glgorman
glgorman-
What, This Thing Is Nuclear? No, Not Really!
06/09/2026 at 01:38 • 0 commentsBut I like to begin my log entries with a catchy title, nonetheless. So, in any case, maybe it is time to look at some code. For Lotto-type games, I created a source file called lotto.cpp, which does all of the heavy lifting, insofar as looking at a bunch of stuff that involves examining pair histories, looking for triplets containing particular pairs, and so on. So the C++ class for "draw" that is going to be rewritten for that part of the model starts out looking like this:
class draw { int score; int number; int x [6]; char str [32]; public: draw () { memset (this,0,sizeof (draw)); }; void sort (); draw (int a, int b, int c, int d, int e, int g = 0) { memset (this,0,sizeof (draw)); x[0]=a; x[1]=b; x[2]=c; x[3]=d; x[4]=e; x[5]=g; sort (); } draw (char*); bool operator > (draw &d); int &operator [] (int arg) { return x[arg]; } void test (char *, size_t max); bool increment (int limit = _G::MAX_NUMBER); bool match_copair (int p, int q, int r, int s); void dump (char *buff, size_t max); void calc_pairs (); void calc_trips (); };class draw { int score; int number; int x [6]; char str [32]; public: draw () { memset (this,0,sizeof (draw)); }; void sort (); draw (int a, int b, int c, int d, int e, int g = 0) { memset (this,0,sizeof (draw)); x[0]=a; x[1]=b; x[2]=c; x[3]=d; x[4]=e; x[5]=g; sort (); } draw (char*); bool operator > (draw &d); int &operator [] (int arg) { return x[arg]; } void test (char *, size_t max); bool increment (int limit = _G::MAX_NUMBER); bool match_copair (int p, int q, int r, int s); void dump (char *buff, size_t max); void calc_pairs (); void calc_trips (); };
There is, of course, a lot of room for improvement, and a lot of things that need to be changed, since clearly it is nowhere nearly as simple as using find and replace to change the word "game" to "context" and "draw" to "reading frame" as one might want it to be. One of the first things that I want to get rid of, therefore, is the reliance on the use of sscanf to parse a line from a Lottery history file into an entry into a game history database. That needs to go badly! Especially if we are going to be "tokenizing" things like the Federalist Papers, or articles from Wikipedia, or whatever else we might encounter. So, this is going to present an interesting challenge, in that respect, i.e., make improvements to the original code so that it will work with more history files for more types of games. At the same time, enabling the algorithms that we are using to try to make "predictions" about what pairs with whatever, to work with other types of tokens, that is according to a more robust probability model.
void CLottoProDoc::find_copairs (int p, int q, int SEARCH_DEPTH) { _int8 copairs1 [64][64]; _int8 copairs2 [64][64]; int i,j,k,l,N,p1,q1; char str [DEFAULT_BUFFER_SIZE]; sprintf_s (str,DEFAULT_BUFFER_SIZE,"searching for copairs %02d-%02d ... \r\n\r\n",p,q); strcat_s (outbuff,OUTPUT_BUFFER_SIZE,str); for (i=0;i<_G::MAX_NUMBER+1;i++) for (j=i;j<_G::MAX_NUMBER+1;j++) { copairs1 [i][j]=0; copairs2 [i][j]=0; } for (N=SEARCH_DEPTH;N>=0;N--) for (j=0;j<DRAW_SIZE;j++) if (history[N][j]==p) // found first number { for (k=0;k<DRAW_SIZE-1;k++) for (l=k+1;l<DRAW_SIZE;l++) { p1 = history[N][k]; q1 = history[N][l]; copairs1 [p1][q1]++; if (p1!=q1) copairs1 [q1][p1]++; } } // OK BUIlT A LIST OF PAIRS THAT HAVE OCCURED WITH THIS NUMBER for (N=SEARCH_DEPTH;N>=0;N--) for (j=0;j<DRAW_SIZE;j++) if (history[N][j]==q) // found second number { for (k=0;k<DRAW_SIZE-1;k++) for (l=k+1;l<DRAW_SIZE;l++) { p1 = history[N][k]; q1 = history[N][l]; copairs2 [p1][q1]++; if (p1!