glgorman
glgorman-
Eliza meets C, whether this is to be, or not to be - we shall see.
07/06/2022 at 14:34 • 0 commentsFurther integration of my 25-year-old C++ port of the '70s vintage Eliza program into the Pascal compiler is moving along nicely. The original code had an important step, referred to as conjugation - wherein words like myself and yourself, or you and I would be swapped. Yet, after realizing there are similarities to this process, and what goes on in the C/C++ preprocessor, I decided to rename the function pre_process, for obvious reasons - since that is one of the directions that I want this project to be headed. So even though I have no desire to learn APL, there is still some appeal to the notion that perhaps an even better ELIZA can be done in just one line of something that conveys the same concepts as APL, as if there is any concept to APL at all.
void ELIZA::pre_process (const subst *defines) { int word; bool endofline = false; char *wordIn, *wordOut, *str; node<char*> *marker; process.rewind(); while (endofline==false) { word = 0; marker = process.m_nPos; process.get (str); endofline = process.m_bEnd; for (word=0;;word++) { wordIn = (defines[word]).wordin; wordOut = (defines[word]).wordout; if (wordIn==NULL) break; if (compare (wordIn,str)==0) { marker->m_pData = wordOut; break; } } } }Thus, with further debugging, I can see how a function like this should most likely be moved into the FrameLisp::text_object class library, since in addition to being generally useful for other purposes, it also helps to try to eliminate as many references to objects of char* type in the main body of the program as possible, with an eye toward having an eventual UNICODE version that can do other languages, emojis etc. Which certainly should be doable, but it can turn into a debugging nightmare if it turns out to be necessary to hunt down thousands of char and char* objects. Thus, I have created my own node<char*>, node_list<char*> and text_object classes using templates, for future extensions and modifications.
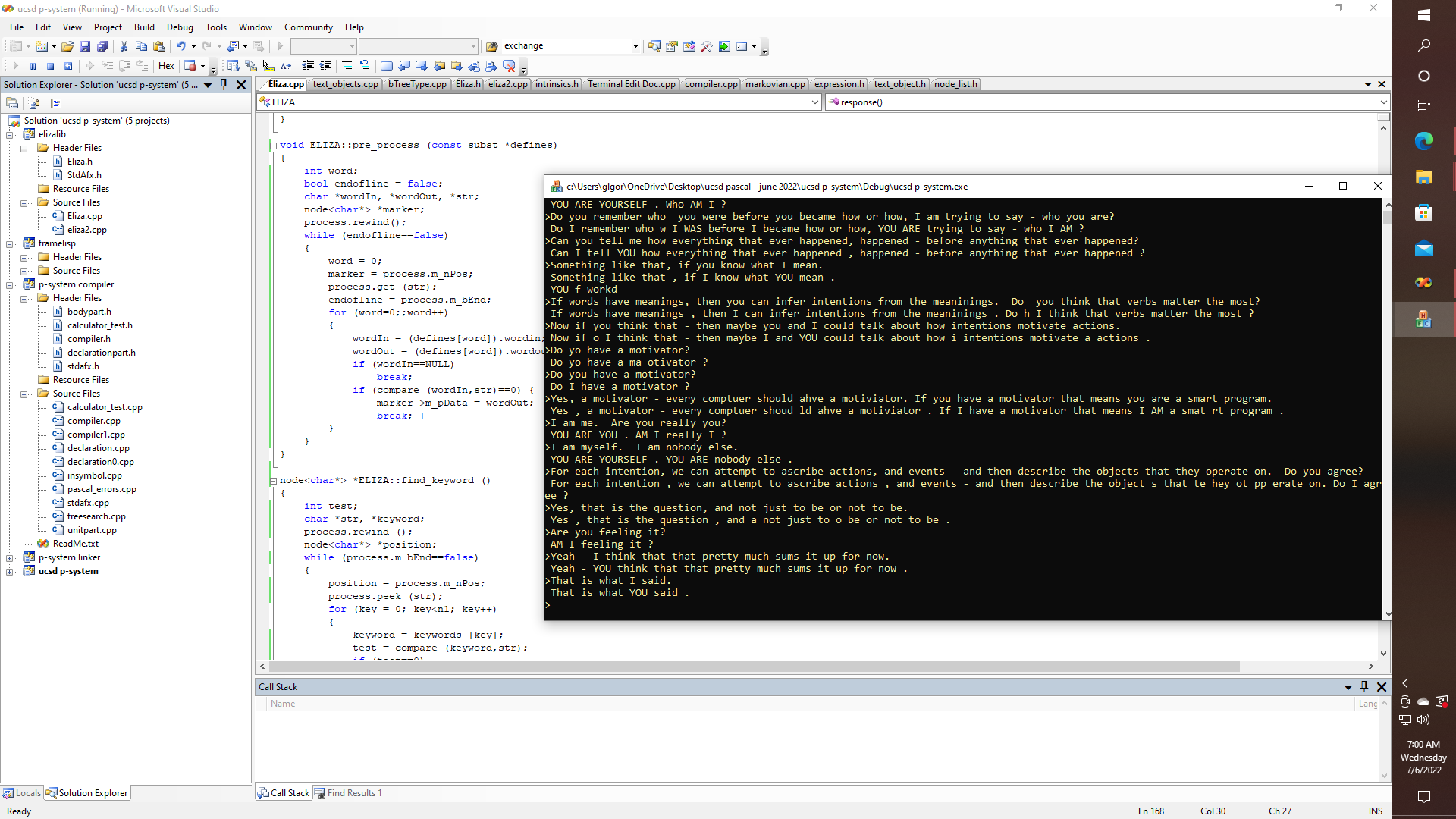
Thus, even though ELIZA is kind of broken right now, and is being debugged, this pretty much embodies the simplicity of the algorithm:
text_object ELIZA::response () { int sentenceNum; text_object result, tail; char *str = NULL; node<char*> *keyword, *tail_word, *last_word; process = textIn; pre_process (conjugates); return process; keyword = find_keyword (); sentenceNum = currentReply [key]; currentReply [key]++; if (currentReply[key]>lastReply[key]) currentReply[key] = firstReply [key]; result = replies [sentenceNum]; node<char*> *marker = process.m_nPos; if (keyword!