 Tim
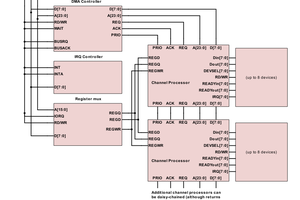
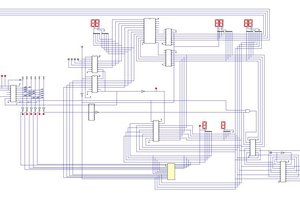
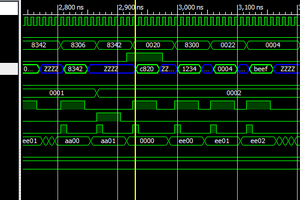
TimAn 8 bit RISC CPU for TinyTapeout. Tinytapeout combines 500 designs on a single IC to be taped out with the Open MPW-7. This offers the opportunity to actually get a design made on a real IC, but also comes with some constraints:
- Maximum allowed area is 100 x 100 µm² (=0.01 mm²) in Skywater 130nm CMOS technology. The actual number of useable gates depends on cell size and routing limitations.
- Only eight digital inputs and eight digital outputs are allowed.
- I/O will be provided via the scanchain (a long shift register) and is hence rather slow.
Designing a CPU around these constraints offers a nice challenge. Challenge accepted!

 More documentation and code here:
More documentation and code here: 












 Erik Piehl
Erik Piehl
 Tim Ryan
Tim Ryan
Damnit you did IT again ! :-D