Eric Hertz
Eric Hertz-
"Print Screen," data-logging, file-transfer
2 days ago • 0 commentsHere's one maybe you hadn't pondered...
The parallel port for printers ("centronics" /protocol/, not connector) has been standard-enough for so long that basically all home printers that had it could be connected to basically all home computers that had it...
So-common that computers (and dumb-terminals) with /serial/ printer-ports in need of a printer might just get a shiny-new /parallel/ printer and a serial-to-parallel converter for cheaper than a serial-printer...
So common that e.g. "print screen" is a friggin button in DOS, and CP/M has the ability to copy to its parallel port just as easily as to another file, via the same utility...
Then....
Doesn't it seem kinda strange that using the parallel port to transfer files (or, e.g. data-logging) to another *computer* is so rare? Sure, laplink, etc. Sure, most of those printer ports are *not* bidir... but the bidir mod was well-known by the PC/XT, and implemented in every PC/clone thereafter, and, of course, that was *right* when PCs were taking-over... replacing folks' Commodores and TRS80s and Kaypros, which folk fought hard to find ways to transfer their files from... ...for, frankly, many PC-generations thereafter... (e.g. kaypro lover *finally* admitted PC's were the only upgrade option by the 386 era)
So, then... by the friggin bidir-parport-era (late PC/XT), they could've just "printed" their docs to a friggin PC the same way they printed to printers....
All it takes is... a little bit of pin-remapping at the end of a straight-through printer cable, and a tiny bit of software (TSR?) to watch for and respond to the incoming "strobe" on a different pin (maybe paper-loaded?)...
I mean, it's really a wonder this hadn't become as-ubiquitous as the bidir mod itself. Even two PCs, laplink's having been so common...Or, heck, I've got at least two, maybe more, friggin serial-to-parallel converters... I always thought they were for hooking parallel printers to serial ports, (e.g. connect your VT100's printer port to a newer parallel printer)... but surely the *opposite* would be /exactly/ as-complex, (nearly *identical*) circuitry-wise, and those things were pretty-durn-common... so, now, your kaypro/TRS80/whatever can print directly to a terminal-emulator on the PC, just like every other BBS-accessing/file-downloading terminal-emulator folk'd already been familiar with... (and, again, nevermind things like data-logging! e.g. all these mainframes that output to teletypes... of course they could've output to VT100s, but they'd only retain 25 rows of text... but now a friggin PC could stream straight to a floppy... scrolling... etc...)...
I mean, it just seems weird this stuff wasn't so commonplace that I'm sitting here, now, with a kaypro that can print logic-analyzed waveforms to "any" printer (setial *or* parallel, your choice!) and after some 30+ years of working with systems as-ubiquitously-/compatible/ as-aforementioned, it actually took me some /thought/ (as opposed to recollection of many prior experiences; because I, surprisingly, haven't had many) to figure out how to transfer the waveform data to a file on another computer... when, frankly, the OMNI4's friggin software has essentially the same "print screen" button, compatible with "any" printer (parallel OR serial, or friggin terminal application) that every computer has had for the past 45 years!
-
Tricking overzealous chargers...?
09/07/2024 at 04:44 • 0 commentsDraft-unposted from September 2024: Heh!
Allegedly, and seemingly supported by experience, the overall lifespan of Li-Ions decreases dramatically with the charge-voltage.
It goes something like this: Charge a particular Li-Ion to 4.1V and you might get 1AH. Charge it to 4.2V and you might get as much as 1.5AH from that same cell.
But this comes at a cost of overall lifespan of the cell (how many charge-cycles).
I've got devices whose Li-IOn cells have lasted 20+ years, and still function at noticeably shorter durations between charges, but *still function*.
I've had numerous other devices whose cells lasted just a little over a year... And their functionality diminishes to completely-unusable. The devices won't even power-up, even after hours of charging.
PART of this has to do with the intent to make things smaller... so, sure, use a single cell where two would extend the lifespan dramatically (maybe as much as 4x!).
But, anyhow, the list of such reasons has resulted, it seems, in the "state of the art" being that Li-Ion cells charge to 4.2V when it used to be 4.1.
And, it seems, the end-result is a lot of devices with cells that just give up, far too soon.
.....
SO: Say one intends to repair such a device with something a bit more lasting...
Two parallel cells, in place of the original one, might go quite a long way toward reducing the strain on each individual cell... Same, possibly, for putting in a much larger capacity cell in place of the original...
OTOH, the charging-system hasn't been changed. So, while the higher-capacity will probably be noticeable, and have a longer overall lifespan, it doesn't change the fact that the cells are still being overcharged each time... which, again, is known to reduce the number of charge-cycles *tremendously*.
...
So... is there some sort of simple-enough and universal-enough intermediate circuit that could be placed inbetween the device and the replacement cell(s), to cause the device, which originally charged to 4.2V, to charge only up to 4.1V?
IF we were merely talking about a *charger*, then a simple schottkey diode might do the job...
BUT, most devices these days both charge and discharge depending on the load... Run a 3D vidgame, and the extra load from the GPU might be even more than your USB charger can supply, so even though you're plugged-in the battery might discharge...
As far as the hypothetical intermediate circuit is concerned, it would be best if it could drop 0.1V when the current flows into the cell, and not drop any voltage when current leaves the cell. OK, so some sort of active "diode" ala a series MOSFET...
And since we've gone that far, then maybe only drop that 0.1V once the cell reaches 4.1V!
OK, so insert a microcontroller on the gate of that MOSFET, and some ADC inputs attached to either side, and maybe elsewhere... and, surely, we could come up with something... right?
