Yann Guidon / YGDES
Yann Guidon / YGDES-
PEAC w18
12/29/2025 at 20:08 • 0 commentsThe last log of #miniMAC - Not an Ethernet Transceiver had concluded that the association of two convolutional blocks of different types but complementary characteristics creates an excellent error detector, on top of thorough scrambling. But the use of a gPEAC becomes dubious, it was used for two reasons:
- PEAC w18 is not known for being perfect or maximal
- PEAC w18 has poor mixing, a generalised type is better.
However it was found that
- gPEAC18 uses 2 cycles instead of one, reducing the throughput
- the added NRZ-Hamming preprocessing totally solves the mixing issue
- It is probably not necessary to beeven close to maximal.
So PEAC w18 is back in the race to reduce the latency and gates count. But I realise that I know almost nothing about it !
I looked back at the logs and found quite little.
- 19. Even more orbits ! : primary orbit of 18 : 172.662.654 (instead of 34.359.738.368 to pass, or 0.5%)
- 44. Test jobs : 18: Total of all reachable arcs: 68719736689
- 90. Post-processing : Width=18 Total= 34359868344 vs 34359869438 (missing 1094)
The missing iterations hint at a small "island" that can't be reached from Y=0 and that's a bit worrying.
I don't know the number and sizes of the other orbits. Fortunately I could reuse fusion_20220109.tgz and the logs logs_p7k_03-21.tbz.
- 11 orbits of length 15,696,605
- 198 orbits of length 172,662,655
In practice, it is not plausible to send 15 million words with the same value.
But the nature of the 1094 missing points is still disturbing and I'll have to program it out. And I only have 32GB of RAM at best, so the 67 billion points can't be represented as bytes. I'll have to do with bits. Filling the RAM with the 198+11 orbits should not be a problem since I have their coordinates, then I'll see which bits are untouched. A few kilopoints should not be hard to process then.
-
gPEAC-LEA19
11/29/2025 at 11:04 • 0 commentsThe modulus 741454 is excellent but it can be made more so.
Log 172. Hashing with PEAC39/2 has great info but let's consider something else: the LEAQ opcode on x86-64. This can compute something like x = y + (z×8) + const in a single cycle.
Which is awesome because if we have x using 16 bits, the ×8 does a <<3 and x now gets 19 bits.
In fact 65535×9=589815 < 741454
741454 - 589815 = 151639 > 2^17
So the constant/offset is smaller now and the avalanche is much better because the input will affect the MSB sooner.
There is not even a need to select a prime number since it wouldn't change the orbit length when x=0. A bit pattern like 0x17777 (=96119) works just as well.
-
Discrete PEAC
04/19/2025 at 13:21 • 0 commentsReading old logs, I rediscovered 1. Notes on using a pipelined ALU for frequency division and it appears that I could build a discrete PEAC16×2 using a pair of circuits I have somewhere in stock.
These adders could work in parallel, with a fixed configuration, and though I doubt they could run at the advertised 40MHz, it's fast enough to implement the scrambler of #Not an Ethernet Transceiver.
![]()
I just need to find where I have stored the chips...
Of course a FPGA will be faster and more practical but I know some people still prefer discretes and MSI :-D
-
Stutter
02/11/2025 at 11:38 • 0 commentsPlaying a bit with PEAC w4 :
#include <stdint.h> uint8_t PEAC_XC=1, // the 5-bit part PEAC_Y=0; // 4-bit #include <stdio.h> int main() { int i=0; do { printf("% 3d: % 3d % 3d \n", i, PEAC_XC, PEAC_Y); // split uint8_t PEAC_X = PEAC_XC & 15; PEAC_XC >>= 4; // PEAC scrambler PEAC_XC += PEAC_X + PEAC_Y; PEAC_Y = ( PEAC_X + 0 ) & 15; i++; } while (i <= 136); return 0; }W4 is a maximal, not perfect, orbit so there are "only" 135 iterations. But the output sequence, either PEAC_Y or PEAC_XC, shows that some numbers repeat but only in consecutive pairs
XC Y 0: 1 0 1: 1 1 2: 2 1 3: 3 2 4: 5 3 5: 8 5 6: 13 8 7: 21 13 8: 19 5 9: 9 3 10: 12 9 11: 21 12 12: 18 5 13: 8 2 14: 10 8 15: 18 10 16: 13 2 17: 15 13 18: 28 15 19: 28 12 20: 25 12 21: 22 9 22: 16 6 23: 7 0 24: 7 7 25: 14 7 26: 21 14 27: 20 5 28: 10 4 29: 14 10 30: 24 14 31: 23 8 32: 16 7 33: 8 0 34: 8 8 35: 16 8 36: 9 0 37: 9 9 38: 18 9 39: 12 2 40: 14 12This "stutter" might be a sort of "signature" of a PEAC PRNG, which is why PEAC is better used as a scrambler IMHO.
