glgorman
glgorman-
All that Glitters
10/27/2021 at 11:47 • 0 comments![]()
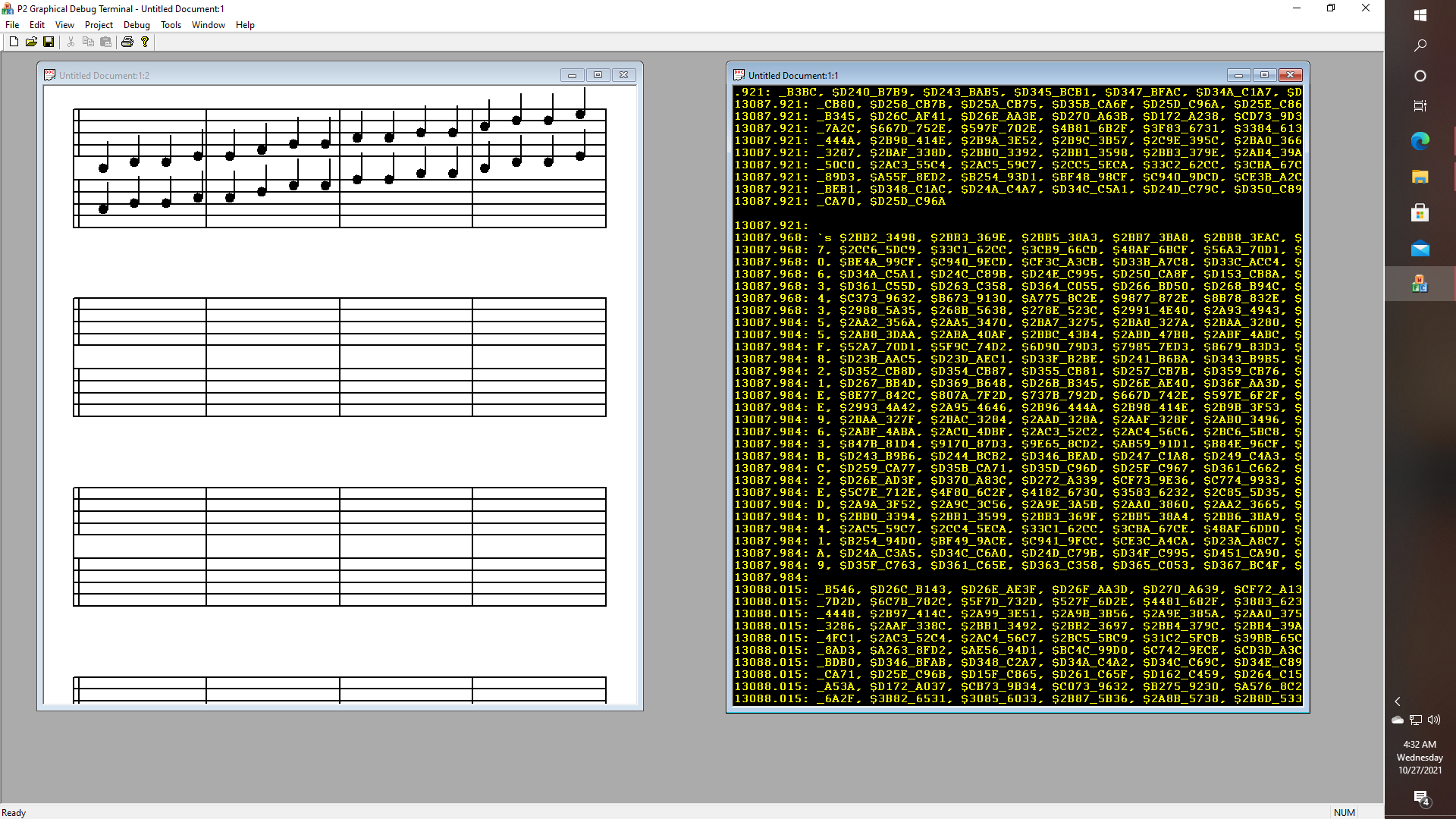
Streaming hexadecimal data from the P2 Eval board which uses multiple DAC and ADC pins to generate various waveforms, which are being converted to analog and back, and then streamed at 2 Mbits/sec over USB to the application, which now has a "sheet music" style display which will be used to take a log-log plot of spectrum analyzer data which will (more or less) pick out any new peaks in each newly rendered frame. Lots of work still remains, like Having BPM detection would be nice, but is not a requirement, as BPM can simply be entered via a menu, so as to be able to get things running. For example, as I demonstrated earlier, I showed how Bohemian Rhapsody has a second harmonic component of the British power line frequency in it at about -60db near the beginning of the song!
Once some of the code that does THAT sort of analysis is properly integrated into the Propeller Debug Terminal, then it will be possible to use the P2 as a real-time audio analyzer, on the one hand, and as whatever else on the other - with an eye toward not just making another oscilloscope (64 channels at 200Mhz for digital signals in logic mode anyone?), but as an eventual platform for a Euro-Rack compatible PC or not-PC based modular synthesizer.
This is of course once again why it would be so nice to have C++, or Object Pascal on the P2 - for "self-hosting" purposes, which is certainly doable, but implementing a GUI in assembly language is not my cup of tea. Much better therefore to simply write a compiler that will be able to generate code that has all of the required features. As mentioned earlier - UCSD Pascal is mostly done, so that when I finish the body part I can look into either implementing a p-machine on the P2, now that I have most of what I need to do floating point, sets, and the various other intrinsic functions (such as mass storage, WRITELN, etc.) that aren't a part of the UCSD distribution, and which need to be written or compiled to native form; whether I end up going the p-code route or entirely native or not.
There is something very interesting that has come out of my digression into porting UCSD pascal, however, and that is something that is going to turn out to be very useful in the long run, no matter what high-level language I eventually use for building more aggressive applications that run directly on the P2 - and that is something that I discovered while porting the WRITELN function, so as to be able to run more of the Pascal compiler code relatively "unmodified", by doing mostly simple find and replace conversion of Pascal keywords to C.
Where that will turn out to be useful will be because although the C language "var_args" function does not pass type information; I was able to implement a proxy class that automatically constructs a "debug_param" object, where I eventually renamed the object's class: "s_param" in order to have a hint of LISP like s-expressions in the type name. Thus, the s_param objects capture type information, allowing WRITELN to in effect be used not just for printing, but for PARSING - for example, streams of English commands like MOVETO, LINETO, or ELLIPSE, such as the commands are spelled out in the Parallax Debug protocol, (or in OpenGL!) so that instead of trying to link the now converted Delphi code against some obscure '386 assembly, rather - why not use a TREESEARCH variant to identify tokens in the debug stream?
Even though I had to implement this myself. since it wasn't in the Pascal distro, it is clear now how the method can be extended (by which WRITELN was implemented) so as to specify which device is to be written to, i.e., by assigning each terminal window its own unique ID, which can be separate from its Microsoft based Window Handle or Window pointer. This would turn the old-fashioned lowly Pascal WRITLEN command into a powerful asynchronous IO pipeline redirector with a built-in command processor. Therefore, solving the problem of de-multiplexing the debug output from the Propeller chip (over USB!) will also allow the creation of programs that can have multiple debug windows, oscilloscope displays, MIDI editors, sheet music, OpenGL, interactive text, and so on - with an eye toward, as I said implementing a full GUI on the P2, or allowing Arduino programs that have multiple windows, and which otherwise work like other "GUI" based applications, even if the GUI part of those "apps" (in the Arduino case anyway) would be running on a PC, Tablet, Bluetooth or WIFI.
Now the Propeller or Arduino will actually do "something", and not just sit there and blink.
-
Always Play Bach
10/26/2021 at 05:32 • 0 comments![]()
If you have never seen the videos on YouTube about "Pachelbel Rant" and how almost every pop song ever written just might be based on "Pachelbel's Cannon in D" - please search for it and check it out NOW, and while you are at it - check out another group that claims that if you can "learn to play just four chords" you can crank out every pop hit from the last 40 years and that one is by a group that calls themselves "Axis of Awesome" and you can find their variations of the "Axis of Awesome Four Chord Song" also on YouTube.
