Yann Guidon / YGDES
Yann Guidon / YGDES-
Chasing a "unexpected feature" in GHDL
11/09/2020 at 00:31 • 0 commentsI know, I know, I should update my SW but if a 2017 build of GHDL misbehaves in significant ways, I wonder why it had waited so long to be apparent.
So I'm adding a new "loading" test to the self-check suite, because I want to know how many gates I can reasonably handle, and I get weird results. It seems that GHDL's memory allocation is exponential and this should not be so. So I sent a message to Tristan, who sounds curious, asks for a repro, and here I start to rewrite the test as a self-contained file for easy reproduction.
The test is simple : to exercise my simulator, I create an array of fixed std_logic_vector's, with a size defined by a generic. Then, I connect elements of one line to other elements of the next line. Finally I connect the first and last lines to an input and output port, so the circuit can be controlled and observed by external code.
The result will surprise you.
So let's define the test code.
-- ghdl_expo.vhdl -- created lun. nov. 9 00:56:57 CET 2020 by Yann Guidon whygee@f-cpu.org -- repro of "exponential memory allocation" bug Library ieee; use ieee.std_logic_1164.all; entity xor2 is port (A, B : in std_logic; Y : out std_logic); end xor2; architecture simple of xor2 is begin Y <= A xor B; end simple; -------------------------------- Library ieee; use ieee.std_logic_1164.all; Library work; use work.all; entity ghdl_expo is generic ( test_nr : integer := 0; layers : positive := 10 ); port( A : in std_logic_vector(31 downto 0) ; Y : out std_logic_vector(31 downto 0)); end ghdl_expo; architecture unrolled of ghdl_expo is subtype SLV32 is std_logic_vector(31 downto 0); type ArSLV32 is array (0 to layers) of SLV32; signal AR32 : ArSLV32; begin AR32(0) <= A; t1: if test_nr > 0 generate l1: for l in 1 to layers generate AR32(l)(0) <= AR32(l-1)(31); t2: if test_nr > 1 generate l2: for k in 0 to 30 generate t3: if test_nr = 3 generate x: entity xor2 port map( A => AR32(l-1)(k), B=>AR32(l-1)(31), Y => AR32(l)(k+1)); end generate; t4: if test_nr = 4 generate AR32(l)(k+1) <= AR32(l-1)(k) xor AR32(l-1)(31); end generate; t5: if test_nr = 5 generate AR32(l)(k+1) <= AR32(l-1)(k); end generate; end generate; end generate; end generate; end generate; Y <= AR32(layers); end unrolled;There are 2 generics :
- test_nr selects the code path to test.
- layers selects the number of elements of the array.
And now let's run it :
rm -f *.o *.cf ghdl_expo log*.txt ghdl -a ghdl_expo.vhdl && ghdl -e ghdl_expo && # first test, doing nothing but allocation. ( for i in $(seq 2 2 100 ) do echo -n $[i]000 ( /usr/bin/time ./ghdl_expo -glayers=$[i]000 ) 2>&1 | grep elapsed |sed 's/max.*//'| sed 's/.*0[:]/ /'| sed 's/elapsed.*avgdata//' done ) | tee log1.txtThe result (time and size) are logged into log1.txt, which gnuplot will happily display :
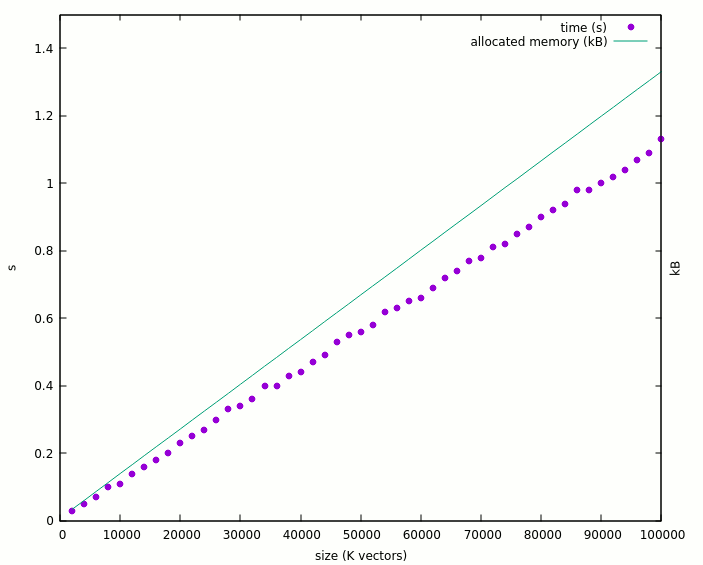
set xlabel 'size (K vectors)' set ylabel 'seconds' set yr [0:1.5] set y2label 'kBytes' set y2r [0:800000] plot "log1.txt" using 1:2 title "time (s)" w lines, "log1.txt" using 1:3 axes x1y2 title "allocated memory (kB)" w lines
And the result is quite as expected : linear.
![]()
The curve starts at a bit less than 4MB for the naked program, which allocated 10 lines of 32 std_logic. Nothing to say here.
I would object that I expected better than 1.13 seconds to allocate 100K lines, which should occupy 3.2MB for themselves (so less than 8MB total). Instead the program eats 710MB ! This means a puzzling expansion factor > 200 ! Anyway, I'm grateful it works so far.
Now, I activate the test 1:
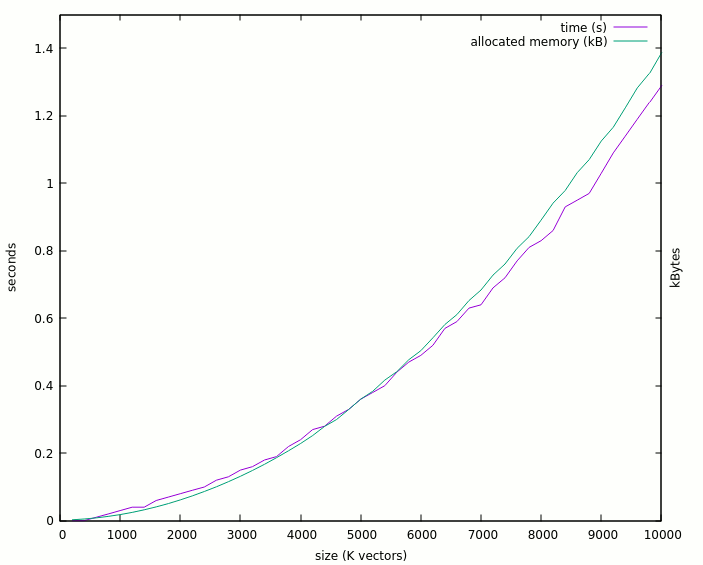
( for i in $(seq 2 2 100 ) do echo -n $[i]00 ( /usr/bin/time ./ghdl_expo -gtest_nr=1 -glayers=$[i]00 ) 2>&1 | grep elapsed |sed 's/max.*//'| sed 's/.*0[:]/ /' | sed 's/elapsed.*avgdata//' done ) | tee log2.txtThe result looks different :
![]()
Notice that I have reduced the number of elements by 10 and the max. run time is similar. Worse : the 10K vectors now use 3.2GB ! The expansion ratio has gone to 100K ! Why would a single std_logic waste 100K bytes ?
