CarbonCycle
CarbonCycle-
Advanced bare-metal storage: Rook-Ceph
02/03/2021 at 23:48 • 0 commentsI have fortunately have had a chance to spend copious quality time with the rook-ceph project recently on x86_64. For some odd reason, storage continues to be a significant pain-point in bare-metal Kubernetes. Recent architectural choices for Ceph to use the Container Storage Interface ( CSI ) have made the deployment of storage services more consistent with scalable micro-service concepts and intentions with the Rook operator. I looked around for other efforts to deploy rook-ceph on ARM64 and found this blog that was encouraging. I want to deploy a full 3-node fault-tolerant version - that can provide dynamic provisioning for persistent volume claims. I have successfully deployed this service on x86_64 - and learned some lessons on interpretation of OSS documentation - that probably shouldn't have been as difficult as it was. Plain explanations for basic requirements are actually rare - and what does exist seems to require extensive background to grok the nuance. I would like to help others find the easy-button to at least get a rook-ceph deployment up and running in their home clusters. Due to circumstances, I have some spare time to pursue this goal. I haven't actually tried this yet, found all the containers and such. I also expect I'll need to tune the resources to the scale of my cluster. I'll need to share some drawings of the component layout - so the bare-metal configuration is explicit.
Once I have working a working helm chart for the Rook operator and cluster manifest for the Ceph components, I'll post them here. I'll be using external USB disk for the supporting storage RADOS
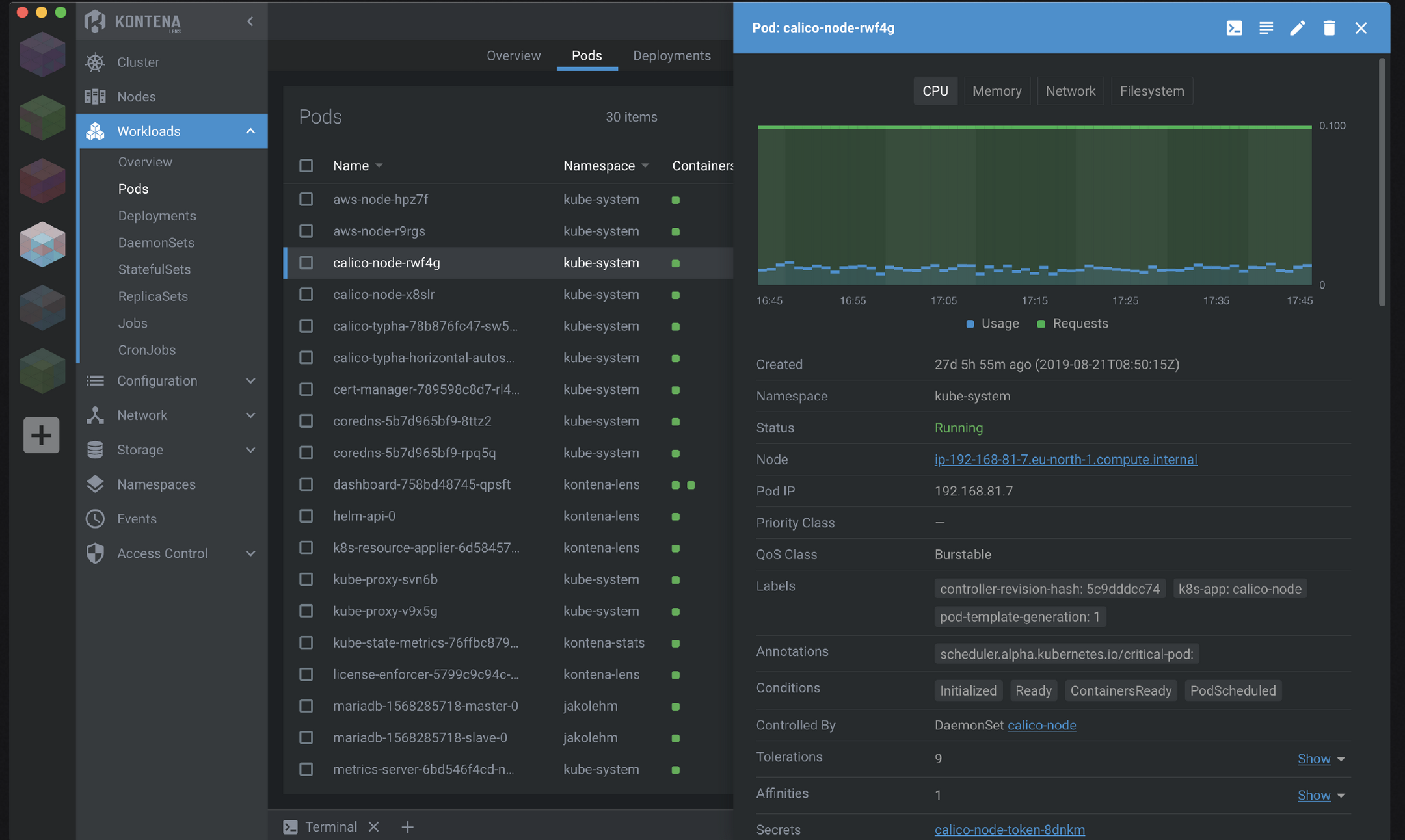
I have been working on the hardware ARM cluster, adding sensors for individual node voltage and current. I've also been evaluating battery backup boards. I'm rebuilding the cluster with the most recent Ubuntu 20.10 images - because of the improved kernel support there. I did some memory upgrades in my x86_64 nodes. One of the interesting tools I have come across is Lens - incredibly useful for x86_64 - also capable of use with the ARM64 cluster - however that becomes problematic if you use the built-in charts that are not ARM64 aware.
![]()
-
postgreSQL, deployed. On microk8s.
11/27/2020 at 09:03 • 0 commentsbash-4.2$ pgo test posty -n pgo