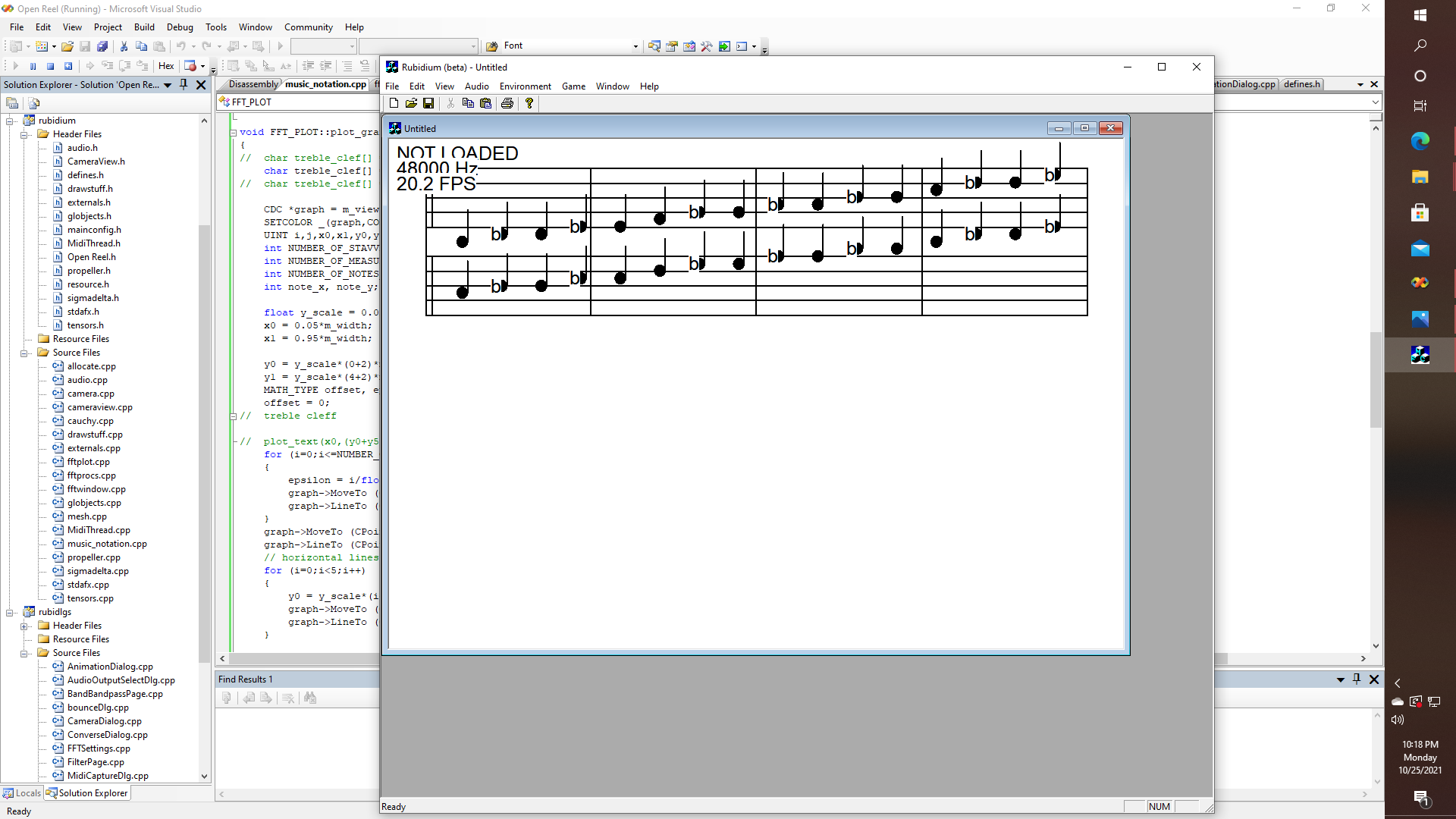
I have my own theory of course, that nearly every rock song ever written can be improvised from J.S. Bach's "Fugue in G"., which is a truly wonderful piece, and eventually, I will be uploading "something" or another to YouTube demonstrating some live "audio in and sheet music out" capabilities either running entirely on the parallax propeller P2 chip, including VGA/HDMI generated on-chip; or else (and initially) by just using the propeller in oscilloscope mode, while running the spectrum analyzer software on a PC connected via USB., but of course, I had to throw together "some kind of sheet music software" that doesn't need 250 Megabytes. Right now this one is using 177 LINES of C++, and even though we don't have C++ yet on the Propeller P2, as long as I avoid polymorphism, multiple inheritances, C++ exceptions, etc., and try to stick to things that work well with structs, namespaces, and MoveTo and LineTo style drawing - this is very doable.
Also, I am adding rudimentary support for actually PRINTING sheet music to the C++ version of Propeller Debug Terminal and will be adding some source code to the repository in GitHub very shortly. In the meantime, you might want to check out the "music_notation_test.pdf" upload that I am putting in with the files on this site, i.e...., as a part of the proof of concept. Object Pascal for the Propeller would also be a good way to pull all of this together; whether based on UCSD Pascal, or whether based on Lazarus, either would serve as a very nice way to get a GUI up and running with some real workhorse software - so that is how all of this is going to come together.
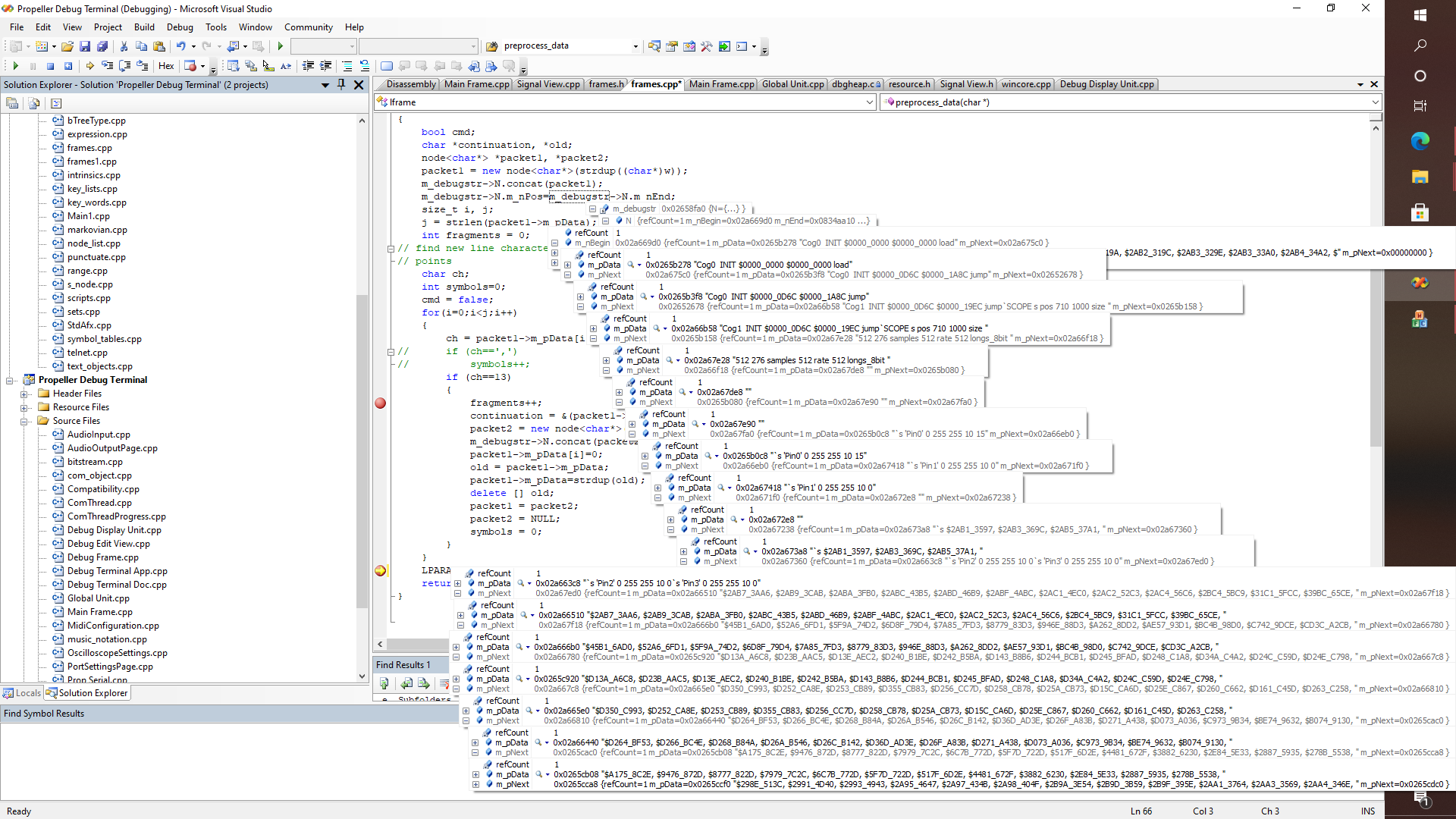
In any case, perhaps this would be a good time to dig into some of the internals of how the data stream decoding/parsing and command processing is going to work, in the various modes that are going to be offered on the PC side of things. Here is a debugging session where we can see how a message from the serial/USB communications object is being generated into the application's "mainFrame" which in turn is in the process of being tokenized.
