Neil K. Sheridan
Neil K. Sheridan-
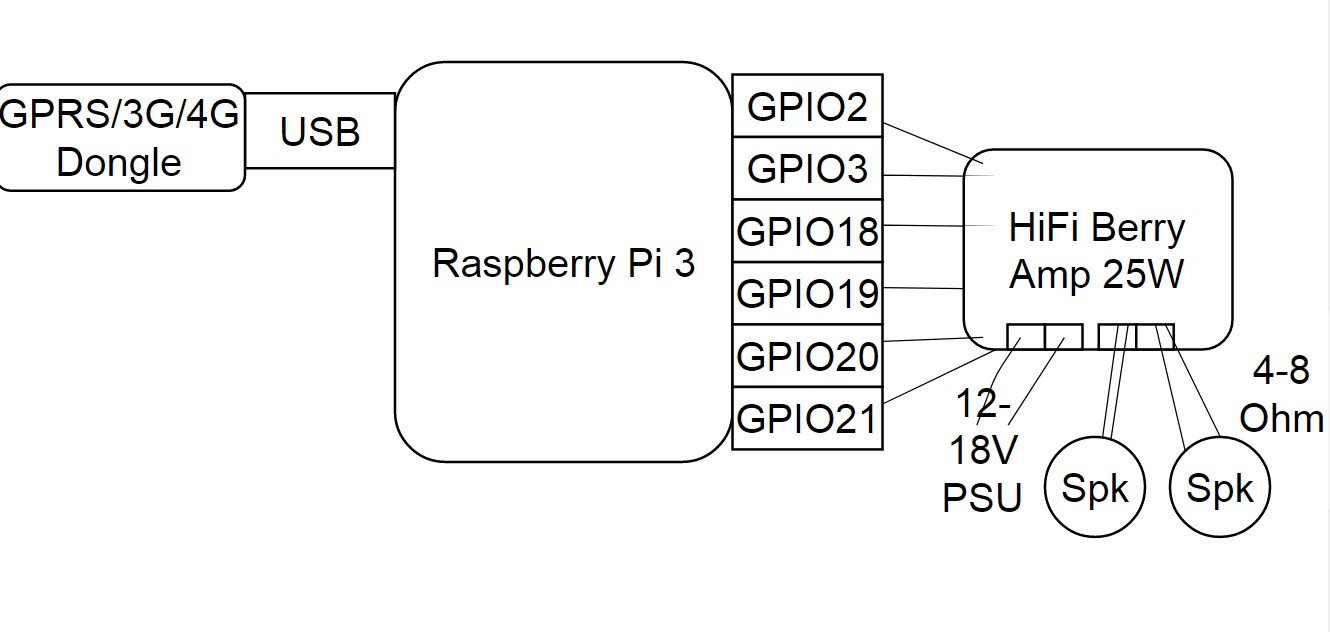
Updates for comms / GSM/3G/4G comms for Raspberry Pi
05/15/2017 at 19:54 • 0 commentsI've been trying the Huawei E3272 and E3276 USB dongles..
Anyway, some other hardware ideas I've come across and will investigate:
PiAnyWhere 4G & LTE Hat for the Raspberry https://www.pianywhere.com/product/pianywhere-4g-raspberry-pi-hat/ £160
PiAnywhere 3G https://www.pianywhere.com/product/pianywhere-3g-raspberry-pi-hat/ £100
PiAnywhere GSM https://www.pianywhere.com/product/pianywhere-gsm-raspberry-pi-hat/ £60
4G + GPS Shield for Raspberry Pi – LE910 - (4G / 3G / GPRS / GSM / GPS / LTE / WCDMA / HSPA+) https://www.cooking-hacks.com/documentation/tutorials/4g-gps-lte-wcdma-hspa-3g-gprs-shield-arduino-raspberry-pi-waspmote-tutorial/ E444 (euros) <- this was is pretty great because of the amount of software they've already written so it's super-easy to use! But very expensive!
Note that I'm only using 4G or 3G for debugging with prototypes, the final elephant detectors don't need to upload their images. They only need GSM to communicate with deterrence devices and local people using SMS.
