M. Bindhammer
M. Bindhammer-
Working on Murphy's torso
04/30/2016 at 07:21 • 0 commentsAn APDS-9960 RGB and gesture sensor acts as a low level machine vision to recognize gestures and colors of objects. The image below shows the hooked up sensor. A bi-directional logic level converter is needed for 5 V micro-controllers, because the APDS-9960 works only with a VCC of 2.4 - 3.6 V.
![]()
Wiring diagram:
![]()
Sensor mounted on Murphy's head:
![]()
Backside of the torso with Arduino Mega, servo power supply and EMIC-2 carrier board:
![]()
-
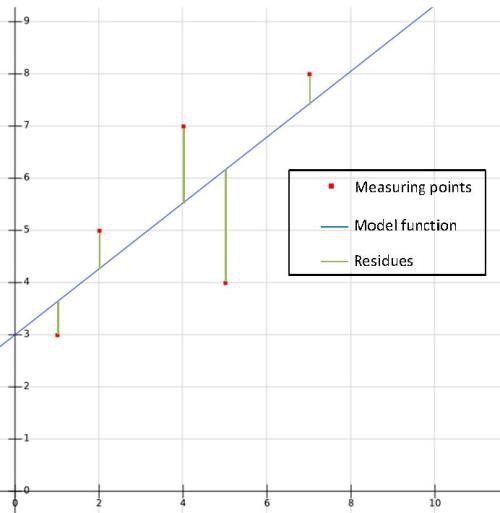
Simple linear regression
04/21/2016 at 09:20 • 0 commentsLinear regression can be used for supervised machine learning. The graph below shows measuring points (input and output values) and its distance (residues) to a function computed by the method of least squares (line).
![]()
The model function with two linear parameters is given by
For the n input and output value pairs (x_1,y_1),...,(x_n,y_n) we are searching for the parameter a0 and a_1 of the best fitting line. The according residues r between the wanted line and the input and output value pairs are computed by:
Squaring and summation of the residues yields:
The square of a trinomial can be written as:
Hence:
We consider the sum function now as a function of the two variables a_0 and a_1 (the values of the learned data set are just considered as constants) and compute the partial derivative and its zero:
Solving the system of linear equations:
Substituting
as the arithmetic mean of the y-values and
we get:
Replacing a_0 in the equation
yields
Because
For a new input value
the new output value is given by
or
-
Markov chains
04/20/2016 at 07:27 • 0 commentsA mind must be able to predict the future to some extent to do any planning. In the following example Markov chains are used to develope a very simple weather model (should I take my umbrella tomorrow, Murphy?). The probabilities of weather conditions (rainy or sunny), given the weather on the preceding day, are represented by the transition matrix:
The matrix P represents the weather model in which the probability that a sunny day followed by another sunny day is 0.9, and a rainy day followed by another rainy day is 0.5. Markov chains are usually memoryless. That means, the next state depends only on the current state and not on the sequence of events that preceded it. But we can change the inital state if we have other experiences to model the weather or something else. One more note: Columns must sum to 1 because it's a stochastic matrix.
The weather on the current day 0 is either sunny or rainy. This is represented by the following vectors (100% sunny weather and 0% rainy weather or 0% sunny weather and 100% rainy weather):
The general rule for day n is now:
or equally
This leaves us with the question how to compute these matrices multiplications for our example:
Let us assume the weather on day 0 is sunny, then weather on day 1 can be predicted by:
Hence, the probability that the day 1 will be sunny is 0.9.
Applying the general rule again, weather on day 2 can be predicted by:
-
Language center
04/18/2016 at 18:55 • 0 commentsLanguage areas of the human brain are located at the Angular Gyrus, Supramarginal Gyrus, Broca's area, Wernicke's area and the Primary Auditory Cortex.