.....
Another consideration is that some of these devices rely so heavily on the battery/cell that they don't even include bulk capacitors! So, fine, as long as those cells are in perfect like-new condition, then their ESRs are low enough to handle such power-surges as, e.g., from a load changing on a 5V boost-converter.
BUT, one of the effects of an aging cell is increased ESR, and cells are aged-tremendously by being [ab]used/charged in these ways! So, we could be talking cell lifespans on the order of 1/10th what they could be if they weren't so-abused.
...
So, I think such an intermediate-circuit might benefit from a bulk-capacitor at the device/charger-side.
....
So, again, the idea is to make these devices usable [bootable!] again, without necessarily caring about the duration they'll last on a single charge, but instead caring that the cells will last for a long time, so we don't have to keep replacing them. Maybe these devices are going to be plugged-in 24/7, but we want the cell(s) to act as a UPS. Maybe the particular device won't even power-up without a cell attached.
The goal, here, isn't to replace the original cells with identical ones, to get it working (and failing) again, as it once did, but instead possibly even doubling the number of such cells and adding new/custom intermediate circuitry if it means fixing the problem that rendered it eWaste far too soon
....
So, I'm contemplating how to trick the charge/load-controllers to think a 4.1V charge is the 4.2V charge they're cruelly requesting. I don't care if it's at the cost of half the AH-rating/runtime between charges! I can always use bigger-capacity cells, or parallel additional cells if I need that runtime... I care that this thing doesn't have to be repaired again next year!
.
I've got a vague idea of how to do this with a series MOSFET and a microcontroller and a bulk capacitor... And that's what I'm contemplating, now... I've little doubt such a system could be fine-tuned to many/most charge/load-controllers individually, but I'm trying to make it more generalized...
E.G. I wonder what a charge/load controller would think about a charge-voltage of 4.2V, but suddenly dropping to 3.6V when the load increases suddenly, requiring the cell to charge a boost-converter's inductor. This intermediate circuit might appear like a huge ESR to a charger like that.... Even though 3.6V is still well-within "fully-charged" specs, I wonder if there are charge-controllers that would be completely thrown-off by something like this. OTOH, if such charge-controllers exist (e.g. the really fancy coulomb-counting ones), then they couldn't possibly handle things like a replaced cell, or even a cell's aging...
So, am-thinkink there may be a somewhat simple circuit(/software) that could be put inbetween a device and a replacement cell(/pack) that would reduce a 4.2V overzealous charger to 4.1V for the cell itself...
‐-------
March 2026 (>yr later): Still running through the ol' noggin from time to time. Forgot I wrote this up.
My old cellphone has been running off an 18650-flashlight/USB-powerbank for quite some time via zipties, a cardboard "cell" to connect to the spring-terminals, and a *direct* connection (bypassing the powerbank's charge/5V-boost circuits) to the cell.
The points being:
A) The original cell is kaput, the phone won't even power-up while it's plugged-in. And a replacement (despite being replaceable!) costs more than a new phone of its caliber)
Fine, 18650.
B) The phone's microUSB connection is flaky... it works if jiggled just-right *and* with *exactly* the right cables...
It's hard to get that right long-enough to fully-charge... takes a lot of keeping-an-eye on it for hours. Heh!
So, now, I can charge it through the powerbank's charging port. BUT:
C) The phone will *not* recognize the cell's new/increased charge unless the phone itself "charges" the cell... The percentage shown seems only to recognize *discharging*, but not [external] charging. (It takes about five minutes "charging" the normal way, via the flakey port on the phone, for it to recognize the cell had gone from 14% to 100% via the powerbank's charger).
You can imagine this can be problematic if the cell depletes to "0%"; even after charging it to full, via the powerbank charger, the phone won't power-up until *it* "charges" the cell (via the flakey port)... which, again, takes about 5minutes for it to recognize that the cell is actually charged.
(I *think* this can be tricked by physically removing the cell, then replacing it... so I added a physical switch inbetween, but thankfully I haven't had to use it much)
But now we come to...
D) I think the powerbank/cell is prematurely-aging... as, the other day it said it had some 40% and it powered-down while doing something Power/CPU-intensive... what was it...? Oh yeah, vid-camera+light. Classic sign of increased-ESR, I think.
Which, as I understand, is a result of recurrent over-charging... which, probably, is what happened to the first cell (that came with this *very cheap* phone), too.
So...
We're coming back 'round to the idea of tricking the charger(s?) to thinking the [next] cell is at 4.2V when it's really at 4.1...
(I'm also pondering how to physically re-aim the [next] powerbank/flashlight in the direction of the camera, because obviously this old phone's LED is far more power-hungry than the flashlight's! Gotta get them cat-vids, even when my main phone is low on power or gigabytes!!!)
-
Battery Pack with a dead cell?
08/21/2024 at 03:01 • 1 commentGet this... Say your cheap 18V cordless drill has one bad NiCd cell out of 15 in the pack...
Say, for whatever reason, you just can't revive it, but all the other cells are fine-enough...
What-say you just cut that cell out of the pack, tie the surrounding cells together for 16.8V instead of 18. Now add two diodes in series at the charger's output. 0.6-0.7V each makes for 1.2V-1.4V which is darn near perfect.
Now you shouldn't have to worry about that cheap charger pushing in too much voltage...
Big friggin' whoop, your 18V drill is running off 16.8 now. Should Be Fine. At Least It Works Again!
-
The Cash involved in Cache
03/02/2023 at 08:12 • 1 commentI just saw a few minutes of Adrian's vid wherein he dug out a 386 motherboard with CACHE!