-
Alternatives to Raspberry-Pi cameras
05/11/2017 at 19:01 • 0 commentsI was thinking today about changing to use GoPro cameras instead. You can connect these to the raspberry pi using an HDMI-CSI bridge (e.g. https://auvidea.com/b100-hdmi-to-csi-2-bridge/)
There's a video here about using GoPro Hero for computer vision with the raspberry pi:
And you can also remove the IR-filtered lens from the GoPro Hero 3 or 4 and replace it with a non-IR filtered for night-vision. As shown in this video:
The GoPro Hero 3 is around £130, whilst the Hero 4 is around £400. So this approach makes for more expense, but it's worth testing!
-
elephant-deterrence devices
05/11/2017 at 18:34 • 0 commentsThe elephant detection devices will notify these to begin their deterrence scripts either via bluetooth or via GPRS/3G/4G modems. The scripts will contain instructions for playing audio from pseudo-randomly selected bee or tiger .ogg files stored on the memory cards.
![]()
Thoughts on using more active approaches
I did mention earlier the idea of firing chilli balls to deter elephants. There is some research on this published:
Repelling elephants with a chilli pepper gas dispenser: field tests and practical use in Mozambique, Zambia and Zimbabwe from 2009 to 2013 (Le Bel et al., 2015)
Here they fired ping pong ball projectiles containing chilli pepper using a pneumatic weapon. The idea has been tried by others too!
![]()
So if I used this approach, I would mount a pneumatic weapon on a rotating platform. I'd add camera and take real-time video once we had elephants present (per notification from elephant detection devices). I'd track their motion using camera, then adjust position of rotating platform and thus weapon. And then go ahead and fire the chilli balls at the presumed location of elephants!
Drawbacks are that chilli balls are quite large so you would need a large barrel size for the pneumatic weapon. That means it would need a large reservoir of compressed air + a compressor! Not to mention I am unsure how it could be automatically reloaded?
-
Elephant Behaviours
05/10/2017 at 19:20 • 1 commentOne of the important of aspects of this is project is that we're not just saying "hey there is an elephant" but we are detecting which class of elephants are present! Thus, we can infer from our imagery which type of behaviour is likely to be exhibited.
1. Bull Elephants during Musth
These are the most dangerous and aggressive elephants to encounter! Serum testosterone rises from a pre-musth median of 35.16ng/mL to a musth median of 63.88ng/mL in Asian bull elephants experiencing musth. This, and other physiological changes, impact their behaviour "behavior by males in musth is often abnormal, and can be bizarre and/or extremely aggressive" (Rasmussen et al, 1999). In addition, during musth, temporal gland secretions were found to contain increased acetone and other ketones. It is speculated that temporal gland swellings during musth may cause the elephants severe pain. Musth lasts for ~16 weeks in Asian elephants (Rajaram, 2006).
These temporal gland secretions result in a thick tar-like deposit on the side of the elephants head which will can attempt to identify from imagery! Thus providing a warning that extremely dangerous elephants are nearby!
![]() [Image: By Yathin S Krishnappa - Own work, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=21406707 ]
[Image: By Yathin S Krishnappa - Own work, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=21406707 ]A bull elephant (African) is thought to come into musth for the first time in his late teens to early twenties. The elephants continue to undergo this period until their early 60s. However, some studies have concluded that older males will to some degree attenuate the aggressive behaviour exhibited by younger males during musth (Slotow et al., 2000).
Additionally, bull elephants will exhibit a distinct vocalisation during their musth period. This is called the musth rumble and sounds like "pulsated "put-put-put" or "glug-glug-glug" quality, like water gurgling through a deep tunnel" (Elephant Voices). You can listen to them here at Elephant Voices.
So we have a visual and auditory method of detecting elephants in the dangerous musth period!
2. Female elephants with calves
3. Tuskers
Since both sexes of African elephant have tusks there doesn't seem much point in looking for these! However, in Asian elephants we can look for tusks as only males have these, with females sometimes having very small tushes. So we can use tusk yes/no to determine sex in Asian elephants.
