Eric Hertz
Eric Hertz-
--- STATE ---
02/25/2017 at 16:31 • 0 commentsTo be honest, I ran out
of steam on making this project "public-ready." But most of my projects
rely on it, so it's "out there." At least, in parts.
--------------
I doubtthat commonCode would offer much, library-wise, that you couldn't
find elsewhere.
So, I guess, upon re-looking at commonCode from an outside-level (vs. just using it for my own projects), it might be less about the libraries themselves, and more something along the lines of an *environment* like Arduino; plausibly a bit more customizable and more optimizable, but significantly (nearly infinitely) less-documented and less-supported... nevermind more fine-tuned for my own needs/habits/style... more esoteric ;)
There'd definitely be a learning-curve to use this system or any of the code within it, probably starting with 'blinky' (or 'heartBeat') and slowly moving up from there. And, again, since I've put public-readiness on the back-burner, the examples stop pretty early-on, pretty much immediately after the [bitbanged] UART 'echo' example. From there, (nearly everything else) user-level documentation is sparse, and user-level consistency even more-so.
Oh, and... I went through several different iterations of "public-readying" those early-examples, especially as I started making it even more architecture-independent, so the actual user-level interface/examples probably vary between each "step"...
Weee!
-----------
So, again, *I* use this 'system' for nearly every code-based project I do... and improve it as I go along... But it's not really "public-ready," and making it so, in its entirety, would be a tremendous undertaking.
But if you're *really* interested in trying out the [a bit outdated] blinky example...
https://github.com/esot-eric-test/heartbeat-2.00-gitHubbing_-revisions
And here's a project which uses 'the system':
https://github.com/ericwazhung/sdramThingZero
Browse into the _commonCode_localized directory to see what's used in that project... Usually I start a project with nothing more than 'heartBeat', then move on to 'polled_uat', and then 'polled_uar'. These *should* have test-code in a subdirectory... e.g. _commonCode_localized/heartbeat/2.06/<test>/ wherein you should be able to type 'make' and try it out... But no promises. ;)
----------
Thanks @David H Haffner Sr for inspiring this status-update!
-
extra warnings/errors
01/06/2017 at 23:34 • 0 commentsIt's handy to have gcc output errors for certain things...
e.g.:
uint16_t a = 512; uint8_t b = a;------
In my code, I prefer to have it explicitly stated that I want to "downsize", so I don't mistakenly do that.
So, as I recall, there's a gcc-warning option for that, and further a means to convert that warning into an error.
--------
Here's a listing from my makefile.
The remaining are CFLAGS for -W... arguments # Warnings that I would rather be considered errors... # THESE ARE gcc-version specific! (Apple's GCC 4.01 doesn't like 'em) #WTF, seriously... this should *not* be a warning, but should be an error: #warning: integer overflow in expression [-Werror=overflow] # (((uint32_t)(TOGGLETIME * 8))<<(highNibble)), #from heartbeat1.50 CFLAGS += -Werror=overflow # Stupid Mistake: strcmp(0==instruction,"test") # should have been 0==strcmp... # Gave a warning, but wanted to convert that to error-material, nogo. # Apparently only works when int is of the wrong size for pointer... #CFLAGS += -Werror=int-to-pointer-cast #-Wstrict-aliasing? # Specifically missing return value # This is handled with -Wreturn-type "falling out of a function is considered returning void" CFLAGS += -Werror=return-type # Watch for use of uninitialized variables... # This does not handle volatiles! Does (attempt to) look for uninitialized array elements. # This apparently isn't very smart and is optional because of that. See the manpage # I'd like to think it's possible to code things so it can be detectable, we'll see. # Problems? "Some spurious warnings can be avoided if you declare all the # functions you use that never return as 'noreturn'." CFLAGS += -Werror=uninitialized #THIS IFNDEF is a hack... the old avr-gcc doesn't have this option # Would be better to test these options in GCC before compiling... TODO ifndef CC # That's basically useless in all but the simplest cases, as is: CFLAGS += -Werror=maybe-uninitialized # Neither detect: #int main(void) #{ # int result; # if(rand()) //may be 0 # result = 1; # printf("%d\n", result); # # return 0; #} # And haven't for over a decade. Except, apparently, Apple's GCC4.0 endif # This case is just BAD and should not be allowed ever. # int i = i; CFLAGS += -Werror=init-self # The next two could be handled together with "implicit" # Implicit declarations (no type specified: e.g. "static i;") CFLAGS += -Werror=implicit-int CFLAGS += -Werror=implicit-function-declaration # Detect global functions that aren't in headers... # This one's kinda annoying... useful, but annoying #CFLAGS += -Werror=missing-prototypes #CFLAGS += -Werror=missing-declarations # Might want to look into -Wignored-qualifiers # also -Wmissing-braces (just to be paranoid about array-initialization) CFLAGS += -Werror=missing-field-initializers # Watch parentheses and nesting... mainly: # if (a) # if (b) # foo (); # else # bar (); CFLAGS += -Werror=parentheses # Watch out for undefined stuff like a = a++; # do not fall into these habits as "more complicated cases are not diagnosed" CFLAGS += -Werror=sequence-point # Watch out for switches without default cases... I consider this bad practice # Who knows what'll happen if an integer's bit is affected by protons? CFLAGS += -Werror=switch-default # Do not allow float comparisons that are == CFLAGS += -Werror=float-equal # Don't allow bad address comparisons (if(func) instead of if(func())) CFLAGS += -Werror=address # Might also want to look into int-to-pointer-cast and pointer-to-int-cast # Watch for pointer argument passing and assignment with different signedness CFLAGS += -Werror=pointer-sign # Stop on the first error #CFLAGS += -Wfatal-errors # Warn for variables that might be changed by longjmp or vfork. CFLAGS += -Wclobbered # Warn about implicit conversions that may alter a value # Annoying... especially when using a uint8_t as an array position uint8_t i; noteList[i]; #CFLAGS += -Wconversion CFLAGS += -Wsign-compare # -Wstrict-overflow looks worthwhile for many reasons... watch out for optimization errors! CFLAGS += -Wstrict-overflow=4 # Warn if an undefined identifier is evaluated in an #if directive. CFLAGS += -WundefNote, I'm certainly no expert on these things. I just, one day, sat down and looked through 'man gcc' and compiled this list as best I could from what I understood that day. Most of it I've *long* since forgotten... hopefully those comments are clear :)
(If the text wraps weirdly, sometimes *shrinking* your window-width will help, counterintuitively)
-
To Revisit:
10/31/2016 at 08:01 • 0 commentsThis looks useful, but I'm unfamiliar with all the tools: #REM
Check out the "Comments Section" on the main-page of this project for an overview from the expert, himself.