cluster : posty
Services
primary (10.152.183.104:5432): UP
Instances
primary (posty-854bcfb79f-xd2s7): UP
bash-4.2$ -
Persistent Volume strategies for BareMetal
11/27/2020 at 06:44 • 0 comments1. Pin the tail on the Donkey. Manual PVC placement to a specific PV
The storageClass declaration
--- kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: db-storage provisioner: kubernetes.io/no-provisioner reclaimPolicy: Retain # must use WaitForFirstConsumer to enable topology-aware scheduling, won't bind PVS until a pod using it is scheduled volumeBindingMode: WaitForFirstConsumerA brief explanation of the sc is:
provisioner - none. Well, actually its a protein-robot (you) provisioner.
reclaimPolicy - There are others, this one is appropriate for persisting things like databases.
volumeBindingMode - This is key for the method. The PV will WaitForFirstConsumer.The Persistent Volume declaration
--- apiVersion: v1 kind: PersistentVolume metadata: name: PVname spec: capacity: storage: 1Gi volumeMode: Filesystem accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Retain claimRef: namespace: "" name: "" storageClassName: db-storage local: path: /mnt/pv1 nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - <FQDN-dns-hostname>Design:
The idea is to create a valid PV object and have it associated with a specific node where the storage exists. Once deployed, the two items with empty quotes not appear when you edit the pv. claimRef will be "claimRef: {}". Once you have the PVC name and namespace (found in the waiting pod's describe output), edit the pv object ( kubectl edit pv PVname ) and add those two back with the namespace name and PVCname found waiting ( kubectl get pvc -n namespace-name ).A brief explanation for the pv:
PVname - I like to use a name that indicates the size of the physical storage.
accessModes - This means only one node can directly write to the storage, not a shared storage in that sense.
persistentVolumeReclaimPolicy - this provides some persistence guarantee.
claimRef - described above.
storageClassName - is chosen to obtain the desired volumeBindingMode.
path - the actual path on the host. Should be in /etc/fstab and mount at boot.
nodeAffinity - this section associates the physical storage to a specific node/host. Look at a node describe to find the specific string inkubernetes.io/hostname
-
A flower, by any other name ...