![]()
This particular function takes strings of characters as they are received and then splits them whenever a line break occurs. If you look carefully, the data stream from the Propeller has a few places where there are some embedded commands like "SCOPE s POS 710 1000 size", followed on the next line (aaargh!) by the parameters "512 276 samples 512 rates 512 longs_8bit ". This is of course what needs to be further parsed out, that is to say, by further tokenizing each string, in order to recognize keywords like "SOCPE" or "ELLIPSE", on the one hand; which I why I have had to implement my own TREESEARCH and symbol table management functions. So that means now that it is a simple matter to fully tokenize each string, and then either allow the original code to process the data by feeding it whatever it needs each time that it makes a call to "NextElement(ele_num)", so that this thing will finally work just like the original Delphi. Pretty simple actually. Still what I want to do, as I have mentioned before, for example, while looking at how the UCSD Pascal compiler works - is to try to express the grammar of the debugging protocol, not with long chains of case statements, which go on for 100's, but not quite 1000's of lines, but rather I want to be able to express Backus-Naur form of the implied grammar with tables of keywords, enums, and function pointers, sort of like how I have figured out how to do with the port of the Pascal compiler. Thus even though the function "IDSEARCH" turned out to be "missing" from the UCSD distribution, I came up with this C++ object that helps move things along nicely, i.e., as far as parsing Pascal programs goes.
struct key_info { ALPHA ID; SYMBOL SY; OPERATOR OP; key_info() { }; key_info(char *STR, SYMBOL _SY, OPERATOR _OP) { strcpy_s(ID,16,STR); SY = _SY; OP = _OP; } }; key_info key_map[] = { key_info("DO",DOSY,NOOP), key_info("WITH",WITHSY,NOOP), key_info("IN",SETSY,INOP), key_info("TO",TOSY,NOOP), key_info("SET",SETSY,NOOP), key_info("DOWNTO",DOWNTOSY,NOOP), key_info("LABEL",LABELSY,NOOP), key_info("PACKED",PACKEDSY,NOOP), key_info("END",ENDSY,NOOP), key_info("CONST",CONSTSY,NOOP), key_info("ARRAY",ARRAYSY,NOOP), key_info("UNTIL",UNTILSY,NOOP), key_info("TYPE",TYPESY,NOOP), key_info("RECORD",RECORDSY,NOOP), key_info("OF",OFSY,NOOP), key_info("VAR",VARSY,NOOP), key_info("FILE",FILESY,NOOP), key_info("THEN",THENSY,NOOP), key_info("PROCSY",PROCSY,NOOP), key_info("PROCEDURE",PROCSY,NOOP), key_info("USES",USESSY,NOOP), key_info("ELSE",ELSESY,NOOP), key_info("FUNCTION",FUNCSY,NOOP), key_info("UNIT",UNITSY,NOOP), key_info("BEGIN",BEGINSY,NOOP), key_info("PROGRAM",PROGSY,NOOP), key_info("INTERFACE",INTERSY,NOOP), key_info("IF",IFSY,NOOP), key_info("SEGMENT",SEPARATSY,NOOP), key_info("IMPLEMENTATION",IMPLESY,NOOP), key_info("CASE",CASESY,NOOP), key_info("FORWARD",FORWARDSY,NOOP), key_info("EXTERNAL",EXTERNLSY,NOOP), key_info("REPEAT",REPEATSY,NOOP), key_info("NOT",NOTSY,NOOP), key_info("OTHERWISE",OTHERSY,NOOP), key_info("WHILE",WHILESY,NOOP), key_info("AND",RELOP,ANDOP), key_info("DIV",MULOP,IDIV), key_info("MOD",MULOP,IMOD), key_info("FOR",FORSY,NOOP), key_info("OR",RELOP,OROP), };Now of course, as stated, in the original UCSD Pascal distribution, they apparently implemented something like this data structure along with the function that uses it in 6502 assembly, which the documentation refers to as MAGIC. Yeah, MAGIC! Great?!! Well, now we know enough to be able to implement an even more generic, and extensible grammar, that can be made to additional things, like maybe translating human-readable OpenGL commands generated using simple print statements into the appropriate function calls, or else defining other types of grammar, that is to say, without having to deeply nested, impossible to debug legacy code, and so on.
-
99 Bottles of Recursive Pascal Beer on Humpty Dumpty's Wall
10/21/2021 at 11:23 • 0 comments![]()
As you probably know time travel is probably impossible, at least for practical purposes, no matter what Calvin Klein says. Neither are you likely to be unbreaking an egg anytime soon, no matter how hard all of the king's horses and all of the king's men may hope for. On the other hand, as far as tricking a C++ compiler into chowing down on Pascal programs with "only" minimal modification; well that one might not nearly be as difficult as inventing time travel or warp drive might actually turn out to be in practice. Now one of the problems with getting a C++ compiler to chow down on Pascal source is the fact that Pascal allows for so-called "nested procedures or functions" which means that PROCEDURE A can have PROCEDURES B and C declared inside A, and also maybe PROCEDURES D and E declared inside A in such a way that A can call B which calls C, which then calls B over and over again recursively, which might be used create a "wall object" and 99 "beer" objects using recursion on the stack (if so desired) through recursion, and then have B or C call A again in a re-entrant fashion so that A can now call procedures D and E, when then operate recursively to pull down some of the bottles and pass them around., at least until an "out of beer exception occurs." Not that you can't do that in C++, but can it be done with DEEPLY nested and mutually recursive functions - and in such a way that when you look at the source code it looks like a Pascal program has been converted to use nested namespaces - which is allowed - just not nested functions. Now let's make it even harder, AND not add any new passed parameters to the original functions, since one of the nice features about Pascal nested procedures, is that the inner nested procedures have access to the outer procedure's local variables, that is to say without having to de-reference any passed pointers, and then otherwise use a WITH statement, (which would be "evil", and which also doesn't exist in C++.
Now to throw another log on the fire, although a template based on 99 bottles of recursive Pascal beer might be useful for implementing fun things like editors with 99 levels of undoing, or Tiny-OS kernels that support up to 99 or more concurrent processes; there are actually even bigger fish to fry.
Even bigger fish to fry? How about the fact that Pascal allows for some very nasty, even though it is not quite Halloween yet, Here is some code that looks like it just might have come straight out of some "sequel that never got made to the Rocky Horror Picture Show" like data structures. Like this one from the Pascal source of UCSD Pascal: (So yeah, "Let's do the time warp again!")
IDENTIFIER = RECORD NAME: ALPHA; LLINK, RLINK: CTP; IDTYPE: STP; NEXT: CTP; CASE KLASS: IDCLASS OF KONST: (VALUES: VALU); FORMALVARS, ACTUALVARS: (VLEV: LEVRANGE; VADDR: ADDRRANGE; CASE BOOLEAN OF TRUE: (PUBLIC: BOOLEAN)); FIELD: (FLDADDR: ADDRRANGE; CASE FISPACKD: BOOLEAN OF TRUE: (FLDRBIT,FLDWIDTH: BITRANGE)); PROC, FUNC: (CASE PFDECKIND: DECLKIND OF SPECIAL: (KEY: INTEGER); STANDARD: (CSPNUM: INTEGER); DECLARED: (PFLEV: LEVRANGE; PFNAME: PROCRANGE; PFSEG: SEGRANGE; CASE PFKIND: IDKIND OF ACTUAL: (LOCALLC: ADDRRANGE; FORWDECL: BOOLEAN; EXTURNAL: BOOLEAN; INSCOPE: BOOLEAN; CASE BOOLEAN OF TRUE: (IMPORTED:BOOLEAN)))); MODULE: (SEGID: INTEGER) END;Now I know why they call it the "Dragon Book", but this is another story. Still, does this mean that the compiler has to use mutually recursive nested functions in order to correctly parse variant record types that themselves might contain a whole zoo of variant sub-records, which themselves contain nested variant records?
