 ReVision
ReVision-
Manual transliteration
04/09/2019 at 16:26 • 0 commentsThought I would try some manual transliteration while waiting on some components, I'll try syncing this with audio/video later, based on my Welsh/British accent.
All the world's a stage,
And all the men and women merely players;AO L SIL TH ER SIL W ER L D S SIL AE SIL S T EY JH SIL
AE N D SIL AO L SIL TH ER SIL M EH N SIL AE N D SIL W IH M EH N SIL M IY AE L IY SIL P L EY Y ER S SIL
04 15 00 1F 0C 00 24 0C 15 09 1D 00 02 00 1D 1F 0D 13 00
02 17 09 00 04 15 00 1F 0C 00 16 0B 17 00 02 17 09 00 24 11 16 0B 17 00 16 12 02 15 12 00 1B 15 0D 25 0C 1D 00
-
Phenome generation software
04/07/2019 at 09:35 • 0 commentsI plan on learning/using an open source phoneme recognition package called cmusphinx/pocketsphinx.
https://cmusphinx.github.io/wiki/phonemerecognition/
Also there are 39 phonemes (plus a silence) so my design will increase the outputs from 32 to 39.
I have also noticed that these are always sequential so can be represented in 6 bits rather than the previous 32. For practical reasons each character should be represented as 8bit, or 2 hex characters.
Examples of the decoding taken from the cmusphinx is laid out below, with hex values added.
HEX CMUBET IPA Example Translation -- ------ --- ------- ----------- 00 SIL . silence ...word-end [ SIL ] word-start... 01 AA ɑ odd AA D 02 AE æ at AE T 03 AH ʌ hut HH AH T 04 AO ɔ ought AO T 05 AW ɑʊ cow K AW 06 AY ɑɪ hide HH AY D 07 B b be B IY 08 CH ʧ cheese CH IY Z 09 D d dee D IY 0A DH ð thee DH IY 0B EH ɛ Ed EH D 0C ER ɜɹ hurt HH ER T 0D EY eɪ ate EY T 0E F f fee F IY 0F G ɡ green G R IY N 10 HH h he HH IY 11 IH i it IH T 12 IY ɪː eat IY T 13 JH ʤ gee JH IY 14 K k key K IY 15 L l lee L IY 16 M m me M IY 17 N n knee N IY 18 NG ŋ ping P IH NG 19 OW oʊ oat OW T 1A OY ɔɪ toy T OY 1B P p pee P IY 1C R ɹ read R IY D 1D S s sea S IY 1E SH ʃ she SH IY 1F T t tea T IY 20 TH θ theta TH EY T AH 21 UH ʊ hood HH UH D 22 UW u two T UW 23 V v vee V IY 24 W w we W IY 25 Y j yield Y IY L D 26 Z z zee Z IY 27 ZH ʒ seizure S IY ZH ER
-
Transliteration protocol ideas
04/05/2019 at 18:56 • 0 commentsMy concept is to break language in to 4 groups of 8 phonemes. Additional sounds would be created by combining these like you would colours, for example the word 'of' would begin with the 'o' sound, and 'us' would begin with the 'u' sound, but the vowels in the word 'boot' would trigger both the 'o' and 'u''.
My example of how the channels are broken down.
1 2 3 4 5 6 7 8 Soft consonants
QuietC/S(+ch/sh) F/Ph/Gh/J H Th W Y * * Soft consonants
LoudL M N R V X Z * Hard consonants B C/K/Q D G J P T * Vowels A E I O U * * * *denotes spare channels, which would probably be assigned later, or used as a modifier like an accent.
The output box would be fed via a serial stream at a suitable speed that could be determined by experiment, but as fast speech is 10 syllables per second, then a sample rate of 50 phonemes per second should be the bare minimum.