11/27/2020 at 05:55 • 0 commentsAbout namespaces and namespace use
I wanna give some unsolicited advice.
Don't use the default namespace. Just don't.
There are reasons.Namespaces are fundamental to how kubernetes is designed and the implied behaviour of the objects used in kubernetes. The term default will not serve you in the context (pun intended) of designing kubernetes clusters.
There are two basic types of object states in this regard - namespaced and Non-namespaced. The implied design is that objects in the default namespace - are NOT namespaced. This has many implications to security and other unpleasant topics.
A good motivation for using namespaces is that you can clean up failed complex deployments easily by just deleting the namespace used for that deployment. This allows rapid iteration after the usual typo is found and corrected.
So there. I said it. Learn how to use namespaces and never, ever use the default.
It is possible to overuse namespaces. Again, there are implications. For each namespace created, there is duplication of objects for etcd. Remember - the essential concept is that you get a virtual, standalone cluster in that namespace. And that has consequences that should be considered in kubernetes architecture design and deployment.
-
Going hybrid - Microk8s with arm64 + x86_64
11/26/2020 at 02:15 • 0 commentsTo create meaningful application stacks - there will be many containers involved. arm64 containers are more the exception than the rule for what is immediately available for certain high-quality components. This means that the first problem to solve in a hybrid cluster is providing hints to the scheduler to select the correct node ( x86_64 or ARM64 ) for a container to properly run when a pod deploys.
This problem was described well in this excellent blog on building Microk8s clusters
The author mentions many of my motivations for building a home k8 lab and introduces the first major issue to be resolved. The use of nodeSelector is described well in that blog, so I won't repeat that here. The important take-away is this code fragment:
nodeSelector: kubernetes.io/arch: amd64The optimal approach is to modify the deployment files before they are applied. Adding this simple code fragment will have the pod deployment schedule on a x86_64 node.
Unfortunately it can be time consuming to convert an existing deployment package to include this fragment - for the pod deployments that end up pulling containers that are not otherwise labeled amd64. Unless you study all containers pulled for a pod to carefully select arm64 replacements - the assumption should be there will be ephemeral containers that will only run on x86_64.
The approach I have been taking is to edit the deployments, after they have been applied to provide a hint to the scheduler and then kill the pods that had been scheduled on arm64 nodes. When the pod get rescheduled - the hint gets the pod over to the x86_64 nodes for execution.
The first complex effort I've attempted is to deploy postgresql in a HA configuration. I may eventually find a way to get the workload moved over to arm64, but not today. I recently deployed the PostgreSQL Operator for a client and was stunned at how easy it made deploying HA postgresql.
To obtain the x86_64 nodes I pulled a Dell OptiPlex960 from the garage ( 2 cores and 4G mem ) and a 17" MacBookPro running parallels ( 3 cores / 6G mem ) and installed Ubuntu 20.04.1 server. This provides adequate resources to run a performant HA deployment with local hostpath provisioning. Persistent storage becomes another wrinkle, as we soon find out.
I deployed the 4.4.1 version and then patched the deployments to schedule on the two new nodes - Wendy (OptiPlex960) and Clyde (MacBookPro).
Hybrid cluster storage
The Operator uses hostpath-provisioner to obtain Persistent Volumes (PV) to satisfy required Persistent Volume Claims (PVC). By default this container is pulled:
https://hub.docker.com/r/cdkbot/hostpath-provisioner
And of course - that is a x86_64 only container - and isn't written to accomodate hybrid cluster resources. Hostpath-provisioner needs two variant deployments to work properly in the hybrid cluster.
Reviewing the cdkbot repository - we find there are CHOICES.
https://hub.docker.com/r/cdkbot/hostpath-provisioner-arm64/tags
But it pays to check the tags CAREFULLY. Note this repository has a LATEST tag that is two years old, while the 1.0.0 tag is only a year old. Setting the tag to LATEST by default is a good way to end up with a drinking problem.