Now, is this "stutter" a defect ? Not really. On the primary orbit of w4 above,
- the number 2 appears 11 times and "stutters" 2 times.
- 3 appears 9 times and stutters 1×.
- 4 appears 12 times and stutters 1×
So in a maximal (and not perfect) orbit, there are some imbalances.
.
-
Init vectors
02/08/2025 at 14:34 • 0 commentsUntil now I use 0xABCD and 0x4567 to initialise the PEAC16x2 algorithms, but they don't propagate the carries enough. This comes from the fact that even and odd hex digits are "aligned" so there are at least 4 bits that are identical at each position. Ideally : X|Y=1 for each bit position.
One way to solve this is to offset the digits by one position : X=0xBCDE and Y=0x4567
This is slightly better:
>>> hex( 0xABCD | 0x4567 ) '0xefef' >>> hex( 0xBCDE | 0x4567 ) '0xfdff'Time to update all the other references...
-
a POSIXy rand()
02/07/2025 at 18:09 • 0 commentsAfter the last log, here's a first draft of a POSIX-compliant PRNG to replace the dumb congruential generator. The combined period should exceed 2^64 yet no heavy operation (like multiplies or moduli) are used. Of course I should test the quality of the output...
#include <stdint.h> #define RAND_MAX 32767 /* From the spec: If rand() is called before any calls to srand() are made, the same sequence shall be generated as when srand() is first called with a seed value of 1. */ uint32_t rand_LFSR = 1, rand_PEAC_XC = 1; uint16_t rand_PEAC_Y = 0; void srand(unsigned seed) { if (seed) rand_LFSR = seed; else rand_LFSR = 0x89ABCDEFUL; rand_PEAC_XC = seed; rand_PEAC_Y = ~seed & 1; } int rand(void) { // LFSR PRNG : uint32_t t = rand_LFSR & 1; rand_LFSR >>= 1; if (t) rand_LFSR ^= 0x82608EDB; // CRC32 poly // PEAC scrambler : uint16_t rand_X = rand_PEAC_XC; // 16 LSB rand_PEAC_XC = (rand_PEAC_XC >> 16) + rand_X + rand_PEAC_Y; rand_PEAC_Y = rand_X + rand_LFSR; // 16 LSB return rand_PEAC_XC & RAND_MAX; }Let's see how far this one flies.
The first compile and run go smoothly:
[yg@ygrand]$ gcc -Wall -Os -o test_ygrand test_ygrand.c && ./test_ygrand 0000000000000001 0000111011011101 0101100010010100 0100110001001101 0110000110011000 0000110001000000 0000111111001111 0110110100001010 0110001101111111 0100001111011101 0001111011001111 0001111001100110 0101000000111101 0011010111111011 0010100111100101 0111000110110111 0110010010000111 0000000011101101 0011101011001100 0010000000101001 0100110100101110 0110011001110011 ...The PRNG is not even initialised, only using the default value of 1, and it immediately reached a high scrambling state. Calling srand() is a must though, and should call rand() a few times itself for "better results".
Initialising with srand(0) also gives a good-looking sequence with the help of some extra calls to rand().
The Hamming distance between consecutive numbers looks good after 10000000000 iterations. Note that slot 16 is cleared because only 15 bits are provided at each step.
0 : 305938 1 : 4575646 2 : 32047057 3 : 138854426 4 : 416575520 5 : 916453074 6 : 1527396508 7 : 1963876973 8 : 1963793753 9 : 1527393214 10 : 916423856 11 : 416545995 12 : 138835287 13 : 32036947 14 : 4580472 15 : 305334 16 : 0
The peak is well centered around slots 7 and 8, the histogram is nicely symmetrical.
For comparison, I made a "fake PRNG" that pulls data out of /dev/random and here is the histogram:
0 : 305586d 1 : 4579839d 2 : 32047565d 3 : 138857968d 4 : 416545970d 5 : 916470025d 6 : 1527349897d 7 : 1963799989d 8 : 1963842436d 9 : 1527391622d 10 : 916495473d 11 : 416539621d 12 : 138850583d 13 : 32042754d 14 : 4575830d 15 : 304842d 16 : 0d
It's pretty spot on but that's only one of many aspects to check.
