 Ted Yapo
Ted YapoOK, I want to do some flashy graphics on a PIC. And on a VGA monitor. I've generated composite video on PICs before, and seen VGA implemented, but it's always a pain, and you're forced to accept marginal timings and low resolution. One particularly nice job of navigating the constraints is at #VGA Blinking Lights - actually another contest entry! But, I want a full-resolution display and while I fondly remember the timing liberties you could take with "multisync" CRTs back in the linux modeline days, I'm not sure modern LCDs are so forgiving. So, I'm planning an actual 640x480 display with standard timings, which means a 25.175 MHz dot clock - too fast to bitbang - and a bunch of external memory to store the pretty pixels.
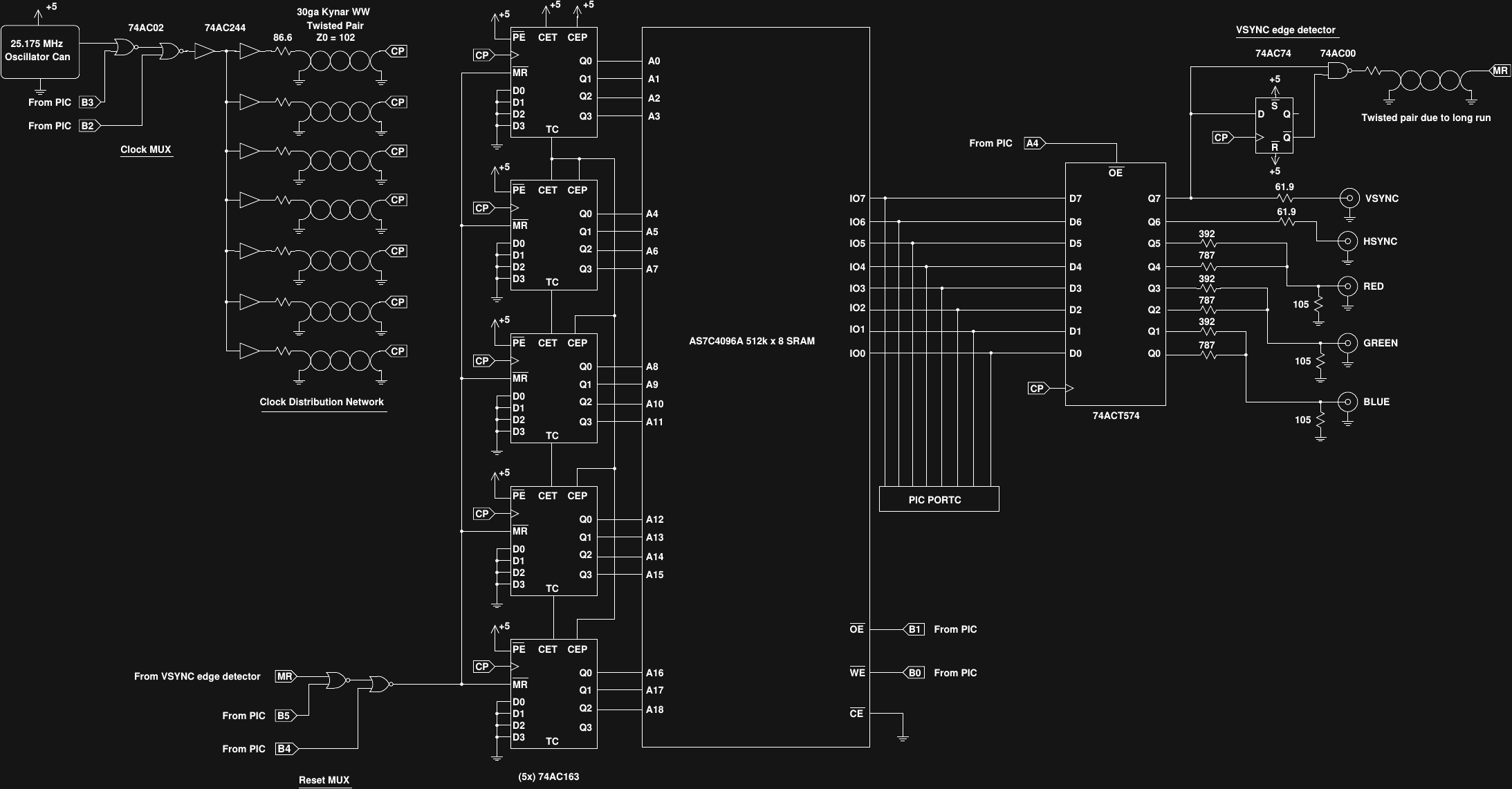
Luckily, I've been following @esot.eric's adventures with #sdramThingZero. His work has inspired me to store the whole digitized VGA signal, sync pulses and all, in a 4 Mbit SRAM. The pic can write the required waveforms to the RAM at its leisure, then the signal can be clocked out at 25.175 MHz with a few 74AC163 counters and a handful of latches and glue logic.