Remember that all it does is scan the array and connects one bit from one line to another bit from another line:
AR32(l)(0) <= AR32(l-1)(31);
This might be the core of the issue...
Test 2 adds another inner generate loop with nothing inside. The result is almost identical (<1%).
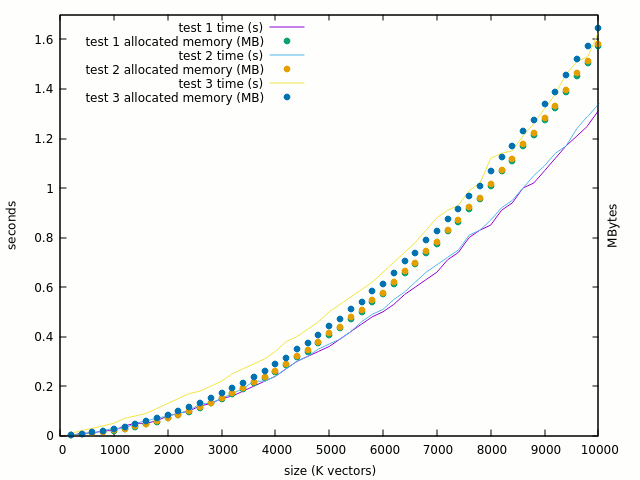
Test 3 adds one entity for each std_logic of the array, and the result is nice : there is only a linear and reasonable increase in time and space. There is a larger increase of runtime than space (due to initialisation ?) but it looks legit.
![]()
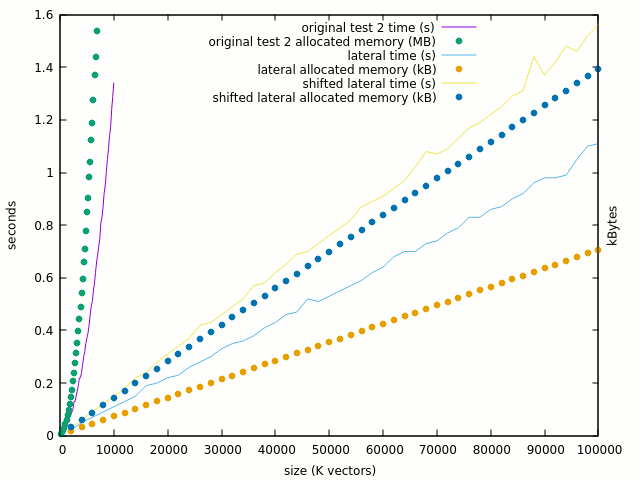
If mapping tons of entities is good, then why the exponential curve ?
Here are the comparative plots of test3 with and without the single bit assignation :
![]()
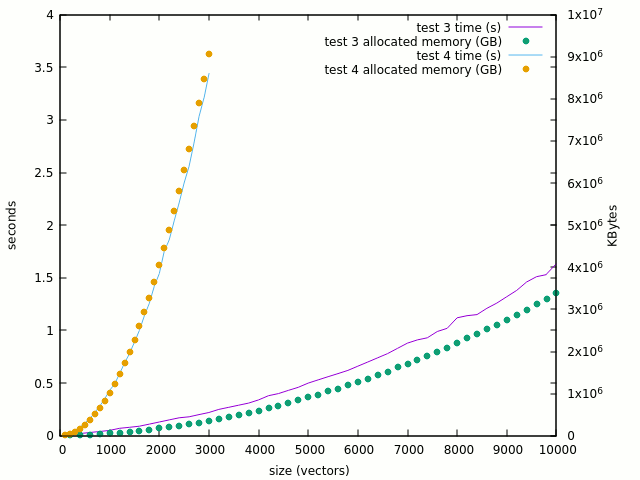
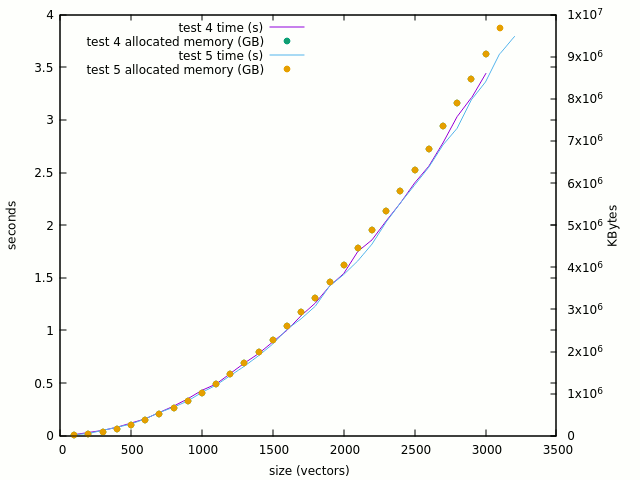
The curve is clearly linearised when the "<=" is removed and 100K gates looks reasonable. But where do the problems arise ? It should not be in the XOR computation itself, so let's try test #4 which computes the XOR in place. The thing gets totally mad :
- 100: 0.01s, 16MB
- 1000: 0.43s, 1GB
- 3000: 3.44s, 9GB !
Going from 100 to 3K is a factor of 30 but the memory & runtime ratio is >560 ! Given my computer's "reasonable" 16GB space, it's a very concerning problem. The curve is crazy :
![]()
The number of single-bit assignations has been multiplied by 32 and the reads of single bits multiplied by 64. So this looks like the culprit.
The last test (5) tries to see what happens when XOR is removed but assignation is kept. The result is very very close to the previous test:
![]()
This hints at the problem's cause : writing to a given bit of a 2D array has a high cost, but I don't see why.
The first lesson is that arrays may not be the right place to put temporary data, but they are necessary when using for...generate loops because it's impossible to create signals dynamically with VHDL. So my test must use another approach...
FOR-GENERATE allows the creation of local signals but they are not visible to other iterations so I'm screwed. Arrays looked like the natural, logical solution but it stabs me in the back.
Update :
Tristan examined the situation. He noticed an avalanche of malloc() of small values and there are potential easy fixes for this.
Meanwhile, I must change my approach to work around this. One easy solution would be to "lateralise" the system, working in variable columns and not in small fixed rows. Mapping entities does not hit the pathological case so it should be fine.