And same issue for the amd64 variant of that container.
https://hub.docker.com/r/cdkbot/hostpath-provisioner-amd64/tags
This provides a path for creating ARCH-aware hostpath deployments so hostpath-provisioner doesn't end up putting the PVC on the wrong storage.
There is more nuance to setting up for the storage behavior needed. In my case for the PostgreSQL Operator, I need to modify the deployment to not use hostpath-provisioner. Instead, I have large partitions already created on Wendy and Clyde that I can deploy as generic PV set and then patch them (kubectl edit pv) to be claimed by a specific pod so I get the placement I desire.
I'm still working on getting this deploy finished. I'll cover more nuances of k8 storage in my next log.
-
FTDI-4232 is replaced.
11/19/2020 at 03:43 • 0 commentsSo the marvelous 4-port serial "thats gonna save ports" solution has a wrinkle on Linux.
ov 14 22:11:14 K8Console kernel: [ 377.599525] usb 1-1.2: new high-speed USB device number 12 using dwc_otg Nov 14 22:11:14 K8Console kernel: [ 377.730456] usb 1-1.2: New USB device found, idVendor=0403, idProduct=6011, bcdDevice= 8.00 Nov 14 22:11:14 K8Console kernel: [ 377.730476] usb 1-1.2: New USB device strings: Mfr=1, Product=2, SerialNumber=0 Nov 14 22:11:14 K8Console kernel: [ 377.730490] usb 1-1.2: Product: Quad RS232-HS Nov 14 22:11:14 K8Console kernel: [ 377.730504] usb 1-1.2: Manufacturer: FTDI Nov 14 22:11:14 K8Console kernel: [ 377.731748] ftdi_sio 1-1.2:1.0: FTDI USB Serial Device converter detected Nov 14 22:11:14 K8Console kernel: [ 377.731933] usb 1-1.2: Detected FT4232H Nov 14 22:11:14 K8Console kernel: [ 377.732489] usb 1-1.2: FTDI USB Serial Device converter now attached to ttyUSB1 Nov 14 22:11:14 K8Console kernel: [ 377.733237] ftdi_sio 1-1.2:1.1: FTDI USB Serial Device converter detected Nov 14 22:11:14 K8Console kernel: [ 377.733394] usb 1-1.2: Detected FT4232H Nov 14 22:11:14 K8Console kernel: [ 377.733876] usb 1-1.2: FTDI USB Serial Device converter now attached to ttyUSB2 Nov 14 22:11:14 K8Console kernel: [ 377.734550] ftdi_sio 1-1.2:1.2: FTDI USB Serial Device converter detected Nov 14 22:11:14 K8Console kernel: [ 377.734732] usb 1-1.2: Detected FT4232H Nov 14 22:11:14 K8Console kernel: [ 377.735219] usb 1-1.2: FTDI USB Serial Device converter now attached to ttyUSB3 Nov 14 22:11:14 K8Console kernel: [ 377.735883] ftdi_sio 1-1.2:1.3: FTDI USB Serial Device converter detected Nov 14 22:11:14 K8Console kernel: [ 377.736046] usb 1-1.2: Detected FT4232H Nov 14 22:11:14 K8Console kernel: [ 377.736570] usb 1-1.2: FTDI USB Serial Device converter now attached to ttyUSB4 Nov 14 22:11:14 K8Console mtp-probe: checking bus 1, device 12: "/sys/devices/platform/soc/3f980000.usb/usb1/1-1/1-1.2" Nov 14 22:11:14 K8Console mtp-probe: bus: 1, device: 12 was not an MTP device Nov 14 22:11:14 K8Console mtp-probe: checking bus 1, device 12: "/sys/devices/platform/soc/3f980000.usb/usb1/1-1/1-1.2" Nov 14 22:11:14 K8Console mtp-probe: bus: 1, device: 12 was not an MTP device Nov 14 22:11:15 K8Console kernel: [ 379.356674] usb 1-1.2: USB disconnect, device number 12 Nov 14 22:11:15 K8Console kernel: [ 379.357691] ftdi_sio ttyUSB1: FTDI USB Serial Device converter now disconnected from ttyUSB1 Nov 14 22:11:15 K8Console kernel: [ 379.357838] ftdi_sio 1-1.2:1.0: device disconnected Nov 14 22:11:15 K8Console kernel: [ 379.358956] ftdi_sio ttyUSB2: FTDI USB Serial Device converter now disconnected from ttyUSB2 Nov 14 22:11:15 K8Console kernel: [ 379.359084] ftdi_sio 1-1.2:1.1: device disconnected