In other news, using not much more than "stone knives and bear skins" I have managed to convert about 4000+ lines of UCSD Pascal to C++, while "somehow" finding a way to allow it to at least appear that I am converting some highly nested and potentially mutually recursive procedures into what looks like mutually nested recursion in C++, by using "only" namespaces (and perhaps some snake oil along with the right source of smoke and mirrors in other places like my earlier Pascal style in C++ WRITELN hack).
Don't believe me? Well, it does compile, so far up though, and including the DECLARATIONPART and UNITPART segments. Once BODY is done I will have a compiler that will be able to be run on the Propeller or the Arduino, among other things, maybe even a NOR computer. Check out "declaration1.cpp" if you don't believe it! Warning! Not only is this software "GNU" and without warranty, along with any other applicable restrictions, I can pretty much guarantee that not only does it have bugs, but it probably has a few more bugs that it didn't have when first released in 1979 or thereabouts.
-
Where this train is really going?
10/20/2021 at 11:49 • 0 comments![]()
Pascal running on real Apple II hardware. No big deal. In my all too ample spare time I suppose that I could actually get the PS/2 keyboard to Apple IIe interface working, or I could just simply buy one already made, I think that there are some other people who might still be making them and selling them. Otherwise, a big mess of wires is kind of hard to manage, but not impossible.
![]()
But would be a lot more fun to just simply bite the bullet and try to find a replacement keyboard case for the IIe, and go pure retro - with a genuine Apple II compatible SCSI drive in a beige case + the scarce as hen's teeth Dou Disk floppies? Now as it turns out - I would actually like to be able to access my Pascal stuff from my college days, but it's not a high priority. Now, remember - jealousy is a green monster - but maybe it could be beige, under the right circumstances.
![]()
Of course, if I were to yank the ROMs from the SCSI card - even though the code type is 6502; it might serve as a basis for a very lightweight SCSI driver for Arduino, or Propeller. Not that Linux doesn't have some nice open-source codes that can simply be downloaded and read - but as always - that stuff is too bloated to run on an Arduino or a Propeller.
-
Pocket Full of Zero Days?
10/20/2021 at 11:32 • 0 comments"One of these days everyone is going to know that Clint Eastwood is the biggest Yellow Belly in the West!" Right? So even though "I have a bad feeling about this!", it isn't all that bad, unless it is actually worse. Earlier, while working on the port of UCSD Pascal for the Parallax P2 and other platforms, I came across this mess, in the original Pascal - which I mentioned actually hints at a zero-day issue for many a system. Which of course presents an ethical conundrum, even if this is HACKADAAY, i.e., in terms of "ethical disclosure." Well, in any case here is the offending code:
BEGIN (* INSYMBOL *) IF GETSTMTLEV THEN BEGIN BEGSTMTLEV := STMTLEV; GETSTMTLEV := FALSE END; OP := NOOP; 1: SY := OTHERSY; (* IF NO CASES EXERCISED BLOW UP *) CASE SYMBUFP^[SYMCURSOR] OF '''':STRING; '0','1','2','3','4','5','6','7','8','9': NUMBER; 'A','B','C','D','E','F','G','H','I','J','K','L','M', 'N','O','P','Q','R','S','T','U','V','W','X','Y','Z', 'a','b','c','d','e','f','g','h','i','j','k','l','m', 'n','o','p','q','r','s','t','u','v','w','x','y','z': IDSEARCH(SYMCURSOR,SYMBUFP^); (* MAGIC PROC *) ETC ...Now apart from inefficiency, what harm could there be in an otherwise "harmless little case statement" (insert Monty PYTHON quote here) which has a separate case for every letter of the alphabet, so that it probably compiles to an if then else chain with at least that many branches? Answer: Besides being inefficient in and of itself, on a modern system, this coding style causes the cache lines to flush every single time, so that code that could have been run out of L1 cache might get run out of L2, or maybe L3 if you are lucky, or maybe on some memory starved systems it will trigger a page fault every single time.
Then besides 'nerfing the cache lines; chances are each time through the chain the branch will be taken or not taken at a different point so that the branch predictor on any modern CPU (that has one) will get it wrong - every single time, contributing to further inefficiencies, and therefore so also setting the stage for new, not yet fully imagined MELTDOWN or SPECTRE type attacks; where even if a remote attacker can't steal passwords by analyzing the time to respond to millions of DNS requests over a network - just by listening in to other traffic, i.e., that is by devising a passive packet sniffing strategy that works by putting the "man" in the middle in the form of an otherwise seemingly well-behaved router.
How knows? Maybe they can. Regardless, this still sets the stage for other shady dealings like carefully crafting and DDOS (denial of service), whereby the rogue actor - "the unicorn" is "in the garden" so to speak, even if the DDOS actually gets routed through Torrents, to that it appears to be inseparably co-mingled with legitimate traffic, and that is how someone could, in principle - do a carefully planned DDOS against certain BGP infrastructure - and take down DNS.
Now if just like "Wall Street", the "circuit breakers trip", and the LRU caches flush - well, that is one variation, and thus the "reindeer games" continue.
Now I wasn't going to say anything about this - but - well, maybe I changed my mind after another bad patch Tuesday because of the "big company" with "the small name", on the one hand, and not just because some people still can't FACE the music on the other hand. But now, you know who in the aforementioned has 'nerfed the whole AMD Ryzen line, with some kind of "oops", exposing yet another critical flaw.
Whatever happened to coding standards? Or testing?
P.S. For a good time (or not-so-good time) Google the phrase for a paper published by the Linux Foundation entitled "Vulnerabilities in the Core" if you haven't heard about it already. I found out about it by reading content linked to another article on the HACKADAY Blog.
Mind Boggling! Time travel anyone? Temporal Paradox? Or something else? Like I said, something else ...
-
Microsoft does it again!
10/18/2021 at 21:07 • 0 comments![]()
How many times is this going to happen? Sometimes I lose a whole day or more having to reinstall everything, that is to say when they not only manage to nerf the updates, but they implode the system restore points. Hopefully, they didn't do to much damage this time. Otherwise, UCSD Pascal is getting closer to actually being able to compile programs for the Propeller or maybe for one of those 100Mhz 6502 things, or whatever - so that while a NOR computer would certainly be interesting, an FPGA-based something or another would be more likely.
As expected, the fact that the UCSD compiler has some deeply nested procedures, which because of the nature of the language might also be recursive, does present an interesting challenge - since C/C++ does not allow "local functions" that it otherwise considers illegal. So an interesting question therefore is whether it is even possible to convert some Pascal programs without extensive re-architecting of the overall design of an application, such as by requiring the use of lambdas, or tables of function pointers, (which I like - but not if we don't have that level of sugar coating available for use with microcontrollers - yet) - or adding a passed parameter for frame tracking to each and every function - which is a pain in the ass - as when let's say - procedure A calls nested procedures B and C recursively, as if to implement 99 bottles of beer on the wall on the stack, and then when an "out of beer" exception should occur, either the "pull one down" or "pass it around" functions have to call some other functions, let's call them D and E and F, where E and F are inside of D, which is also inside of A, and then a callback to A might result in - well you get the idea, a fresh call to B or D - and then the compiler has to somehow generate code that preserves the invocation record for the entire call history, so that just in case the latest E wants to access a variable from the most recent B or C, is that even possible? What a mess!
So when I ask is it possible, I mean is it possible to go into a Pascal program and simply use find and replace to replace all of the BEGINs and ENDs with curly braces, and otherwise simply pour a little sugar on where it is needed to deal with WITH statements and the rest - but otherwise leave the body of the Pascal procedures exactly as written, that is to say so that most of the re-write can be done with find and replace in a word processor?