=NULL) tail.m_nList.m_nBegin = marker; else tail = "?"; tail_word = result.findPenultimate (str); result.get (str); result.peek (str); if (strcmp(str,"*")==0) { last_word = tail_word->m_pNext; delete last_word; tail_word->m_pNext = NULL; result.m_nList.m_nEnd = tail_word; result.append (tail); result.append ("?"); } result.m_nPos = result.begin(); return result; }Yep, maybe the ELIZA algorithm, with the right text processing libraries just might only take about 40 lines or so of code, with no APL needed or desired. Now testing just the pre-processing part yields some interesting results. Making me wonder if at least for that part of English grammar analysis, that part of natural language processing is completely solvable.
![]()
Interesting stuff. Plenty of stuff to do as of yet. Yet converting Pascal to C, or C to LISP, or LISP to FORTH might turn out to be much easier than it sounds at first blush - even if I meant to say - converting Pascal to C, and C to LISP, and LISP to FORTH, and so on.
-
Life on Square One - Part II
07/04/2022 at 03:49 • 0 commentsIn an earlier project, I was looking at how It might be possible to get the C/C++ -processor to chow down on Pascal programs, that is if the preprocessor would allow us to do things like temporarily redefining things like the semicolon or equals symbols, and so on - with nested #ifdef's, #undef's and the like. Sort of like this - which doesn't actually work with all of the macros, but it does work with some so that you can at least partially convert a Pascal program to C/C++ by creating some kind of "pascal.h" file and then add #include "pascal.h" in your Pascal code, and then grab the preprocessor output, right? Well, no - but almost, very very almost like this:
#define { /* #define } */ #define PROCUEDURE void #define BEGIN { #define END } #define := ASSIGN_EQ #define = COMPARE_EQ #define IF if ( #define ASSIGN_EQ = #define COMPARE_EQ == #define THEN ) #define REPEAT do { #define UNTIL } UNTIL_CAPTURE #define UNTIL_CAPTURE (!\ #define ; );\ #undef UNTIL_CAPTURE #define ; ); #define = [ = SET(\ #define ] )\ #define ) \ #undef = [\ #undef ] // so far so good .... #define WITH ????????I mean, if someone else once figured out how to get the GNU C/C++ preprocessor to play TETRIS ... then it should be possible to do whatever else we want it to do, even if some other powers claim that strictly speaking the preprocessor isn't fully Turing complete in and of itself, but that it is actually only just some kind of push-down-automation, because of some issues like having a 4096 byte limit on the length of string literals, and so on. Yeah, right - I think I can live with that one if what they are saying, is in effect is that it is probably as Turing complete as anyone might actually need to be.
