the hit box with the largest percentage of pixels in the threshold. It still won't work if anyone else has the same color shirt.
Always had a problem with selecting a color in the phone interface. The problems have kept this in the idea phase.
The idea is to make a pipeline where histograms are computed while the next efficiendet pass is performed. It would incrementally add latency but not reduce the frame rate.--------------------------------------------------------------------------------------------------------
USB on the servo driver was dead on arrival, just a month after it worked.
![]()
It seems the STM32 didn't react well to being plugged into a USB charger over the years. The D pins were shorted in the charger, a standard practice, but shorting the D pins eventually burned out whatever was pushing D+ to 3.3V in the STM32. The D+ side only went to .9V now & it wouldn't enumerate. Bodging in a 1k pullup got it up to 1.6. That was just enough to get it to enumerate & control the servo from the console. That burned out biasing supply really doesn't want to go to 3.3 anymore.
The best idea is just not to plug STM32's into normal chargers. Just use a purpose built buck converter with floating D pins & whack in a 1k just in case.
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
efficientdet-lite1 showed promise. Resurrecting how to train efficientdet-lite1, the journey begins by labeling with /gpu/root/nn/yolov5/label.py
Lite1 is 384x384 so the labeling should be done on at least 384x384 images. The training image size is set by the imgsz variable. The W & H are normalized to the aspect ratios of the source images.
After running label.py, you need to convert the annotations to an XML format with /gpu/root/nn/tflow/coco_to_tflow.py.
python3 coco_to_tflow.py ../train_lion/instances_train.json ../train_lion/
python3 coco_to_tflow.py ../val_lion/instances_val.json ../val_lion/
The piss poor memory management in model_maker.py & size of efficientdet_lite1 mean it can only do 1 batch size of validation images. It seemed to handle more lite0 validation images.
It previously copied all the .jpg's because there was once an attempt to stretch them. Now it just writes the XML files to the source directory.
It had another option to specify max_objects, but label.py already does this.
run /gpu/root/nn/tflow/model_maker.py
model_maker2.py seems to have been broken by many python updates. It takes 9 hours for 300 epochs of efficientdet-lite1 so model_maker2.py would be a good idea. https://hackaday.io/project/183329-raspberry-pi-tracking-cam/log/203568-300-epoch-efficientdet A past note said 100 epochs was all it needed.
-
Efficientdet-lite0 on a raspberry pi 5
02/20/2023 at 05:27 • 0 commentsInstalled the lite 64 bit raspian. The journey begins by enabling a serial port on the 5. The new dance requires adding these lines to /boot/config.txt
enable_uart=1 dtparam=uart0 dtparam=uart0_consolelogin: pi password: raspberry doesn't work either. You have to edit /etc/passwd & delete the :x: for the password to get an empty password. Do that for pi & root.
Another new trick is disabling the swap space by removing /var/swap
Then disabling dphys-swapfile the usual way
mv /usr/sbin/dphys-swapfile /usr/sbin/dphys-swapfile.bak
The raspian image is the same for the 5 & the 4 so the same programs should work. The trick is reinstalling all the dependencies. They were manely built from source & young lion deleted the source to save space.
Pose estimation on the rasp 4 began in
https://hackaday.io/project/162944/log/202923-faster-pose-tracker
Efficientdet on the rasp 4 began in
https://hackaday.io/project/162944/log/203515-simplified-pose-tracker-dreams
but it has no installation notes. Compiling an optimized opencv for the architecture was a big problem.
There were some obsolete notes on:
https://github.com/huzz/OpenCV-aarch64
Download the default branch .zip files for these:
https://github.com/opencv/opencv
https://github.com/opencv/opencv_contrib
There was an obsolete cmake command from huzz. The only change was OPENCV_EXTRA_MODULES_PATH needed the current version number. The apt-get dependencies were reduced to:
apt-get install cmake git apt-get install python3-dev python3-pip python3-numpy apt-get install libhdf5-dev
Compilation went a lot faster on the 5 than the 4, despite only 4 gig RAM.
Truckflow requires tensorflow for C. It had to be cloned from git.
https://github.com/tensorflow/tensorflow/archive/refs/heads/master.zip
https://www.tensorflow.org/install/source
The C version & python versions require totally different installation processes. They have notes about installing a python version of tensorflow using the source code, but lions only ever used the source code to compile the C version from scratch & always installed the python version using pip in a virtual environment.
Tensorflow requires the bazel build system.
https://github.com/bazelbuild/bazel/releases
It has to be chmod executable & then moved to /usr/bin/bazel
Inside tensorflow-master you have to run python3 configure.py
Answer no for the clang option. Then the build command was:
bazel build -c opt //tensorflow/lite:libtensorflowlite.so
This generated all the C dependencies but none of the python dependencies. There was no rule for installing anything. The dependencies stayed in ~/.cache/bazel/_bazel_root/ The only required ones were libtensorflowlite.so & headers from flatbuffers/include
To keep things sane, lions made a Makefile rule to install the tensorflow dependencies.
make deps
The lion kingdom's efficientdet-lite tracking program was in:
https://github.com/heroineworshiper/truckcam
The last one was compiled with make truckflow
Then it was run with truckflow.sh
It's behind the times. It used opencv exclusively instead of compressing JPEG from YUV intermediates. The phone app no longer worked. Kind of sad how little lions remembered of its implementation after 2 years. The phone app was moved to UDP while the server was still TCP.
SetNumThreads now had to be called before any other tflite::Interpreter calls.
-----------------------------------------------------------------------------------------------------------------------------------------
On the rasp 5, it now runs efficientdet-lite0 at 37fps with SetNumThreads(4) & 18fps with SetNumThreads(1),. Single threaded mode is double the rasp 4, which makes lions wonder if it was always single threaded before.
It only uses 40% of 3 cores & 100% of 1 core. It might be more efficient to process 1 tile on each core.
The image is split into 3 tiles regardless of the threading. If it processes 3 tiles simultaneously with SetNumThreads(1), it goes to 90% on 3 cores & 14.5fps. If it processes 1 tile at a time with SetNumThreads(4), it goes at 12fps. Helas, it needs a heatsink & fan.
Efficientdet-lite1 384x384 goes at 8.8fps. That's as high in resolution as the rasp 5 can go. 1 core per tile with SetNumThreads(2) makes the frame rate go down to 8.5 & increases the CPU usage to 300%. It's memory bandwidth constrained.
The current with the full fan, servo, camera, & 3 core efficientdet is 2.6A. Without the servo, it's 2A. It's prone to stalling when there's network connection because it's writing to the socket in the scanning thread.
It could probably handle face detection on the 4th core if the camera was better.
![]()
It brings back memories of 16 bit tensorrt. The problems there might have been precision related. It has overlapping boxes because the tiles overlap. They don't always overlap.
Raspberry pi tracking cam
Tracking animals on lower speed boards to replace jetson & coral