=q1) copairs2 [q1][p1]++; } } // ALRIGHT NOW HAVE A LIST OF COPAIRS FOR THE SECOND NUMBER int found; for (i=1;i<_G::MAX_NUMBER;i++) if ((i!=p)&&(i!=q)) for (j=i;j<_G::MAX_NUMBER+1;j++) { if ((j!=p)&&(j!=q)) { found = 0; if ((copairs1 [i][j]>1)&&(copairs2 [i][j]>0)|| ((copairs1 [i][j]>0)&&(copairs2 [i][j]>1)) ) for (k=SEARCH_DEPTH;k>=0;k--) { if (found==0) { sprintf_s (str,DEFAULT_BUFFER_SIZE,"FOUND COPAIR %02d-%02d\r\n",i,j); strcat_s (outbuff,OUTPUT_BUFFER_SIZE,str); found = k; } if (history [k].match_copair (i,j,p,q)) history[k].dump (outbuff,OUTPUT_BUFFER_SIZE); } } if (found!=0) strcat_s (outbuff,OUTPUT_BUFFER_SIZE,"\r\n"); } // now search for rings. for (i=1;i<_G::MAX_NUMBER+1;i++) if ((i!=p)&&(i!=q)) for (j=i+1;j<_G::MAX_NUMBER+1;j++) if ((j!=p)&&(j!=q)) if ((copairs1 [i][j]>0)&&(copairs2 [i][j]>0)) for (k=j+1;k<_G::MAX_NUMBER+1;k++) if ((k!=p)&&(k!=q)) if ((copairs1 [i][k]>0)&&(copairs2 [i][k]>0)&& (copairs1 [j][k]>0)&&(copairs2 [j][k]>0)) { sprintf_s (str,DEFAULT_BUFFER_SIZE,"Found ring %02d-%02d-%02d",i,j,k); strcat_s (outbuff,OUTPUT_BUFFER_SIZE,str); if (history.check(draw(p,q,i,j,k))==true) { strcat_s (outbuff,OUTPUT_BUFFER_SIZE," ***"); } strcat_s (outbuff,OUTPUT_BUFFER_SIZE,"\r\n"); } }And to be quite honest, I have no idea what will happen if I rewrite this so as to be able to chow down on "Alice In Wonderland" or "The Adventures of Tom Sawyer." Lots of things will need to be parallelized. Lots of things need to have neuronal weights calculated based on relative probabilities, and of course, a lot of loops need to be replaced with some other kind of iterator that works with ordered or unordered sets, and so on. Yet this is at the heart of at least one type of method for trying to find the best "co-pair" to match with a given pair of tokens, so as to then try to make a "forward prediction" within a reading frame, as if to also enable "predicting the next word in a sentence."
Maybe. Right now this is VERY messy.
-
Simple Simon met a "pi" man - going to the fair.
06/08/2026 at 01:48 • 0 commentsI was thinking about doing another log entry about Lottery systems, and the probability that certain groups of numbers will come up, so as to take a closer look at certain types of problems, like what is the actual probability that someone's birthday will come up, on any particular Lotto type game, as well as the more general problem with respect to the probability that any particular set of 2, or even 3 numbers might come up, like 3 and 14, of course. Yet that leads to the more general problem of "how long will it be on average for 3-14 and 15 to come up", depending on the number of balls in the particular game, and the number of numbers picked in a particular draw. But that will have to wait. Maybe I will write a short C++ program that prepares a chart for the waiting time for each variation, with fans of e = 2.71828, which can be played on a Lottery as 2-7-18-28, along with "whatever" taking the absolute longest, that is, besides matching all five or six numbers, according to the game.
Instead, I want to look at something else, something that is, that I hope we can get some help with, that is, in the realm of "vibe coding," perhaps.
![]()
Yet if in the previous example, I was thinking about how the phrase "I LOVE A MYSTERY" might encode the sequence 5-8-30-14, or else the phrase "I LIVE OUT MY DREAMS" might encode the set 5-8-13-14-30, it is easy to see that neither of these came up on the California Super Lotto last night, even if the five and eight did, but oh so sorry, no 13, and no 14, no hidden pi, or any pie for that matter to be had. No pi, pie, too bad so sad, and better luck next time?