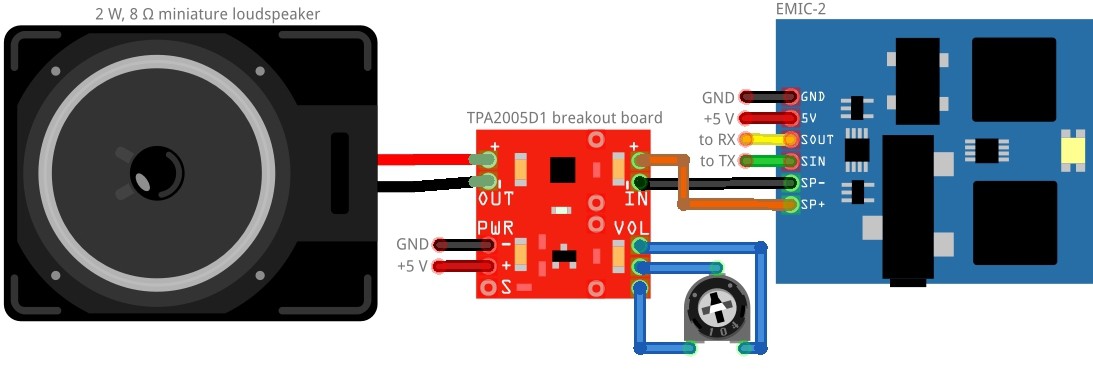
Murphy's language center consists of a 2 W, 8 Ω miniature loudspeaker, an EMIC-2 text-to-speech module and a TPA2005D1 breakout board. Both PCB's do not have mounting holes, so I designed a carrier board:
![]()
Populated and under testing (10k potentiometer for volume control still not added):
![]()
Wiring diagram:
![]()
Important note: The EMIC-2 does not work properly with Arduino hardware serial. Use the SoftwareSerial Library instead.
Demonstration video below. Do you know which movies contain these quotes?
-
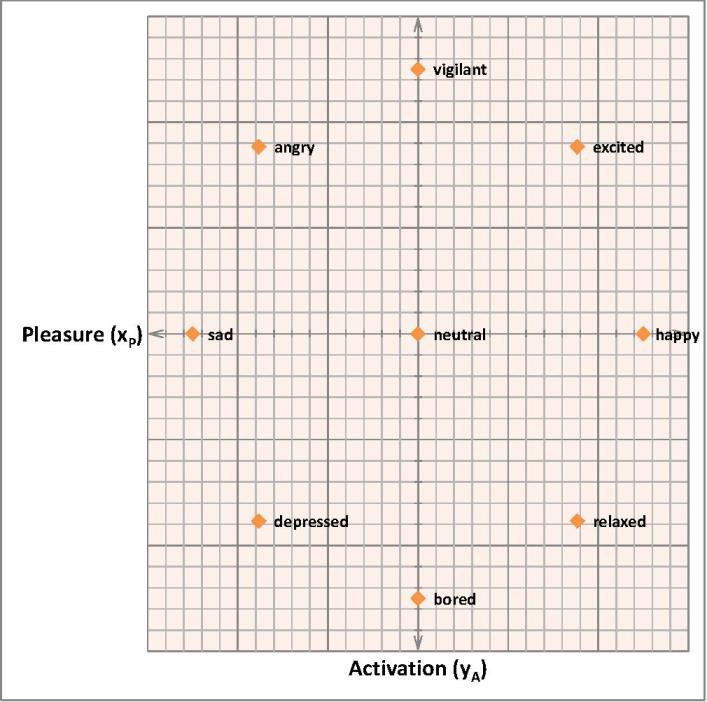
Emotional agent
04/13/2016 at 17:11 • 2 commentsThis log starts with the so called circumplex model of affect. Re-drawn and simplified model:
![]()
You might notice, that this model implicates the use of the KNN algorithm immediately. More formally: let the sample space be a 2-dimensional Euclidean space IR², the center coordinates (0,0) and the radius r ∈ IR > 0, then our classes are located at:
andA remark about Pleasure and Activation before we continue: Activation could be seen as a kind of entropy of the robot in a physical sense, depending for instance on the ambient light level and temperature. Pleasure could be seen as a success rate of a given task the robot has to fulfill or to learn.
The distance between two points in a 2-dimensional Euclidean space is given by
which follows directly from the Pythagorean theorem.
With the defined boundaries we get a maximum distance between a class point and a new sample point of:
Here is a little sketch I wrote to demonstrate how the emotional agent works:
const float r = 5.0; void setup() { Serial.begin(9600); Emotional_agent(5, 0); } void loop() { } void Emotional_agent(float x_P, float y_A) { if(x_P < - r) x_P = - r; // limit the range of x_P and y_A else if(x_P > r) x_P = r; if(y_A < - r) y_A = - r; else if(y_A > r) y_A = r; float emotion_coordinates[2][9] = { {0.0, 0.0, r, - r, 0.0, r/sqrt(2.0), - r/sqrt(2.0), r/sqrt(2.0), - r/sqrt(2.0)}, // x-coordinate of training samples {0.0, r, 0.0, 0.0, -r, r/sqrt(2.0), r/sqrt(2.0), - r/sqrt(2.0), -r/sqrt(2.0)} // y- coordinate of training samples }; char *emotions[] = {"neutral", "vigilant", "happy", "sad", "bored", "excited", "angry", "relaxed", "depressed"}; byte i_emotion; byte closestEmotion; float MaxDiff; float MinDiff = sqrt(2.0) * r + r; //set MinDiff initially to maximum distance that can occure for (i_emotion = 0; i_emotion < 9; i_emotion ++) { // compute Euclidean distances float Euclidian_distance = sqrt(pow((emotion_coordinates[0][i_emotion] - x_P),2.0) + pow((emotion_coordinates[1][i_emotion] - y_A),2.0)); MaxDiff = Euclidian_distance; // find minimum distance if (MaxDiff < MinDiff) { MinDiff = MaxDiff; closestEmotion = i_emotion; } } Serial.println(emotions[closestEmotion]); Serial.println(""); } -
Machine learning
04/13/2016 at 12:49 • 0 commentsHere I will briefly discuss the concept behind the learning robot and its environment based on the variable structure stochastic learning automaton (VSLA). This will enable the robot to learn similar like a child.