This is one of those long-running unknowns for me... How does cache work. I was pretty certain I recalled that 486's had it, but 386's didn't... which means: for a 386 /to/ have it requires an additional chip... And /chips/ I can usually eventually understand.
So I did some searching to discover Intel's 82385 cache controller and took on some reading, excited to see that, really, there's no reason it couldn't be hacked into other systems I'm more familiar with, like, say, a z80 system. Heck, with a couple/few 74LS574's, I think it could easily be put into service as a memory-paging system. up to 4GB of 8K pages!
But the more I read of the datasheet, the more I started realizing how, frankly, ridiculous this thing is, for its intended purpose.
I mean, sure, if it was an improvement making a Cray Supercomputer a tiny bit more super when the technology first came out, or a CAD system more responsive to zooming/scrolling, I could see it. But... How it works in a home-system seems, frankly, a bit crazy. A Cash-Grab from computer-holics, who /still/ post questions about adding cache to their 35y/o 386's for gaming. LOL.
Seriously.
Read the description of how it actually functions, and be amazed at how clever they were in implementing it in such a way as to essentially be completely transparent to the system except on the rare occasion it can actually be useful.
Then continue to read, from the datasheet itself, how carefully-worded it is that there's a more sophisticated mode that actually only provides a "slight" improvement over the simpler mode which provides basically no improvement over no cache, unless the software is basically explicitely-designed with cache in mind.
Which, frankly, seems to me would have to be written in inefficient ways that would inherently be slower on cacheless systems, rendering benchmarking completely meaningless.
So, unless I'm mistaken about the progression of this trend--as I've extrapolated from the advancement of the "state of the art" between the era of computers without cache, to the first home computers with cache--here's how it seems to me:
If programmers had kept the skills they learned from coding in the before-times, cache would've been nothing more than a very expensive addition (all those transistors! Static RAMs!) to squeeze a few percent more useable clock-cycles out of top-end systems, for folk using rarely-used softwares which could've been carefully programmed to squeeze even more computations out of a system with cache.
But, because programmers started adopting cache as de-facto, they forced the market who didn't need it /to/ need it. The cacheless systems would've run code not-requiring-of cache roughly as-efficiently as code poorly-written to use cache running on systems with it. Which is to say that already-existant systems lacking cache were hobbled not by what they were capable, but by programmers' tactics to take advantage of tools that really weren't needed at the time, and, worse, often for little gain other than to use up the newly-available computing resources.
The 486, then, came with a cache-controller built-in, and basically every consumer-grade CPU has required it, since.
Now, I admit this is based purely on my own extrapolation based on what I read of the 82385's datasheet. Maybe things like burst-readahead and write-back, that didn't exist in the 82385, caused *huge* improvements. But, I'm not convinced, from what I've seen.
Think about it like this: In the time of the 386, 1 measly MB of DRAM was rather expensive... so how much, then, would be 32KB of /SRAM/? The 82385 also had nearly 2KB internal SRAM/Registers just to keep track of what was and wasn't cached. And this all in addition to a huge number of gates for address-decoding, etc.
After all that taken into account, I'm guessing the 82385 and cache chips probably contained*far* more transistors than the 386 itself. Heck, the 82385 alone might've been roughly on-par.
All that, and, frankly, the 82385 really doesn't /do/ much, aside from intercepting and regurgitating reads when the data was already, recently, read previously. Folk talk about 20% improvements in benchmarks, but were those benchmarks written with cache in-mind? If so, then it's not an improvement in computing-power, but an improvement in handling new and generally useless requirements. And, again, frankly, looking at the datasheet, my guess would've been something like a best-case 8% average improvement of code not written for cache.
[Though, again, I admit the cleverness in coming up with this peripheral cache controller in such a way that it's guaranteed not to *slow* the system under any circumstances, due to its transparent design!]
.
Frankly, it seems to me a bit like a 'hack' trying to squeeze a few more CPU cycles out of existing CPUs. Clever, but certainly not the sort of relic that should've been built-upon. E.G. 64bit 486's might've been a comparative *tremendous* improvement, requiring maybe even fewer transistors. Dual-Core, similar... But cache? And the friggin' slew of rabbit-hole processing/transistors/power required? Nevermind the mental-hurdles of coding with it in mind?
For /that/ to have become so de-facto, so early, and yet at the same time so late, boggles my mind.
Again, think about it: What were folk running on 386s? Windows 3.1. Multitasking. BIOS-calls and TSRs via ISRs. Video games that pushed every limit. The idea *any* program would be under 32KB, nevermind *both* the program *and* its data, nevermind its being switched in and out of context... Absurd.
Pretty much the only places I imagine it being useful, without coding specifically for cache, is in e.g. small loops used for performing iterative calculations (like Pi, which is why I mentioned mainframes), and only then if there's no risk of the data being in the same 8K address-space as the loop itself, except in another page.
...
I'm sure I've lost my train of thought, but that brings us to another topic....
Where is data vs code located? A HUGE problem, for quite some time, has been buffer-overflows causing executable code to get overwritten. Why The Heck are we still using the same memory-space for code and data?
I propose that part of the reason may have to do with cache. As I understand it, from the 82385 datasheet. Now, don't get me wrong, I'm all for the backwards-compatibility that the x86 architecture has provided. But it wouldn't have been at all difficult to separate code and data into separate memory-spaces in newer prgorams *if it weren't for cache*.