Or else wait a minute. I didn't even play the Super Lotto last night, and not just because I am not even in California right now. At least the 5 and 8, and then I noticed something that I find interesting, nonetheless. Something that fits in nicely with my examples "DOWN THE PRIMROSE PATH", "DOWN THE HATCH", "DOWN THE RABBIT HOLE" and of course "DOWN THE DRAIN" and that would of course also mean that I should have mentioned something along the lines of "DOWN BY THE RIVER SIDE" as an example of something that can be, and perhaps should be done when we have "lists of words" that we somehow "need" to use in a sentence, or in a composition, as a whole, and where we need to be a bit more flexible with word order, or else when we need to accommodate the need to have an occasional word or phrase inserted into the response.
So I spotted something, something kind of fun, since I was working on a meme that begins with 5 and 8 representing the word "LOVE", yet what about "FLOWERS" which encodes the sequence 8-5-40, which of course does not work, with last night's Super Lotto, yet "A FLOWER WILTS!" does encode the sequence 5-8-45-10. Just as easy to think of as the "easy e = 2-17-18-28", and just as hard to predict, of course!
A flower wilts.
A flower wilts when it has no water.
A flower wilts when it has no air.
A flower wilts in one year!
A flower wilts.Ah poetry! Using "random numbers as seed values!"
Easier said than done?
Q.E.D
For now!
-
The Birthday Problem and other Roads Less Travelled
05/31/2026 at 02:21 • 0 comments![]()
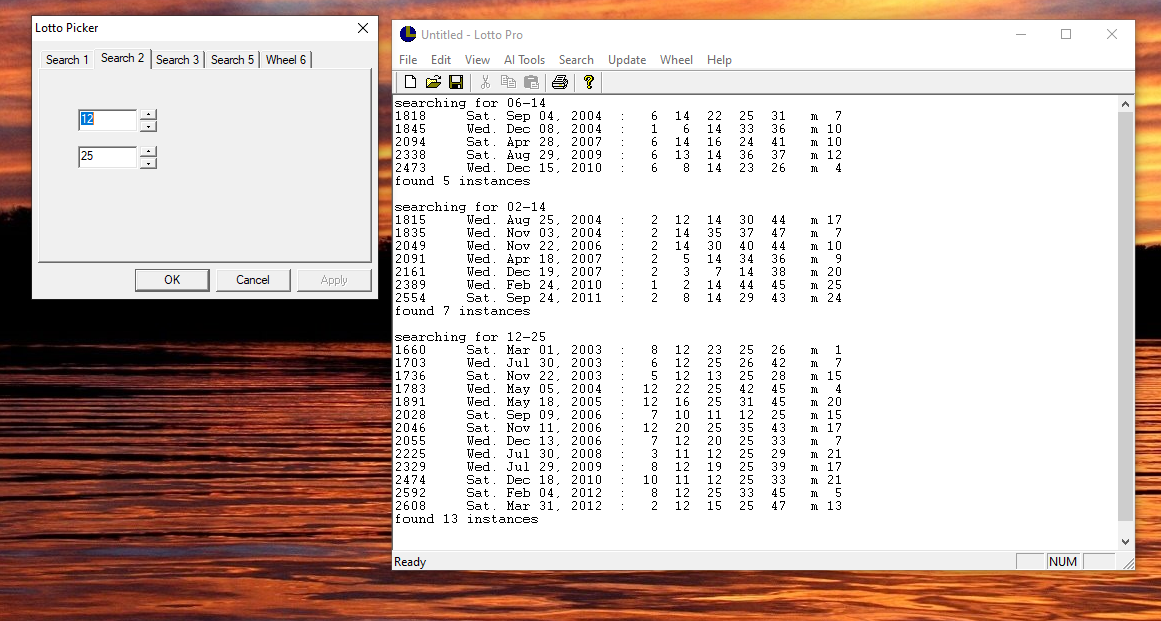
Looking at the Fantasy Five Birthday problem, vs. the Power Ball birthday problem, and how to calculate the "Birthday Problem" for any Lotto-type game. In the California Fantasy Five game, there are 39 numbers to choose from. So, if someone's birthday was 12-25, then what is the chance that 12-25 will come up on the California Fantasy Five, which, as stated, has 39 numbers, vs. the Power Ball, which has 69 numbers? According to my classic HP-15 calculator, the birthday probability for the California Fantasy 5 game is approximately 1 in 74.10, whereas the "Birthday Probability" for the Powerball is approximately 1 in 234.60.