__________________________________________________________________________
Here is the new code :
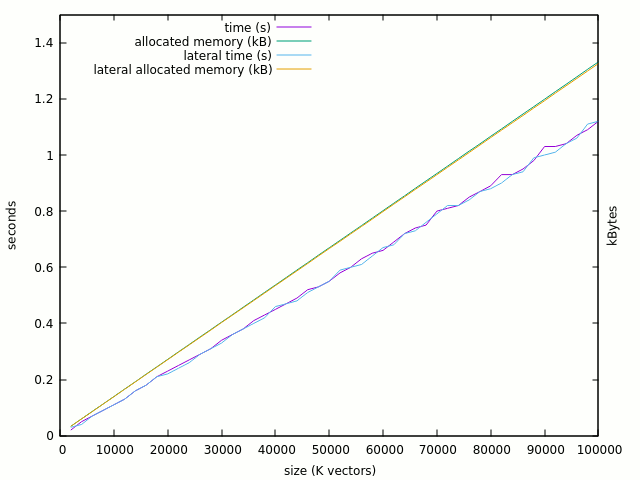
architecture lateral of ghdl_expo is subtype SLV is std_logic_vector(layers downto 0); type ArSLV32 is array (31 downto 0) of SLV; signal AR32 : ArSLV32; begin -- connect the inputs and outputs : l0: for o in 31 downto 0 generate AR32(o)(0) <= A(o); Y(o) <= AR32(o)(layers); end generate; ...And apparently, there is no significant difference between the initial and the lateral versions:
![]()
And there is still the same 706MB allocation, with >220 expansion ratio. Is there one malloc per single element ?
Enabling the test #1:
t1: if test_nr > 0 generate l1: for l in 1 to layers generate AR32(l)(layers downto 1) <= AR32(l)(layers-1 downto 0); end generate; end generate;![]()
This is functionally identical to the first version but here I assign vectors to vectors, and not elements to elements.
The behaviour is still linear : RAM doubled (fair enough) and time increased by 30%. Notice that we didn't even simulate anything yet, it might count the initialisation time after elaboration.
100K vectors (3.2M std_logic) now use 1.4GB but it's 20x better than the first version. I can extrapolate that I can simulate up to 32M elements with 16GB of RAM:
1000 00.02 18540 10000 00.15 143832 100000 01.48 1394652 1000000 14.25 13903172
Anything more and the HDD swaps. The ratio is "only" 437 though but 30M gates is serious enough.
____________________________________________________________
Now let's apply the lessons learned and implement a "big mess of gates":
t2: if test_nr = 2 generate l2: for l in 1 to layers generate -- wrap around w: entity xor2 port map( A => AR32(l-1)(0), B=>AR32(l-1)(31), Y => AR32(l)(31)); l22: for o in 31 downto 0 generate x: entity xor2 port map( A => AR32(l-1)(o), B=>AR32(l-1)(o-1), Y => AR32(l)(o-1)); end generate; end generate; end generate;As hinted before, entities use less memory :
1000 00.06 11688 10000 00.08 75328 100000 00.71 711704 1000000 06.83 7074936 2000000 13.51 14145228
The behaviour is linear too, and with 14GB I can describe 2M*32=64M gates ! We can also estimate the speed at 4M gates/second.
Notes:
- No actual simulation is taking place, it's only the elaboration + time=0 cost.
- No extra lib is used, there is nothing else at all, and this does not estimate the impact of the LibreGates library, I was only searching for a baseline and a rough idea of GHDL's behaviour to estimate the impact of my added code.
I hope this log could help others in the same situation :-)
-
The new netlist scanner
11/06/2020 at 08:33 • 0 commentsSee the beginning at 3. Rewrite as well as 35. Internal Representation in v2.9 for more dirty details !
After a hiatus, it's finally time to work again on the implementation of the algorithm explained in the log 36. An even faster and easier algorithm to map the netlist !
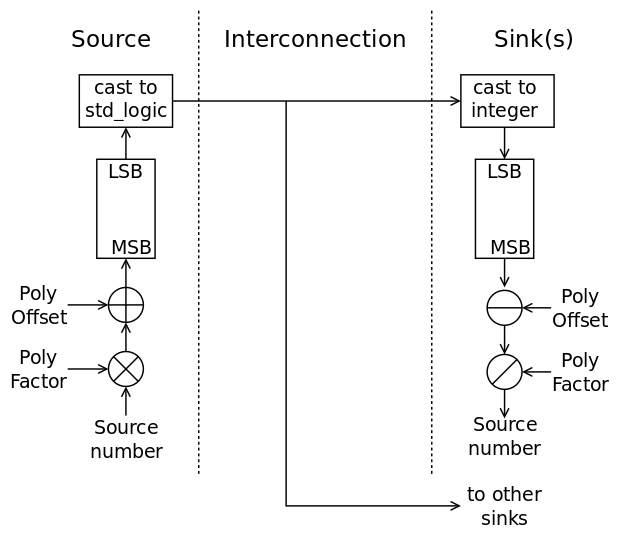
The linear function 5x+3 can be configured to trade off security for speed, with POLY_OFFSET and POLY_FACTOR. The higher the factor, the better the discrimination of snafus, but that increases the number of steps. A generic with default value is appropriate in this case.
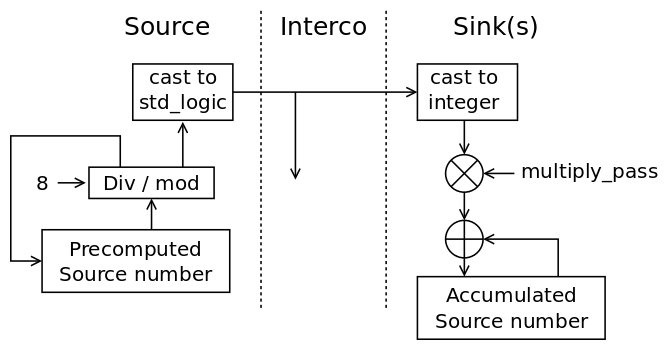
The principle of serialising and de-serialising through wire-type symbols is shown in the picture below. The original idea, around 2001, used binary codes for real wires but std_logic provides 8 useful symbols, plus the "refresh" one ('U').
![]()
Conversion between integers and the enumerated std_logic type is not as trivial as in other languages but still very easy, when you "get" how to dance around the strong typing constraints, as shown in this code:
Library ieee; use ieee.std_logic_1164.all; entity test_std is end test_std; architecture arch of test_std is begin process is variable i : integer; variable s : std_logic; begin for j in std_logic'low to std_logic'high loop if j = std_logic'high then s := 'X'; -- not 'U', to show a custom wrap-around else s := std_logic'succ(j); end if; report integer'image(std_logic'pos(j)) & " : " & std_logic'image(j) & " : " & std_logic'image(s); end loop; for i in 0 to 7 loop s := std_logic'val(i+1); report std_logic'image(s); end loop; wait; end process; end arch;The result:
$ rm -f test_std *.o *.cf && ghdl -a test_std.vhdl && ghdl -e test_std && ./test_std test_std.vhdl:24:7:@0ms:(report note): 0 : 'U' : 'X' test_std.vhdl:24:7:@0ms:(report note): 1 : 'X' : '0' test_std.vhdl:24:7:@0ms:(report note): 2 : '0' : '1' test_std.vhdl:24:7:@0ms:(report note): 3 : '1' : 'Z' test_std.vhdl:24:7:@0ms:(report note): 4 : 'Z' : 'W' test_std.vhdl:24:7:@0ms:(report note): 5 : 'W' : 'L' test_std.vhdl:24:7:@0ms:(report note): 6 : 'L' : 'H' test_std.vhdl:24:7:@0ms:(report note): 7 : 'H' : '-' test_std.vhdl:24:7:@0ms:(report note): 8 : '-' : 'X' test_std.vhdl:31:7:@0ms:(report note): 'X' test_std.vhdl:31:7:@0ms:(report note): '0' test_std.vhdl:31:7:@0ms:(report note): '1' test_std.vhdl:31:7:@0ms:(report note): 'Z' test_std.vhdl:31:7:@0ms:(report note): 'W' test_std.vhdl:31:7:@0ms:(report note): 'L' test_std.vhdl:31:7:@0ms:(report note): 'H' test_std.vhdl:31:7:@0ms:(report note): '-'
So it's pretty trivial to convert an int to std_logic and vice versa. It's a bit less so to extract bit fields from an integer because VHDL does not provide the shift and boolean operators :-( As I have tested a decade ago, going with bitvectors is too slow. The only way is to divide or multiply but the semantic is somehow lost and this does not work correctly with negative numbers (due to inappropriate rounding). I don't want to use my own shift&bool routines because they link to C code and that might break somehow in the future with new revisions to GHDL.