4. Lone elephants
5. Herds of bulls
6. Herds of females
7. Mixed herds
-
Image classification with TensorFlow using Inception trained on ImageNet 2012 dataset
05/03/2017 at 18:45 • 1 commentToday, I thought I'd try using TensorFlow with the Inception model already pre-trained using the ImageNet 2012 competition dataset! Just to see what kind of results I got for some of my elephants!
I just used the classify_image.py code (licensed under http://www.apache.org/licenses/LICENSE-2.0) and the Inception v3 model. You can find the code here.
So here we go:
Indian Elephant 96.653![]()
Tusker = 0.014
African Elephant = 0.002
African Elephant 0.453![]()
Indian Elephant 0.325
Tusker 0.152
![]()
Indian Elephant 0.689
Tusker 0.160
African Elephant 0.125
-
#5 result for object detector using Histogram of Oriented Gradients (HOG) and Linear Support Vector Machines (SVM)
05/01/2017 at 20:02 • 0 commentsSo this is my largest-scale training run for the classical machine-vision object detector using HOG + SVMs.
Method
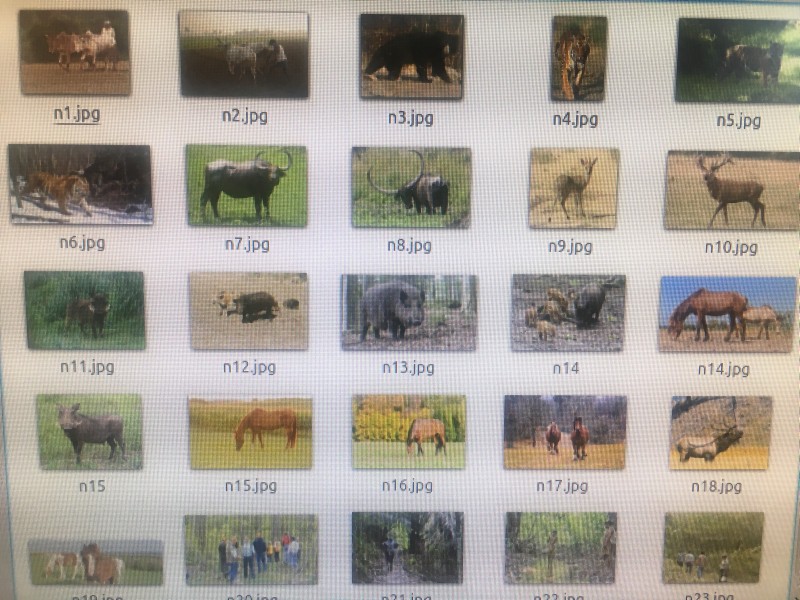
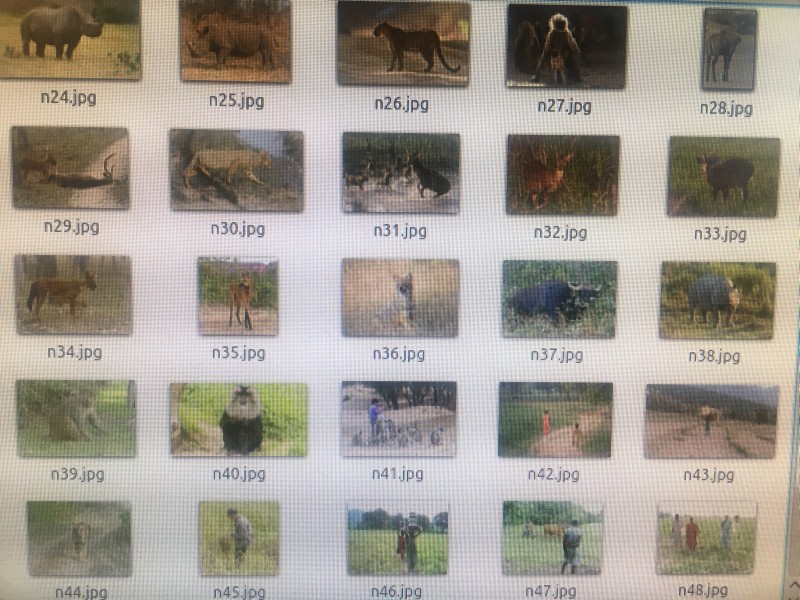
I used 3500 non-elephant images for the negative training set. This consisted entirely of animals (e.g. rhinos 45, sloth bears 95, Indian cow breeds 41, tigers 210, water buffalo 210, ducks, people, etc.). I used 330 elephant images for the positive training set. I removed the elephant bums! The images were all cropped to 256 width * height with aspect ratio preserved. This may have caused problems which I will examine later. I did hard-negative mining with 50 images.