Why? Imagine your code is 32KB. And you've got 8KB of strings to manipulate in data. Now, your cache was 32KB... But if your sprintf function looping through each character was located at byte 256 in the code-space and the string you're sprintfing to started at byte 257 in your dataspace, then the cache would "thrash" between the dataspace and the codespace's bytes 257++. OTOH, if your sprintfwas printing to a string defined in your codespace after the loop, there'd be no tharshing, because the loop would be around byte 256 and the string would be around byte 576. In The Same [cache] page. No thrashing necessary... both would be cached into the same cache-"page." [not that it would be a huge benefit that they're both cached, since sprintf would be *writing* which isn't at all sped up by the 82385, but at least the loop could be run from cache].
But, there's no reason it has to have remained that way (code and data being interwoven)... except, it seems to me, because when we discovered how risky buffer-overflows were, we'd already relied on our databeing interwoven with our code in order to reduce cache-misses.
The friggin' Pentium could've, quite simply, added one additional output pin, ala an address bit (which could feed into a cache controller) alongside MEM/IO, to indicate Code/Data, which would, for backwards-compatibility, not really even been used, but for new programs would've allowed for separate address-spaces, should the programmer decide to make use of the new feature (no different than MMX extensions). One additional "address bit" indicating code/data in the cache controller would prevent cache-misses, despite the fact the address offsets of the sprintf loop and the string buffer might be near each other. And now executable overflows are a thing of the past, only concerns with old code. Programmers jumped on efficiently coding for cache, surely they'd've jumped on this!
.
But, back to cache...
I fought cache issues back in the ARM7 days, which, if I understand correctly, were *long* before ARMv7, and whatever passes for the lowest-end ARMs used in smartphones today.
I could be entirely mistaken, but I gather that on-chip cache controllers, and on-chip cache SRAM, are de-facto today... on basically every processor short of microcontrollers (and even some of them).
Is it possible these huge arrays of transistors de-facto-included in any "current" processor--expensive, space-consuming, heat-producing as they are--are actually *hindering* the abilities of our multicore multithreaded systems, today?
I'm beat. Who knows.?
...
That said, I am a bit intrigued about the hackery possible in the 82385... Seriously, e.g. connecting something like it [preferably in a DIP] to a Z80 could be quite interesting. It seems to be, roughly a slew of 74646(?) address decoders and 1024x(!) 74574 8-bit registers, which could be quite useful in completely unrelated tasks, as well.
-
3/4 Quadrature Decoding - NOPE
02/21/2023 at 11:19 • 0 commentsThis is my own invention... Maybe someone else has done it, maybe it has someone's name attached to it. I dunno. (Maybe not, and I'll finally hear from someone who can get me a patent?)
The idea is simple enough... I'll go into detail after the first image loads:
![]()
A typical method for decoding a digital quadrature rotary encoder involves looking at each edge of each of the two signals. If One signal "leads" the other, then the shaft is spinning in one direction. If that same signal "lags" the other, then the shaft is spinning in the other direction.
This is very well-established, and really *should* be the way one decodes these signals (looking for, then processing, all the transitions).
This is important because of many factors which we'll see if I have the energy to go into.
...
An UNFORTUNATE "hack" that has entered the mainstream does it differently. It's much easier (but, not really).
The idea, there, is to look for the edge(s) of one of the signals, then when it arrives, look at the *value* of the other signal.
This is kinda like treating one signal as a "step" output, and the other as a "Direction" output. But That Is Not What Quadrature Is.
If the signal was *perfect*, this would work great.
But the real world is not perfect. Switch-Contacts bounce. Optical encoder discs may stop rotating right at the edge of a "slot", a tiny bit of mechanical vibration or a tiny bit of 120Hz fluorescent lighting may leak into the sensor. And obviously electrically-noisy motors can induce spikes in decoding circuits as well as the encoders'.
That "Step" pulse may oscillate quite a bit, despite no change in the "direction".
...
My friggin' car's stereo has this glitch. And now that the detents are a little worn, it's very easy to accidentally leave the volume knob atop a detent, where suddenly and without warning a bump in the road causes the volume to jump up, sometimes an alarming amount, even though [actually /because/] the knob itself still sits atop that detent.
This Would Not Happen if they decoded the quadrature knob correctly. That was the whole point of the design behind quadrature encoders, as far as I'm aware.
But then somehow it became commonplace to decode them *wrong*, and I'm willing to bet it's in so many different devices these days that at least a few folk have died as a result. (It's sure given me a few scares at 70MPH!)
"Hah! That's a one in a million chance!" Yeah? But if you plan to sell 10 million... Sounds like ten counts of first-degree manslaughter to me. What's that... Ten 20 year prison sentences? But, yahknow, since "Corporations are people" it means the end of said corporation, and prison sentences, not slaps on wrists, for those who knowingly aided and abetted.
.
.
.
So, let's get this straight:
Quadrature can be decoded correctly.
The "step/direction" method is NOT correct.
.
.
.
If the elite engineers who hold onto trade secrets like this technique are unwilling (or just too tired) to teach you, and there's even the tiniest chance a glitch could hurt someone, then please remember that the internet is full of seeming-authoritative information from folk who really have no clue what they're talking about, and then look into products designed for the task, like HP/Agilent's HCTL-2000, or similar from U.S. Digital.
.
.
.
Now, As A /hacker/ or /maker/ or DIY sort of person, I often try to solve puzzles like the one I faced tonight: How do I decode my two quadrature signals with only one Interrupt pin and one GPIO pin and no additional circuitry?
So, ONLY BECAUSE it doesn't really matter in this project, I considered the "Step/Direction" decoding approach, which I'd dismissed so long ago that I'd forgotten exactly /why/. And I had to derive, again, the *why*, which I described earlier ("Noise" on "Step" would cause the counter to run away).