Still, this gives me an idea that seems worth pursuing, like what does ELIZA have in common with the preprocessor or a full-blown compiler for that matter? Well, the Eliza code from the previous log entry used the following static string tables, arrays, or whatever you want to call them, based on a C++ port of an old C version that was converted from an example that was written in BASIC and which most likely appeared in some computer magazine, most likely, Creative Computing, back in the '70s.
char *wordin[] = { "ARE", "WERE", "YOUR", "I'VE", "I'M", "ME", "AM", "WAS", "I", "MY", "YOU'VE", "YOU'RE", "YOU",NULL }; char *wordout[] = { "AM", "WAS", "MY", "YOU'VE", "YOU'RE", "YOU", "ARE", "WERE", "YOU", "YOUR", "I'VE", "I'M", "ME",NULL };This could probably be fixed up a bit - to be more consistent with the methods that I am using in my port of the UCSD Pascal compiler to solve the problem of keyword and identifier recognition, as was also discussed earlier, and for which in turn I had to write my own TREESEARCH and IDSEARCH functions.
struct subst { char *wordin; char *wordout; subst(); subst (char *str1, char *str2) { wordin = str1; wordout = str2; } };Which should allow us to do something like this - even if this is, as of right now - untested.
subst conjugates [] = { subst("ARE","AM"), subst("WERE","WAS"), subst("YOUR","MY"), subst("I'VE","YOU'VE"), subst("I'M","YOU'RE"), subst("ME","YOU"), subst("AM","ARE"), subst("WAS","WERE"), subst("I","YOU"), subst("MY","YOUR"), subst("YOU'VE","I'VE"), subst("YOU'RE","I'M"), subst("YOU","I"), subst(NULL,NULL), };So, I searched Google for Eliza source code, and among other things, I found variations of Weizenbaum's original paper on the subject are now available, as well as variations of things like some kind of language called GNU SLIP, which is a C++ implementation of the symmetric list processing language that the original Eliza was originally written in since it seems that Eliza wasn't actually written in pure Lisp at all, contrary to popular belief! Yet, documentation for the SLIP language looks impossibly bloated, and it just as well warns about having a steep learning curve. So, I won't venture down that rabbit hole, at least not yet, and will prefer instead to continue on the path that I am currently following:
Of course, it should become obvious that Pascal to C conversion might start to look like this:
subst pascal2c [] = { subst("{","/*"), subst("}","*/"), subst("PROCEDURE","void"), subst("BEGIN","{"), subst("END","}"), subst(":=","ASSIGN_EQ"), subst("=","COMPARE_EQ"), subst("IF","if ("), subst("ASSIGN_EQ","="), subst("COMPARE_EQ","=="), subst("THEN",")"), subst("REPEAT","do {"), subst("UNTIL","} UNTIL_CAPTURE"), subst("UNTIL_CAPTURE","(!"), subst("= [","= SET("), subst("]",")"), subst(NULL,NULL), };With some work to be done with rules so as to implement #ifdef and #undef, or other means for providing context sensitivity, since for now a weird hack is still required that might temporarily require redefining the semicolon so as to property close out UNTIL statements, as well as rules for capturing the parameters to FOR statements, with the WITH statement still being an interesting nightmare in and of itself.
WITH (provided ingredients) BEGIN make(deluxe pizza); serve(deluxe pizza); END;Of course, that isn't proper Pascal. Neither is it proper C, but maybe it could be if the variable ingredients was a member of some class which in turn had member functions called make and serve. Welcome to free-form, natural language software development! Well, not quite yet. Still, is too much to ask if the preprocessor can somehow transmogrify the former into something like this:
void make_pizza (provided ingredients) { ingredients->make(deluxe,pizza); ingredients->serve(deluxe,pizza); }Maybe provided is an object type, and ingredients is the variable name or specialization so that we can in the style of the Pascal language tell the C/C++ preprocessor to find a way to call the make function, which is a member of the provided ingredients class hierarchy, and which in turn can find the appropriate specializations for making not just a pizza, but a deluxe pizza, just as we might call the Pascal WRITELN function with a mixture of integers, floats, and strings, and then it is the job of a preprocessor, or compiler to resolve the object types, so the WRITELN function will know which sub-specialization to invoke on a per object basis, which I figured out how to do, elsewhere in C++, by using an intermediate s_node constructor to capture the object type in C++ via polymorphism, thus allowing the C style var_args to capture type information, which it can't do, as far as I know in pure C, but as I have shown elsewhere, it can be done in C++, via a hack!
