 kasik
kasikAs mentioned in the description of the project, I am working on the remote feeder (I start with figuring out the communication with one of the most common remote feeder available on the market) that can spot that someone is at the door via camera and recognising the sound of a knock/doorbell.
This is very useful to help teach the dog calmness when someone comes and help also with barking. There is this amazing positive reinforcement dog trainer, Susan Garrett, who talks about it in her podcast: https://dogsthat.com/podcast/240/
The prototype of the device communicates with of the shelf feeder from Trixie Dog Activity Memory trainer.
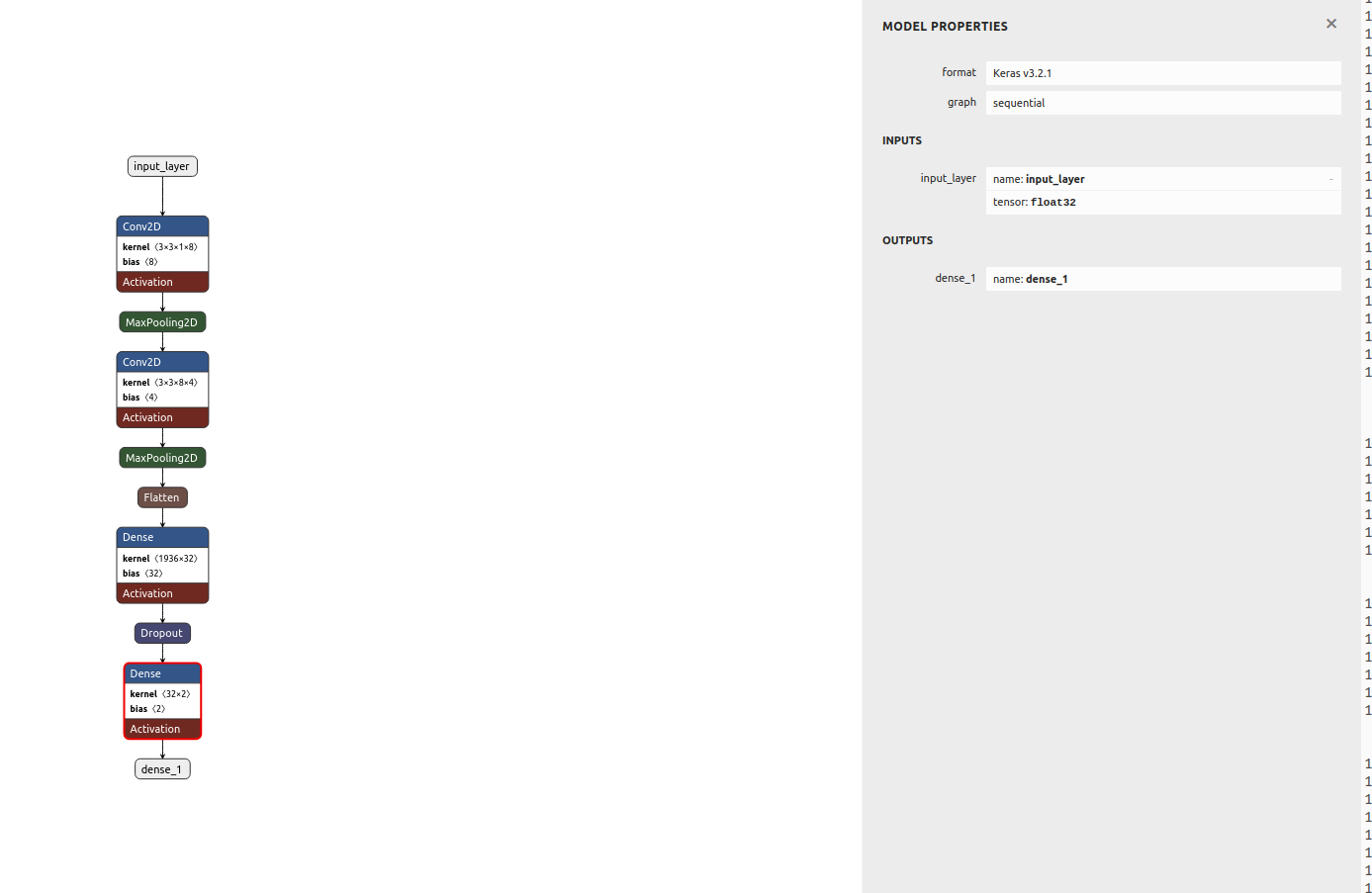
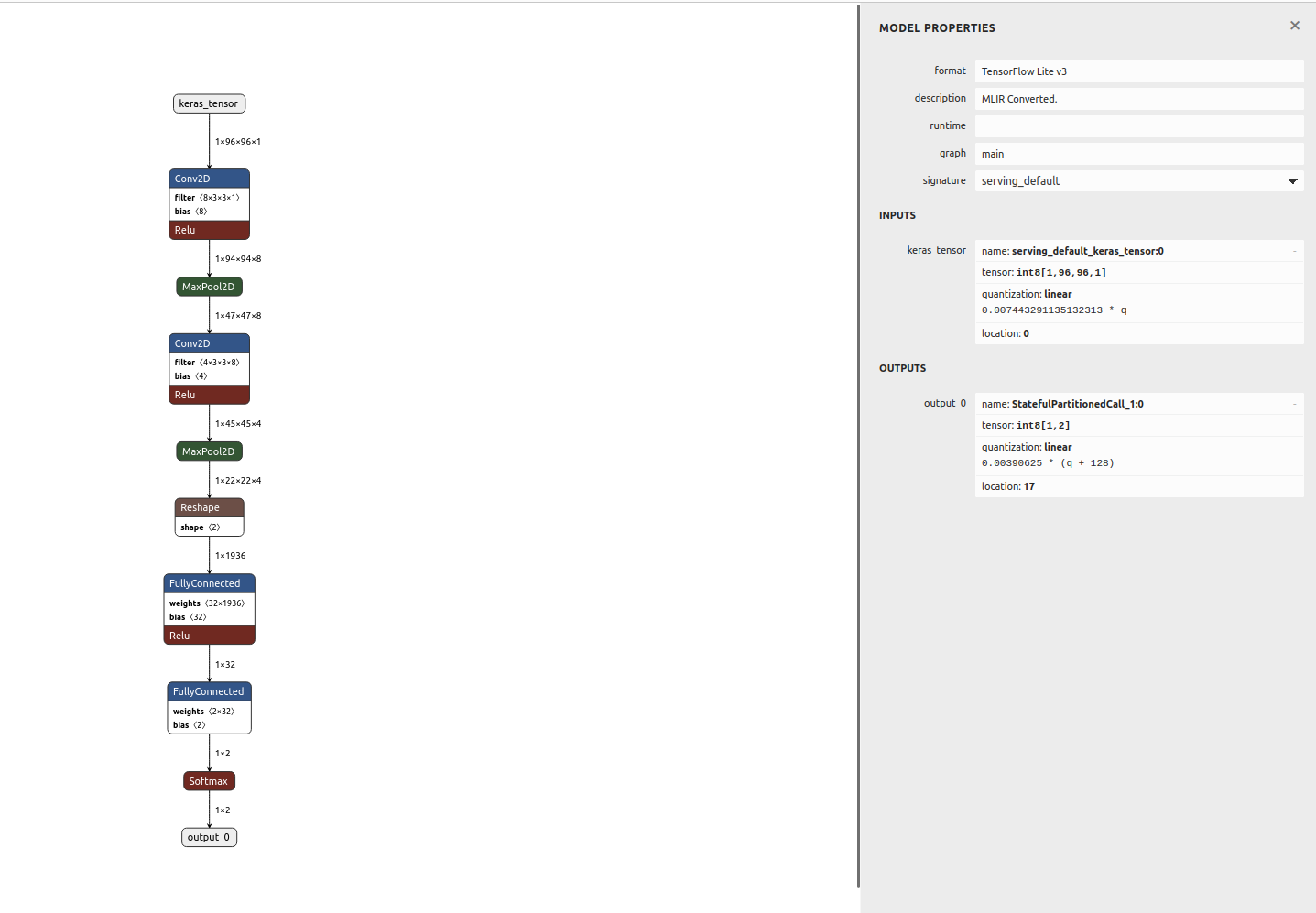
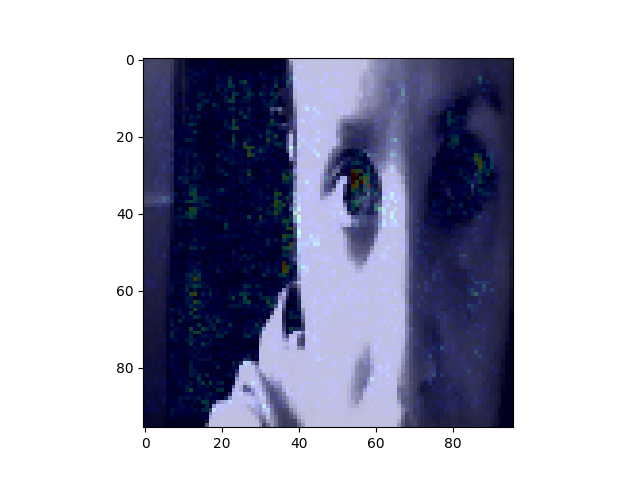
I started with Arduino nano 33 ble sense, as it has a microphone and a camera OV7675. However, the images are not great quality and turned out that my board had a malfunctioning microphone.
I am now working with Seeed Studio XIAO ESP32S3 Sense with camera OV2640. It is a tiny board that I could directly incorporate into the pcb and esp gives a lot of room for more features.
I use also nrf24l01 for communication with the feeder.

