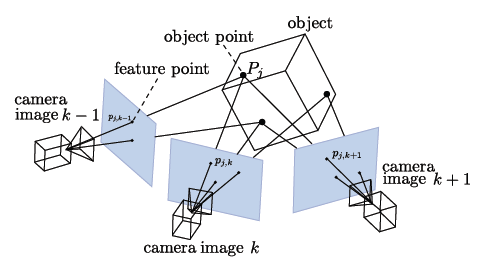
This project covers the practical use of photogrammetry and won't explain the algorithms in the background. Where needed some information will be given.
0%
0%
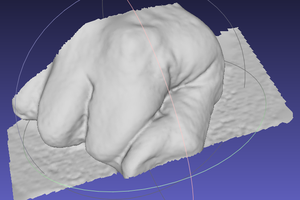
Photogrammetry 3D Scanning
This project is a brief tutorial from acquiring multiple images to a finished 3D print of a real world object.
Become a Hackaday.io member
Already have an account? Log in.
Just one more thing
To make the experience fit your profile, pick a username and tell us what interests you.
Pick an awesome username
hackaday.io/
Your profile's URL: hackaday.io/username. Max 25 alphanumeric characters.
Pick a few interests
Projects that share your interests
People that share your interests







 marcs
marcs
 Joan Horvath
Joan Horvath
Hi, Do you know how I might make a cheap lider type scanner to scan the ground maybe plugging a laser device into my phone? I am not looking for high res, just something i can tie in with gps on my phone to scan say terrain and objects at a basic level. If i can do this i might go for a next stage of object recognition.