First of all, the robot can choose from a finite number of actions (e.g. drive forwards, drive backwards, turn right, turn left). Initially at a time t = n = 1 one of the possible actions α is chosen by the robot at random with a given probability p. This action is now applied to the random environment in which the robot "lives" and the response β from the environment is observed by the sensor(s) of the robot.
The feedback β from the environment is binary, i.e. it is either favorable or unfavorable for the given task the robot should learn. We define β = 0 as a reward (favorable) and β = 1 as a penalty (unfavorable). If the response from the environment is favorable (β = 0), then the probability pi of choosing that action αi for the next period of time t = n + 1 is updated according to the updating rule Τ.
After that, another action is chosen and the response of the environment observed. When a certain stopping criterion is reached, the algorithm stops and the robot has learned some characteristics of the random environment.
We define furthermore:
is the finite set of r actions/outputs of the robot. The output (action) is applied to the environment at time t = n, denoted by α(n).
is the binary set of inputs/responses from the environment. The input (response) is applied to the robot at time t = n, denoted by β(n). In our case, the values for are β chosen to be 0 or 1. β = 0 represents a reward and β = 1 a penalty.
is the finite set of probabilities a certain action α(n) is chosen at a time t = n, denoted by p(n).
Τ is the updating function (rule) according to which the elements of the set P are updated at each time t = n. Hence
where the i-th element of the set P(n) is
with i = 1,2,...,r,
and
is the finite set of penalty probabilities that the action αi will result in a penalty input from the random environment. If the penalty probabilities are constant, the environment is called a stationary random environment.
The updating functions (reinforcement schemes) are categorized based on their linearity. The general linear scheme is given by:
If α(n) = αi,
where a and b are the learning parameter with 0 > a,b < 1.
If a = b, the scheme is called the linear reward-penalty scheme, which is the earliest scheme considered in mathematical psychology.