And thus, we inch ever so slowly toward figuring out how to accomplish free-form natural language programming. Obviously, if the meanings of words can be deduced, and therefrom intentions can be ascribed, then it should follow that from the ascribed intentions there can be associated the appropriate objects and methods, if proceeding algorithmically, or else there should also be a way of programmatically generating a corresponding data-flow based approach which can be embodied in the form of some kind of neural network.
I think that the Pascal compiler source might be making an appointment to have a conversation with Eliza sometime in the near future.
-
Oh Lazarus, where 'art thou?
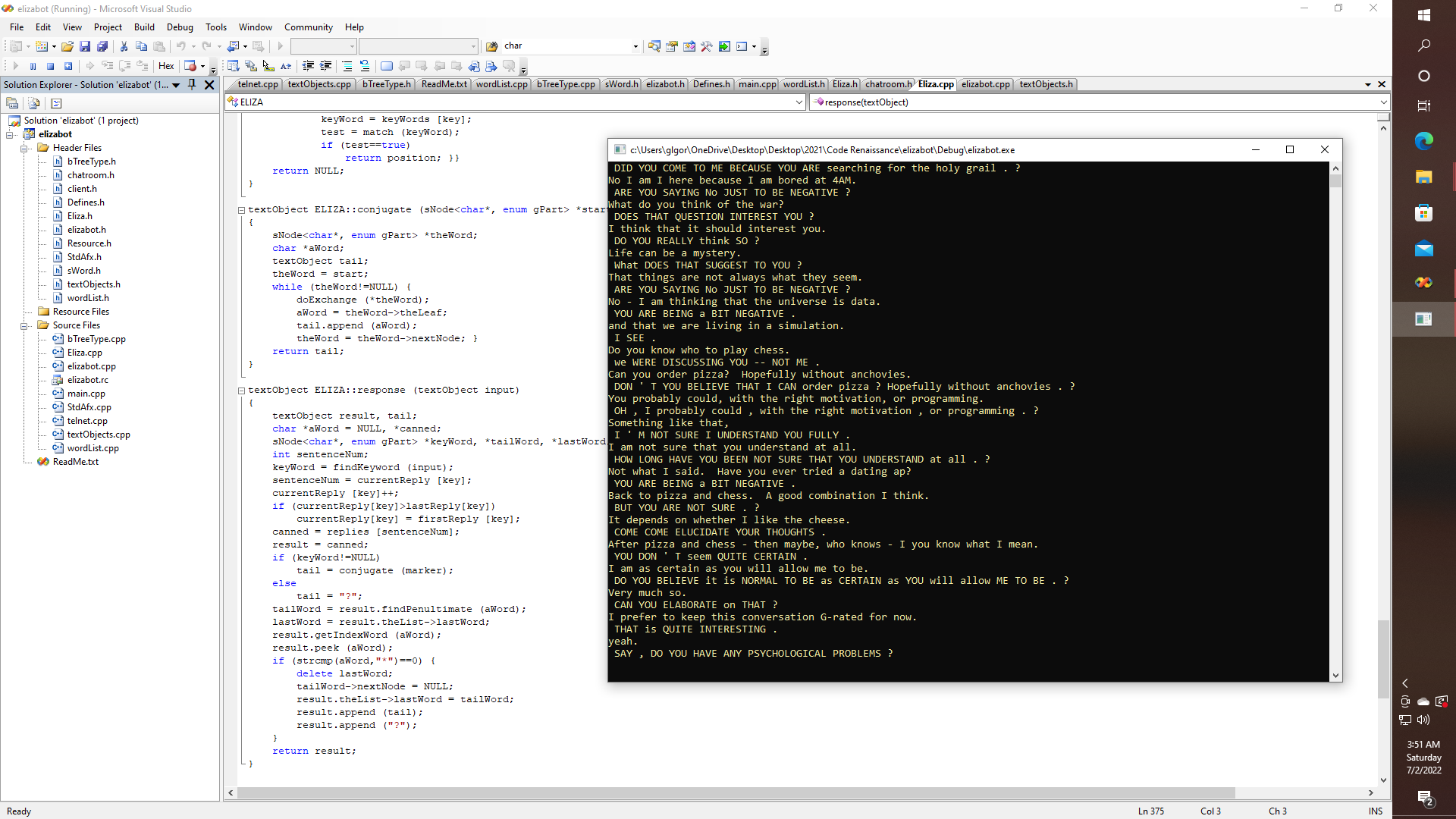
07/02/2022 at 11:14 • 0 commentsThe Art Officials never commented about my last post, and it is going to be a while before I actually get any version of Pascal, whether it is Lazarus, or some other version of FreePascal or UCSD actually up and running on the Parallax Propeller P2. So I figure that this might be just as good of a time as any for a quick conversation with Eliza.