___________________________________________________
Update : I fixed the init values so it matches srand(1) after 3 calls to rand().
uint32_t rand_LFSR = 0x61A864DB, rand_PEAC_XC = 0x00015894; uint16_t rand_PEAC_Y = 0xF3B8;I've put the files there ygrand.tgz
-
a rand()... or so.
02/03/2025 at 15:11 • 0 commentsI have recently received inquiries from two projects :
Both are interested by a new/better implementation of the rand() function and it would be beneficial to merge these two requests.
First, I need a good definition of the requirements : size of the state, width of the registers... I'll first try a typical version with two variables, not much larger than the historic implementation (congruential generators have only one register). I suppose that the variable seed must be adapted...
Already, a limitation : POSIX defines rand() as returning an int limited by RAND_MAX>=32767
The <stdlib.h> header shall define the following macros which shall expand to integer constant expressions: {RAND_MAX} Maximum value returned by rand(); at least 32767.On my local installation, /usr/include/stdlib.h says
/* The largest number rand will return (same as INT_MAX). */ #define RAND_MAX 2147483647(Note: yet another reason that POSIX IS DEAD ! You CAN'T know your local size until you test the system, instead of being sure to have a certain width that lets you program comfortably everywhere).
.
Now, the recent libc has more than one function :void srand(unsigned); void srand48(long); void srandom(unsigned); .... int rand(void); int rand_r(unsigned *); long jrand48(unsigned short [3]); long lrand48(void); long mrand48(void); long nrand48(unsigned short [3]); long random(void); double drand48(void); double erand48(unsigned short [3]);So it's a whole crazy mess... and https://pubs.opengroup.org/onlinepubs/9699919799/functions/srand.html adds more mess. But who uses it anyway ?
For TrapC,
We need
- a crypto random for crypto stuff,
- a streaming random for telecom stuff,
- a repeatable random for scientific stuff,
- and a good checksum hash that isn't random for hash tables...
crypto_random_t cr;// for casino real-money gaming packet_random_t sr;// for encrypted streaming transmission pseudo_random_t rr("test 1");// for repeatable A/B testing hash32_t h32("hello world"); hash64_t h64("hello world");And constructors to automatically do the right thing to seed generators. An application programmer doesn't need to know how they work to use them.
.
Let's go back to POSIX.
-
Checksum w16 on 6309
02/02/2025 at 01:02 • 0 commentsMy friend François designed a SBC sporting a Hitachi 6309E, a faster and extended version of the venerable Motorola 6809. Looking at its instruction set table, I find that it has instructions that handle 16 bits at once on the D register (made of the A and B byte accumulators). This is actually pretty suitable for a PEAC16×2 algorithm, which is way better than the xorsum currently used...