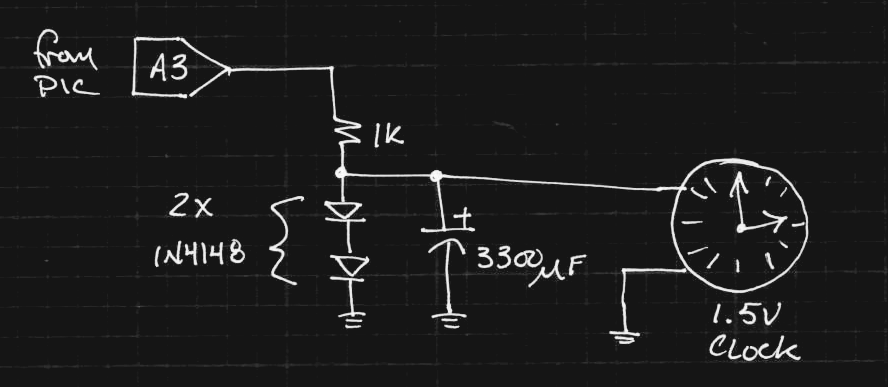
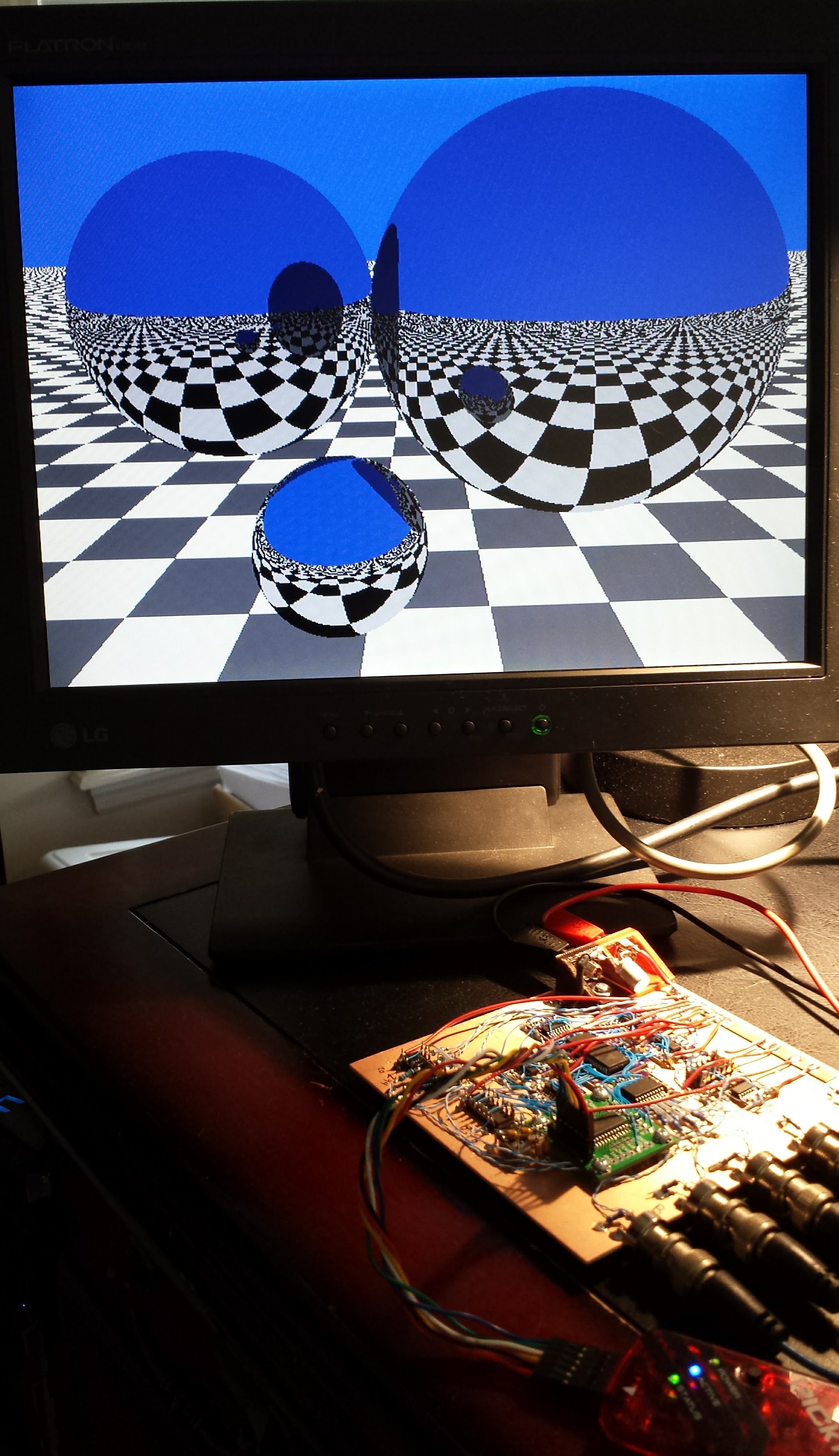
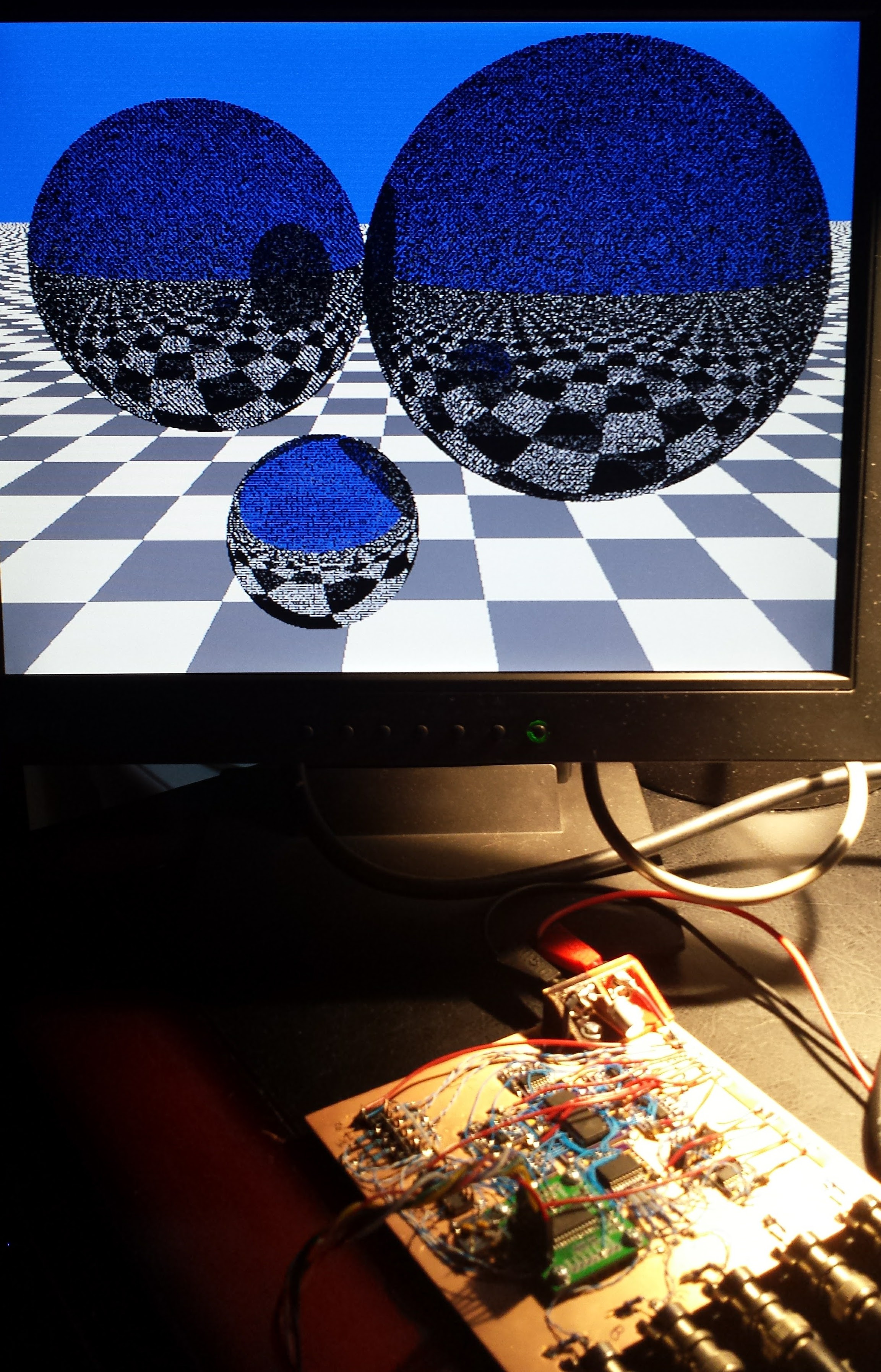