If the signal running as 1 bit per phoneme then each sample would be 32bit uncompressed, with each phoneme type being represented by 2 hexadecimal digits
in this instance the word 'wigwam' would be
00001000 00000000 00000000 00000000 #08000000 W
00000000 00000000 00000000 00100000 #00000020 "I"
00000000 00000000 00010000 0000000 #00002000 "G"
00001000 00000000 00000000 00000000 #08000000 W
00000000 00000000 00000000 10000000 #00000080 "A"
00000000 01000000 00000000 00000000 #00400000 "M"
As a scripted file, in the manner of standard subtitle files each line starts as follows...
hh:mm:ss.mms
hh is hours
mm is minutes
ss is seconds
mms is millisecondsso the above script would be...
00:00:00.00 #08000000
00:00:00.10 #00000020
00:00:00.20 #00002000
00:00:00.30 #08000000
00:00:00.40 #00000080
00:00:00.50 #00400000
00:00:00.55 #00000000the last part being return to silence.
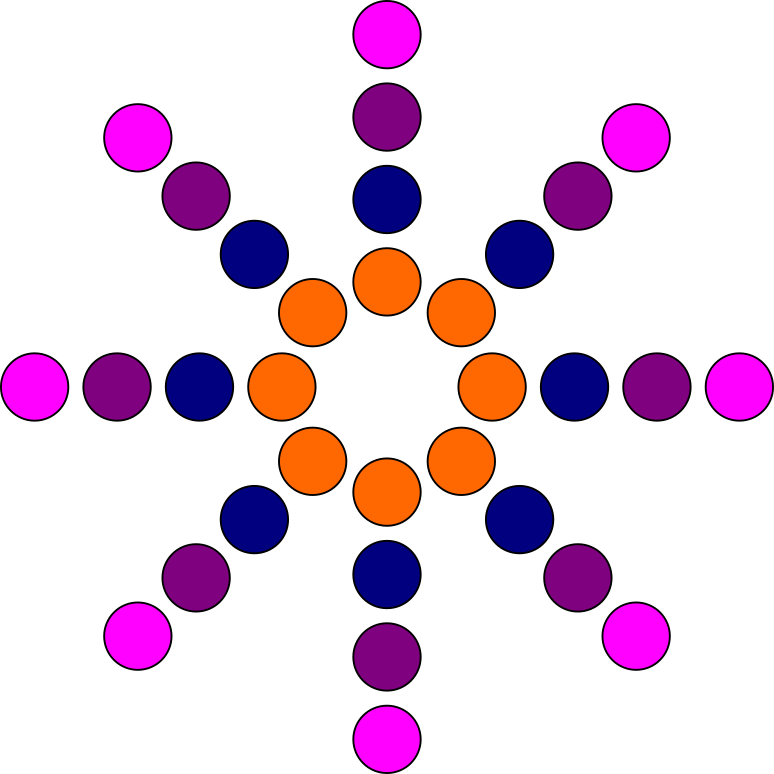
Possible pattern of contact points.
![]()
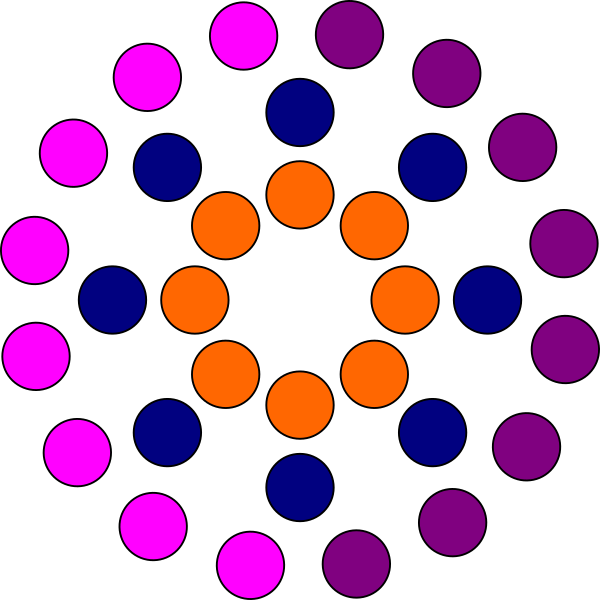
Improved pattern of contact points.
![]()
Any thought would be appreciated.
Tactile Ear
The translation of phonemic sounds of speech in to tactile feedback.