.
I spent a few hours trying to think of ways to resolve that, and ultimately went back to my original technique, just using two GPIOs, polling, and history to monitor both edges for the expected changes.
The problem is, it's a bit overboard:
This encoder outputs something like 8000 ticks per revolution(!?) and 100 would be plenty for my needs.
And, it really doesn't even matter if it misses some steps.
So, I can afford to sacrifice a whole slew of "ticks", and (need to) save a bunch of CPU power, too.
...
I put on my thinking-cap and realized I could reduce the quadrature-decoding processing time (and resolution) by 3/4ths!
*And* do-so by modifying the "Step/Direction" technique.
And do-so without introducing the step-runaway problem.
And do-so without introducing, I think, any additional chance for "missed steps" (except, of course, the 3 of 4 I'm intentionally skipping).
...
![]()
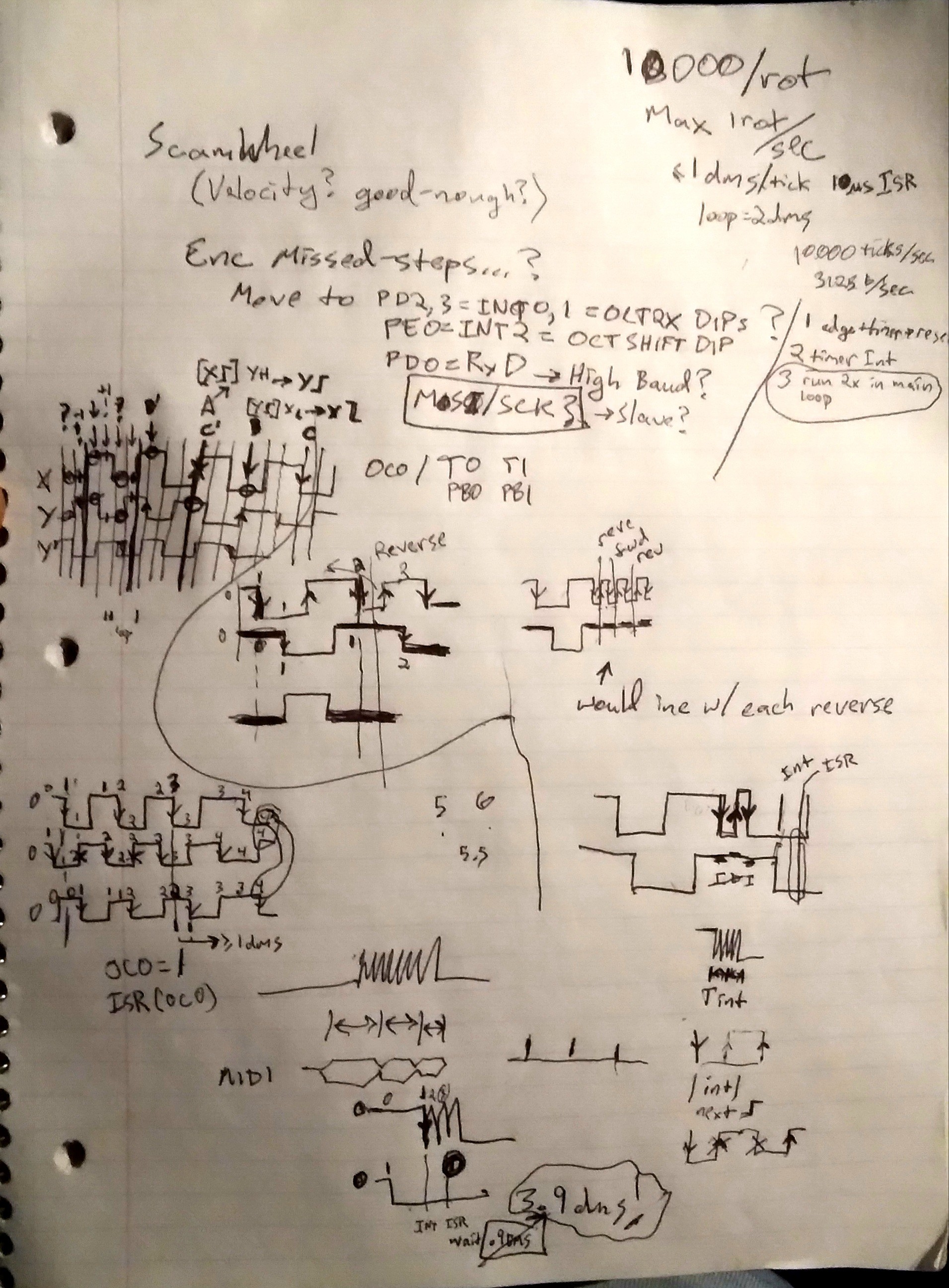
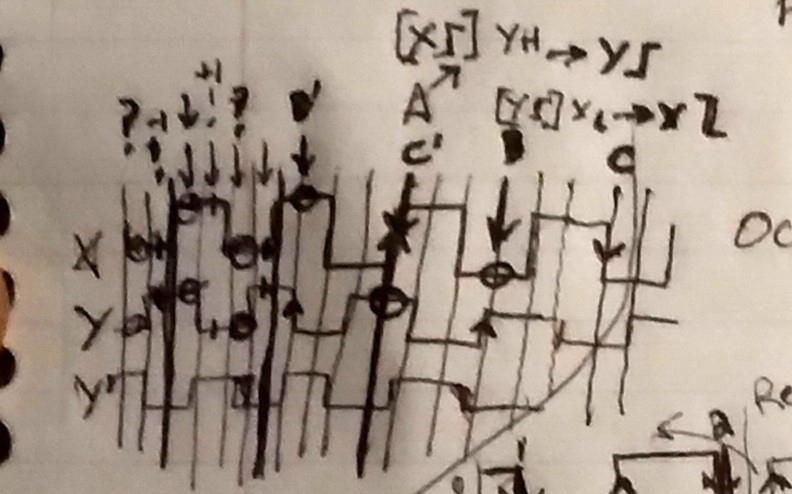
Here we have two quadrature signals, 90deg out of phase, on X and Y. Y' is when it spins in reverse.