Results
I've used n=50 for the false-positive testing image set. It's the same set as I used in test #4 with a selection of animals which I thought likely to be present in same environment as elephants. The false-positive result was 16%. That's much better than my previous 26%!!
I've only done n=10 for the false-negative testing image set so far. But I'm at 0% so far! Really great, especially considering I think the sliding window size was a bit off. And the hard-negative mining was lower than I'd planned.
* update:
Unfortunately it hasn't been as successful as I hoped! Once I increased increased my number of elephant images for the false-negative testing I got an awful lot of false-negatives!! It looks like this might be because the positive images have been resized badly and the sliding window size was changed to an inappropriate size!
![]()
![]() [Images: false-positive testing set with the false-positives marked with red crosses]
[Images: false-positive testing set with the false-positives marked with red crosses] -
Retraining TensorFlow Inception v3 using TensorFlow-Slim (Part 2)
04/29/2017 at 19:06 • 1 commentIn this experiment I will not be using flowers, but elephants! I'm going to use 5 classes of elephants: baby elephants, elephant groups no babies, elephant groups with babies, lone female elephants, lone male elephants. I'll just start with 100 images for each class. So that's 500 images in the dataset. I'll take 80% for training and 20% for validation.
Protocol for experiment:
1. Convert dataset to TensorFlow's native TFRecord format. Here each TFRecord contains a TF-Example protocol buffer. First we need to place the images in the following directory structure "data_dir/label_0/image0.jpeg", "data_dir/label_1/image0.jpeg" etc. Then we can convert using a modified version of build_image_data.py (original is written by Google and licensed under http://www.apache.org/licenses/LICENSE-2.0). This is the original code on github.
2. So we should have several TFRecord files created now!
3. Next to define a Slim Dataset. This stores pointers to the data file, as well as various other pieces of metadata: class labels, the train/test split, and how to parse the TFExample protos. TF-Slim dataset descriptor using the TF-Slim DatasetDataProvider code :
import tensorflow as tf from datasets import elephants slim = tf.contrib.slim # Selects the 'validation' dataset. dataset = elephants.get_split('validation', DATA_DIR) # Creates a TF-Slim DataProvider which reads the dataset in the background # during both training and testing. provider = slim.dataset_data_provider.DatasetDataProvider(dataset) [image, label] = provider.get(['image', 'label'])4. Downloading the Inception v3 checkpoint. Modify later for Inception v4 instead! (see https://github.com/tensorflow/models/tree/master/slim)
$ CHECKPOINT_DIR=/tmp/checkpoints $ mkdir ${CHECKPOINT_DIR} $ wget http://download.tensorflow.org/models/inception_v3_2016_08_28.tar.gz $ tar -xvf inception_v3_2016_08_28.tar.gz $ mv inception_v3.ckpt ${CHECKPOINT_DIR} $ rm inception_v3_2016_08_28.tar.gz5. Now we can retrain from the checkpoint we downloaded using train_image_classifier.py . See https://github.com/tensorflow/models/blob/master/slim/train_image_classifier.py for code.$ DATASET_DIR=/tmp/elephants $ TRAIN_DIR=/tmp/elephants-models/inception_v3 $ CHECKPOINT_PATH=/tmp/my_checkpoints/inception_v3.ckpt $ python train_image_classifier.py \ --train_dir=${TRAIN_DIR} \ --dataset_dir=${DATASET_DIR} \ --dataset_name=elephants \ --dataset_split_name=train \ --model_name=inception_v3 \ --checkpoint_path=${CHECKPOINT_PATH} \ --checkpoint_exclude_scopes=InceptionV3/Logits,InceptionV3/AuxLogits \ --trainable_scopes=InceptionV3/Logits,InceptionV3/AuxLogits6. Next is to evaluate performance using the the eval_image_classifier.py. See https://github.com/tensorflow/models/blob/master/slim/eval_image_classifier.py for code.