Interestingly enough - it appears that the answer is YES - and that something like this does the trick!
class DECLARATIONPART::USESDECLARATION: public DECLARATIONPART { protected: struct SEGDICT { DCREC DANDC[MAXSEG]; ALPHA SEGNAME[MAXSEG]; int SEGKIND[MAXSEG]; int TEXTADDR[MAXSEG]; int FILLER[128]; }; bool FOUND; int BEGADDR; CTP LCP; LEXSTKREC LLEXSTK; ALPHA LNAME; SYMBOL LSY; OPERATOR LOP; ALPHA LID; protected: USESDECLARATION(bool MAGIC); void GETTEXT(bool &FOUND); };So in the original Pascal source "USESDECLARATION" is a procedure that takes exactly one BOOLEAN parameter called "MAGIC", and then "USESDECLARATION" needs to be able to call a nested function called "GETTEXT" which in turn needs to be able to access some of the local variables that were previously declared in the outer procedure, which of course is being called from another outer procedure called "DECLARATIONPART", and then there are other examples where the mess just might turn out to be as bad, or worse than trying to implement ninety-nine bottles of beer on the wall using recursion for the functions "pull", "pass", "sip", etc., and get a bunch of "customer" objects, "bottle" objects, and others to work nicely with each other - that is until you run out of beer, or diet soda!
So apart from running these posts on popcorn, pizza, and Diet Coke while Windows takes an occasional respite, the approach that I am now taking is to go ahead and continue with trying to devise an even more generic programming route with the design for the APIs that I am eventually going to be running entirely on the Propeller "standalone" - even though we don't have C++ for the Propeller yet - but as stated in an earlier post - if it does indeed appear that technically we don't need floating point, or strings or any data type other than perhaps BYTE or WORD - and yet C++ is powerful enough that with templates, macros, and operator overloading it is actually possible to define REAL. and SETS, and RANGES, and generate a "close to the metal" implementation that should work on any platform - including the so-called "NOR" computer!
Then why not?
void DECLARATIONPART::TYP::FIELDLIST::ALLOCATE(CTP FCP) { bool ONBOUND; ONBOUND=false; // WITH FCP^) { if (PACKABLE(FCP->IDTYPE)) { if ((NUMBITS + NEXTBIT)>BITSPERWD) { DISPL=DISPL + 1; NEXTBIT=0; ONBOUND=true; } FCP->FLDADDR=DISPL; FCP->FISPACKED=true; FCP->FLDWIDTH=NUMBITS; FCP->FLDRBIT=NEXTBIT; NEXTBIT=NEXTBIT + NUMBITS; } else { DISPL=DISPL + ORD(NEXTBIT>0); NEXTBIT=0; ONBOUND=true; FCP->FISPACKED=false; FCP->FLDADDR=DISPL; if (FCP->IDTYPE!=NULL) DISPL=DISPL + FCP->IDTYPE->SIZE; } if (ONBOUND&& (LAST!=NULL)) // WITH LAST^ if (FCP->FISPACKED) if (FCP->FLDRBIT==0) FCP->FISPACKED=false; else if ((FCP->FLDWIDTH<=8)&&(FCP->FLDRBIT<=8)) { FCP->FLDWIDTH=8; FCP->FLDRBIT=8; } } /*ALLOCATE*/So THIS is how the Pascal compiler allocates the data structures needed to handle packed arrays at compile time. Except this is C++ - and it compiles! Stay tuned!
-
Notes on creating an FPU for the NOR computer.
10/16/2021 at 05:16 • 0 commentsEarlier I mentioned throwing some code together where I began implementing a complete ALU for a hypothetical computer that uses only NOR gates, figuring that by working in C/C++ with an eye toward being able to port "whatever seems to work" to system C or even Verilog, then, well, why not? Then I realized of course that since I eventually want to run UCSD Pascal, or perhaps Modula II, or even ADA on the Parallax Propeller 2 - then with a few other code tricks up my sleeve, this could become the basis for turning my Frame Lisp project into a full-fledged compiler. So why not implement floating point, especially if I am going to eventually need it - for whatever this transmogrifies into?
So this is how 32-bit floating point multiplication works, and what IEEE-754 style looks like, even if it isn't fully tested for STRICT compliance with the standard or any standard - but it does seem to work, which is enough for now:
real real::operator * (real arg) { short _sign; real result; short exp1 = this->exp()+arg.exp()-127; unsigned int frac1, frac2, frac3, frac4, fracr; unsigned short s1, s2; unsigned char c1, c2; _sign = this->s^arg.s; frac1 = this->f; frac2 = arg.f; s1 = (frac1>>7); s2 = (frac2>>7); c1 = (frac1&0x7f); c2 = (frac2&0x7f); frac3 = (c1*s2+c2*s1)>>16; frac4 = (s1*s2)>>9; fracr = frac1+frac2+frac3+frac4; if (fracr>0x007FFFFF) { fracr = ((fracr+(1<<23))>>1); exp1++; } result.dw = (fracr&0x007FFFFF)|(exp1<<23)|(_sign<<31); return result; }Oh, what fun! Haven't tried compiling it yet on either the Propeller or for Arduino, but I do know that some versions of the Atmel architecture such as the Mega 2560 series have hardware multiplication at least as far as being able to 8-bit by 8-bit on the chip, so this could get interesting performance wise, let's say when the time comes so as to be able to compare the performance of a 6502 emulator running UCSD p-system Pascal, which itself runs as an emulated 16-bit p-machine running on the 6502 whether real or virtual, vs. whatever the performance might be for floating point if the p-machine were running under direct emulation. I will be putting some code for this up on this site, as well as (eventually) on Git, for anyone who wants to tinker with a greatly simplified calculator example, which is now in the process of getting floating point!!
-
Shall we play a game?
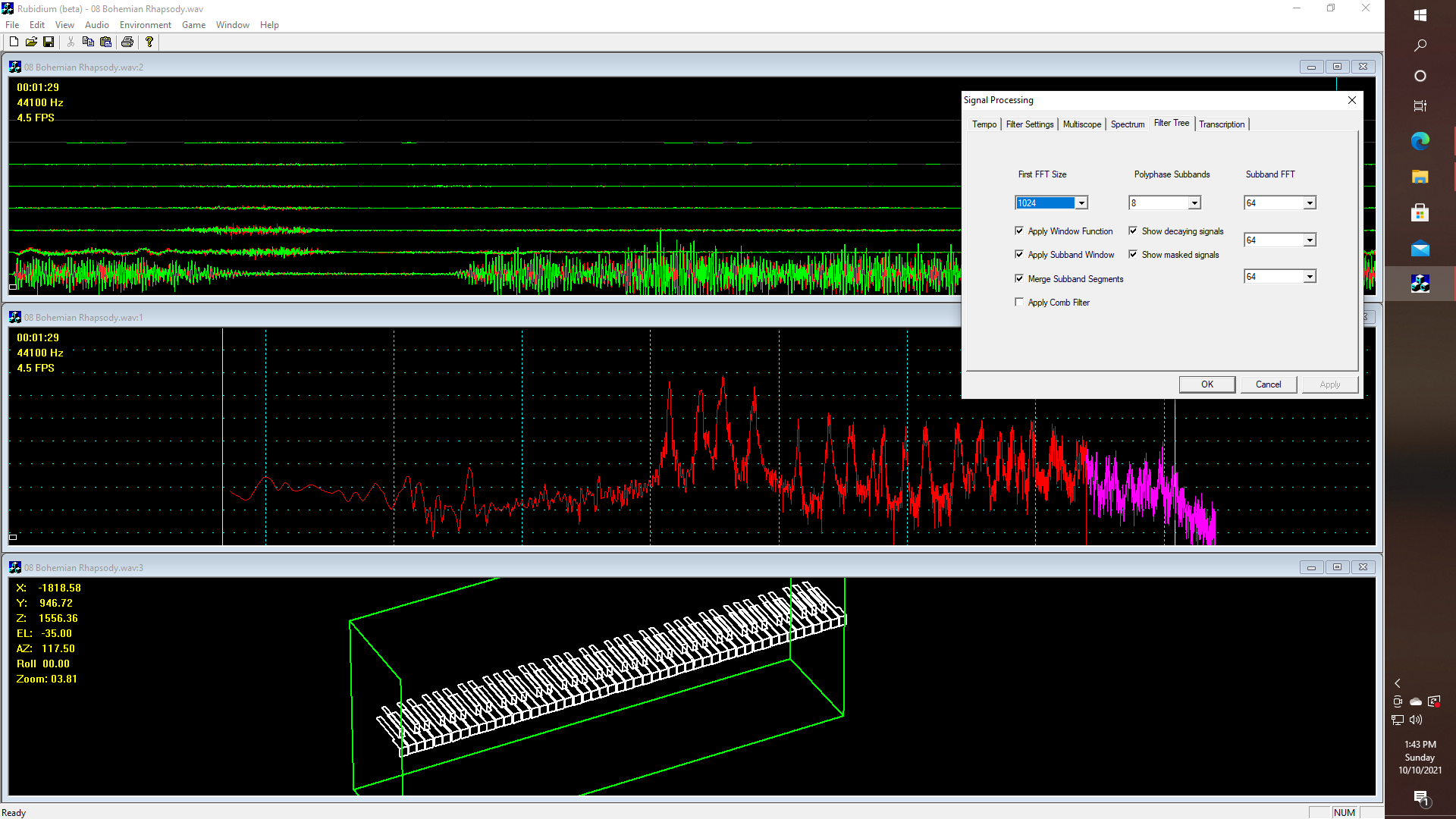
10/10/2021 at 21:13 • 0 commentsI know what you are thinking. As WOPR (pronounced "whopper") said when asked "Is this real or is this a simulation"?" -- What's the difference? Right? What are a few megatons among friends, or former friends? On the other hand, if you have ever run spectrum analyzer software on a song like "Bohemian Rhapsody" let's say, you might have noticed a very prominent second harmonic component of the British power line frequency sticking out prominently at around -60db, that is to say at 100Hz. Wow!! Let's have a look at a screenshot of a processed sample block from the CD:
![]()
Here is what is happening. The yellow vertical lines in the middle window are the upper and lower bounds of the range of notes available on a standard full-size piano, and the minor divisions on the horizontal axis represent semi-tones, i.e.. so that there are 12 divisions per octave based upon a so-called log-log plot of the spectrum. Thus for this image, I am performing an initial 1024-point FFT, whereby I take the output of that first FFT and break up the spectrum into eight blocks of frequencies, as indicated by the dialog box, just like MP3 on the one hand, that uses a "filter bank" to split the spectrum up into 32 sub-bands, which can then be subjected to further processing - such as in separate threads, or according to different algorithms, according to the need for beat and bass line detection, harmonic analysis, etc.