One way to do this calculation is, of course, to use the "choose function C" to compute the value C(39,5)/C(37,3) for the California Fantasy Five, or to likewise simply compute C(69,5)/C(67,3) for the Powerball, obtaining the 234.60 value in that case, as stated. So this would appear that we could find the general case for any Lotto-type game as C(M, N)/(M-2, N-2), which uses either a bit of multiplication and division to get done, or else we could perhaps generalize it a bit further, by discovering a pattern that seems to exist in the calculations, when it is written out by hand, so that it also presents an opportunity to perform some optimization.
Thus, it would appear that the problem of finding the probability of having two specific numbers come up in a five-numbered draw set actually generalizes to the value: N*(N-1)/20. This, of course, might have some interesting implications.
With an LLM, of course, we are going to want to replace some Lottery concepts like "draw set" with "reading frame," and we are going to want to think about the idea of grammars that might have 10's of thousands of symbols or more, so that maybe problems of this type are going to turn out to be important when we think about memory allocation, thread pool size, and so on. Yet drawing from the examples of "down the rabbit hole", "down the primrose path", "down the hatch," and "down the drain", it should be easy to contemplate that there should be some way of developing metrics for measuring the probability that two randomly chosen symbols will occur within some context, so as to be able to do some work in the problem of scaling things like "neuronal weights" associated with relevance, or significance, that is, within the framework of the hopefully more general transformer based attentional systems.
Maybe. Or we can go back to asking "What happened to the other dollar?"
-
Which way do we go from here?
05/24/2026 at 16:23 • 0 commentsThere is a whole bunch of stuff that I want to do, like talk about the "phone book trick from the movie Rain Man", and how there is an urban legend that it was actually done by the magician and memory expert Harry Lorayne, who was also one of the authors of a best-selling book entitled "The Memory Book." Even if Lorayne didn't actually memorize the entire Manhattan telephone directory, it was said that he did memorize quite a few pages, just to prove that it could be done.
This is something that I want to talk about in a different context, i.e., with respect to Lottery systems, whether they work or not. Yet they will have utility, I think, in finding interesting and novel ways to approach the problem of designing an LLM from scratch.
Since this is going to take a while to explain, perhaps it would be best to start with an excerpt directly from the book, or just simply borrow a description for one popular system for memorizing numbers from the Wikipedia article on the so-called "Mnemonic Major System."
So here is "The system", shamelessly borrowed from Wikipedia:
--------------------------------------------------------------------------------------------------------------------------------------------------------------
0 /s/, /z/ s, soft c, z Zero begins with z (and /z/). Upper case S and Z, as well as lower case s and z, have zero vertical strokes each, as with the numeral 0. The alveolar fricatives /s/ and /z/ form a voiceless and voiced pair. 1 /t/, /d/, /θ/, /ð/ t, d, th (as in thing and this) Upper case T and D, as well as lower case t and d have one vertical stroke each, as with the numeral 1. The alveolar stops /t/ and /d/ form a voiceless and voiced pair, as do the similar-sounding dental fricatives /θ/ and /ð/, though some variant systems may omit the latter pair. 2 /n/ n Upper case N and lower case n each have two vertical strokes and two points on the baseline. 3 /m/ m Lower case m has three vertical strokes. Both upper case M and lower case m each have three points on the baseline and look like the numeral 3 on its side. 4 /r/ r Four ends with r (and /r/ in rhotic accents). 5 /l/ l L is the Roman numeral for 50. Among the five digits of one's left hand, the thumb and index fingers also form an L. 6 /tʃ/, /dʒ/, /ʒ/, /ʃ/ ch (as in cheese), j, soft g, sh Upper case G looks like the numeral 6 and lower case g looks like the numeral 6 rotated 180°. Lower case script j tends to have a lower loop, like the numeral 6. In some serif fonts, upper case CH, SH and ZH each have six serifs. CHurch has six letters. The postalveolar affricates /tʃ/ and /dʒ/ form a voiceless and voiced pair, as do the similar-sounding postalveolar fricatives /ʃ/ and /ʒ/. 7 /k/, /ɡ/ k, hard c, q, hard g, ch (as in loch), Both upper case K and lower case k look like two small 7s on their sides. In some fonts, the lower-right part of the upper case G looks like a 7. G is also the 7th letter of the alphabet. The velar stops /k/ and /ɡ/ form a voiceless and voiced pair. 8 /f/, /v/ f, ph (as in phone), v Lower case script f, which tends to have an upper and lower loop, looks like a figure-8. The labiodental fricatives /f/ and /v/ form a voiceless and voiced pair. 9 /p/, /b/ p, b Upper case P and lower case p look like the numeral 9 flipped horizontally. Lower case b looks like the numeral 9 turned 180°. The labial stops /p/ and /b/ form a voiceless and voiced pair. --------------------------------------------------------------------------------------------------------------------------------------------------------------
Now what do we do with it? Well when taking a short phrase like "I LOVE A MYSTERY", or "I LIVE OUT MY DREAMS", we can easily see that the first sentence encodes the sequence 5-8-30-14 and the second sequence encodes the pattern 5-8-13-14-30, that is to say, if we have a constraint that what we want to do is to try to find a way to create some kind of "magic cookie" as it were, that somehow encodes a set of numbers that can be played on a Lottery game.