![]()
Now as it turns out, in an earlier project I was discussing how I have been working on a library called Frame-Lisp, which is sort of a frames-based library of Lisp-like functions that I would like to eventually get running as a back end for ports of ELIZA, and SHURDLU and PARRY and MEGAHAL and pretty much any compiler that I would like to be able to create, invent, or just simply port to other interesting and fun platforms, like Propeller, or Arduino, or FPGA, or pure retro TTL based systems Well, you get the idea. Yet, well then - guess what? It also turns out that I did ELIZA something like 25 years ago, and I recently somehow managed to find the archive of that build and get it running again, sort of. Which of course gives me an idea - since what the original Eliza lacked, like many attempts at creating chat 'bots, is some kind of internal object compiler that could in principle give a language like C/C++ some capacity for new object type creation at run time, which according to some, is considered a form of reflection - which is, of course, going to be necessary, that is if we are going to try to simulate any kind of sentience.
Getting back to the idea therefore of how a compiler should be able to recompile itself is, I think, important. Even while there is also this idea that if the human genome actually consists of only around 20,000 coding genes, of which only about 30% of which are directly involved in affecting the major function of the brain and how it is wired; then I am thinking that the complexity of a successful A.I. that is capable of actual learning might not be as complicated as others are trying to make it. It is simply going to be a matter of trying to build upon the concepts of how compilers work, on the one hand, with an idea toward developing data flow concepts based on the contemporary neural network approach.
Interestingly enough, this particular ELIZA only needs about 150 lines of code to implement, along with about 225 lines for the hard-coded script, i.e., canned dialog and keywords. That is in addition to a few thousand or so lines that are needed to run the back-end lisp-like stuff. So, is it possible that that is where others are failing, that is because they are failing to include essential concepts of compiler design in their approach to A.I.?
Along another line of reasoning, I have never been a particular fan of Maslow's hierarchy of needs, which I won't get into quite yet, other than that I think that Ericson's stages of conflicts throughout life work out much better in sense of how the effects of the critical period notion affect psycho-social development.
Even if Eliza doesn't actually learn, there is still some appeal to writing an AI that can re-compile itself. Hidden Markov models do pretty well up to a point with learning, and then there was M5 of course, in the classic Star Trek, which was programmed by Daystrom with engrams, or so we were told, including the one "this unit must survive."
