0%
0%
MC68881 VHDL
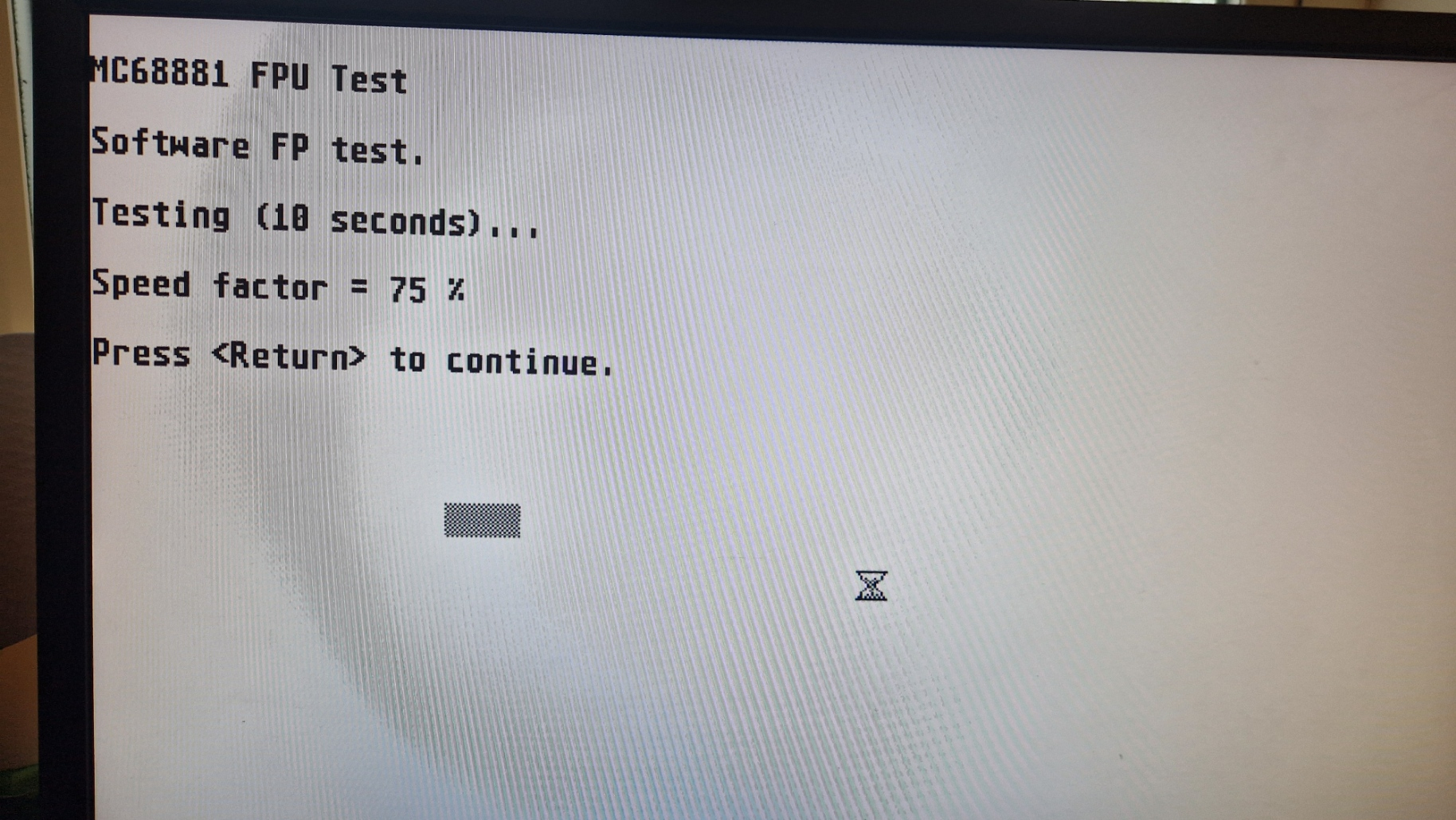
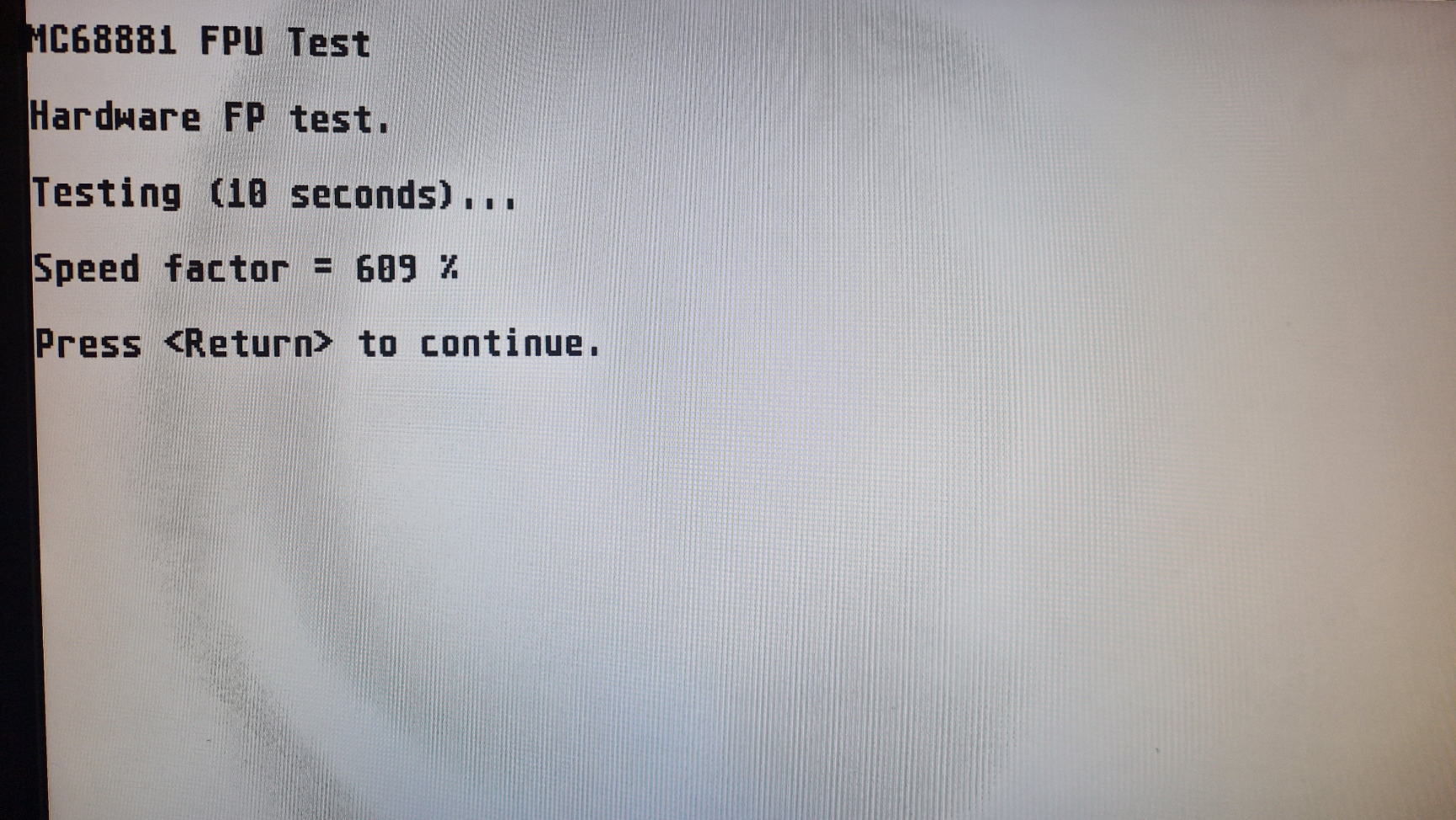
This project is an open source implementation of the Motorola MC68881 floating-point unit written in VHDL
 Matthew Pearce
Matthew PearceBecome a Hackaday.io member
Already have an account? Log in.
Just one more thing
To make the experience fit your profile, pick a username and tell us what interests you.
Pick an awesome username
hackaday.io/
Your profile's URL: hackaday.io/username. Max 25 alphanumeric characters.
Pick a few interests
Projects that share your interests
People that share your interests


 Arnov Sharma
Arnov Sharma
 David Prutchi
David Prutchi
 Carl Strathearn
Carl Strathearn