CHECKPOINT_FILE = ${CHECKPOINT_DIR}/inception_v3.ckpt # Example $ python eval_image_classifier.py \ --alsologtostderr \ --checkpoint_path=${CHECKPOINT_FILE} \ --dataset_dir=${DATASET_DIR} \ --dataset_name=imagenet \ --dataset_split_name=validation \ --model_name=inception_v37. Next to feed in a single image! See https://www.tensorflow.org/versions/master/tutorials/image_recognition but I haven't got that far yet!
-
Testing the object detector using HOG + SVMs (video)
04/28/2017 at 19:12 • 0 commentsAs you can see it takes around 1 minute to detect the elephant in this image. This using an i5.
-
Summary of python code for Object Detector using Histogram of Oriented Gradients (HOG) and Linear Support Vector Machines (SVM)
04/28/2017 at 18:29 • 0 commentsDependencies:
from __future__ import print_function from sklearn.feature_extraction.image import extract_patches_2d from imutils import paths from scipy import io import numpy as np import random import cv2 import cPickle from sklearn.svm import SVC1. Extracting features
#init HOG detector hog = HOG(orientations=conf["orientations"], pixelsPerCell=tuple(conf["pixels_per_cell"]), cellsPerBlock=tuple(conf["cells_per_block"]), normalize=conf["normalize"]) data = [] labels = [] # TRAINING IMAGES # collect the paths to the training (positive elephant) images pos_paths = list(paths.list_images(conf["positive_images"])) print("1/3: Processing training images") for (i, pos_path) in enumerate(pos_paths): # load training image image = cv2.imread(pos_path) # convert to grayscale train_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # resize train_image = cv2.resize(train_image, (122, 96), interpolation=cv2.INTER_AREA) # put the train_image into a list called train_image_list train_image_list = (train_image, cv2.flip(train_image, 1)) if conf["use_flip"] else (train_image,) # loop for train_image in train_image_list for train_image in train_image_list: # extract features from train_image and add to list of features features = hog.describe(train_image) data.append(features) labels.append(1) #NEGATIVE IMAGES neg_paths = list(paths.list_images(conf["negative_images"])) print("2/3: Processing negative images") or i in np.arange(0, conf["num_negative_images"]): # randomly select a negative image # extract patches image = cv2.imread(random.choice(neg_paths)) if image is not None: image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) #note here 3737: error: (-215) scn == 3 || scn ==4 in function cvtColor if u pass #a bad input image patches = extract_patches_2d(image, tuple(conf["window_dim"]), max_patches=conf["num_distractions_per_image"]) for patch in patches: # extract features from patch features = hog.describe(patch) # update list data.append(features) labels.append(-1) #SAVING DATA FILE print("3/3 Saving file") dataset.dump_dataset(data, labels, conf["features_path"], "features")2. Training classifier
print("1/2: training classifier...") model = SVC(kernel="linear", C=conf["C"], probability=True, random_state=22) model.fit(data, labels) # save classifier to cpickle file print("2/2: saving classifier to cpickle file") f = open(conf["classifier_path"], "w") f.write(cPickle.dumps(model)) f.closeSee http://scikit-learn.org/stable/tutorial/basic/tutorial.html for information on using scikitlearn
-
#4 result for object detector using Histogram of Oriented Gradients (HOG) and Linear Support Vector Machines (SVM)
04/15/2017 at 20:18 • 0 commentsHi, this is the result so far from my larger-scale training run (see here). Unfortunately, it wasn't quite as large-scale as I hoped due to problems with the color-spaces and sizes of images from the caltech-256 dataset.