There is also a constraint on the amount of data that can be stored in the descriptor of each gate. For example a complete precomputed std_logic_vector would take too much room and the size would not be easy to determine before running the whole thing.
One compromise could be to store one std_logic element that is precomputed before each new pass. There are already 2 such variables in the record of each gate: curOut and prevOut but then, what about the input gates ?
curOut, -- the last result of lookup prevOut : std_logic; -- the previous result of the lookup changes : big_uint_t; -- how many times the output changed LUT : std_logic_vector(0 to 15); -- cache of the gate's LUT. sinks : sink_number_array(0 to 3);The variable changes can be used to accumulate the number to serialise, but the LUT can't be overwritten because it's necessary for the following steps of the algorithm.
sinks is an array of numbers that can be used to de-serialise the incoming numbers for each input. Serialisation would start "LSB first" so each new received symbol is simply shifted left, or multiplied, by a variable amount, which is very simple.
-- in the driver : ... variable multiply_pass : integer := 1; ... -- don't forget to first clear all -- the counters in the cells' sinks ... loop -- send the data ... wait for 1 s; -- yield to the code in the cells ... multiply_pass := multiply_pass * 8; end loop; -- in the cells : ... variable v : std_logic; -- the received value variable n : integer; ... if v = 'U' then output <= 'U'; else output <= emit(); -- de-serialisation: n := std_logic'pos(v) - 1; -- 0 <= n <= 7 n := n * multiply_pass; sinks(x) := sinks(x) + n; end if;
the variable multiply_pass goes from 1 to 8 to 64 to 512 to 2048 etc. and places the new 3 bits at the right position.
Then to check the result in sinks(x):
variable n, m : integer; ... n := sinks(x) / POLY_FACTOR; m := sinks(x) - (n*POLY_FACTOR); -- compute the modulo if m = POLY_OFFSET then sinks(x) := n; -- now "register" the sink in the linked list else error... end if;The harder part is for sending. Variable divisions are slow, divisions by constant powers of two can however be optimised at compile time to shifts. The solution appears to be using local shift registers, or accumulators (decumulators ?), instead of calculating the index/offset every time. The intermediate result is saved for the next step, thus saving some calculations, however all the gates must be updated at the same exact time and as many times, or the shifting would be desynchronised. A local update counter is required for each group of sinks (gates and outputs) and will be compared at the end of the tracing algorithm. Inconsistent counter values would betray unconnected sinks for example.
The new diagram makes the idea clearer, I hope :
![]()
With the fixed div/mod factor, the operation shouldn't be resource-consuming and the list of gates/ports needs only a scan at the start and the end of the loop.
When should the scan loop stop ?
- A safe condition is when all the sources send the same value corresponding to symbol 0.
- When the last serialiser de-cumulator reaches 0
The last one is simpler/shorter and stops earlier than the first so it's adopted :-)
There is a last problem to solve though: the source number must be positive for the transmission algo to work. However negative numbers exist to indicate the input ports... The poly_offset must also include the number of input ports, and start counting from port #0 to DutVectIn_length, then from gate 1 to gate_max (there is no gate #0 !). At this point, backwards gates do not count as input ports.
The algo will :
- scan to initialise the ports then the gates, incrementing the init value by Poly_factor, and clear the sinks' accumulators.
- loop and increase multiply_pass, also check the outputs, until the last gate's decumulator reaches 0.
before letting the gates react, clear a counter, which is incremented by all the gates and output, to ensure that ALL elements receive data at every cycle, ensuring the netlist is fully connected. - scan the gates and the outputs, check the sink values' correctness then connecting the sinks to the linked list of the corresponding source.
This should work...
-
OSU FreePDK45 and derivatives
09/20/2020 at 18:07 • 0 commentsOne easy library to add to the collection is OSU's FreePDK45, found at https://vlsiarch.ecen.okstate.edu/flows/ (direct download link : https://vlsiarch.ecen.okstate.edu/flows/FreePDK_SRC/OSU_FreePDK.tar.gz : only 1.7MB, mirroredhere)
It's a good candidate because it's a really surprisingly tiny library : 33 cells only !
FILL (no logic input or output)
BUFX2 BUFX4 CLKBUF1 CLKBUF2 CLKBUF3 INVX1 INVX2 INVX4 INVX8 TBUFX1 TBUFX2 (1 input, 1 output)
AND2X1 AND2X2 HAX1 NAND2X1 OR2X1 OR2X2 NOR2X1 XNOR2X1 XOR2X1 (2 inputs)
AOI21X1 FAX1 MUX2X1 NAND3X1 NOR3X1 OAI21X1 (3 inputs)
DFFNEGX1 DFFPOSX1 DFFSR LATCH (non-boolean)
This is close to the minimum described at http://www.vlsitechnology.org/html/cell_choice2.html but should be enough for basic circuits. In fact we have the 1st order and most of the 2nd order gates, which I covered in log 31. v2.9 : introducing 4-input gates. OAI211 and AOI211 are missing, which are very useful for incrementers and adders...
The site also provides these same basic standard cells for AMI 0.6um, AMI 0.35um, TSMC 0.25um, and TSMC 0.18um released in 2005 at https://vlsiarch.ecen.okstate.edu/flows/MOSIS_SCMOS/iit_stdcells_v2.3beta/iitcells_lib_2.3.tar.gz. A single bundle packages 4 technologies ! The library seems to have evolved to reach v2.7 and included a LEON example project: https://vlsiarch.ecen.okstate.edu/flows/MOSIS_SCMOS/osu_soc_v2.7/ (but the latest archive looks broken)
I love how minimal, compact and simple these gates are, accessible to beginners and targeting from 45nm to .5µm. It looks like a "RISC" approach to VLSI ;-) Note also that there are only 2 gates with two output drives and 2 inputs : AND and OR, which are 2nd order gates, merging a NAND/NOR with a X1 or X2 inverter. The rest of the fanout issues are solved by inserting INVX gates at critical fanout points. This means that physical mapping/synthesis should start by examining the fanouts, inserting the inverters/buffers and then deducing which logic function to bubble-push.