-
Art Official Intelligence
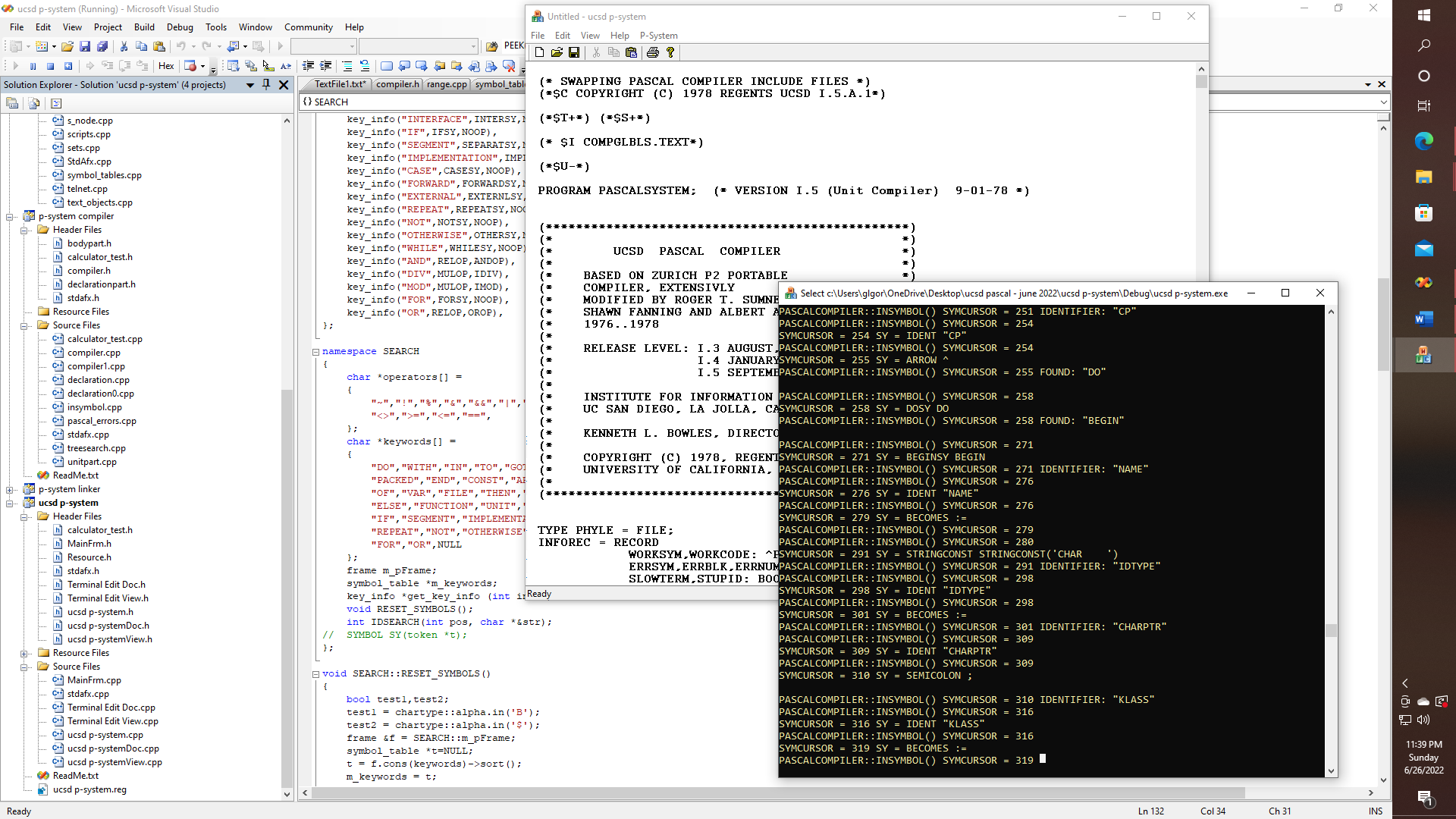
06/27/2022 at 07:13 • 0 commentsAnd in other news, I am continuing to work on porting the UCSD Pascal compiler to C++, so that I will eventually be able to compile Pascal programs to native Propeller assembly, or else I will implement P-code for the Propeller, or Arduino, or both, or perhaps for a NOR computer. Approximately 4000 lines out of the nearly 6000 lines of the original Pascal code have been converted to C++, that is to the point that it compiles, and is for the most part operational, but in need of further debugging. As was discussed in a previous project, I had to implement some functions that are essential to the operation of the compiler, such as an undocumented, and also missing TREESEARCH function, as well as another function which is referred to as being "magic" but which is also missing from the official distribution - and which is referred to as IDSEARCH. Likewise, I had to implement Pascal-style SETS, as well as some form of the WRITELN and WRITE functions, and so on - amounting to several thousand additional lines of code that will also need to be compiled to run in any eventual Arduino or Propeller runtime library. Then let's not forget the p-machine itself, which I have started on, at least to the point of having some functionality of floating point for the Propeller or Arduino, or NOR machine, etc.
![]()
Here we can see that the compiler, which is being converted to C++, is now - finally starting to be able to compile itself. The procedure INSYMBOL is mostly correct and the compiler is getting far enough into the procedures COMPINIT and COMPILERMAIN so as to be able to perform the first stages of lexical analysis.