The training run entailed the usage of:
- 0.5*350 (positive) elephant images that I'd obtained and cropped manually
- 2000 (negative) non-elephant images from caltech dataset. These are mostly of animals
- Hard-negative mining on 50 negative images
For the elephant images I included front-view, side-view at various angles, rear view (elephant bum), and close-up of elephant faces (range <1m).
Workflow using m4.4xlarge EC2 instance:
- Extract features (time = 15 minutes)
- Train model (time = 120 minutes)
- Hard-negative mining (time = 120 minutes)
- Train model adding hard-negatives (time = 120 minutes)
- Download model (time = 60 minutes)
Approx cost using m4.4xlarge EC instance: $7
Results
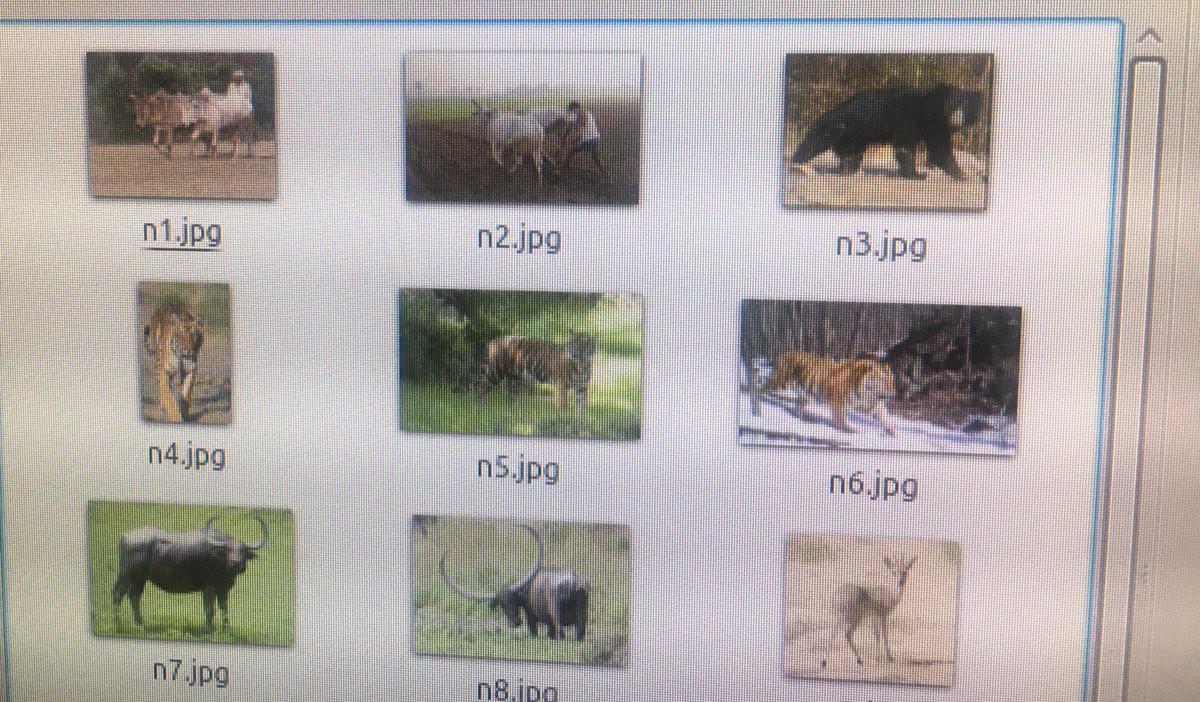
So far I've only had time to test the object detector on testing sets of 10 elephant images and 10 non-elephant animal images (animals likely to be present in area: sloth bears, wild pigs, cows, water buffalo, tigers, deer, humans). I was quite pleased with the results really tho! I got 0% false-negatives (i.e. failures to detect elephants when elephants present), and 20% false-positives (i.e. detect elephants when elephants not present).
Update!
So on a testing set of 50 non-elephants I got a 26% false-positive!