I'm not sure how to create the files but I can easily derive them from the A3P files in 3 ways:
- Modify the file generator
- Modify the generated files
- Create a "wrapper" file
Furthermore the sequential gates are not yet clear about the precedence of the inputs.
Extracting the logical functions was as simple as a grep and some sed :
grep -r '>Y=' * |sed 's/.*data//'|sed 's/<tr.*FFF//'|sed 's/<.*//'|sed 's/[.]html.*Y/: Y/' CLKBUF2: Y=A AND2X2: Y=(A&B) NAND3X1: Y=!(A&B&C) NOR3X1: Y=!(A|B|C) XOR2X1: Y=(A^B) BUFX4: Y=A MUX2X1: Y=!(S?(A:B)) OR2X1: Y=(A|B) AND2X1: Y=(A&B) TBUFX2: Y=(EN?!A:'BZ) /INVX8: Y=!A /CLKBUF3: Y=A INVX1: Y=!A AOI21X1: Y=!((A&B)|C) XNOR2X1: Y=!(A^B) BUFX2: Y=A OAI22X1: Y=!((C|D)&(A|B)) TBUFX1: Y=(EN?!A:'BZ) OR2X2: Y=(A|B) OAI21X1: Y=!((A|B)&C) NAND2X1: Y=!(A&B) AOI22X1: Y=!((C&D)|(A&B)) CLKBUF1: Y=A NOR2X1: Y=!(A|B) INVX4: Y=!A INVX2: Y=!A
For the VHDL version, only a few more simple substitutions are required:
$ grep -r '>Y=' * |sed 's/.*data[/]/"/'|sed 's/<tr.*FFF//'|sed 's/<.*//'|sed 's/[.]html.*Y=/": /' |sed 's/[!]/not /g' |sed 's/[|]/ or /g' |sed 's/[&]/ and /g' |sed 's/\^/ xor /g' |sort "AND2X1": (A and B) "AND2X2": (A and B) "AOI21X1": not ((A and B) or C) "AOI22X1": not ((C and D) or (A and B)) "BUFX2": A "BUFX4": A "CLKBUF1": A "CLKBUF2": A "CLKBUF3": A "INVX1": not A "INVX2": not A "INVX4": not A "INVX8": not A "MUX2X1": not (S?(A:B)) "NAND2X1": not (A and B) "NAND3X1": not (A and B and C) "NOR2X1": not (A or B) "NOR3X1": not (A or B or C) "OAI21X1": not ((A or B) and C) "OAI22X1": not ((C or D) and (A or B)) "OR2X1": (A or B) "OR2X2": (A or B) "TBUFX1": (EN?not A:'BZ) "TBUFX2": (EN?not A:'BZ) "XNOR2X1": not (A xor B) "XOR2X1": (A xor B)
Notice that MUX2 should be called MUXI and A and B are swapped relative to the A3P lib. Some other corner cases are easily translated by hand as well. The TBUFs however fall outside of the purely boolean realm...
Some gates have 2 outputs :
HAX1: YC=A and B YS=A xor B FAX1: YC=(A and B) or (B and C) or (C and A) YS=A xor B xor C
These are obviously gates that can be split into known functions (such as MAJ in other libraries) but they certainly offer a space advantage when some inputs are merged. Macros would easily be created for these two gates.
The non-boolean gates need some more analysis.
- LATCH has no extra input, it's just a transparent latch with no reset or preset. It is practically equivalent to MUX2X1 with an extra loopback inverter. Next.
- DFFPOSX1 and DFFNEGX1 are simple simple DFF with no extra input, and you can choose the clock polarity.
- DFFSR is another beast, defined by this code:
FLIPFLOP{ DATA=D CLOCK=CLK PRESET=!S CLEAR=!R Q=P0002 QN=P0003 } Q=P0002This seems to map to an internal representation of a full flip-flop with Data, Reset and Preset inputs but with no information about the precedence of the signals.
And that's all for this simple but nice PDK. No RAM, no data enable on DFF, no anything, just the minimal set of gates you need to make most common digital circuits.
-
inside out
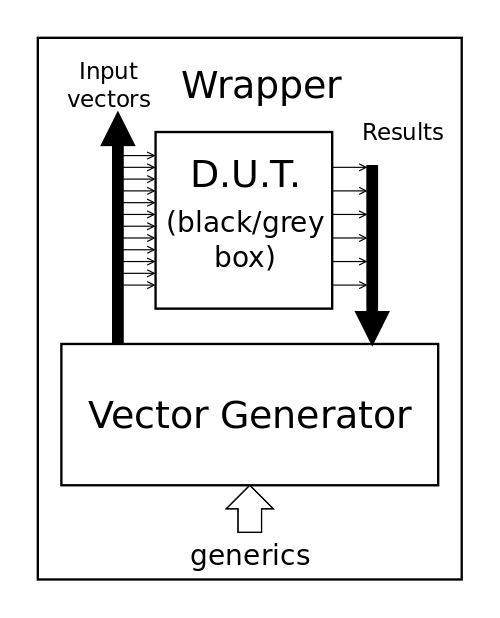
09/14/2020 at 17:51 • 0 commentsThe log 5. Another method to create the wrapper has successfully implemented the automatic wrapper that I intended to design one year ago. This is a relief, even though for now it forces bit vectors to use the SLV package of wrapper types. This could be solved later and it's not a great problem because the units I test have a fixed size, genericity has gone out of the window since the netlists are synthesised.
Now this forces me to re-architect the whole code because now the wrapper is the top level. The previous choice has been discussed in the log 24. Hierarchy problems and solutions and we're back to the initial version:
![]()
The bash script now knows the size of the vectors and can also "plug" the generator or driver but the rest of the code must be turned upside down like a sock. I have to rewrite/restructure the code from scratch, but the modifications are minor.
The new structure has the wrapper containing the "driver" so the wrapper has no I/O ports, which are replaced by internal signals. Another change is that the driver is made of procedures and functions and it would be weird to encapsulate them in another entity. A main procedure with in and out arguments would work better and reduce the semantic complexity : in VHDL a procedure can work like an entity so let's exploit this trick :-) And the procedure can be nicely packaged in a separate library.