On the left, with all the tightly-spaced arrows, we have the typical decoding-scheme. Wherein, it's important to register every state/transition (I call these 'ticks'). Thus, if this were 10000 ticks/revolution and I spin it at most 1 rev/second, we need to sample those GPIOs at least 10,000 times/sec.
(Note that since every state must be traversed, in order, a noisy/edge-case input (as described earlier for "Step") results in a value that may oscillate, but will not, can not, increase repeatedly.)
.
On the right is where it gets interesting.
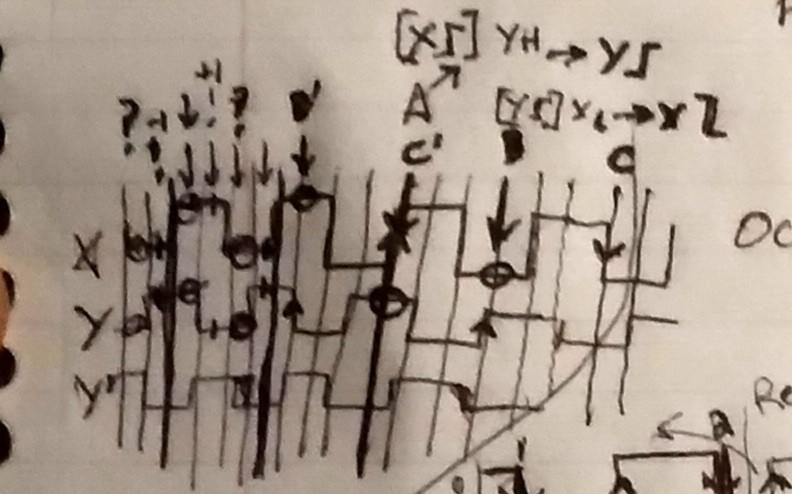
![]()
Say we power-up the device just left of the position marked A, where both X and Y are low. We configure the decoder to look for a rising-edge transition (e.g. interrupt) on X. Turn the encoder to the right, detect the rising-X ("[X] Step"), measure Y=H ("Right"), position=1.
Now reconfigure to look for rising-Y. Why?
If we'd've chosen Falling-X, we might get triggers due to the runaway-stepping problem, if it stopped near A, or if electrical noise was high, or if the output bounces.
If we'd've chosen falling-Y, it would be the same as the typical decoder scheme; too high of resolution for my needs, too much processing time... Reducing the processing time this much, I can get away with much-faster (3x!) knob-turning, without missed-steps or actually using any interrupts. GPIO-polling should do fine.
So, if it went right, to B, X will be low, position++. Left, at B', X=H, position--.
Now, at B, we look for X-Falling, three steps away in either direction. Or, from B' we look for X-Rising.
And So On.
...
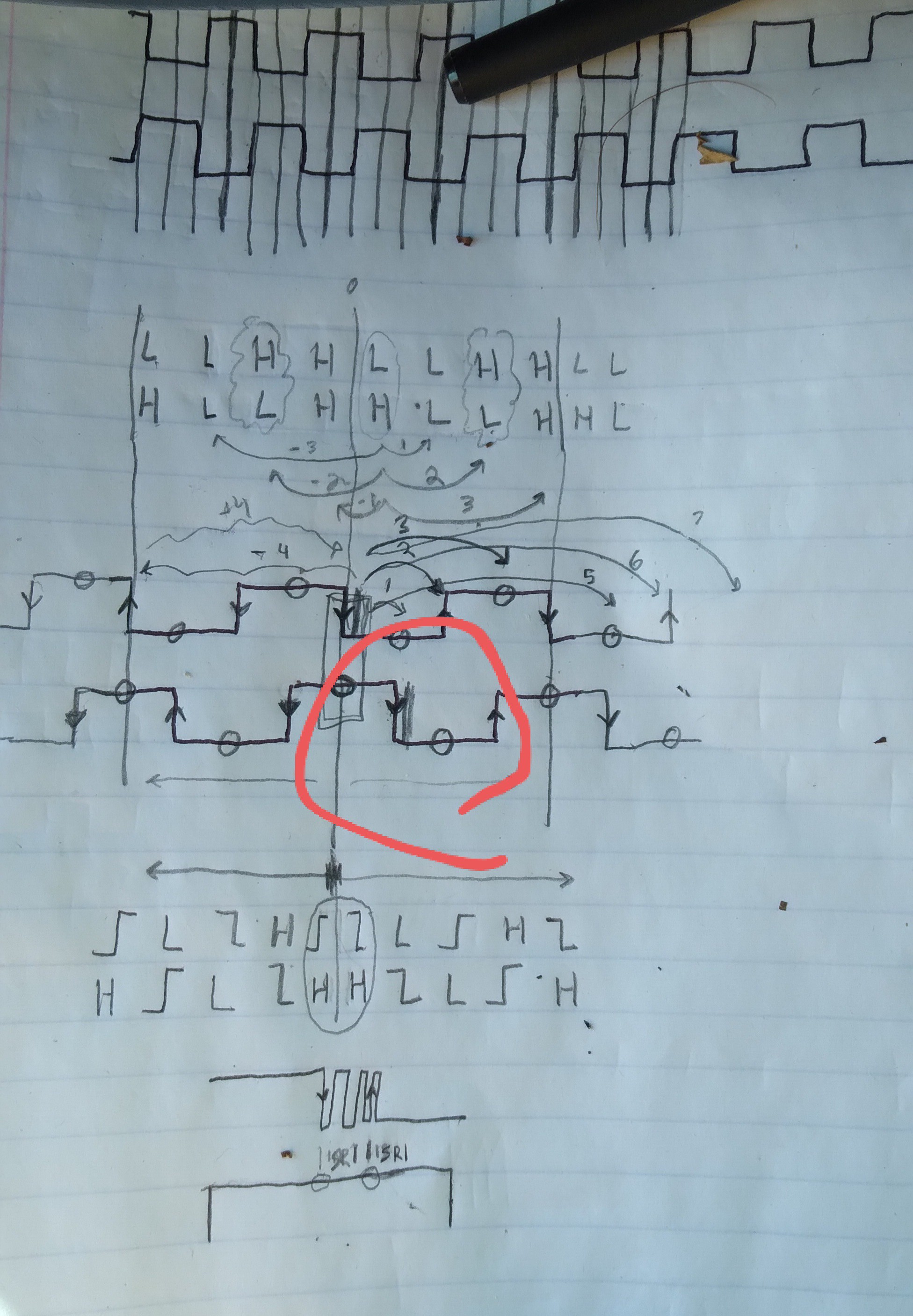
The key-factor involves looking for an edge on one input, then immediately after receiving it, switch to looking for a different edge on the other input. Why? Well, think of it like the ol' pushbutton-debouncing technique of using an SPDT button and a set-reset latch. When the first edge comes through, it flat-out stops paying attention to that signal (set is set already. Any number of bounces on the set input won't change that). That signal is now debounced. So, now wait for the "pushbutton's" "release" to reset the flip-flop. Again, if it bounces it doesn't change anything.
This is especially relevant in quadrature because when there's one edge, the other input should be steady (high or low) by design. So...
BWAHAHAHA!!!! NOPE!!!!
A couple days later I see the problem.
NOPE!
Because bounce on the next falling edge would mean a rising-edge we're looking for. Two ticks too early. Where the "direction" signal is inverted.
![]()
NOPE.
.
So, still, we have to watch *every* quadrature edge.
-
Interrupts Are Stupid
02/16/2023 at 09:13 • 0 commentsImagine you've designed a clock...
Each time the seconds go from 59 to 0, it should update the minutes.
Imagine it takes three seconds to calculate the next minute from the previous.