-
weee! 'bithandling' and now 'gpio_port'
09/06/2016 at 05:04 • 9 commentsSo the "thing", of the last post, was porting of https://github.com/ericwazhung/grbl-abstracted such that grbl can now be more-easily ported to a variety of architectures.
Now (actually, months-ago) functioning and configurable for either a PIC32 or the original AVR (while remaining Byte-For-Byte identical to the original!). If you're curious, check out the "diff" at that page.
----------
Today, as a move toward porting #sdramThingZero - 133MS/s 32-bit Logic Analyzer to its next architecture (originally AVR, now PIC32, and, again, with all intention of making it completely "architecture-agnostic" (where did I get that phrase stuck in my head...? It doesn't seem quite right...)... as a means to that end, I've begun the first completely new version of my first go-to 'commonThing,' 'bithandling,' since its origins about a decade ago.
----------
I've jumped from v0.99 to v1.99, because, frankly, it's darn-near entirely different, and darn-near a complete rewrite, with new function/macro-names and more standardization...
E.G. a big one that should make it a million times more intuitive:
all argument-lists are now arranged such that the variable to be modified is listed *first*.
Apparently, I was pretty much completely arbitrary about that in the previous versions... and, despite having made *TONS* of use of it over the years, that was always a big trip-up...
e.g. writeMasked2(variable, mask, value) rather'n... oh jeeze, what was that order again?
E.G.2. a big one that might make it a million times less intuitive:
'bithandling' has been stripped of most of its GPIO-related stuff, that stuff has now been moved to 'gpio_port' (that's a "more intuitive")... but in-so-doing I also changed quite a few macro-names... e.g. whereas previously all the port-related macro-names were *very closely* related to the associated 'bithandling' names (e.g. setpinPORT() ~ setbit()) now they're NOT AT ALL similar. E.G. setpinPORT -> gpioPORT_ohJeezeI'veAlreadyForgotten.
gpioPORT_makeOutputPinHigh(), or, rather, gpioPORT_outputOneToPin(), I think.
So, where *reading* the code is downright self-explanatory, *writing* the code seems to result in lots of reference to gpio_port.h
That, maybe, is more a result of just not yet being familiar with it...
It was pretty bad, before, as well... e.g. there was setinPORT() and setPORTin()... one would set a pin on a port to an input, the other would set the entire port to inputs (all bits).
These *ideas* came about mostly as a result of prepping these macros for grbl-abstracted, and, to a much lesser-extent, much of it was implemented there... and I'm pretty content with most of the changes, but there's reason I went to 1.99, rather than 2.00, as I'm obviously not 100% on a few things. (But, surely, it was *WAY* too large a change to go from merely 0.99 -> 1.00)
So, having written the whole blasted thing with those crazy-long function-names ala how you're supposed to choose a difficult-to-crack, but allegedly-easy-to-remember password:
https://xkcd.com/936/
 ... well, anyways, you're *supposed* to be able to remember those things... but these things are a bit more wonky... Did I choose "correct" or "right", "One" or "High" this time 'round...? Yahknow?
... well, anyways, you're *supposed* to be able to remember those things... but these things are a bit more wonky... Did I choose "correct" or "right", "One" or "High" this time 'round...? Yahknow?...I find I might just write a whole new set of wrapper-macros or otherwise rename 'em back to the old names I've somewhat arbitrarily-memorized, but with a "2" at the end so I know that the version-2 macro-names *always* have the arguments listed with the *variable first* (or *PORT*).
We'll see.
Maybe I'll write a shell-script to automatically change e.g. setinPORT2() to gpioPORT_configurePinAsInput() for whenever I might decide to distribute something, just so it's easier for me to write/remember, while also being easier for newbs to digest. It's a thought.