Some more typing and I get the following example out of the ALU:
-- Wrapper.vhdl -- Generated on 20200915-07:57 -- Do not modify Library ieee; use ieee.std_logic_1164.all; Library work; use work.all; Library LibreGates; use LibreGates.Gates_lib.all; use LibreGates.Netlist_lib.all; entity Wrapper is generic ( WrapperWidthIn : integer := 22; WrapperWidthOut: integer := 17; main_delay : time := 1 sec; filename : string := ""; -- file of exclude vectors verbose : string := "" ); end Wrapper; architecture Wrap of Wrapper is signal VectIn : std_logic_vector(WrapperWidthIn -1 downto 0); signal VectOut: std_logic_vector(WrapperWidthOut-1 downto 0); signal VectClk: std_logic := 'X'; begin -- force the registration of the gates. -- must be placed at the very beginning! update_select_gate( -- called only once at start 0, -- show gate listing when < 1 -1, -- no alteration 2, -- probe mode verbose, filename); Drive_DUT(VectIn, VectOut, VectClk, main_delay); -- Finally we "wire" the unit to the ports: tb: entity alu8 port map ( cin => VectIn(0), neg => VectIn(1), passmask => VectIn(2), orxor => VectIn(3), rop2mx => VectIn(4), cmps => VectIn(5), sri => VectIn(13 downto 6), snd => VectIn(21 downto 14), rop2 => VectOut(7 downto 0), sum => VectOut(15 downto 8), cout => VectOut(16)); end Wrap;The line use LibreGates.Gates_lib.all; is required because update_select_gate() is used. Drive_DUT() is defined is defined in the new package Netlist_lib where all the netlist management functions are moved, from Vectgen.vhdl which will soon be obsolete.
So now all the "fun stuff" is going to happen in Netlist_lib.vhdl, in which the size of the vectors is very easy to get, with the 'LENGTH attribute:package body Netlist_lib is procedure Drive_DUT( signal VectIn : out std_logic_vector; signal VectOut: in std_logic_vector; signal VectClk: inout std_logic; Interval: in time) is begin report "VectIn: " & integer'image(VectIn'length) & ", VectOut: " & integer'image(VectOut'length) & ", CLK: " & std_logic'image(VectClk) ; wait; end Drive_DUT; end Netlist_lib;There, it's solved. And I can even sense if the clock signal is connected, by setting it to 'X' or 'U' in the wrapper.
Well no, it's not totally and definitively solved because it's a hack and it can't catch the std_logic_vectors. It works but it's not scalable.Unai did some code at https://github.com/ghdl/ghdl/pull/1449 for his project https://umarcor.github.io/hwstudio/ and there is hope that libghdl will be more and better used in the future. I didn't want to add more languages (and my python version is obsolete) but it's not ruled out. I'm waiting for Unai to progress with his version while I progress on my own code :-)
-
Another method to create the wrapper
09/09/2020 at 23:12 • 0 commentsFor now I manually create the "wrapper" unit that maps the inputs and outputs to a pair of unified vectors.
In private, Tristan told me there was some sort of Python thing that could do what I need but I'd rather avoid Python and experimental (like, less than 5 years old) features.
But there could be another way to extract the inputs and outputs from the compiled design : with the trace dumps ! GTKwave knows the type and direction of each port so maybe I can parse the trace dump to extract the info I want.
I'll have to test this ASAP, as I am currently contemplating how to make GetVectorsSize better.
Trying to play with GHDL in the LibreGates/tests/test2_INC8 directory:
> PA3="-P../../LibreGates -P../../LibreGates/proasic3" > ghdl -a $PA3 INC8_ASIC.vhdl > ghdl -e $PA3 INC8 > ./inc8 --vcd=inc8.vcd > less inc8.vcd ____________________________ $date Sat Sep 12 05:18:00 2020 $end $version GHDL v0 $end $timescale 1 fs $end $var reg 8 ! a[7:0] $end $var reg 8 " y[7:0] $end $var reg 1 # v $end $var reg 8 $ ab[7:0] $end $var reg 1 % a012 $end $var reg 1 & a012a $end $var reg 1 ' a012b $end $var reg 1 ( a34 $end $var reg 1 ) a345 $end $var reg 1 * a3456 $end $scope module (0) $end $scope module x4 $end $var reg 1 + a $end $var reg 1 , y $end $var reg 1 - t $end $scope module e $end ......OK....
I get a dump of signals but NO indication of type (which can only be assumed), direction or hierarchy...
From the doc:
"Currently, there is no way to select signals to be dumped: all signals are dumped, which can generate big files."
There could be more hope with the ./inc8 --wave=inc8.ghw command but that would require more efforts because the dump is in binary, undocumented and subject to change...
Another approach uses another underrated feature of GHDL :
ghdl --file-to-xml $PA3 INC8_ASIC.vhdl
The -a command is replaced here with --file-to-xml command which, as you can infer from the name, dumps a XML stream...
Here we find the definitions of the ports. This is contained in the "port_chain" tag :
<port_chain> <el kind="interface_signal_declaration" identifier="a" mode="in"> <subtype_indication identifier="slv8"></subtype_indication> </el> <el kind="interface_signal_declaration" identifier="y" mode="out"> <subtype_indication identifier="slv8"></subtype_indication> </el> <el kind="interface_signal_declaration" identifier="v" mode="out"> <subtype_indication identifier="sl"></subtype_indication> </el> </port_chain>I have removed a LOT of text to get only what is required.
This allows the use of the wrapper types SLVx and SL, but now we need XML processing software to list and extract only the needed information...
Well, this is where it's getting interesting : at first I'd thought that using the wrapping types would make thing harder but looking at the XML, it looks like a great way to simplify the parsing because the std_logic_vectors use a complex system to define the bounds. OTOH the type SLV8 makes a static statement about the type and size, which is not flexible or generics-configurable but much more direct to extract.
Well, thanks to some unexpected hack found on StackOverflow, it seems that XML can be crudely parsed with some dirty-as-ever bash script.
#!/bin/bash # LibreGates/wrap.sh # created sam. sept. 12 09:29:47 CEST 2020 ReadTag () { IFS=\> read -d \< ENTITY } GetAttribute () { #input list in $1 LIST=($ATTRIBUTES) # split string into array ATTRIBUTE="" for i in $(seq "${#LIST[@]}") ; do # scan the list IFS='"' read -a ATTRIBUTE <<< "${LIST[$i]}" # split the individual parameter in a sub-string #echo " $ATTRIBUTE - ${ATTRIBUTE[1]}" if [[ $ATTRIBUTE = "$1" ]] ; then # found the key echo -n "${ATTRIBUTE[1]}" # return the value fi done } PORT_TYPE="" PORTNAME="" INOUT="" FlushPort () { if [[ "$PORT_TYPE" != "" ]] ; then case "$INOUT" in "in") ;; "out") ;; *) echo "wrong port direction for signal $PORTNAME" return esac echo "$PORTNAME $PORT_TYPE $INOUT" fi } # keep only the first "port_chain" block which should be the top-level interface ghdl --file-to-xml $* | # transform the VHDL into XML sed '/ <\/port_chain>$/,$d' | # drop everything after the first end of block sed -n '/ <port_chain>$/,$p' | # drop everything before the first start of block while ReadTag; do # parse the stream TAG_NAME=${ENTITY%% *} ATTRIBUTES=${ENTITY#* } if [[ $TAG_NAME = "el" ]] ; then FlushPort LIST=($ATTRIBUTES) # split string into array INOUT=$(GetAttribute 'mode=') PORTNAME=$(GetAttribute 'identifier=') fi if [[ $TAG_NAME = "subtype_indication" ]] ; then PORT_TYPE=$(GetAttribute 'identifier=') fi done FlushPortIt could have been shorter but I wanted to avoid any collision (or worse) caused by eval.