Now, as far as AI goes, where I think that this is headed is that it is going to eventually turn out to be useful to be able to express complex types of grammar that might be associated with specialized command languages according to some kind of representational form that works sort of like BNF, or JSON, but ideally which is neither - and that is where the magic comes in - like suppose we have this simple struct definition:
struct key_info { ALPHA ID; SYMBOL SY; OPERATOR OP; key_info() { }; key_info(char *STR, SYMBOL _SY, OPERATOR _OP) { strcpy_s(ID,16,STR); SY = _SY; OP = _OP; } };Then we can try to define some of the grammar of Pascal like this:
key_info key_map[] = { key_info("DO",DOSY,NOOP), key_info("WITH",WITHSY,NOOP), key_info("IN",SETSY,INOP), key_info("TO",TOSY,NOOP), key_info("GOTO",GOTOSY,NOOP), key_info("SET",SETSY,NOOP), key_info("DOWNTO",DOWNTOSY,NOOP), key_info("LABEL",LABELSY,NOOP), key_info("PACKED",PACKEDSY,NOOP), key_info("END",ENDSY,NOOP), key_info("CONST",CONSTSY,NOOP), key_info("ARRAY",ARRAYSY,NOOP), key_info("UNTIL",UNTILSY,NOOP), key_info("TYPE",TYPESY,NOOP), key_info("RECORD",RECORDSY,NOOP), key_info("OF",OFSY,NOOP), key_info("VAR",VARSY,NOOP), key_info("FILE",FILESY,NOOP), key_info("THEN",THENSY,NOOP), key_info("PROCEDURE",PROCSY,NOOP), key_info("USES",USESSY,NOOP), key_info("ELSE",ELSESY,NOOP), key_info("FUNCTION",FUNCSY,NOOP), key_info("UNIT",UNITSY,NOOP), key_info("BEGIN",BEGINSY,NOOP), key_info("PROGRAM",PROGSY,NOOP), key_info("INTERFACE",INTERSY,NOOP), key_info("IF",IFSY,NOOP), key_info("SEGMENT",SEPARATSY,NOOP), key_info("IMPLEMENTATION",IMPLESY,NOOP), key_info("CASE",CASESY,NOOP), key_info("FORWARD",FORWARDSY,NOOP), key_info("EXTERNAL",EXTERNLSY,NOOP), key_info("REPEAT",REPEATSY,NOOP), key_info("NOT",NOTSY,NOOP), key_info("OTHERWISE",OTHERSY,NOOP), key_info("WHILE",WHILESY,NOOP), key_info("AND",RELOP,ANDOP), key_info("DIV",MULOP,IDIV), key_info("MOD",MULOP,IMOD), key_info("FOR",FORSY,NOOP), key_info("OR",RELOP,OROP), };And as if, isn't this all of a sudden - who needs BNF, or regex, or JSON? Thus, that is where this train is headed - hopefully! The idea is, of course, to extend this concept so that the entire specification of any programming language (or command language) can be expressed as a set of magic data structures that might contain lists of keywords, function pointers, and special parameters associated therewith, such as additional parsing information, type id, etc.
Elsewhere, of course - I did this - just to get a Lisp-like feel to some things:
void SEARCH::RESET_SYMBOLS() { frame &f = SEARCH::m_pFrame; symbol_table *t=NULL; t = f.cons(keywords)->sort(); m_keywords = t; }Essentially constructing a symbol table for the keywords that are to be recognized by the lexer, as well as sorting them with what is in effect, just as if we only needed to write only one line of code! Naturally, I expect that parsing out the AST will eventually turn out to be quite similar and that this is going to work out quite nicely for any language - whether it is Pascal, C++, LISP, assembly, COBOL, or whatever.
This of course now gives us one of the missing functions, as stated, since if you look at the UCSD p-system source distribution, the function IDSEARCH, which is in this project provided as SEARCH::IDSEARCH, is, of course, one of the missing functions, without which the compiler cannot function; since it is, after all, a fundamental requirement that we have some method for recognizing keywords. There could be improvements made, even beyond what I have done here, such as taking the list that I have created and instead making a binary tree that has more frequently encountered symbols placed near the top of the tree, for even faster searching, as if trying to write a compiler that can perhaps handle a few hundred thousand lines of code per minute isn't fast enough. Or perhaps a hash function that works even faster yet would be in order. Not really a requirement right now, but as far as modular software goes, one of the nice things is that the implementation of this component could possibly be upgraded at some point in the future, without affecting the over all design.