--------------
Other additions:
Because bithandling is pretty much the first thing to go into any of my projects, regardless of the architecture, it handles a few architecture-related-things, like making it possible to easily add architecture-specific code to other 'commonThings' *when necessary*... Which, of course, is *highly* necessary for 'gpio_port'... So far, there's gpio_port_avr.h and gpio_port_pic32.h... So, there's a #include in gpio_port.h that looks, quite literally, like:
#include CONCAT_HEADER(gpio_port_,__MCU_ARCH__)which equates, hopefully obviously, to (when compiled for an AVR):#include "gpio_port_avr.h"This method, again, was largely developed for grbl-abstracted, and now finally moved to commonCode.And... a sorta late-in-the-game realization that I'll probably make use of in the near-future...
Part of the point of gpio_port's functionality is that it makes darn-near everything one can do with a GPIO port/pin available as its own macro... SUCH THAT, A) it's easy to read, B) it compiles (via optimizer) as, usually, the bare-minimum instructions that'd be required to accomplish the goal (no switch-statements to look up which pin is on which port, or which functionality to perform, etc.)...
BUT: again, that can lead to a bit of confusion with the naming... because there are a *lot* of names.
And, even worse, it means that *all those things* have to be reimplemented each time a new architecture is added (if you want full architecture-...-independent support for whatever code makes use of it). That's a lot of work.
SO... it occurred to me...
There are A LOT of things that *can* be handled quite-simply, by making use of each other... E.G.
configurePinAsAnOutput()
configureAllPinsAsOutputs()
configureMaskedPinsAsOutputs()
ALL of these could be handled, simply, by different "calls" to configureMaskedPinsAsOutputs()
The question, then, is... Is it reliable to think that most architectures' optimizers would be smart enough to recognize the most-optimal optimization of all those masked-cases...?
I know for a fact AVR's optimizer (at -Os) has been known to recognize e.g.
PORTA |= (1<<7)
as nothing more than an sbi() instruction
Pretty awesome, really... as it could much more easily have done a read-modify-write as the code was written. (Props to that optimizer team!)
BUT: at, e.g., -O1, I think it should be pretty much guaranteed to use the read-modify-write, as-written... which I don't see a use for, and would really bog things down in some other, more sophisticated, cases. And... are other architectures' optimizers as smart as avr-gcc's? Further, e.g. xc32-gcc, the free license, doesn't allow -Os, so would generate some pretty bloated code that, likely, wouldn't be any better as macros than function-calls. Maybe worse.
So, then, How could I reduce the "entry barrier" for new architectures...?
How's about e.g. using configureMaskedPinsAsOutputs() for *all* cases *except* when that case is explicitly-defined in the architecture-specific file e.g. gpio_port_pic32.h.
Then, it's likely, the majority of stuff could easily be implemented at an early-stage (and functional, really) with only a few explicitly-architecture-specific macros... And, the remainder could be manually "optimized" whenever one sees fit...
And... That's where it gets a little less "optimal"... Some architectures would be quite happy with writeMasked style stuff... PIC32 has _SET and _CLR registers for every PORT register... writeMasked could easily be implemented with two register-writes, no read-modify-write necessary. That is *just as* efficient for all the cases shown. But, e.g. on an AVR, where *three* bits are to be written, it would *definitely* require a read-modify-write, and probably some bit-shifts. (and, again, when optimization is turned off, it'd result in the same, even if only one bit was toggled and an sbi() *could've* replaced it
I've already, long-since, optimized *most* of those macros for AVR, and *many* for PIC32... but when a new architecture is added... would it be better to use writeMasked() as default for all cases, or is another method more general-purpose-optimal... (and... maybe... it'd be worth it to just implement writeMasked as a function-call in those cases...?)
So, that's where I'm at, at the moment.
And... admittedly... some amount of pondering whether having *all those macros* is such a great idea, at all... Yeah... I think it's better'n e.g. writing PORT |= (1<<7) everywhere, ain't no question whether that's architecture-specific. ("Wait, do I write LAT on this architecture, or PORT? Can I read it back for an R-M-W?") Yeah... these help... a lot.
And, again, when hand-optimized ONCE, in the associated gpio_port_<mcu>.h file, they generally result in the lowest instruction-count possible... which is generally *FAR* fewer than a function-call. So that's also quite handy. (Kinda the point, really).
...........
I guess, at some point, one might wonder whether *so much* effort should be placed on GPIOs at all, when darn-near everything these days *could* be handled by peripherals... right?
Not sure... E.G. I once implemented a UART on a device whose only serial-peripheral was synchronous, via an example from the manufacturer. Admittedly a great hack that they came up with a way to use a synchronous serial peripheral to implement asynchronous communication. And, frankly, I was pretty proud to have accomplished the same, from their example.
But, as I recall I think it was almost as much CPU-load (if not more?) than bit-banging the blasted thing. Nevermind being something that really only applies to a handful of parts, even from the same line of controllers, as it made use of a whole bunch of features available only to that style of synchronous serial peripheral, and other available features on that specific device (Again, a "Great Hack" worthy of admiration, and a great learning-experience). But, that guy was half-duplex, and bitbanging a UART in full-duplex while running other software, without even having interrupts isn't really *that* difficult for a RISC processor running at even a lowly 4MHz to handle.
Write that gpio-based software *once* (commonCode's 'polled_uar' and 'polled_uat'), and implement as many UARTs as you need on GPIOs on nearly any architecture... Not *ideal* in most-cases, (especially where a dedicated UART exists) but certainly easy to get a project started, when it's already been written, and easier to throw a debug-port on a device whose uart-peripherals are already in use, or otherwise not-yet-understood.