Nov 14 22:11:15 K8Console kernel: [ 379.367419] ftdi_sio ttyUSB3: FTDI USB Serial Device converter now disconnected from ttyUSB3 Nov 14 22:11:15 K8Console kernel: [ 379.367576] ftdi_sio 1-1.2:1.2: device disconnected Nov 14 22:11:15 K8Console kernel: [ 379.368846] ftdi_sio ttyUSB4: FTDI USB Serial Device converter now disconnected from ttyUSB4 Nov 14 22:11:15 K8Console kernel: [ 379.368990] ftdi_sio 1-1.2:1.3: device disconnected Nov 14 22:12:09 K8Console kernel: [ 432.915225] usb 1-1.2: new high-speed USB device number 13 using dwc_otg Nov 14 22:12:09 K8Console kernel: [ 433.046149] usb 1-1.2: New USB device found, idVendor=0403, idProduct=6011, bcdDevice= 8.00 Nov 14 22:12:09 K8Console kernel: [ 433.046171] usb 1-1.2: New USB device strings: Mfr=1, Product=2, SerialNumber=0 Nov 14 22:12:09 K8Console kernel: [ 433.046186] usb 1-1.2: Product: Quad RS232-HS Nov 14 22:12:09 K8Console kernel: [ 433.046200] usb 1-1.2: Manufacturer: FTDI
I have replaced the quad port adapter with 4 CP2102 on a 4-port USB hub. Now the consoles are stable. Every time the device reset, I lost 4 consoles.
I'm working on some ideas for the hardware as well as the software stack.
Hardware -
1. LiPo backup for two of the core nodes. I'm considering implementing etcd and two nodes on battery should allow some resilience.
2. Adding intake fan seizure detection. The fans I selected to provide direct cooling have a third wire that allows detecting a problem on the management Pi and have open-collector output that can interface directly to the GPIO pins.
3. Stickers. For the un-painted box. I have nginx, Log-dna (even tho that didn't go well ) ... but must obtain others. A Postgres sticker would probably secure its place in the stack.
Software -
1. Fluent-bit for logging. I've already deployed the daemonset - but my elasticsearch server is down ( sad face ). There is a presentation at KubeCon tomorrow on a Fluent-bit/PostgreSQL stack that sounds interesting. I've recently used the Crunchy Postgres operator and I'd really like to run it in this cluster. Like Sybok, you can let an operator take away the database pain. Elasticsearch is (in practice) something you endure more than use.
-
SodoSopa cluster development
10/27/2020 at 06:52 • 0 commentsSodoSopa is where the Elasticsearch stack lives. It will grow into additional nodes ( maybe ) That cluster is going to be arm64. However stacking isn't going exactly swell.
Kibana isn't entirely with the arm64 thing yet. And to process logs - you need a thingy called Beats. FileBeats, specifically for logs. And that isn't available in non x86 persuasions. So that part actually has become the first hard x86 requirement. This is so I can stop cussing every time I grab an amd64 distribution because I haven't cleaned my glasses and find there a blocker for knuckle dragging this forward. I can fake it for a while with a VM on my mac. I'll have to get a NUC to have a x86 node. Something AMD with cores would be ideal ... but the ghost of labs past has me build low power anymore. I can put this on a UPS and run for a long time ( We have these power outages where I am, usually when the wind blows ) but even just one x86 host would likely cut that time in half or less.
Elastic.co has some commitment to ARM - and it was going pretty swell there for awhile until I hit the Beats issue. I ran into Beats in a past job. I didn't know what it was or why it was creating a problem with the tool I supported. It seemed no one knew. Knowledge hole filled - hardware requirement created.