![]()
[Image: Examples of animals in the testing set]![]()
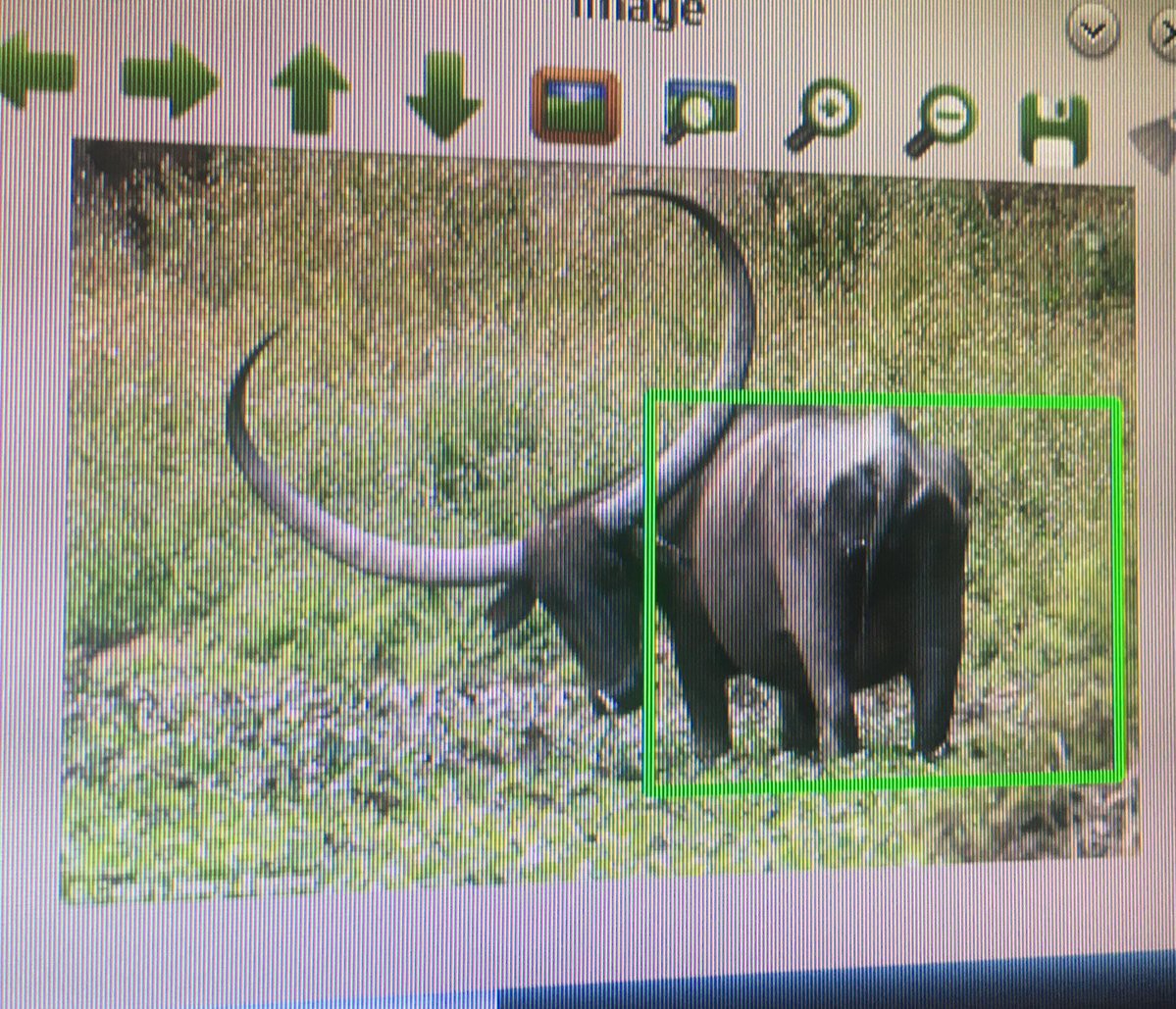
Interestingly, the false-positives occurred with animals having bums which looked like elephant bums! The water buffalo, which really did look like an elephant bum even to me! And the cow, which looked a bit like one. However, the color was wrong. But this object detector is using grayscale not BGR.