It's like anything, a tool, with pros-and-cons. Definitely not a one-size-fits-all, but handy to have at the right time. And, using 'bithandling' (and now 'gpio_port'), once set up *once* for your architecture, it doesn't care any more about your architecture-specifics than how to toggle a pin in the same way you'd blink an LED, the same way you'd bit-bang 32-bit SPI on an 8-bit architecture, interface with an SD-card, or SDRAM, or handle something as complex as timing acceleration of stepper-motors ala grbl on a processor most people would consider under-spec'd (props to its creator, definitely some wizardry in making that possible!). It would, however, be a bit more of a stretch to use these macros for, e.g., the bitbanged-implementations of USB on e.g. an AVR, where every clock-cycle counts and most of the *surrounding* code has to be written in assembly, so couldn't be ported to another architecture by merely abstracting the I/O routines. This "abstracted-gpio" method, despite intending to be *as fast as* direct register-writes and/or the associated-assembly, definitely has its limitations.
But, as it stands, *most* of those PIC32 I/O routines have already been "added to the bank," as-of grbl-abstracted, and several other projects. So, the current project, porting of #sdramThingZero - 133MS/s 32-bit Logic Analyzer from its current early-experiments on the AVR-host is little more than a matter of "transferring between accounts" (e.g moving the associated code from grbl-abstracted into commonCode's new 'gpio_port')...
Well, that... and soldering up a TQFP breakout-board, figuring out pinouts, etc. WEEE!
---------
Oh, and I've been meaning to throw in there that...
Another *big* part of the older versions of 'bithandling' (0.xx) and now 'gpio_port' is the fact that all port-related macros make use of *only* references to the associated "PORT" register.
That's kinda a big deal...
E.G. on AVR you have:
- PORTA
- 1's written to *output* bits in this register cause the pin to go high
- 1's written to *input* bits in this register cause the pin's internal pull-up resistor to be activated
- 0's written to *output* bits in this register cause the pin to go low
- 0's written to *input* bits in this register cause the pin's internal pull-up resistors to be disabled
- PINA
- Read-Only (right?)
- Reads from this register give you the binary-value measured at the pin, regardless of whether it's an input or an output
- DDRA
- 1's written to this register cause the pin to be an *output*
- 0's written to this register cause the pin to be an *input*
WHEREAS: E.G. on a PIC32 you have an *entirely* different scenario:
(And this list is a bit simplified)
- TRISA
- 1's written to this register cause the pin to be an input
- 0's written to this register cause the pin to be an output
- (Essentially the opposite of AVR's DDRA)
- LATA
- 1's written to *output* bits in this register cause the pin to go high
- 0's written to the *output* bits in this register cause the pin to go low
- ***READS from LATA reads the value stored in the data (output) latch
- (SIMILAR to AVR's PORTA, but *only* for output-bits)
- PORTA
- WRITEs to this register act identical to writes to LATA
- READs from this register act identical to reads from the AVR's PINA
- ODCA
- ODC registers allow setting an output to open-drain
- The equivalent could be accomplished on an AVR, roughly, by using two back-to-back register-writes:
- For Low output: writing '0' to the bit in PORTA and '1' to DDRA
- For Open-Drain output: writing '0' to DDRA (leave PORTA at '0')
- CNPUA = pull-ups (CNPDA = pull-downs)
- 1's written to *output* bits in this register cause the pin's internal pull-up/down resistors to be enabled
- 0's written to *output* bits in this register cause the pin's internal pull-up/down resistors to be disabled
- (CNPUA is pretty much equivalent to an AVR's PORTA register *FOR BITS THAT ARE INPUTS*)
- (_SET/_CLR/_INV registers)
- (Every port-related register above, (and even more not listed!) has associated REGISTER_SET, REGISTER_CLR, and REGISTER_INV registers which can be written with individual bits set to 1 to change the register-value without affecting other bits. Cool! No such luck on AVRs, but they do have sbi() and cbi(), so it's close).
- (Every port-related register above, (and even more not listed!) has associated REGISTER_SET, REGISTER_CLR, and REGISTER_INV registers which can be written with individual bits set to 1 to change the register-value without affecting other bits. Cool! No such luck on AVRs, but they do have sbi() and cbi(), so it's close).
OK, so why all this info...?
Well, there are a few things that are supported by both architectures (and I don't pretend to know enough about the myriad of architectures out there to claim these options exist on *all* architectures, but are probably pretty common)...
So, let's look at the AVR again... It basically has *four* GPIO pin-states, controlled by its registers:
- Output '1'
- Output '0'
- [Input] pulled-up
- [Input] Hi-Z
The PIC32 can implement all these, as well... (and more, e.g. [Input] pulled-down)
But, doing-so on *both* architectures, requires writing to a myriad of different registers. And, Not Only do those registers have different names on different architectures, not only do they have different *functionality*, but setting some of those configurations on *one* architecture might require multiple registers to be written, plausibly even with read-modify-writes, while setting that same configuration on another architecture might only require writing one register.
So, obviously, setting up different pin-configurations on these different architectures requires not only different *code*, but *also* different register-names.
BUT:
The cool thing about these architectures (and maybe this is true amongst most?) is that these registers are all located *relative* to each other, within the devices' memory-maps.