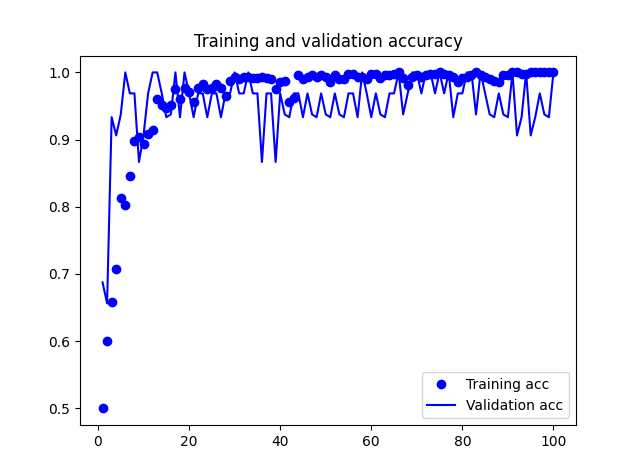
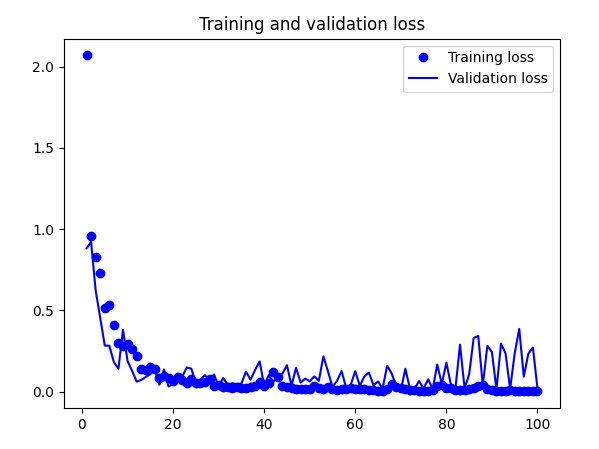
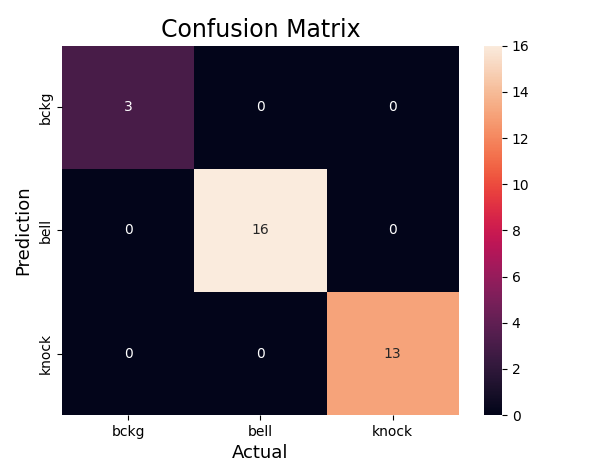


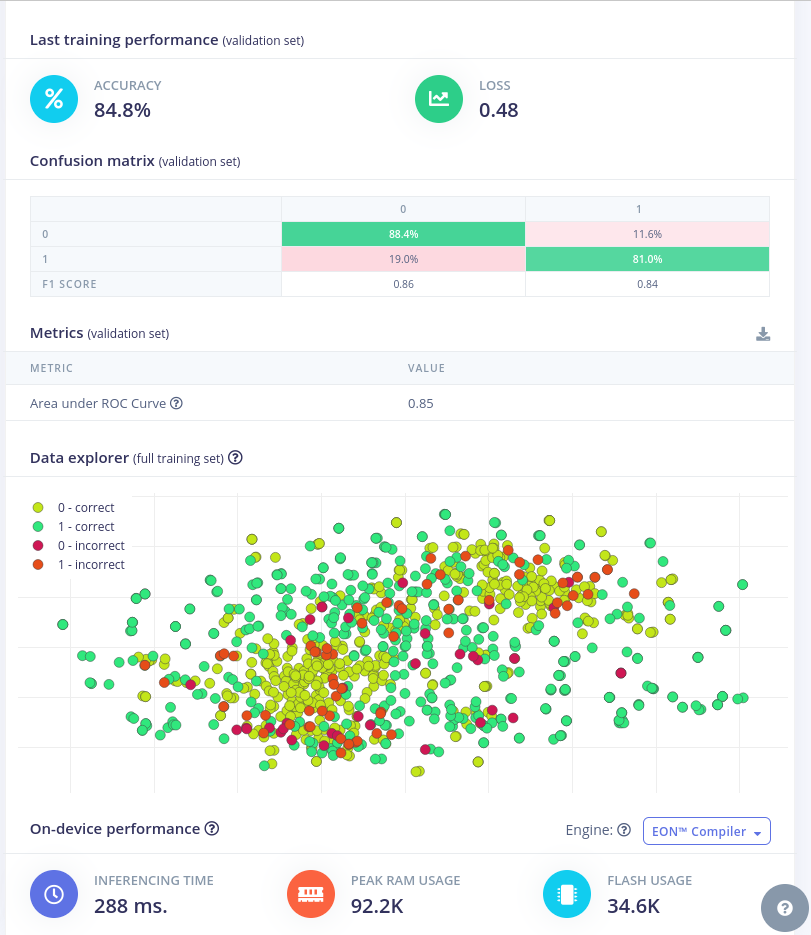







 Sumit
Sumit
 alex.miller
alex.miller
 Nick Bild
Nick Bild
 Tim
Tim