And it works ! Here is the result when run on ALU8 :
$ ../../LibreGates/wrap.sh $PA3 ALU8_classic.vhdl cin sl in neg sl in passmask sl in orxor sl in rop2mx sl in cmps sl in sri slv8 in snd slv8 in rop2 slv8 out sum slv8 outSo now I just have to extract the size of each port and I'm almost done ;-)
Thank you GHDL :-P
Oh wait, the wrapper also needs the name of the entity to include. Hold my beer:
# Get the top level entity: rm -f work-obj93.cf *.o ghdl -a $* && TOP_ENTITY=$(ghdl --find-top $*)Sweet.
More head-desking caused by bash's insane system, and I can generate this :
architecture Wrap of Wrapper is begin tb: entity alu8 port map ( cin => VectIn(sl), neg => VectIn(sl), passmask => VectIn(sl), orxor => VectIn(sl), rop2mx => VectIn(sl), cmps => VectIn(sl), sri => VectIn(slv8), snd => VectIn(slv8), rop2 => VectOut(slv8), sum => VectOut(slv8), cout => VectOut(sl)); end Wrap;Now I just have to manage the indices in the vectors.
But the whole system is upside down again because now the wrapper sets the sizes (nothing to probe) and must provide these values to the rest of the engine.
20201107 :The scripts have worked but apparently it can't process files that include external gates.
I just found today that it works just OK when parsing the header/declaration !
Before, I had to parse the higher-level version of a unit without the inclusions, and flush all the intermediary results, but I can simply strip the (often duplicated) declaration and cut at the "architecture" line.
-
More features ! (one day)
09/08/2020 at 16:40 • 0 commentsWhile replying to Pat in comments in I’m Sorry Dave, You Shouldn’t Write Verilog, I realised that this little library could perform more functions, in particular "auto-pipeline" (the automatic insertion of DFF in the middle of a circuit to increase its clock speed). This requires the new function that re-exports a (modified) netlist. And from there, it's "all the way down on the slippery slope", with the possibility to modify the netlist in whatever other ways we might desire (extract a logic cone, strip DFFs to de-pipeline, you name it). It would become like a sort of sed for netlists ;-)
I don't think it will be hard to re-export a netlist, based on the depthlist. I'd love to visualise the graphs however !
Another possible funny application would be "de-synthesising" because the PA3 files contain a symbolic/algebraic representation of the boolean function of each gate, in text format ! Just substitute the operands with the net name and you get source code. So, given a netlist of gates with 3 inputs each, finding the corresponding reverse boolean function/name is quite easy and the netlist can be decompiled into a higher-level description, that is easier to read. You don't even need to know the name of the gate or function, the 8 bits of the LUT are enough (as found in some EDIF dumps), and applying permutations to the inputs will compress the 256 cases down to the known non-degenerate cases. I don't know if/how that will be useful in practice but it opens the perspective to transcode a library into another (when I'll have integrated other libraries). Can you imagine being able to port a design to another technology with a simple run of a program and not bother with the gates naming ? This means you can start your design on whatever platform you like and not being locked into it. -
Rewrite
09/03/2020 at 16:17 • 0 commentsSee also 8. The new netlist scanner as well as 14. A smarter sinks list allocator for the rest.
As I try to integrate the Backwards component, I see no place where I could easily change a few lines of code to make it work (although the principle itself is quite simple, right ?). Instead I am facing a big plate of spaghetti, not with the code itself (which is rather good, thanks) but with the data structures that are interwoven and the naming that might not be reflecting the function (which has certainly evolved since their creation). Oh and I didn't log much about the internals, so that genius pile of code is hard to re-architect easily.
Of course there are good and great things that I want to keep. However I see that my initial technique for netlist extraction is quite under-efficient in the case of large designs : it works for small systems but I'm evaluating how it will scale to much larger circuits and I face a O(n²) vs O(n×log(n)) problem. If I ever have one million gates, the setup phase will be ... loooong.
So I have to redesign some parts. This affects only 2 files : VectGen.vhdl and Gates_lib.vhdl, but the data structure depend a lot on the algorithms and I'm going to significantly change the latter. I must re-engineer the former... And this time I must document them ! In essence, I must rewrite just after the first routine :
-- the main sequence of VectGen.vhdl: GetVectorsSize; -- probing the inputs and outputs GetNetList; -- actively probing the gates FixSinklist; -- post-processing, no gate activity FixDepthList; DisplayDepthList;
GetVectorsSize is alright so far (though it might be re-designed one day, but it's another story).
Edit : see 5. Another method to create the wrapperGetNetList however is a big offender and needs a replacement, and the change in algorithm could lead to a change in data structures, that will affect the next procedures : FixSinklist and FixDepthList. This is where I can check for "zombies" and/or take Backwards into account. Changing GetNetList will probably lead to the redesign of FixSinklist and others as well...
The basic idea is that of drivers and sinks, as anywhere. A net is all the connections between the driver and all the sinks, so the "net" is practically described by the driver (we don't play with tristates here). So a "netlist" is just a list of drivers, with sublists of respective sinks.
But a complete digital circuit must have input ports and output ports, not just logic gates, so the main database is (as already described in 1. First upload):
- A list of gates, each with one output and an array of inputs. The array is indexed with gates numbers >= 1
Gates_lib.vhdl : type Gate_Desc_Array is array(integer range <>) of Gate_Descriptor; type Gate_Desc_Access is access Gate_Desc_Array; shared variable GateList : Gate_Desc_Access; ... GateList := new Gate_Desc_Array(1 to gate_instance_counter);
The size is known after the elaboration phase, after all the gates have called their respective census function, but before the very first clock cycle. update_select_gate must be called by the very first component in the hierarchy list.
- A list of input ports, which is an array of drivers. The std_logic_vector is "downto 0" but the signals are mapped to gates numbers < 1 (range "-x to 0"). Note that these numbers are valid when found in a sink port.
Gates_lib.vhdl: shared variable input_records : output_record_access;
- A list of output ports, the reverse of the input ports : this is an array of sinks, with positive indexes for the std_logic_vector, but mapped to the negative ( < 1) gate numbers found on drivers.
Gates_lib.vhdl: shared variable output_records : input_records_access;
The port sizes are determined by GetVectorsSize after a number of clock cycles.
-- allocate some memory for the descriptors output_records := new input_records_array(0 to VectOutMax); input_records := new output_record_array(0 to VectInMax);
And this is only now that I realise I shouldn't have called it "input_records_array" but "sink_records_array" because it adds to the confusion...
So what are those sinks and drivers, what do they contain and how are they implemented ? In fact there are two versions of the story : the ugly and the tidy:
- The ugly version is when the netlist is being created, with so many unknowns that it's impossible to know any size for sure. The solution is called "linked lists" : the driver has the number to the first sink, which has the number to the second sink, and so on. The link is a small size increase to the gates and all, but this avoids a lot of dynamic allocations and reallocations.
- The tidy version comes after the ugly version is completed. Knowing all the sizes, one array can be dynamically allocated for each net such that random/indexed access is possible and easy. This requires a sort of "compilation" or transformation of the ugly version into the clean one.