Yet that implies something, of course, and that is a whole "new" kind of "mining", that is to say, "new" for most people. Since the order in which Lottery numbers are drawn usually doesn't matter, for some games, that is, like the Power Ball or the Mega Millions, which creates the situation of perhaps generating "sets of single consonants, as well as pairs and pairs of pairs of consonants" as a starting point, that is to say, for random text generation!
I mean, sure! Why not? It should be easy to see how the word pair "MARTHA COMPONENTS" might be playable on some Lottery game as the set 34-17-39-22-10, if I am reading it right. Now this implies some things, such as the idea of searching the space that contains every possible choice of the type "1-2-3-4-5" though "43-44-45-46-47" and generating all 120 permutations within that space, and then generate every possible set of split points for each combination and permutation, and then of course do a dictionary lookup to see which combinations have word mappings, and then generate potential "magic cookies."
I don't want to tell you how many CPU's I might have melted, or how many hard drives I destroyed trying to generate text in this way. Yet maybe now is a good time to explore some interesting possibilities with a modern GPU.
Warning! This project could melt your PC! You have been warned!
-
Another Day - Another 3000 Words: Maybe
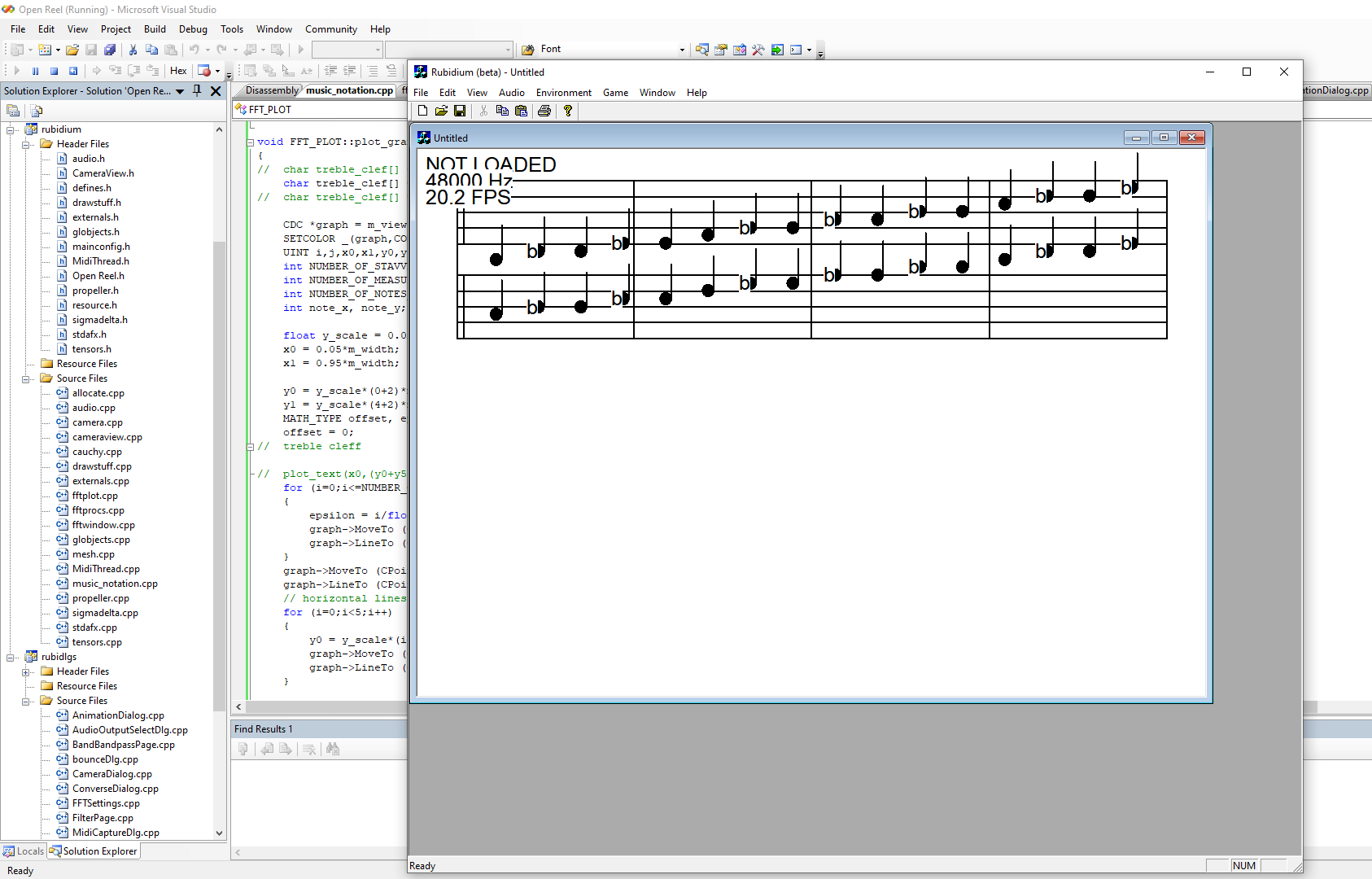
04/29/2026 at 21:29 • 0 commentsThe way that I figure it, what if I could write 3000 words each day, of "new material" which is somehow relevant to training an LLM, by whatever means? Then it would take "only" 333.33 days to get to one million words of hopefully, new, original, and just as important, potentially "useful" content. Yet there are other things that an LLM might be trained on, like MIDI data derived from audio input.
![]()
Or patterns in DNA, maybe?
![]()
I mean, why not? If it seems like a reasonable thing to try, and if the advent of vibe coding might somehow make the otherwise gargantuan task of retooling something like 100,000 lines of code, spread across at least 20 libraries, actually seem feasible. Then maybe that is yet another domain for AI, which is not only highly important, but also relevant, even if at the same time it might seem like such explorations are perhaps being underserved, at least within the Open Source community.
I know that I am going to want to be doing things with "transformers"; however, they actually work. Yet, there is also the obvious, yet seemingly all too often overlooked, task of getting the data into the program, to begin with. Maybe that isn't as hard as it might seem.
Yet there is also this idea of generating as much "metadata" as possible, maybe, based on traditional methods. Not just because it is possible to do, but because, maybe, just maybe, the transformer model would be a lot more efficient if some of the initial heavy lifting were done according to standard coding techniques.