Hence, one of the things that I have found a need for is the creation of a menu that allows me to select different FFT parameterizations, so that I try every possible combination, including ridiculous ones like million-point FFTs that split the spectrum into individual channels which are, whatever - lest say 10Hz wide, if we wanted. Thus what the upper window represents, is in the present case, taking like I said: an initial 1024 point FFT, which is then split up into 8 blocks of frequencies, and then converted back into TIME-DOMAIN signals, resulting in what you see on the top window. Thus that window is running an eight-channel, (actually 16 because of stereo pairs) oscilloscope, that is displaying the output of the aforementioned "poly-phase filter tree", although such an oscilloscope could just as well be used as a "simple" logic analyzer, in the old-fashioned sense.
Now all of this has interesting implications, For example - by taking an audio signal and splitting it into something like 128 (or 256) time domain signals, an initial 44100-hertz sample rate (stereo signal) can be turned into 128-time domain signals where the sample rate for the sub-bands, (works as if we have made a kind of loud-speaker crossover from hell), is 345 Hz since 44100 divided by 128 is 344.53, and this goes a long way toward solving the event detection problem, if one of the things that we want to to is generate MIDI on and MIDI off events on a note by note bases, either as part of an audio in and sheet music out kind of system, or audio in and then possibly drive a piano with light-up keys, (if you have one or want to build one). or else if you wanted an application with light-up keys, and a piano on the screen - maybe that would be an ideal project for Android or as a WebGL-based application for general use. But first, we need to create the right metadata so that we can stream it, if at the end that is what we are most likely to want to do.
Then there is the issue of speech recognition. Now I know that there are several "bots" on this forum that use Google speech, or Apple speech, and yet you still can't say "OK Google - take dictation", and why not? Besides that, do you really want to let Google listen to everything you say and do, with no accountability, that is to say - NO why what so ever so as to be able to "look under the hood" and ask "just how much data is being processed locally on the device" before a query goes out the to cloud. And then what if there is an Internet outage, or a certain major provider of services starts facing other configuration issues, that affect service availability?
I don't own a farm. I am not trying to convert a John Deere tractor to propane, but I do believe should that I have the right to do so I if wanted to, or run my tractor on natural gas that matter, if I wanted to do that.
When will they ever learn? Oh, but wait - there is something else I should mention since I did mention games.
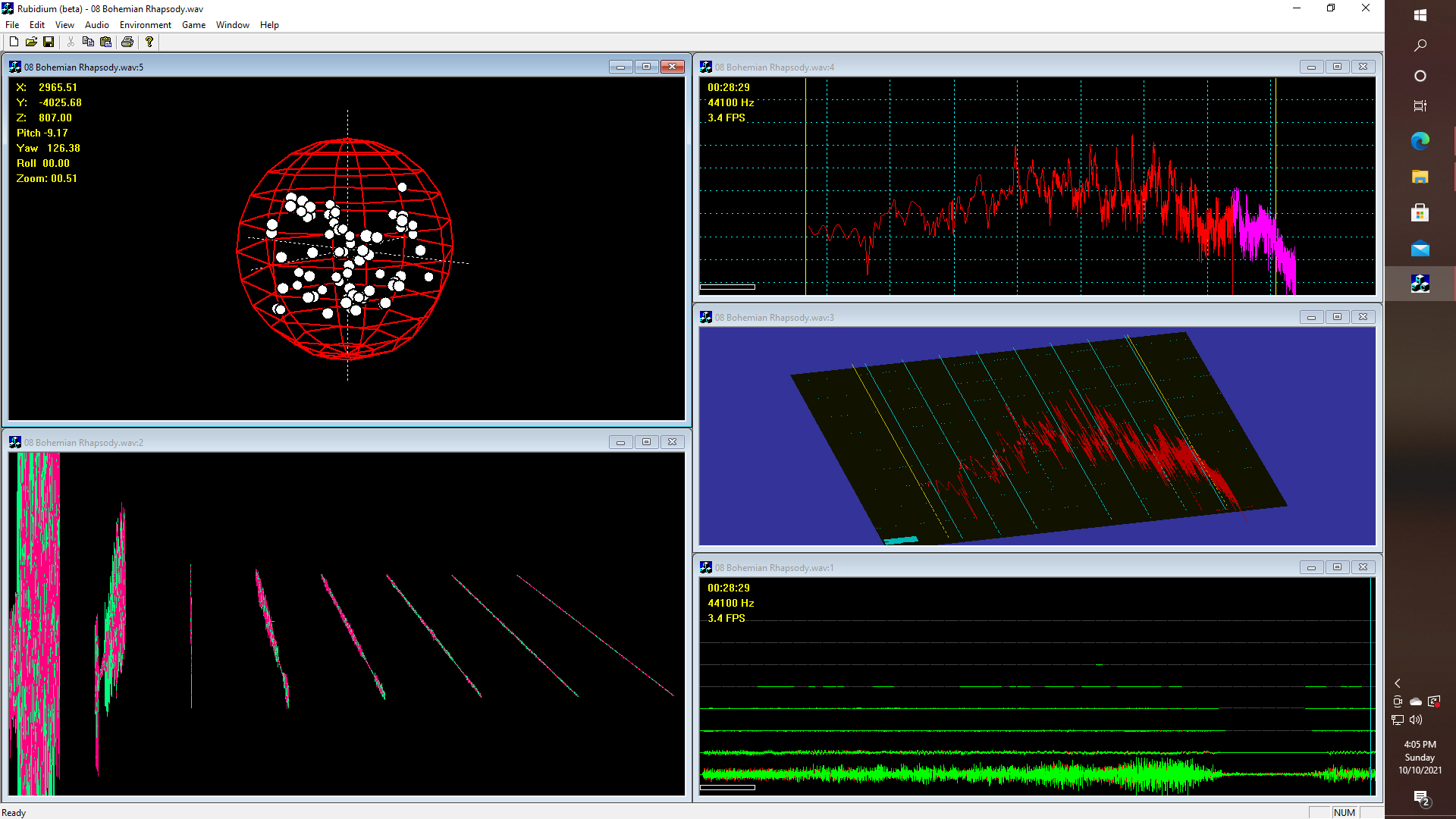
![]()
Now, what might this be? Well, think about what just sort of happens if you decide to run an oscilloscope or a spectrum analyzer view in an open-GL stack, even though an oscilloscope doesn't really NEED 3-D. Maybe it does. If we create 128 logarithmically based sub-bands, additionally take the waveforms and compute the logarithm of the power per sub-band, and then pass that data through a threshold function, then we could display the data in the form of some interesting shape - such as warping note data onto the surface of a sphere, or how about an animated piano-roll like display?