E.G. On the AVR (for *all* AVRs? I've only worked with a dozen or so varieties):
- PORTx is located at address (a)
- DDRx is located at address (a-1)
- PINx is located at address (a-2)
On the PIC32 (for *all* PIC32s? At least the MX-series...?)
- PORTx is located at (a)
- LATx at (a+0x10)
- CNPU at (a+0x30)
- TRIS at (a-0x10)
- and so on...
- Then, each _CLR/_SET/_INV register has its own offset relative to those
- PORTx_CLR at (a+0x4)
- PORTx_SET at (a+0x8)
- PORTx_INV at (a+0xC)
- LATx_CLR at (a+0x10+0x04)
- and so on...
SO... This knowledge makes pinoutting *perty-durn-easy* while *still* being architecture-unspecific...
Every GPIO pin, on both architectures (and probably most?), can be uniquely-referenced by its PORT-register and its bit-number...
Thus, e.g.
#define LED_BIT 3 #define LED_PORT PORTA
...are the only two things yah-needs-ta-list for any LED pin attached to any port on (any?) both architectures (this happens to correspond to pin PA3, on an AVR, or RPA3 on a PIC32).The remainder can be accomplished by nothing more than the macros in 'gpio_port'.
So, say you want to set the LED-pin as an output and turn it on (active-high):
gpioPORT_configurePinAsOutput(LED_PORT, LED_PIN); gpioPORT_outputOneToPin(LED_PORT, LED_PIN);But, again, for an AVR that would require, otherwise, keeping track of LED_BIT, LED_PORT, and LED_DDR.
For a PIC32 that would require, otherwise, keeping track of LED_BIT, LED_LAT, and LED_TRIS. (And, actually, LED_ANSEL, as well)
...
If we had to keep track of all that for *every* pin on *every* architecture, then feed the appropriate register to the appropriate macro... Yeah, talk about NON-architecture-unspecific.
So, just use _BIT and _PORT, and let the rest be handled by macros... and, in the end, in most cases, the math should be handled during compile time via the optimizer (or maybe even the preprocessor?), thus they'll result in *direct* writes to the *actual* register, rather than doing pointer-arithmetic during *every* call to determine *which* register to write.
(Again, these are *macros*, not *functions*, and their arguments are *expected to be* constants. (You could get away with non-constants, it'd function, but it would *definitely* be much slower))
Perty Handy... and at least a bit more architecture-unspecific.
And, having yet to meet many other architectures, I can only imagine some might have different predefined register names than, e.g., "PORTA" (maybe "port_reg0"?)... hey, as long as they have their various register-offsets in a predefined order (like DDRx = PORTx - 1, etc.) then it'd be just as easy to implement the associated macros for that architecture...
Sure, your LED_PORT wouldn't be as pretty as "PORTA", instead looking like "port_reg0", but functionally, it'd all be the same...
And, really, how often you think you're gonna use the same pinout on two *entirely* different architectures...? Hey, at least all ya's gots to do is find/replace a *couple* #defines for each pin, and can still use the same macros and the same arguments in the calls to those macros.
- PORTA
-
new... thing...(?)
06/18/2016 at 18:11 • 0 commentsSo I'm working on porting someone else's thing to another thing...
That "someone else" happened to use some pretty specific things to access their thing, and I'm working on abstracting those specific-accesses to work with my thing... (I'll call it my thing, merely in expression of differing it from the other person's thing which doesn't yet work with the thing I'm trying to make it work with, for my own purposes, which in-so-doing might just make it work with many others' things, with much less effort than currently necessary to make that person's thing work with other people's things).
hmm, sounds a heck of a lot like what I've been doing here... Abstracting things...? And, low-and-behold, in-so-doing, I've been kinda converting that thing to make use of this thing in order to make it work with mything. Hmm...
But, I don't particularly want to release "this thing" (nor most of my things) in its entirety via the typical licensing-thing that these things are typically licensed-under--despite the fact that that licensing-thing is exactly what enables things like this to become so common-place in the first place--because, frankly, there're a few side-things in that licensing-thing that I don't particularly agree with subjecting my efforts toward.
So, rather'n forcing this thing upon that thing, and either sacrificing my preferred-licensing-thing over their licensing-thing or forcing my licensing-thing upon their-thing, I'm thinking, instead, to release *portions* of this thing under that/their-licensing-thing as a means to (hopefully) better their thing and maybe even finally see this thing begin to enter into the usefulness-playing-field, to boot.
Who knows, it could be all hogwash, but it's a new concept I hadn't considered before...
I'll be less abstract when I actually get that thing working on my thing. But, as it stands, it looks like this thing is merging into that thing quite a bit more smoothly than I first-expected. Fun things!
Oh, for a tally, the new thing, so far, takes 6 bytes more program-space than the original thing, out of nearly 32KB, that ain't bad. And, I think, actually, that 6 bytes may be largely due to a mutex-bug I found/fixed in "that thing." So, in fact, it could be that all this abstraction and the benefits it may gain that thing might, in effect, have no noticeable *functionality*-consequences whatsoever... Which, admittedly, was kinda a big part of the goal, but a really nice surprise to see verified.
-
commonCode, commonCode, I haven't forgotten ye...
03/06/2016 at 11:38 • 0 commentscommonCode is one of those things I (generally) work on as a side-aspect of other projects...