But François said :
- the program must use the LEAST number of bytes
- the checksum is reduced down to one byte
- the scanning range can be from one to 2^16 bytes.
PEAC16×2 works with pairs of bytes so the eventual extra odd byte must be handled separately at the end. And there is no notion of alignment, but the 6809 is a Big Endian machine. Since the constraint is placed on the code size and not the speed, the algorithm loop would work on individual bytes, not 16-bit words.
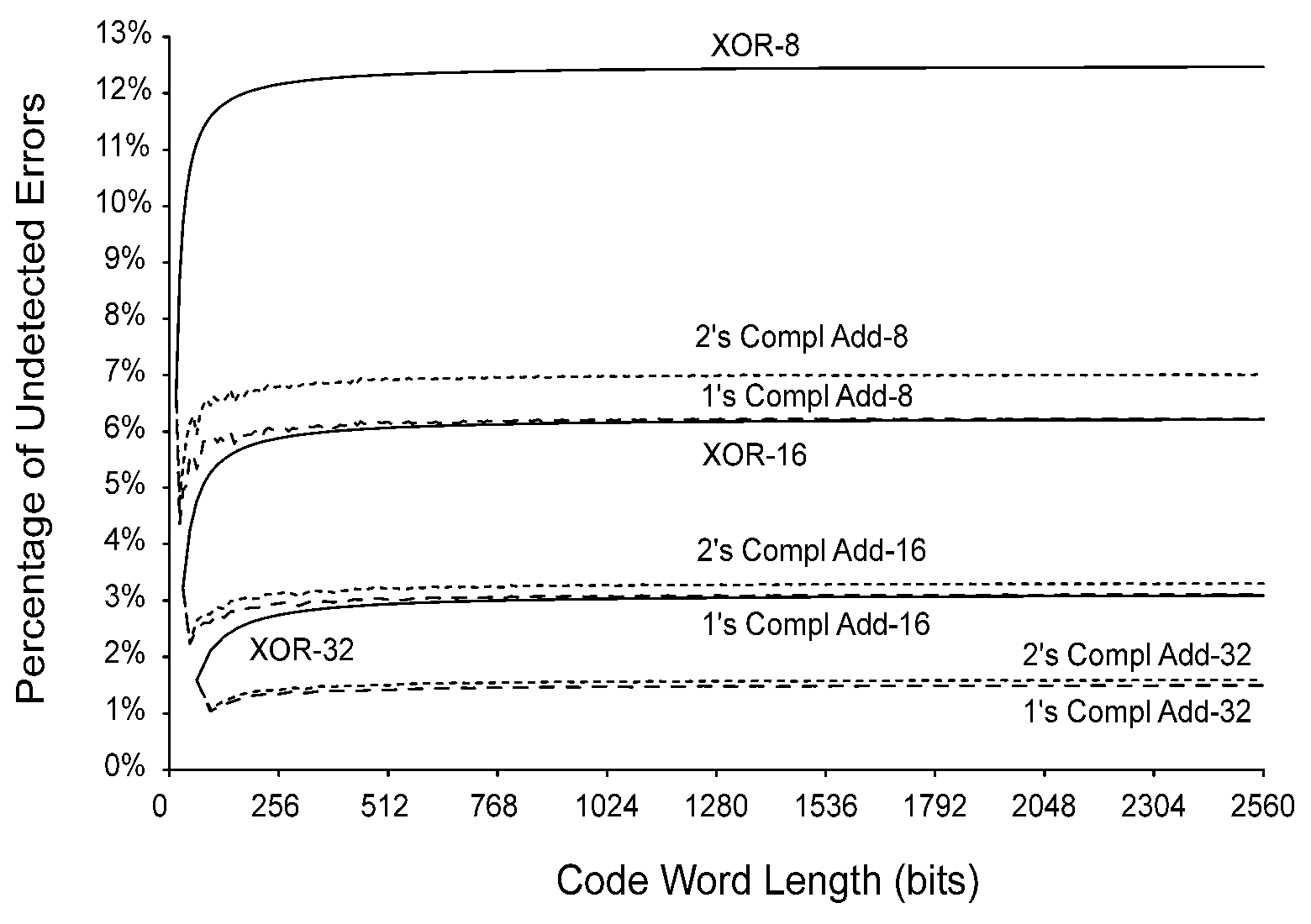
At first look, the algorithm is more complex and larger than xorsum but a first enhancement would replace the xor with add, and reuse the carry: this is not foolproof but requires very little effort to implement.
Replacing xor8 with adc8 divides the error rate by two :
![]()
.
-
PEAC modulo
11/05/2024 at 13:43 • 0 commentsThe log 122. Funky modulo has some funny/funky/hackmemesque observations for lower-level implementations, but what about the higher level ?
It only occured to me today, thinking about gPEAC, that the wraparound of the sum S goes like
S' = (S / m) + (S % m) Not sure how it's going to help with analysing the large-scale behaviour though, it's above my pay grade.
-
Hashing with PEAC39/2
11/04/2024 at 06:02 • 0 commentsLook at the logs
155. More candidates and 741454
156. The good numbers
163. Hash enhancementsThe scan has harvested a very interesting number:
- m= 2^(39/2)-1 = 741454 = 2×7×211×251 = 10110101000001001110b is known perfect, using 20-bit registers.
- orbit = 549.754.775.568 = 111111111111111111100000010100000010000 in binary, takes about 8 minutes to scan.
- offset: o = 0111.11010101.11010101 = 7D5D5h = 513493 = 107×4799
With these parameters, we get a very effective hash algorithm for text strings, 2 bytes at a time (among others). Aside from the PEAC structure itself and its Fibonacci/Pisano scrambling with the addition,
- The modulus is conditional and increases the scrambling by seeding avalanche with 8 more bits,
- The offset is unconditional and increases the avalanche in normal ASCII characters, while also triggering "End Around Carry" much more often than normally with empty input.
TODO
- Check common divisors of 741454 | 513493 : none !
- Check the orbit length of PRNG with offset 513493
For this, the "scanner" must be modified to add the offset, which creates all kinds of ... hmmm algorithmic questions. Fortunately there are two ways to design a checksum with PEAC : single-carry or dual-carry. Single-carry is less parallel but uses a bit fewer operations. It's easy to adapt with the binary PEAC but I realise it's the first time I do this operation on a gPEAC: it's my first gPEAC checksum.
.
.
PEAC Pisano with End-Around Carry algorithm
Add X to Y and Y to X, says the song. And carry on.