Now imagine drawing a simple piano, or perhaps even a player piano, where you can see inside where if you know how old-fashioned player pianos work - where there is this glass window so that you can see how the player piano music is on a roll so that the piano roll goes over some kind of cylindrical thing with holes, and that is how the system controls a bunch of air operated actuators that drive the keys! Maybe it would be much easier to try a simple "Star Wars (TM)" type of effect, which is easy to do by just setting the camera position. But warping music onto a sphere is pretty silly, and yet on the other hand, I don't know (haven't checked yet ) if "Guitar Hero" is still patented, so for now this demo is STRICTLY FOR RESEARCH AND EDUCATIONAL PURPOSES.
Right now, I need to finish the Propeller Debug terminal, and possibly add an OpenGL stack to the C++ version, which would allow anyone to run "processing style" calls on the Propeller while having the graphics rendered on a connected PC or tablet. Eventually, this would allow audio in, sheet music out type applications, and open source speech recognition applications to run on the Propeller with no PC required. Still, I think what people are going to want is to be able to plug some kind of hardware device into their DJ rig or their MIDI instruments, or both, and have real-time control over all kinds of new modular fun synth stuff, via a phone or tablet, such as over Blue tooth or WiFi.
-
How this all adds up.
10/08/2021 at 11:37 • 0 commentsO.K., that's not what this log entry is about either; but it does seem relevant. Would you prefer "Where this train is really headed? And is the light at the end of the tunnel another oncoming train?" I do try however to begin every log entry with a catchy title. In any case, I threw together a quick example in C++ of how to implement a function table, which is also better described as a "table of function pointers" which can be used, as in the example I am about to discuss as a part of a simple programmable calculator application, or the techniques can be applied in such a way as to make for a very elegant emulator for any CPU platform, or else this is how we finally will be routing commands from the debug stream to the appropriate oscilloscope, debugging, or interactive windows in the Propeller Debug Terminal, and it is also a very useful technique for compiler writing, as we will see later on.
#define PI (3.14159265358979323) typedef enum { add=0, sub=1, mult=2, divi=3, } opcode; typedef double (*ftable[])(const double&, const double&); class calculator { protected: double reg[16]; static double (*ftab[4])(const double&, const double&); static double fadd(const double &, const double &); static double fsub(const double &, const double &); static double fmult(const double &, const double &); static double fdiv(const double &, const double &); public: static double exec(opcode, const double &arg1, const double &arag2); static int main(); };It looks simple enough, with lots of static member functions that do all of the heavy lifting for us, along with a "set of registers" that some other functions, which are not provided in this example might use to implement a complete calculator. Now let's look at the functions, that we do have:
#include "stdafx.h" #include "calculator_test.h" ftable calculator::ftab = { &calculator::fadd, &calculator::fsub, &calculator::fmult, &calculator::fdiv, }; double calculator::fadd(const double &arg1, const double &arg2) { double result; result = arg1+arg2; return result; } double calculator::fsub(const double &arg1, const double &arg2) { double result; result = arg1-arg2; return result; } double calculator::fmult(const double &arg1, const double &arg2) { double result; result = arg1*arg2; return result; } double calculator::fdiv(const double &arg1, const double &arg2) { double result; result = arg1/arg2; return result; } double calculator::exec(opcode op, const double &arg1, const double &arg2) { double result; result = (ftab[op])(arg1,arg2); return result; } int calculator::main() { double val1, val2; val1 = exec(mult,2,PI); val2 = exec(mult,exec(add,3,4),exec(add,4,6)); return 0; }Now if you have never seen anything like this before, what typedef enum { add=0, sub=1, mult=2, divi=3, } opcode and typedef double (*ftable[])(const double&, const double&) do is exactly as described, they create a new type of variable that we will call an "opcode", and then another type of variable that we are going to use later to map opcodes onto specific functions, and thus what the "executive" does is to (when presented with an opcode and appropriate parameters) -- look up the function that is responsible for carrying out the operation described by that particular opcode or instruction. With no need for 256 if-then-else statements, the equivalent case statements in Pascal or switch statements in C/C++.
And thus:
ftable calculator::ftab = { &calculator::fadd, &calculator::fsub, &calculator::fmult, &calculator::fdiv, };--- actually creates the function table, and this is how we call the desired function with one line of code, instead of sometimes thousands. Seriously.
result = (ftab[op])(arg1,arg2);
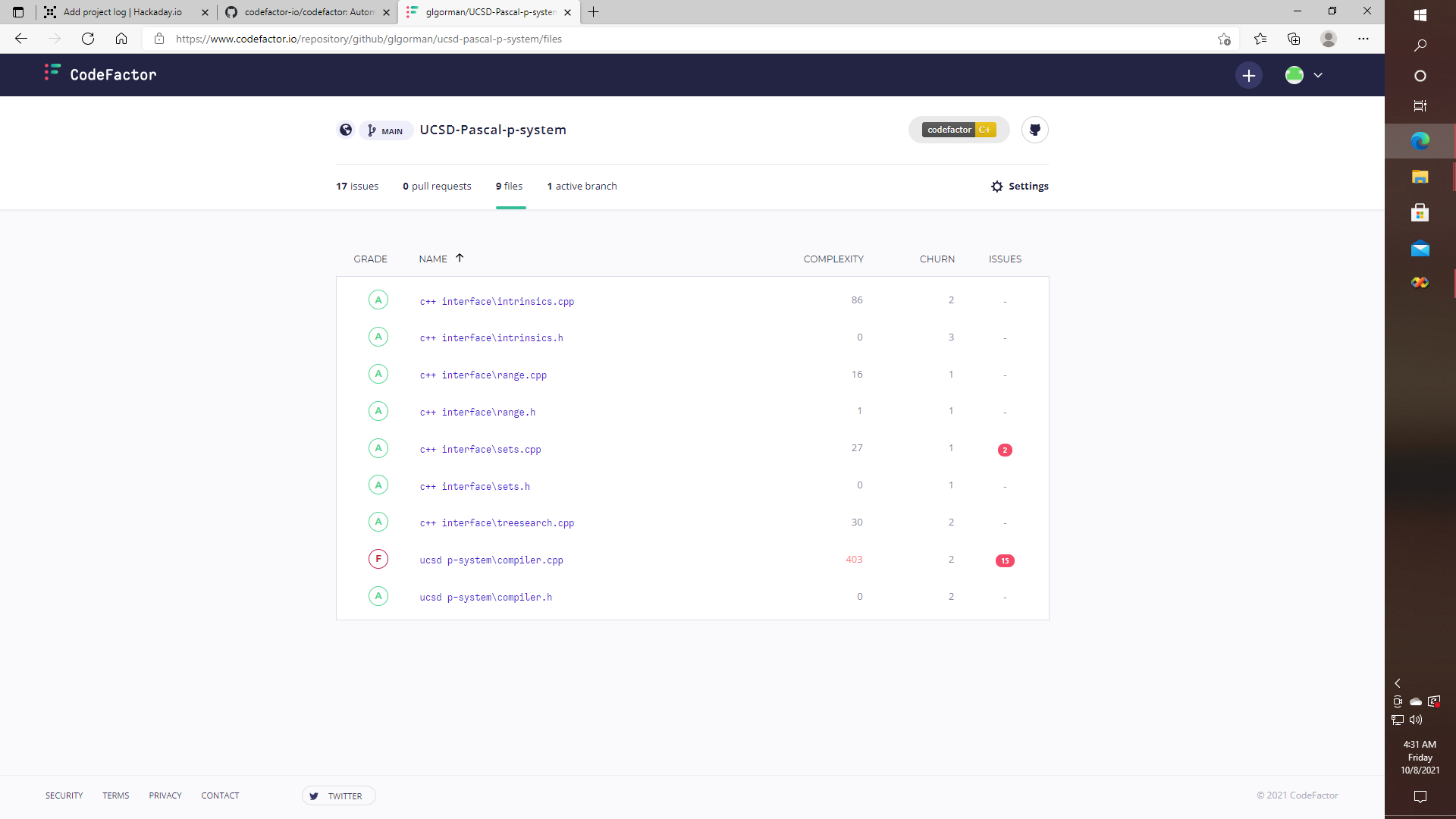
Now, this is where things get surreal. I have so far converted about 2500 lines of the UCSD Pascal p-system compiler from Pascal to C++, trying to be as strict as possible in converting the original source line by line and keeping as near an exact style as the process will allow, and then I ran "Code Factor" which is a code quality analysis tool, to try to identify issues with the code. So are you ready for the results, so far?