![]()
[Image: false-positive with a water buffalo]
![]()
![]()
[Images: full range of images using for testing set]
Next steps:
- Removal of elephant bums (rear-view) from the training set of positive images. Since elephants are going to trigger PIR when they approach rather than walk away!
- Removal of close-up elephant faces (<1m range). Since we should have detected them way before they get this close to the camera! If they are this close they are probably going to do something nasty to the camera!!
- Fix the problems with the negative images that caused issues. I'll have to look through these manually and see what exactly the problems are! Very tedious I expect!
- So increase negative images up to 4000, and use the full 350 positive images
Elephant AI
a system to prevent human-elephant conflict by detecting elephants using machine vision, and warning humans and/or repelling elephants





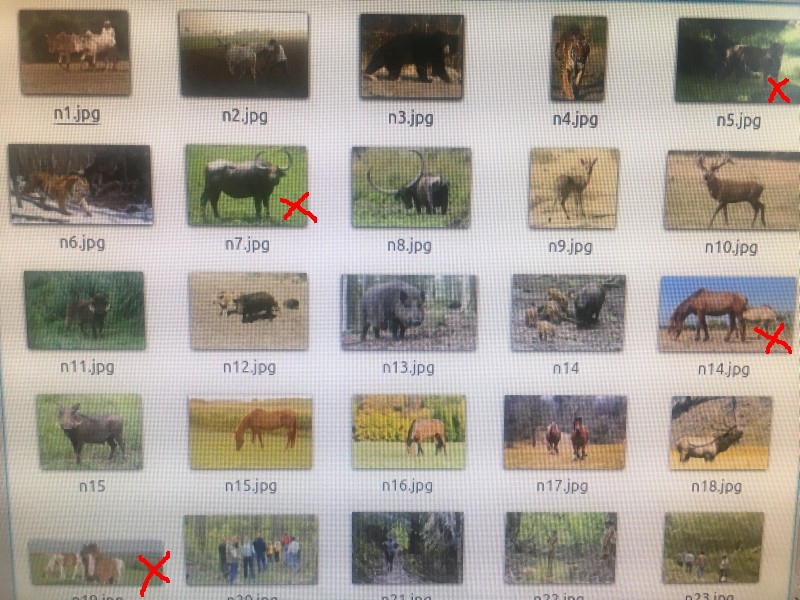
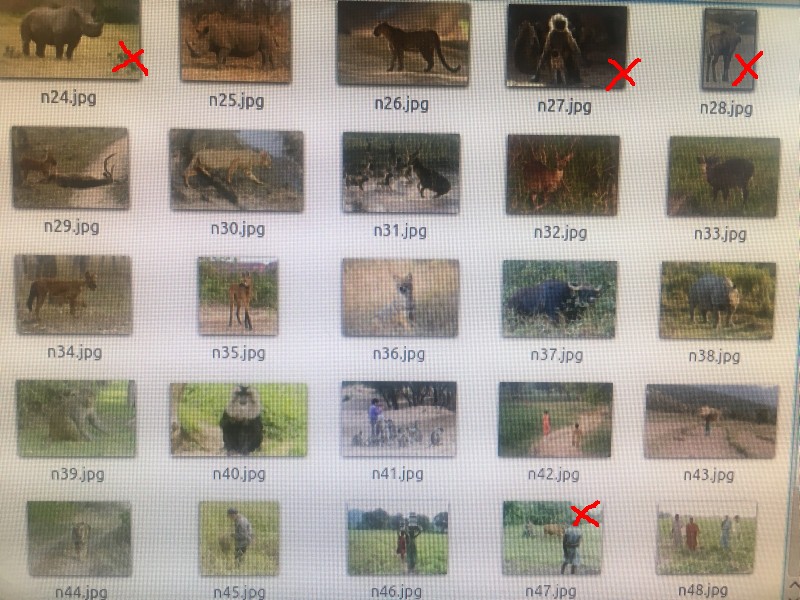 [Images: false-positive testing set with the false-positives marked with red crosses]
[Images: false-positive testing set with the false-positives marked with red crosses]