The memory footprint must also be carefully considered. To save space, a new compact representation is introduced :
- Driver addresses are a relative number, with numbers above 0 being gates and numbers below 1 being input ports (nothing new here)
- Sink addresses are also a relative number, with numbers below 1 representing output ports. Positive addresses however must encode not only the gate but also the input port number, between 0 and 3. A simple first-order formula encodes both into a single number:
address := (gate_number * 4) + input_number; input_number := address mod 4; -- and 3 gate_number := address / 4; -- shr 2
This reduces the coding weight and size vs the previous system where a sink is a record with 2 numbers...
This also allows the creation of a large (sparse) array to map all the gates inputs.
It's a hack but at least I managed to encode everything in a single integer. Clarity dictates that these addresses should be subtypes of integer, to prevent any confusion and bug. Indeed : you can not directly compare a sink number and a driver number anymore ! The code below is added to Gates_lib.vhdl, it's just added syntax but at least it's not a record and the coding intention is more explicit (there are already so many integers here and there).
type gate_port_number_type is range 0 to 3; type sink_number_type is range integer'range; type driver_number_type is range integer'range;
At minimum, sinks only need to point to the driver. The linked list could be temporarily stored in an external array of integ... of numbers.
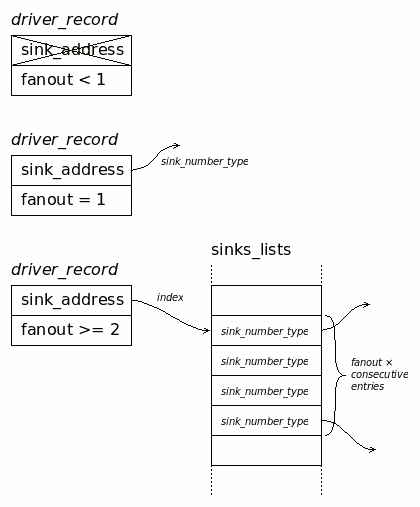
The drivers must also store the fanout : the number of sinks. There is nothing else that strictly belongs to the driver definition, so a driver is simply a record with 2 fields. The 2nd field is either a pointer to a first sink, or to an array.
The previous version of the code would "recompile" each linked list and allocate a new array, each with it housekeeping data. Considering that the meta-information of the array easily outsizes the contents if the fanout is small (1, 2 or 3 sinks is the majority of the cases), this might not have been the wisest and most efficient (fast and compact) organisation for FixSinklist and others.
All those tiny arrays could be merged into a large vector/array, and the driver contains either:
- The index in the large "gates sinks array" if the fanout is > 1 (and "fanout" following entries are the sub-array)
- The sink number itself if fanout < 1 or when in "linked list" mode.
Both are integer numbers so there is no need to make 2 versions of the record, or a "union" (which VHDL doesn't support).
type driver_record is record sink_address : integer; -- can be either: -- * when fanout > 1 : an index in the unified sinks table -- * when fanout < 2 : a sink_number_type fanout : integer; end record;This already reduces the complexity and confusion created by the previous input_address_record and input_record_type.
![]()
I mentioned a large array of sink_number_type and in first approximation, the size could be gate_instance_counter*4. Let's not forget the output ports, of course. But that number can be refined to a more accurate value because gate_instance_counter is computed with all the calls to the census functions and they can be extended with an argument, which is the inputs count. Then, when GetVectorsSize returns, it is easy to allocate the right amount of memory. Because, you know, when you have to deal with a million gates, this is the kind of detail that starts to matter.
shared variable total_sinks_count : integer := 0; ... impure function Gate_Census(sinks: integer) return integer;
Of course this breaks the PA3_gategen.vhdl code, which is now updated as well...
To complete the picture, here is the (partial) definition of a gate :
type Gate_Descriptor is record -- general info: gate_kind : enum_gate_kind; -- boolean, DFF or backwards ? gatename : line; -- full path & name of the gate -- Lookup & histograms : ..... -- for the probe: sinks : sink_number_array(0 to 3); driver : driver_record; end record;The initial netlist is made of:
shared variable GateList : Gate_Desc_Access; -- The array that contains all the gates shared variable sinks_lists, -- dynamic array with total_sinks_count entries, essential part of the netlist output_sinks : sink_number_array_ptr; -- the dynamic array of descriptors of the output port shared variable input_drivers : driver_record_array_access; -- array of the descriptors of the input portYou see the first mention of sinks_list, the main array that contains the lists of sinks (with the index and length given by the driver records).
It is complemented by global variables for the size of each array:
GateList => gate_instance_counter sinks_lists => total_sinks_count output_sinks => VectOutMax input_drivers => VectInMax indexPtr => registered_instance_counter
By the way : indexPtr is simply an array of gate numbers that have more than 1 input and where it is worth it to collect the histogram data (it's a subset of the GateList but the eventual confusion is worth clearing).
....
Continued at 8. The new netlist scanner
- A list of gates, each with one output and an array of inputs. The array is indexed with gates numbers >= 1
-
Second upload
09/02/2020 at 19:24 • 0 commentsToday I moved things again. The proasic3 directory is now inside the LibreGates directory to ease inclusion with other projects, with a single entry point for the paths (a single symlink would be enough and the other directories will be relative to this base). I'm considering updating the #YGREC8 soon but for now there are other more pressing issues, such as (finally) integrating the Backwards gates (they don't work yet), and changing the probing algorithm (introduced in log 36. An even faster and easier algorithm to map the netlist). That's 2 things to be done simultaneously and the second seems more daunting, the Backwards gates will integrate nicely when I rewrite some parts of VectGen.vhdl.
-
First upload
09/01/2020 at 14:39 • 0 commentsLibreGates_20200801.tgz is online !
This is what should have been #VHDL library for gate-level verification's v2.10 but the scope of the change cascaded into a big structural change, which is necessary anyway to get the Backwards gates working.
All the previous unit tests work and indeed have been instrumental to get the new version right. They took time to develop and fix but they are priceless because without them, the archive would not be as right so fast (it only took some hours to get things back to relatively bugless and working status).
Unit tests are invaluable and also serve as examples, tutorials and showcase the functions and usefulness of the library. More tests should follow...
But for now I must focus on getting the Backwards gates working, and I have added a new enum :
type enum_gate_kind is ( Gate_boolean, Gate_register, Gate_backwards );I don't want to break any part of the code, which is quite sophisticated... So I keep the gates numbering system :
- gate numbers > 0 are library gates. Now it is possible to specify the "kind" (either boolean, register or backwards)
- gate numbers < 1 are ports
- If the number appears on an output, the port is an input
- conversely, if the number appears on an input, the port is an output
This reduces the amount of modifications, compared to the bolder plan I had but that would be much more harder to get right and fast. I get my feet wet again by adding support for Backwards and then I'll see how I can manage to get a useful, accurate and reliable model for the DFFs and latches.
Libre Gates
A Libre VHDL framework for the static and dynamic analysis of mapped, gate-level circuits for FPGA and ASIC. Design For Test or nothing !