So, lately, I've been working on my #Big Ol' Modular CNC and various aspects thereof... mostly the motor-control and position-sensing aspects, these days...
The latest is #anaQuad!, which will *definitely* be added as a new 'commonThing' soon. This guy... well, take a really low resolution analog-output optical encoder (like that from a computer's ball-mouse) and bump that resolution *way* up using an ADC. Currently I'm working with a 72-slot encoder-disk and anaQuad's able to resolve a resolution of 1152 positions per revolution, without adding a whole lot more processing-time than a regular-ol' quadrature-decoding algorithm (e.g. 'encoderDirect'). This guy also has the benefit of... if it somehow falls behind the actual motion, as long as it's less than half a slot, it'll eventually "catch up"... so no "invalid quadrature states".
I dig it.
---------------------------------------
I've been working with PIC32's for a bit, now... The *vast majority* of commonCode was developed on AVRs, so I'm coming up with new ways to make the system more 'architecture agnostic', and including those new discoveries in my progress with commonCode.
The latest, I guess, is that there seems to be a sort of "core" bit of code that remains almost completely unchanged, regardless of the architecture. Then there are certain architecture-(and project!)-specific aspects that that 'core' relies on...
E.G. for the 'heartBeat', there's the bit that handles the fading/blinking of the LED, knowing when to switch the pin to an input, waiting for pull-up resistors to overcome capacitances, then reading whether the button is pressed... That's the "core" of the heartBeat code.
Whereas, there's a tiny bit that's architecture/project-specific... E.G. *which* pin is used for the heartbeat...? How is that pin accessed...? (how do you make it an output, set it high or low, for the LED, and then switch it to an input for the pushbutton...?).
I went to a bit of effort to keep some sort of standardization, there, based not only on the switching of pinouts/projects, but also for the switching of architectures *while* keeping it backwards-compatible with old projects... I think I went about that wrong.
Rather'n telling the 'heartBeat' commonThing which *pin* to use, (which gets a bit complicated when switching between MCU's), instead, maybe, tell it *how to access* the pin...
So... heartBeat, now, has a few functions which must be defined specific to the project, something like "heart_setLED(on/off)", "heart_switchToInput()", "heart_readInput()". These guys are *REALLY* simple. heart_setLED(on/off) is basically nothing more than something like if(on) setBit(pinNum, PORT); else clearBit(pinNum, PORT). And, frankly, for the most-part, they can be the same for the vast-majority of projects, especially those on the same architecture.
So... where am I going with this...?
It gets a bit more complicated, e.g. with anaQuad, which makes use of ADCs... Each architecture's ADCs will have a different interface, different registers... so those will have to be set-up prior... So, anaQuad is supplied with a project-specific function for getting the values from the ADC...
OK, so this is where it gets interesting... There's no reason heartBeat's "heart_setLED()" function has to access a *pin*... It could do *anything*... It could, just as well, contain a 'printf()' call, that prints a '.' on a terminal-window when the LED should be off, or a '*' when it's on...
Or, for anaQuad, the "anaQuad_getChannelVal(A/B)" function could just as easily grab a value from a ... webpage... for all it cares.
This makes *testing* really easy... anaQuad's desktop-based test-application just fills the getChannelVal() functions with values from C's built-in sin() function (and a little math). But the *core* of anaQuad is usable on any architecture, from any sinusoidal (or maybe even triangular) source, with a tiny bit of configuration. So.......
I think this is where commonCode is going... Rather'n having several configuration-options, instead have a project-localized configuration file... (which, obviously, can be copied directly from project-to-project, as long as the architecture/pinout doesn't change).
Yeah... I guess this is pretty much the concept behind abstraction, in general... I never tried to claim I don't reinvent the wheel.
Oh, and, since those localized-functions are generally only called *once* within the "core", there's no reason they shouldn't be inlined (and plausibly optimized to nothing more than a single register read/write). So... it should be just-as-fast as my old method. (as opposed to, say, relying on supplying arguments and switching return-values).
Anyways... I haven't forgotten yah, commonCode... "You were always on my mind..."
-
'hfModulation' and motors
09/09/2015 at 16:32 • 0 commentsI never really figured I'd find a use for 'hfModulation' for motors, as generally PWM works well, and generally you want to minimize the number of level-transitions so the MOSFETs don't sit in the resistor/heat-producing state for too long/often... But I finally found a purpose for using it with motors, and there's a bunch of other info here about hfM and power-supplies. (TODO: put a bunch of this info as comments in the code!) And another blog-mention. Too Cool!
Oh, also, I think we determined with some amount of certainty that 'hfModulation' is actually "first-order delta-sigma modulation".
And, if you don't know, 'hfModulation' is used for several purposes including LED fading in 'heartbeat', pixel-stretching in 'lcdStuff', bit-stretching in 'polled_uar' and 'polled_uat', is used to increase the resolution on my 'racer' game's track, and several other things. It works well for purposes where division would otherwise be used within iterative loops.
-
System Design
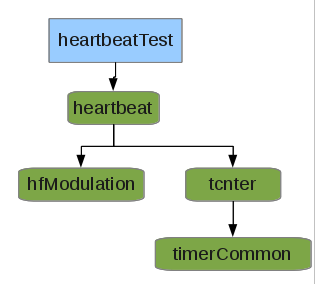
08/17/2015 at 16:12 • 0 commentsEach commonThing typically has three files: thing.h, thing.c and thing.mk (represented as a whole by the green boxes in the following diagrams).
