 Yann Guidon / YGDES
Yann Guidon / YGDESI didn't mean to reinvent the wheel but the recent experience with the tape-outs has taught me to reduce DFFs as much as possible. So as I return to the previous 2-cycle modular addition, which I thought was already reasonably efficient, and found that this circuit leads to mutual race conditions (which would explain the messy development several months ago), I understand that I must find a better approach.
The last log 139. Re-birth (2) : the modulo. hints that there have been studies and Google led me to
Hiasat, Ahmad. (2002). High-speed and reduced-area modular adder structures for RNS. Computers, IEEE Transactions on. 51. 84-89. 10.1109/12.980018.
It starts there https://www.researchgate.net/figure/The-modular-adder-proposed-by-Bayoumi-and-Jullien-18_fig1_3044437 with a simple diagram from a different paper:
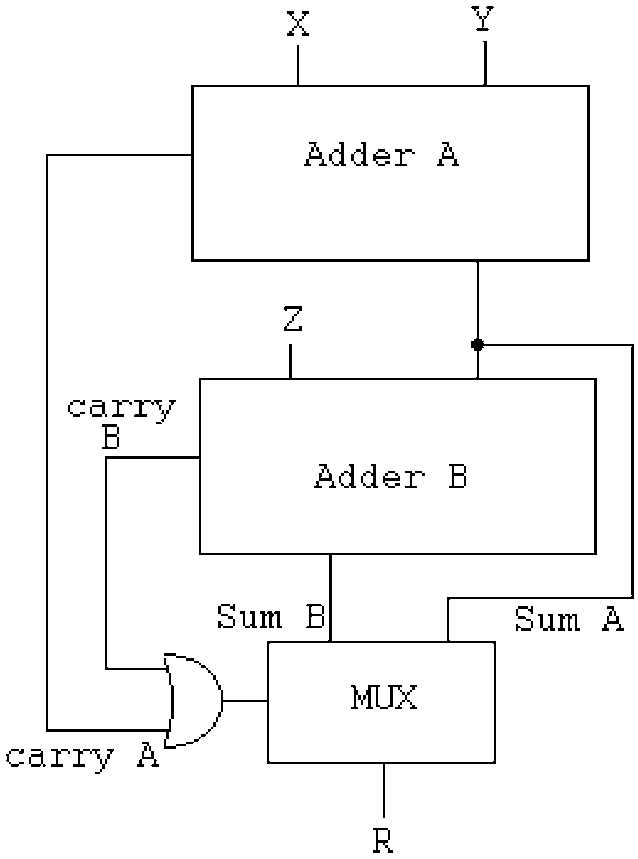
This inverts the order of the adders that I intended before but fair enough. There are 3 critical datapaths back-to-back:
- Adder A
- Adder B (though some overlap is possible since they both start from the LSB)
- the fanout for the MUX
-------------------------------------------------------------------------------------------
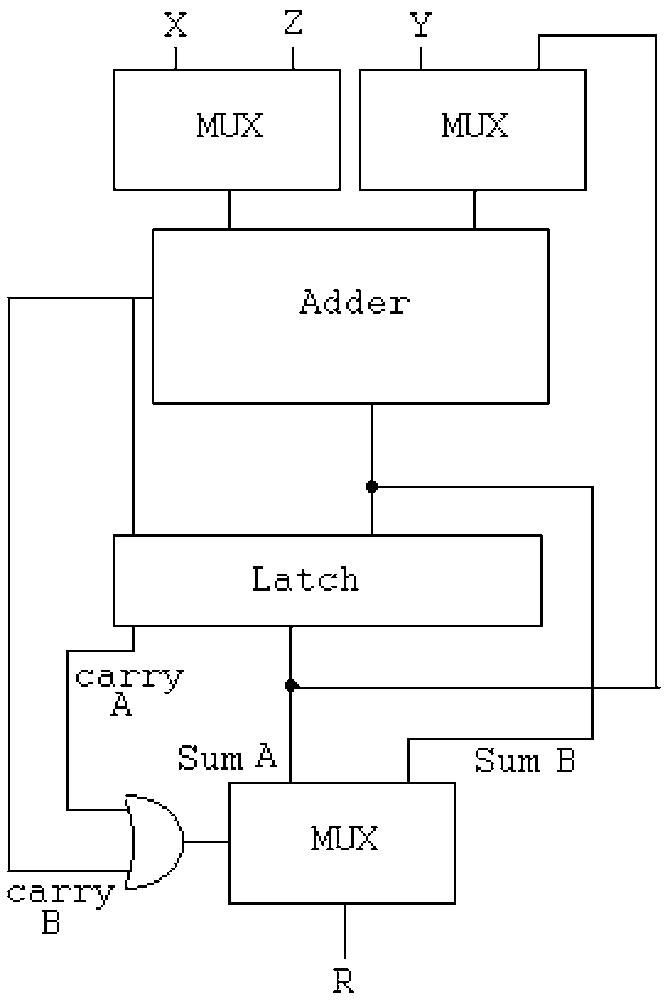
Fun fact: figure 2 of the paper describes a 2-cycle version ("Dugdale" topology), similar to the method I developed previously. The use of a latch (and not DFF) at this position is pretty smart but the size increase is still significant, adding 3 MUX.
The Dugdale topology trades a constant adder for 3 MUX, 1 latch and 1 added cycles, which is not favourable when adders are relatively cheaper.
-------------------------------------------------------------------------------------------
More studies:
Pipelined Two-Operand Modular Adders
(Maciej CZYŻAK, Jacek HORISZNY, Robert SMYK) 2015 (13 years after Hiasat & Ahmad)
-------------------------------------------------------------------------------------------
The papers propose various enhancements, so the B&J circuit above, even though not optimal:
- is a good starting point
- would be somewhat optimised in our back by the synth tools
- has less overall latency than a 2-cycle version (since the 2 carry chains can be close to each other and the LSB of Adder B can be evaluated soonder)
- does not require over-registering like the 2-cycle version
- promises ways to optimise later, when there is more time.
The strategy now is to "isolate" the mod adder, such that it can be reworked after the first crude version proved it works. The adder is a bit larger than before but, considering the other factors, it's the fastest and most compact reasonable way to implement it in an ASIC, where the adder seems to be less of a concern than in an FPGA.
And this leaves some potential optimisations on the table, for later.
.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.