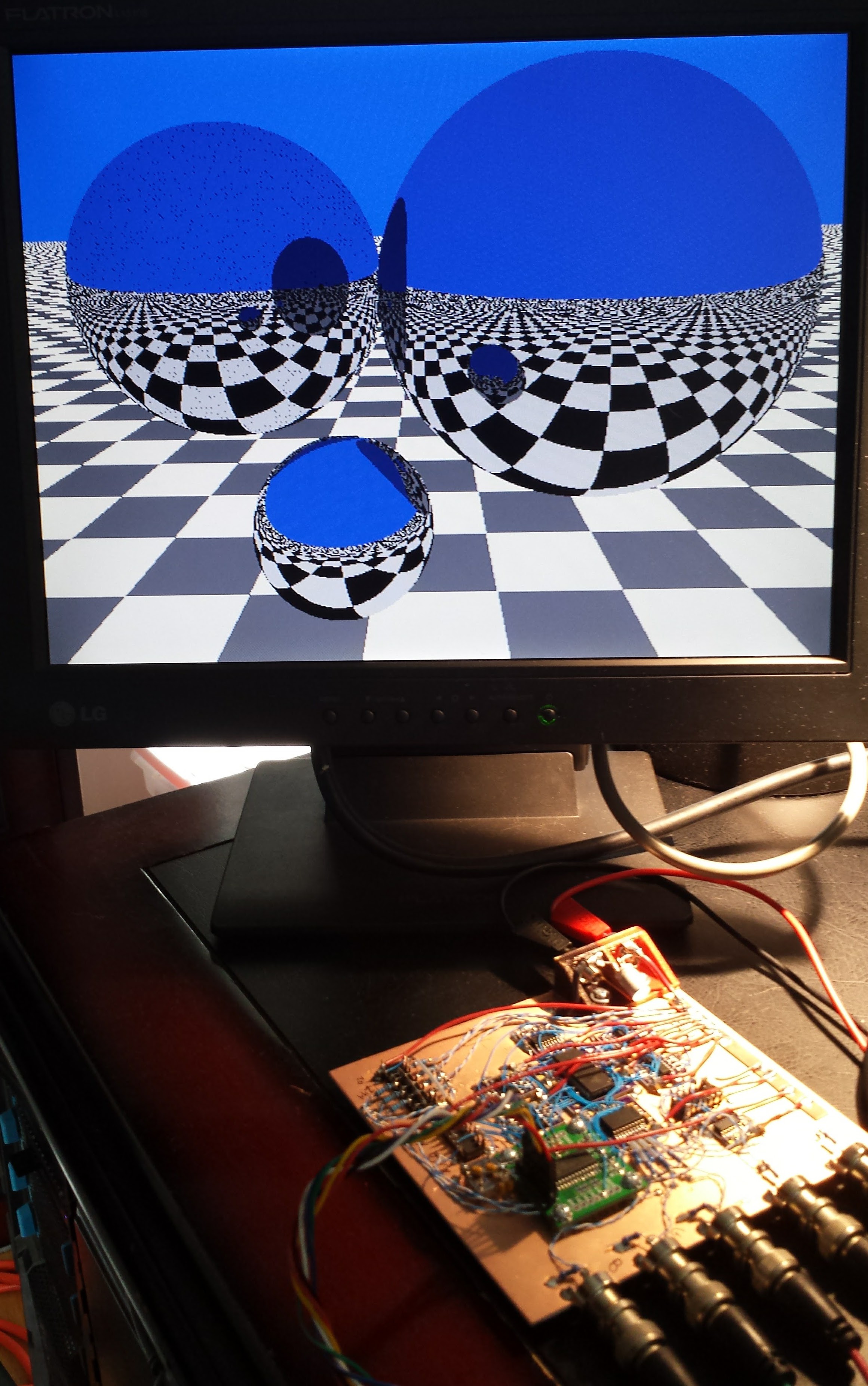
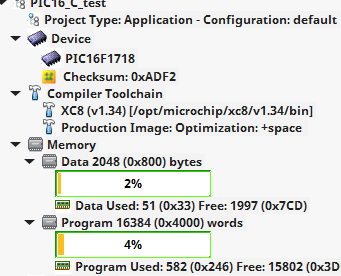
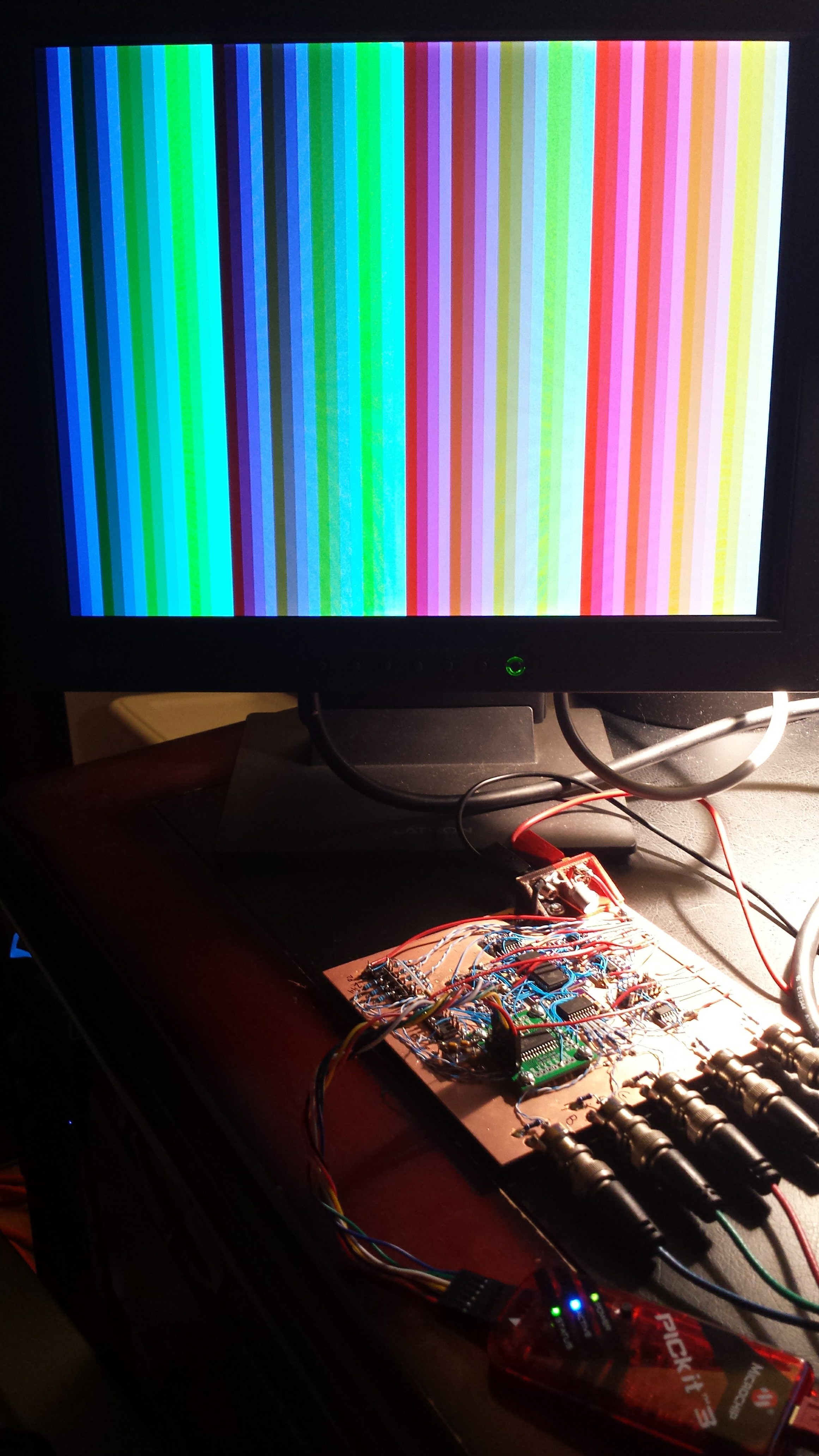
I got fractals working in 1kB on a PIC16F1718 coded in pure C with the hardware 640x480 VGA adapter. The results are in this log and the code is here. The hardware is discussed in this log, and a pdf schematic can be downloaded here.













What is the actual PIC you are going to use?
Btw. your spellcheck is too pic-ky