So, if you have an interrupt at 59 seconds to update the minute-hand, the seconds-hand will fall-behind 3 seconds, by the time the minute-hand is updated.
...
Now, if you knew it takes three seconds to update the minute-hand, you could set up an interrupt at 57 seconds, instead of 59.
Then the minute-hand would move one minute exactly after the end of the previous minute.
BUT the seconds-hand would stop at 57 seconds, because updating the minute uses the entirety of the CPU. If you're clever, the seconds-hand would jump to 0 along with the minute's increment.
....
Now... doesn't this seem crazy?
...
OK, let's say we know it takes 3 seconds of CPU-time to update the minute-hand. But, in the meantime we also want to keep updating the seconds-hand. So we start updating the minutes-hand *six* seconds early... at 54 seconds. That leaves six half- seconds for updating the seconds-hand, in realtime, once-per-second, and three split-up seconds for updating the minutes-hand once.
But, of course, there's overhead in switching tasks, so say this all starts at 50 seconds.
...
At what point do we say, "hey, interrupts are stupid" and instead ask "what if we divided-up the minutes-update task into 60 steps, each occurring alongside the seconds-update?"
What would be the overhead in doing-so?
...
So, sure, it may be that doing it once per minute requires 3 seconds, but it may turn out that the interrupt-overhead is 0.5 times that, due to pushes and pops, and loading variables from SRAM into registers, etc.
And it may well turn out that dividing that 3 seconds across six will require twice as much processing time due to, essentially, loading a byte from SRAM into a register, doing some small calculation, then storing it back toSRAM to perform the same load-process-store pocedure again a second later...
But, if divided-up right, one can *both* update the seconds-hand and calculate/update the minutes-hand every second; no lag on the seconds-hand caused by the mintues' calculation.
No lag caused by a slew of push/pops.
...
And if done with just a tiny bit more foresight, no lag caused by the hours-hand, either.
...
Now, somewhere in here is the concept I've been dealing with off-n-on for roughly a decade. REMOVE the interrupts. Use SMALL-stepping State-Machines, with polling. Bump that main-loop up to as-fast-as-possible.
With an 8-bit AVR I was once able to sample audio at roughly its max of 10KS/s, store into an SD-Card, sample a *bitbanged* 9600-baud keyboard, write to an SPI-attached LCD, writes to EEPROM, and more... with a guaranteed 10,000 loops per second, averaging 14,000. ALL of those operations handled *without* interrupts.
Why? Again, because if, say, I'd used a UART-RX interrupt for the keyboard, it'd've taken far more than 1/10,000th of a second to process it, between all the necessary push/pops, and the processing routine itself (looking up scancodes, etc), which would've interfered with the ADC's 10KS/s sampling, which would've interfered with that sample's being written to the SDCard.