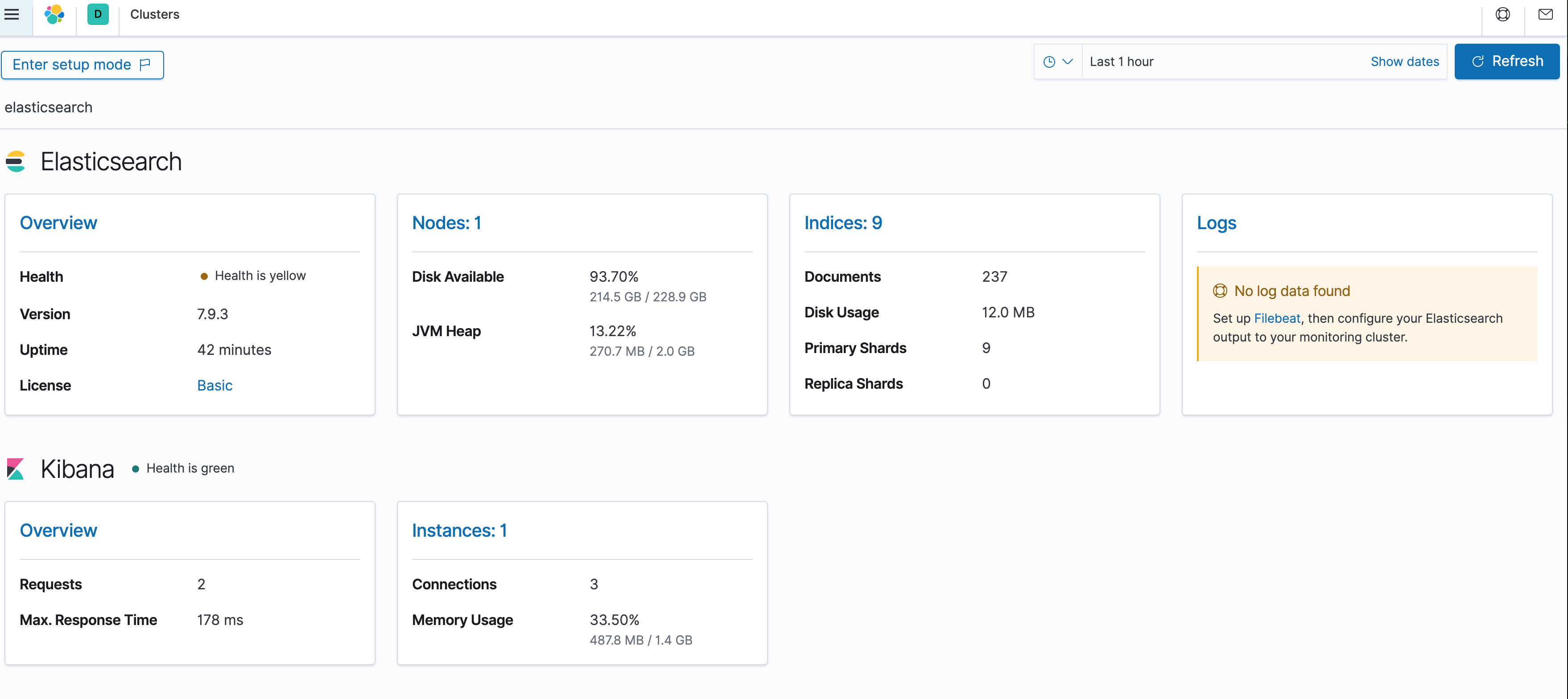
So this is the dashboard, for the thing -
![]()
SodoSopa seems to need a Shi Tpa Town (x86 land) to do some things for now.
Looking at the Github repo - https://github.com/elastic/beats/issues/9442
There is a work-around there that could run on the K8console Pi. But I'd rather not run it on a armhf kernel. Lots of folks working on the ARM bits.
Aha!
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.9.3-linux-arm64.tar.gzA bit of configuration and I have the Beat thingy connected to Elasticsearch.