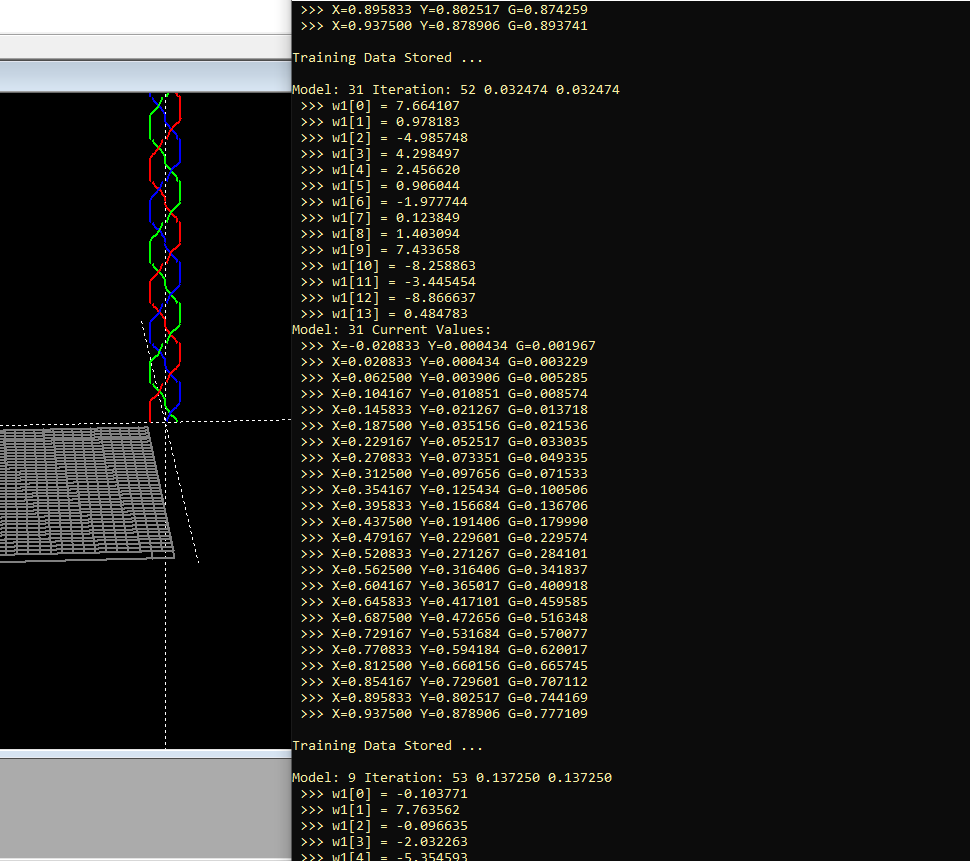
Interestingly enough. When I took some Atari BASIC code and experimented with using a "genetic" algorithm to approximate a mathematical function, I found that I got better results if I ran 32 models in parallel, and let them compete with each other, let's say for 64 iterations each, than I was getting if I ran a single model for 2048 iterations.
![]()
So I think that there are even more avenues that need to be explored, as far as how this sort of thing might work out in the long run. Clearly, at least in this particular case, a competition among the so called "mixture of experts", multi-model approach, seems to work best.
-
Somewhere in the Once Upon a Long Time Ago
04/29/2026 at 02:36 • 0 comments![]()
Right! Whatever I just said.
Well, anyway.
What if this project isn't really about trying to predict the Lottery, and it is especially not about trying to predict any current game using a database of numbers from as long ago as 2012, which hasn't been updated in at least that long?
No, that's not the point.
That is only the beginning.
Really, an LLM, or so we are told, is not so much about words or numbers as it is said to be about "tokens". Whatever those tokens represent is, well, whatever they represent. Maybe macroblocks from a JPEG of a medical X-ray, or maybe waveform data from a seismograph, or "whatever." That, of course, was the big surprise, with the discovery that "maybe attention is all you need." Yet somehow, the "pairs of pairs" meme seems to have stuck with researchers as one of the best predictors, at least as far as text generation is concerned. So does it make sense to try to, in effect, create some kind of "lottery-like" application that increases the number of balls in a particular game to some "reasonable number" like 65535, or something like that, along with an appropriate increase in the size of the "reading frame?"
Maybe. Maybe there are a lot of things that need to be tried in parallel, and it is just as important to come up with methodical techniques for formalizing the parallelization of whatever processes are being put to the test. Something else comes to mind, such as whether to try to store the topology of a neural network in a traditional fashion, such as by extending the capabilities of Spice, or Ki-Cad, or whether it is actually much easier to do something like that with a relational database like MySQL . Yet, that of course is where the newfound meme of "vibe coding" might come in handy, that is to say, as things grow, and grow, and grow. Which they will.
Likewise, we might want to add or delete a source from the training set.
So a "make system" is also needed.
This thing is huge, but not impossible.
![]()
Yes, there will be back propagation and gradient descent.
![]()
Maybe even a seemingly infinite number of monkeys, all leaping about. Having private "conversations" with each other, and so on.
This is an ambitious project.
In the meantime, thank you for choosing Johnny Cab. Hope you enjoy the ride!
Let's Build a Modern LLM - Entirely from Scratch
While there are several open source versions of various AI applications out there, there is still very little out there for doing training.