 Yann Guidon / YGDES
Yann Guidon / YGDESThe last log shows that the "flipper" (popcount+XOR) idea works but we see that the max run length of 0s is equal to the width of the flipped word +3.
By splitting the 16-bit word, two flipping areas reduce the worst case to 8+3=11 bits.
And it is smaller hence faster !
But two flip bits forces to abandon the parity bit, which
- increase error detection,
- restore the neutral state at the end of the word.
I have decided to move the level restoration (as well as droop management) to a dedicated packet that can tweak the line level average.
For error detection, I move the parity bit to a different place, repurposing one of the mark bits : it gets XORed by the parity of the data word, and thus helps with immediate detection of the error.
Furthermore, each flipping unit adds one bit, which is extra coding space and serves as a byte-wide pseudo-parity : the decoder runs popcount again, and detects when the incoming data has more than 4 cleared bit, adding to an even finer error detection.
Furthermore a little reorganisation easily reduces the run length to 10 bits max, by grouping the two flip bits together :
m1 m0 byte A Flip A Flip B byte B
This way, there is no valid way to exceed 10 cleared bits in a row, without even having to force values of the other extra bits. This keeps the circuits short/simple/fast.
...
Overall, all the 4 extra bits count toward error detection, in different ways. The 64Ki codes get mapped to a unique 20-bit word, giving a 1/16th chance of missing alterations.
- 1/4th of the whole coding space is dedicated to control/commands, that's 18 bits to play with, or 256Ki codes. These codes do not count toward PEAC scrambling so if a control packet is detected by error, it will also be detected by PEAC as a missing word or desynchronisation, so no chance to miss it.
- The remaining 768Ki codes contain only 64Ki valid codes, that's 1/12th chance of missing an error immediately, or 11/12th code bloat.
- the rest of the PEAC algo catches the rest of the errors and makes them "sticky".
That sounds pretty safe for me.
The "unflipping" of the received word is simple but parallel checks are run to ensure that the received bitcount is valid : no byte with 5, 6, 7 or 8 zeroes. This bitcount also feeds the parity check to flip m0.
This is valid because the flipping does not change the parity of bitcount :
0<->8
1<->7
2<->6
3<->5
4<->4
The extra offset due to the OR does not affect this part.
-----------------------------------------------------------------------------
Behold the result.
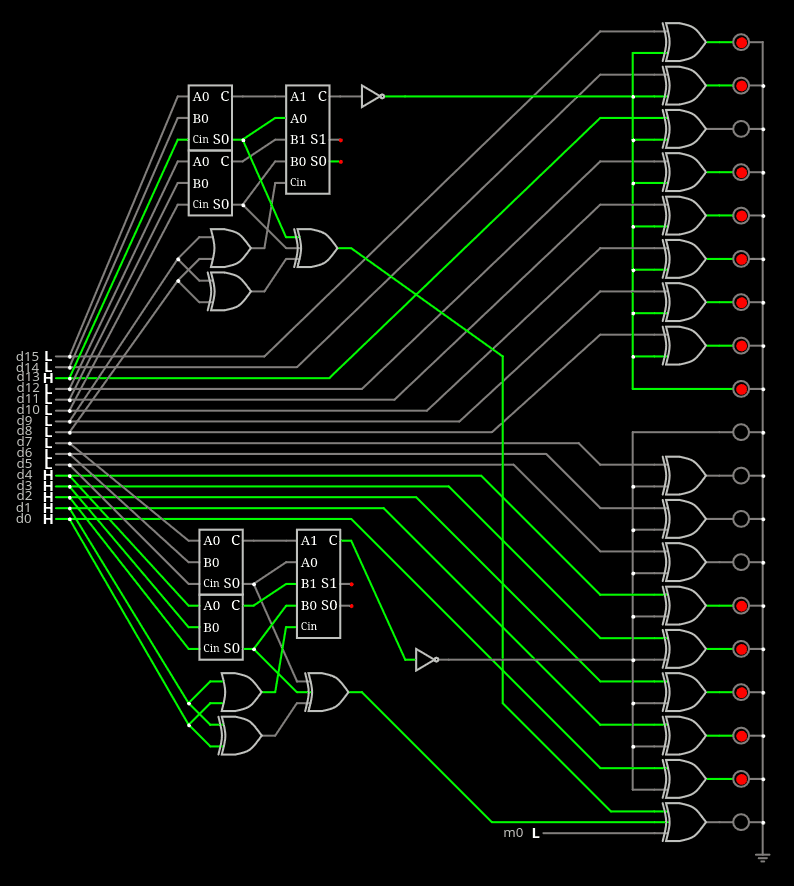
It's leaner and a bit faster. You can play with it on CircuitJS.
I have found a "little flaw" but that's for the next log.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.