The commonCode system handles automatic inclusion of nearly all aspects of each commonThing. E.G. for a simple test program for the 'heartbeat' commonThing, many other commonThings are included: hfModulation (which handles modulating/fading the LED), tcnter (which handles timing and is useful for many other purposes), and timerCommon (which handles the interface with the AVR's timer peripherals).
When using defaults, main.c can be as simple as:
#include _HEARTBEAT_HEADER int main(void) { heart_init(); while(1) { heart_update(); } }Optionally, the following can be added to the while() loop:
static int blink = 0; //0 = fading in and out, not blinking if(heart_getButton()) heart_setBlink(blink++);Since heartbeat is a good starting-point for (and useful in) most projects, its “test” code is a great place to start any project. Its 'makefile' contains all the necessary defaults and detailed explanations for each configuration option.
Note that heartbeat.h contains a usage-example, as shown above.
In the following examples, each of the additions are shown assuming you've started with the heartbeat test application.
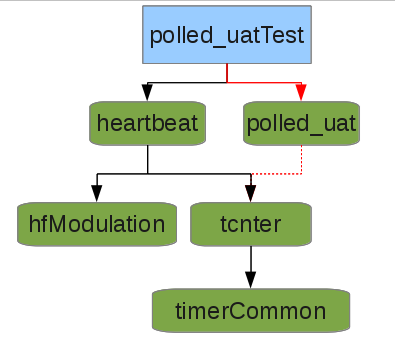
Addition of polled_uat (the bit-banged universal-asynchronous-transmitter) is as simple as adding the following lines to the original 'heartbeatTest' makefile:
VER_POLLED_UAT = 0.40 POLLED_UAT_LIB = $(COMDIR)/polled_uat/$(VER_POLLED_UAT)/polled_uat include $(POLLED_UAT_LIB).mkAnd this optional line defines the baud-rate:
CFLAGS += -D'BIT_TCNT=((TCNTER_SEC/9600))'This process may seem ugly/complicated, but it is thoroughly standardized throughout the commonCode system, so that adding another commonThing, regardless of its dependencies, is as simple as adding the first three lines, as appropriate. Doing-so includes several pieces of each commonThing, including: a makefile snippet which adds the commonThing to SRC for compilation, creates a macro for the #include statement which contains the proper version, (and, again, handles inclusion of dependencies, if not already included).
Then in the previous heartbeatTest's main.c add the following three lines in their respective locations (note the argument: 0. There can be multiple puats!):
#include _POLLED_UAT_HEADER_puat_init(0);
puat_update(0);
(and optionally: puat_sendByte(0, byte);, etc. as-desired).
Again, polled_uat.h contains a basic usage-example showing these lines and where they belong.That's it!
To make it a little bit more sophisticated, the following adds transmission of a Period '.' once every second (in the while() loop):
static tcnter_t lastTime = 0; if(tcnter_isItTime(&lastTime, TCNTER_SEC) puat_sendByte(0, '.');Note that tcnter_update() isn't called in the while() loop, because tcnter and heartbeat are both so commonly-used, tcnter_update() is by default automatically included in heart_update(). (This like many such defaults, can be changed and/or disabled by options in the makefile).
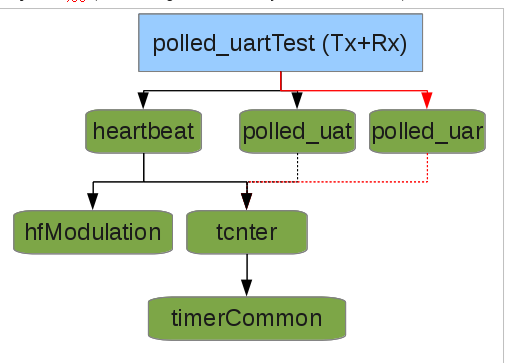
Now, let's add the polled_uar (the bit-banged universal-asynchronous-receiver):
polled_uar is another commonThing, so it's added in the same way as polled_uat (and, indeed heartbeat). Add these lines to the makefile:
VER_POLLED_UAR = 0.40 POLLED_UAR_LIB = $(COMDIR)/polled_uar/$(VER_POLLED_UAR)/polled_uar include $(POLLED_UAR_LIB).mk(BIT_TCNT, defined earlier, also applies to polled_uar)
And add these lines, in their appropriate locations, to main.c:
#include _POLLED_UAR_HEADERpuar_init(0);
puar_update(0);
The polled-uar, of course, has the ability to receive data, so something needs to be done with the data it receives, so to implement 'echo' you can add the following to the while() loop, after puar_update(0):
if(puar_dataWaiting(0)) puat_sendByte(0, puar_getByte(0));Conclusion:
As you can see, this standardized methodology is used throughout the commonCode system to include commonThings assuring only those necessary pieces get compiled into your application. Multiple versions of the same commonThings can exist on your development system, allowing improvement of one without interfering with another project being developed concurrently. Yet, well-tested/implemented bug-fixes, etc. can be implemented such that they trickle-down to all the projects which make use of that version of that commonThing. Options for each commonThing allow for sophisticated control over your project's implementation... These allow for speed-improvements, code-size reduction, control of things like baud-rate which will never change during run-time... Some specific examples include: changing the tcnter source to another timer-source (rather than the default AVR timer0), changing the heartbeat to use a different pin (rather than the AVR's default MISO pin), changing the baud-rates, pin-assignments, and/or number of puar/ts, and much more. These options are clearly explained in the respective commonThings' test-code's makefile. No changes are necessary to the commonThing's code itself, all options are implemented via project-specific configuration-options (usually added to the project makefile).