![]()
Yep, "Code Factor" gave the University of California at San Diego an "F" for code quality, or at least that's the grade that their compiler got. Hmmm? Of course, if older versions of Pascal didn't support function pointers or jump tables, then that might explain some things. Otherwise feeling pretty good that nearly every piece of code I have ever written seems to be getting an "A". At least with that particular tool. Kind of makes me wonder what it might say about GCC.
One of the issues with UCSD Pascal that I would like to mention, however, is the quite astonishing use, in at least one place, of a CASE statement that has a separate CASE for each and every expected ASCII symbol. Converting the original Pascal source of part of a function called INSYMBOL to C++ directly, that is to say, without making any gratuitous changes gives us something like this:
switch (CH) { case (int)'"': STRING(); break; case (int)'0': case (int)'1': case (int)'2': case (int)'3': case (int)'4': case (int)'5': case (int)'6': case (int)'7': case (int)'8': case (int)'9': NUMBER(); break; case 'A': case 'B': case 'C': case 'D': case 'E': case 'F': case 'G': case 'H': case 'I': case 'J': case 'K': case 'L': case 'M': case 'N': case 'O': case 'P': case 'Q': case 'R': case 'S': case 'T': case 'U': case 'V': case 'W': case 'X': case 'Y': case 'Z': case 'a': case 'b': case 'c': case 'd': case 'e': case 'f': case 'g': case 'h': case 'i': case 'j': case 'k': case 'l': case 'm': case 'n': case 'o': case 'p': case 'q': case 'r': case 's': case 't': case 'u': case 'v': case 'w': case 'x': case 'y': case 'z': SEARCH::IDSEARCH(SYMCURSOR.val,(char*&)(*SYMBUFP)); /* MAGIC PROC */ break; ....etcHow sad!
Imagine going through all of that for every character read by an application. Why not - if you really wanted to so something in a proper, but classic Pascal style - try this:
namespace chartype { SET digits(10,'0','1','2','3','4','5','6','7','8','9'); SET whitespace(3,' ','\t','\n'); SET alpha(52,'A','B','C','D','E','F','G','H','I','J','K','L','M', 'N','O','P','Q','R','S','T','U','V','W','X','Y','Z', 'a','b','c','d','e','f','g','h','i','j','k','l','m', 'n','o','p','q','r','s','t','u','v','w','x','y','z'); SET punct1(10,'.',',',':','\'','(',')','{','}','[',']'); SET operat(11,'+','-','*','/','%','|','~','=','&','>','<'); }It does seem to compile and pass some simple tests, and it should be Unicode compatible when using suitable codepage parameters and methods elsewhere, for those people who insist on writing their applications in Arabic, Greek, or APL. I am aware of course that Pascal is a descendant of Algol-60, and as both Pascal and C were created in the 70's, it is understandable that the creators didn't use C functions like "isalpha()", or "isnum()", and maybe even Pascal SETS weren't quite working yet. But seriously!
Yes - seriously, there are likely hundreds, if not possibly thousands of so-called "zero-day" vulnerabilities out there, lurking in major applications that are in use every day because of misuse of the CASE or SWITCH statements. Maybe I will explain just why that is so in another post.
-
Whether or not, to say "whether or not" or not.
10/07/2021 at 23:53 • 0 commentsOr is it this or that, or neither this nor that? Perhaps it doesn't matter. That's not what this post is about, unless maybe it is. Writing a compiler from scratch is no small task, on the one hand, but then again, on the hardware side of things there are always going to be those people who want to do things like "build" a compete CPU or at least an ALU with nothing but NOR gates; just like the Apollo guidance computer. So while building such at beat is not in the cards, simulating on with software is certainly fair game, especially if there is also the possibility that a compiler for such a beast might emerge in the very near future. So lets have a look at some code.
inline DWORD nor(DWORD r1, DWORD r2) { DWORD result; result = ~(r1|r2); return result; } inline DWORD not(DWORD r1) { DWORD result; result = nor(r1,r1); return result; } inline DWORD or(DWORD r1, DWORD r2) { DWORD result; result = not(nor(r1,r2)); return result; } inline DWORD and(DWORD r1, DWORD r2) { DWORD result; result = nor(not(r1),not(r2)); return result; }So far so good. Just wait until you try to debug addition. But first, take a look at how we do "and" via DeMorgan's law. Fairly straightforward. Now assuming that you have addition, and if you also have the square of the first 255 integers in a look-up table, 8-bit by 8-bit multiplication follows, like so:
inline unsigned short mult8 (unsigned char c1, unsigned char c2) { unsigned short s0, s1, s2, s3, s4; if ((c1==0)|(c2==0)) return 0; if (c1==1) return c2; if (c2==1) return c1; s0 = (unsigned short) add(c1,c2); s1 = (unsigned short) sub(c1,c2); bool m_odd = (s0&0x1?true:false); bool m_neg = (s1&0x8000?true:false); if (m_odd) { s0 = (unsigned short) add(s0,1); s1 = (unsigned short) add(s1,1); } s2 = (unsigned short)(m_neg?add(not(s1),1):s1); s0>>=1; s2>>=1; s3 = (unsigned short) sub(lut1[s0],lut1[s2]); if (m_odd) s4 = (unsigned short) sub(s3,c2); else s4 = s3; ASSERT(s4==c1*c2); return s4; }Yes, script kiddies and sugar friends, that does the trick. Which kind of makes me wonder what it would look like if I had a good C++ 6502 compiler, or C++ for the NOR machine, that is. Care to try for 16 bits? I think that this works, but I haven't run every possible test:
inline DWORD square(unsigned short r1) { DWORD t0,result; DWORD t1, t2, t3; unsigned char highbyte, lowbyte; lowbyte = r1&0xff; highbyte = (r1&0xff00)>>BYTESIZE; t0 = (lut1[highbyte]<<WORDSIZE)|(lut1[lowbyte]); t1 = mult8(highbyte,lowbyte); t2 = t1<<(BYTESIZE+1); t3 = add(t0,t2); result = t3; ASSERT(r1*r1==result); return result; } inline DWORD mult16(unsigned short r1, unsigned short r2) { DWORD result; DWORD t1, t2, t3, t4; t1 = add((DWORD)r1,(DWORD)r2); t2 = sub((DWORD)r1,(DWORD)r2); t3 = square(t1); t4 = square(t2); result = sub(t3,t4)>>2; return result; }Now, this is starting to look like it would be a good way to use overloaded operators in templates, that is to say, if a full-featured C++ compiler were available. Conformant IEE-754? Not quite there yet. Even though I am not currently doing anything with this code, it is interesting from the point of view of compiler writing; that is to say - to the extent that it should be possible to write a complete compiler for any language that might use only a very limited instruction set, such as NOR, SHIFT, COMPARE, and JUMP, along with perhaps CALL, LOAD, PUSH and POP. That means of course that when writing a compiler for a new platform, it might be useful to initially make use of only a subset of instructions, i.e., with respect to what is actually available with a new architecture. Then, for example, one approach might be to use C++ classes which provide the facility for the use of virtual functions. Thus, one might declare a "fake.cpu" which defines virtual functions for all of the primitives and then use a class that inherits from that class, and which provides overrides which in turn do interesting things, like spitting out "inline' assembly to a "debug file." Presto! Instant compiler construction kit for any platform without 99% of the bloat. Check out the code for "fake_cpu.cpp" in the files section on this project page, as well as the Frame Lisp project on GitHub for further insights.
Rubidium 2.0
This is an all in one spectrum and logic analyzer, robotics control platform, and modular synthesizer with audio in and sheet music out!