There is also a metricbeat thingywget https://artifacts.elastic.co/downloads/beats/metricbeat/metricbeat-7.9.3-linux-arm64.tar.gz -
EFK stack install
10/25/2020 at 06:29 • 0 commentsKyle - Pi 4b/8G NVMe
Stan - Pi 4b/8G NVMe
Cartman - Pi 4b/8G NVMe
Kenny - Pi 4b/8G 500G 7200rpm spinning rust
Butters - Pi 4b/8G 500G Crucial flash sata
A console node for serial ports - Pi 3b+
K8console - Pi 3B+ MicroSD
Now there is a need for log aggregation. This design will use Fluentd on the OS and Fluent-bit on the microk8s cluster. The log destination will be to a Elasticsearch node with Kibana installed.
Installed another Pi 4 / 4G with the new Ubuntu 20.10 64 bit release ( no desktop). This release does not require the MicroSD card to boot - so I've used a SATA flash disk here.
Adding this new node that runs Elasticsearch and Kibana.
Ike - Pi 4b/4G 240G Crucial flash sata
-
What to do?
10/22/2020 at 04:39 • 0 commentsOne o'clock, two o'clock, three o'clock, four o'clock chimes
Dandelions don't care about the time
Most of the blogs that have you deploy microk8s may have the final step as just getting a dashboard. There seems to be this tendency to avoid configuring ingress. And then we wonder why folks end up in the weeds.
Microk8s installs with most components disabled. Once you configure a component on a node in a formed cluster - it becomes enabled on all the other nodes of the cluster.
So lets not turn it all on at once.
The first component enabled should be DNS. HA is enabled by default in 1.19 and will activate once three nodes are present in the cluster. Additional nodes are backups to the master quorum of three. Master selection is automatic. If you have network connectivity issues (latency?) you may see some movement of nodes from MASTER to backup. I saw this in my cluster as the original lead node was delegated to backup duty. Surely the reason is in logs, but I haven't set up logging yet to see the reason. I did install fluentd on all the nodes (easy) but I don't have an ELK stack, yet. I'm thinking that perhaps this might be an awesome use for a free LogDNA account. I've used their product before and liked what I could find with it, using rather naive search terms. So look for that as a probable instruction entry.
It is important to stabilize clusters EARLY in their deployment. It becomes harder to debug issues when layers of malfunction are present. I like to see 24-48 hours of runtime after a change to have confidence that my applied idea wasn't a poor life choice. -
All nodes up
10/21/2020 at 15:53 • 0 commentsAll 5 nodes are up now:
ubuntu@kenny:~$ microk8s status microk8s is running high-availability: yes datastore master nodes: 192.168.1.40:19001 192.168.1.41:19001 192.168.1.43:19001 datastore standby nodes: 192.168.1.30:19001 192.168.1.29:19001 addons: enabled: dashboard # The Kubernetes dashboard dns # CoreDNS ha-cluster # Configure high availability on the current node ingress # Ingress controller for external access metrics-server # K8s Metrics Server for API access to service metrics storage # Storage class; allocates storage from host directory disabled: helm # Helm 2 - the package manager for Kubernetes helm3 # Helm 3 - Kubernetes package manager host-access # Allow Pods connecting to Host services smoothly metallb # Loadbalancer for your Kubernetes cluster rbac # Role-Based Access Control for authorisation registry # Private image registry exposed on localhost:32000 ubuntu@kenny:~$ microk8s kubectl get nodes NAME STATUS ROLES AGE VERSION stan Ready <none> 4d10h v1.19.0-34+ff9309c628eb68 kyle Ready <none> 4d9h v1.19.0-34+ff9309c628eb68 cartman Ready <none> 4d9h v1.19.0-34+ff9309c628eb68 kenny Ready <none> 11h v1.19.0-34+ff9309c628eb68 butters Ready <none> 9h v1.19.0-34+ff9309c628eb68One thing that seems odd is the AGE. This seems to be the first boot, as these nodes have been powered down for some hardware assembly. 9 hours is closer to the actual age of this cycle.