You can imagine, it gets significantly more complicated as the commonThings become higher-level. E.G. motion-control (with a motor) has many factors: Is speed-ramping used to accelerate/decelerate the motor(s) as they move from one position to another? The inclusion-tree can become quite complicated! Ramping requires sineTravel, which requires sineTable, positioning requires coordStuff, xyTracker, gotoPosition which requires holdPosition... these can all be included automatically by adding the three-lines in your makefile for 'gotoRamped', the appropriate gotoRamped_init() and gotoRamped_update() functions to main.c, (and, of course, your actual gotoRamp_setup() calls, which initiate the motion).
TODO:
It gets a bit more complicated when considering the lower-level/hardware details, such as: Positioning a motor... what kind of position-detection system does it use, a quadrature encoder? Is that quadrature-encoder connected directly to I/O pins, or does it go through a quadrature-decoder chip? What kind of modulation is used to control the motor power? What are the specific pin-requirements for the motor-driver/H-Bridge chip? These sorts of specifics could be handled by a driver when using an operating-system, but we're working “bare-metal...” so there needs to be some sort of standardized interface for these sorts of things. Similarly, these things don't change during runtime, so it really doesn't make sense to have, say, a motion_init() function which takes pointers to motor-control functions. Function-pointers, function arguments, etc. weigh heavily on resources! Especially if, in the end, the entire call could be boiled down (optimized, by the compiler) to nothing more than a couple lines of code, e.g. “writePin()” (which may boil down to nothing more than a single assembly instruction!)
These sorts of things have definitely been considered in much of commonCode. And as commonCode becomes more architecture-independent, it still attempts to retain these levels of optimization which are ideal for embedded architectures.
-
This is getting confusing... + video!
08/17/2015 at 07:33 • 0 commentsWhile, technically, these three projects are three *separate* projects (as in, they have different end-goals), they all feed into each other. I'm talking about:
- 'commonCode' (this project)
- #operation: Learn The MIPS (PIC32MX1xx/2xx)
- #2.5-3D thing
A description of these three projects, and how they feed into each other, follows the video, so be sure to click the "Read More" link!
Click "Read More!"
This "project," commonCode:
is an attempt to make available to the public the commonCode libraries/system I've been developing/using for over a decade. There's *quite a bit* to be done in this process... In addition to making the libraries/system available, there's also the plan to make them "architecture-independent," standardize the flow, and more. And, as (ironically) mentioned in another project's log (https://hackaday.io/project/6450-operation-learn-the-mips-pic32mx1xx2xx/log/20769-wins-and-tcnter):
Basically, as-of little more than a few months ago, I seldom looked at commonCode as a project of its own... it's always been developed/improved as a result of some other project[s] that makes use of it... I'm actually quite amazed at how much I accomplished that way, as looking at it *directly*, now, seems like a *huge* undertaking.
#operation: Learn The MIPS (PIC32MX1xx/2xx)
on the other hand, is a specific attempt at porting commonCode to a specific new architecture. In doing-so, however, I'm getting a first-hand look at quite a bit of underlying commonCode which has been buried deep for quite some time... and... making that stuff architecture-independent! (Woot! One of the end-goals of *this* project (commonCode)!)
In addition, of course, that project is also a great learning-experience for a new-to-me microcontroller architecture, and more. And, also, compiles quite a bit of getting-started info--from various scattered sources as well as utter banging-of-the-head-on-the-table--on getting a PIC32 running with a minimum of entry-requirements (software/hardware) that many "hackers" might already have laying around and can certainly be useful for other projects.
#2.5-3D thing
finally(ish), is a specific project based on the porting of commonCode to the PIC32... Its specific end-goal is a 2D or plausibly 3D Cartesian system to be used e.g. for pen-plotting, lasering, or maybe even CNC-routing. A side-result of using the PIC32 in this system is that doing-so will force me to revisit my motion-control related commonCode, and... make that stuff architecture independent (Woot! One of the end-goals of the other two projects!)
In addition, this Cartesian-system has turned a bit into a mechanical challenge which could be quite interesting... A tiny 3-axis system which is assembled from little more than one sheet of laser-cuts... a "business-card kit" of sorts, which once snapped-together could be like a hand-driven etch-a-sketch and an optional snap-on attachment for motors.
...others
I say "finally(ish)" above, because, again... nearly all my code-bearing projects from the past decade use and contribute to my commonCode system, making use of several commonThings. Wee!
-
the main-three now on PIC32
08/11/2015 at 14:34 • 0 commentsThe 'main three' are now running on PIC32: 'heartbeat', 'polled-uat' and 'polled-uar'...
so we have I/O, timers, and a bitbanged UART. Now on to motion-control: #2.5-3D thing
See more about the PIC32 porting-process at: https://hackaday.io/project/6450/log/22496-finally and #operation: Learn The MIPS (PIC32MX1xx/2xx)
commonCode (not exclusively for AVRs)
A shit-ton of things that are useful for a shit-ton of projects. (and, Think 'apt-get' for reusable project-code)