Instead: i.e. I knew the keyboard *couldn't* transmit more than 960 bytes/sec, so I could divide-up its processing over 1/960th of a second. Similar with the ADC's 10KS/s, and similar with the SDCard, etc. And, again, in doing-so managed to divide it all up into small pieces that could be handled, altogether, in about 1/10000th of a second. Even though, again, handling any one of those in its entirety, in say, an interrupt, would've taken far more than 1/10000th of a second; throwing everything off, just like the seconds-hand not updating between 57 and 0 seconds in the analogy.
-
If you ever wondered about weather predictions
12/22/2022 at 07:24 • 0 comments![]()
![]()
-
Hard Disk vs VHS reality-check
12/12/2022 at 06:05 • 0 commentsThere used to be special ISA cards that allowed for connecting a VCR to a PC in order to use the VCR as a tape-backup.
I always thought that was "cool" from a technological standpoint, but a bit gimmicky. I mean, sure, you could do the same with a bunch of audio cassettes if you're patient.
...
But, actually, I've done some quick research/math and think it may not have been so ridiculous, after-all.
In fact, it was probably *much* faster than most tape-backup drives at the time, due to its helical heads. And certainly a single VHS tape could store far more data. (nevermind their being cheap, back then).
In fact, the numbers suggest videocassettes were pretty-much on-par with spinning platters from half a decade later in many ways.
https://en.m.wikipedia.org/wiki/VHS
https://en.m.wikipedia.org/wiki/ST506/ST412
I somehow was under the impression the head on a VHS scans one *line* of the picture each time it passes the tape. But, apparently it actually scans an entire frame. At 60Hz!
In Spinning-platter-terms, it'd be the equivalent of a hard disk spinning at 3600RPM. Sure, not blisteringly fast, but not the order-of-magnitude difference I was expecting.
The video bandwidth is 3MHz, which may again seem slow, but again, consider that hard drives from half a decade later were limited to 5MHz, and probably didn't reach that before IDE replaced them...
"The limited bandwidth of the data cable was not an issue at the time and is not the factor that limited the performance of the system."
...
I'm losing steam.
...
But this came up as a result of thinking about how to archive old hard drives' data without having a functioning computer/OS/interface-card to do-so.
"The ST506 interface between the controller and drive was derived from the Shugart Associates SA1000 interface,[5] which was in turn based upon the floppy disk drive interface,[6] thereby making disk controller design relatively easy."
First-off, it wouldn't be too difficult to nearly directly interface two drives of these sorts to each other, with a simple microcontroller (or, frankly, a handful of TTL logic) inbetween to watch index pulses and control stepping, head-selects, and write-gates. After that, the original drive's "read data" output could be wired directly to the destination's "write data" input. Thus copying from an older/smaller drive to a newer/larger one with no host inbetween.
It's got its caveats... E.G. The new drive would only be usable in place of the original, on the original's controller, *as though* it was the original drive.
The new drive has to have equal or more cylinders and heads. It has to spin at exactly the same rate, or slower. Its magnetic coating has to handle the recording density (especially, again, if it spins slower).
BUT: it could be done. Which might be good reason to keep a later-model drive like these around if you're into retro stuff. I'm betting some of the drives from that era can even adjust their spin-rate with a potentiometer.
...
Anyhow, again, I've a lot to cover, but I'm really losing steam.
...
Enter the thoughts on using VHS as an only slightly more difficult-to-interface direct-track-copying method... as long as the drive (maybe Shugart or early MFM? is within the VHS's abilities, which it seems there may very well be such drives in retro-gurus' hands.
So, herein, say you've got a 5MB mini-fridge-sized drive with an AC spindle-motor (which just happens to spin at 3600RPM, hmm). Heh...
Anyhow, I guess it's ridiculous these days, each track could be recorded directly to a PC via a USB logic analyzer, right? (certainly with #sdramThingZero - 133MS/s 32-bit Logic Analyzer)
Or isn't there something like that already for floppies ("something-flux").
Anyhow, I guess the main point is that storing/transferring the flux-transitions in "analog" [wherein I mean *temporally*] has the benefit of not needing to know details like the exact bit/sample-rate, or the encoding format (RLL/MFM/FM], nor anything about higher-level details like the OS's choice of sector-size or hex values for padding bytes.
I guess this has all been done.
I just thought it interesting that VCRs are in many ways on-par with hard disks from the era. I knew the helical-scan thing was a clever solution, but had no idea it was *that* clever. Heck, cassettes aren't cleanrooms.
...
I guess maybe part of the idea was something along the lines of backing up the original minifridge drive onto tape, then dumping that back to a 5.25in drive of higher capacity (once a suitable one is acquired); their interfaces are basically compatible, and unlike IDE/SCSI, no knowledge of the actual *data*/format would be necessary in the transfer, nor would the new drive's actual parameters need to be identical to the old one's. Yet the old controller card would think it the same. I think that's intriguing. (oh, bad sectors in different locations might prevent this idea, heh).
It's not dissimilar to my finding out that throwing a 1.44M 3.5in floppy drive in place of a 400K 5.25in drive was perfectly doable in #OMNI 4 - a Kaypro 2x Logic Analyzer .
Not unlike using a duplicate of your favorite video-game floppy-disk to play from, rather than wearing-out the original... Except, instead of disks, we're talking drives, heh!
...
12/16/22:
The HaD blog just had a relevant article...
https://hackaday.com/2022/12/13/vhs-decode-project-could-help-archival-efforts/#more-567080
In the comments was this, which i'll peruse later: https://www.spiraltechinc.com/otis/IRIG_Files/IRIG_Chap6F.htm
Random Tricks and Musings
Electronics, Physics, Math... Tricks/musings I haven't seen elsewhere.