For simplicity we consider the random environment as a stationary random environment and we are using the linear reward-penalty scheme. It can be seen immediately that the limits of a probability pi for n → ∞ are either 0 or 1. Therefore the robot learns to choose the optimal action asymptotically. It shall be noted, that it converges not always to the correct action; but the probability that it converges to the wrong one can be made arbitrarily small by making the learning parameter a small.
-
Power management
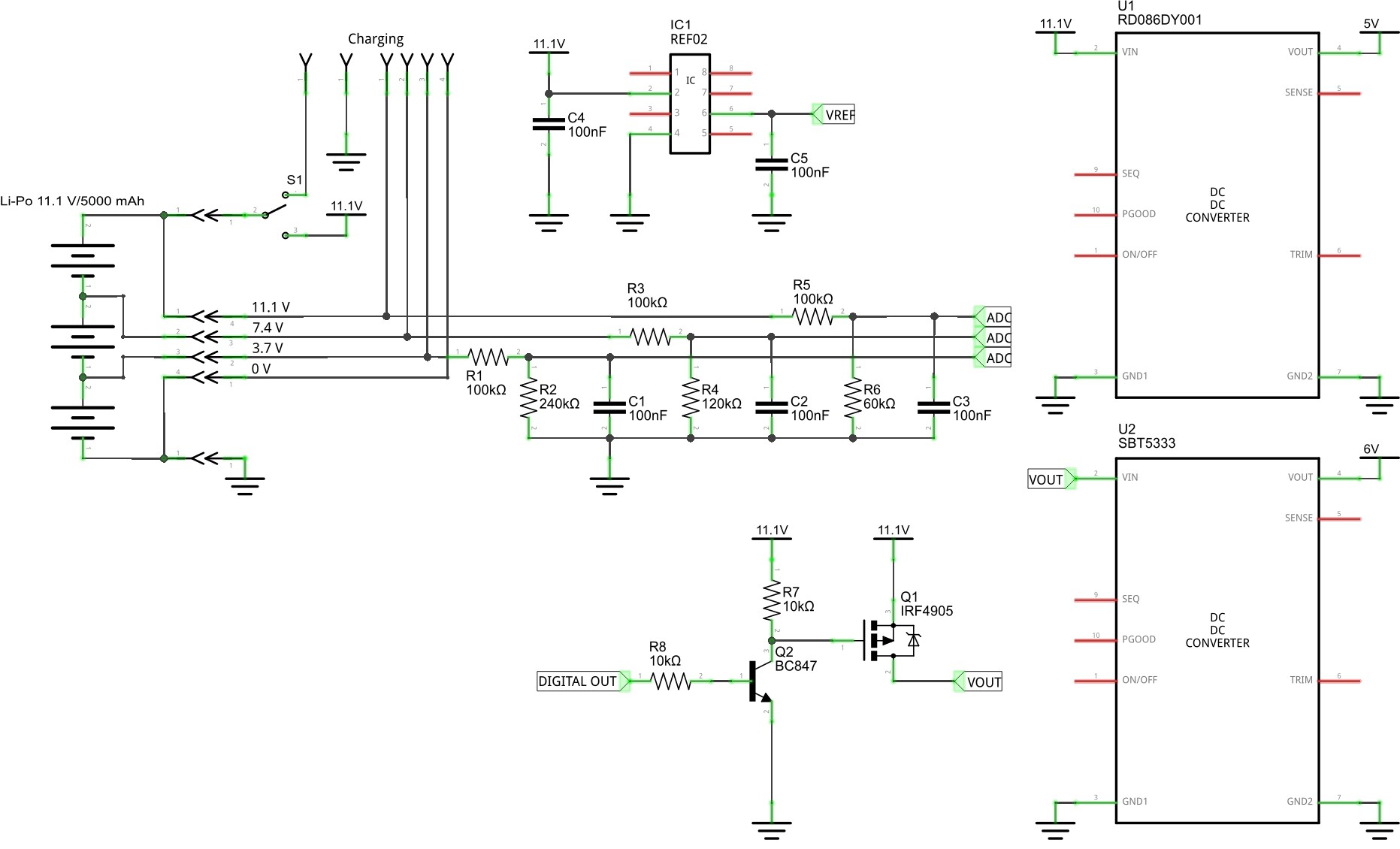
04/11/2016 at 08:40 • 0 commentsLithium Polymer (Li-Po) is the most likely battery chemistry choice for small robots due to its high energy density and output current capabilities. But Li-Po cells can be dangerous if not treated properly. A safe Li-Po cell needs to be protected against over-voltage, under-voltage, and over-current to prevent damage to the cell, overheating, and possibly fire. The power management subsystem built into Murphy is shown in this block diagram:
![]()
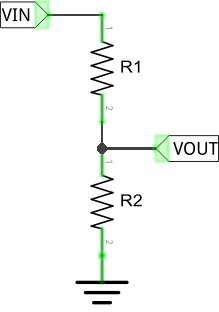
A Li-Po cell has a no-load resting voltage of 4.2 V when fully charged and 3.7 V when discharged. The Arduino is running at 5 V, so the maximum voltage we can measure with the on-board analog ports is 5 V. The balance port on cell 3 of the 11.1 V Li-Po battery can reach 12.6 V, so we need a way of reducing this to ≤ 5 V. A common way is to use a voltage divider. A voltage divider is a simple circuit which turns a large voltage into a smaller one. Theory is simple:
![]()
VREF of the Arduino is not very precise. Fortunately you can easily attach an external VREF. Therefore I added a REF02 on the board which provides a reference voltage of + 5V ± 0.2% max. Values of the resistors in the block diagram above are just fantasy values for now. You can change them as you wish. The 3.7 V balance connection port does not need a voltage divider at all. But I prefer to use at least a series resistor. Important is to keep the power consumption of the voltage dividers at a minimum. Capacitors C1 - C3 should reduce noise.
The P-channel power MOSFET IRF4905 will shut down the load (servos, motors) in case of low battery if the digital output connected to the base of transistor Q2 goes LOW. In any organism activities will be reduced to a minimum if no nutrients are available anymore. Brain will die at the very end. Same here. Brain will die at the same moment the battery will die. Instinct of self preservation is the most important instinct. It will not work if the brain dies off first.
Populated and tested power management PCB:
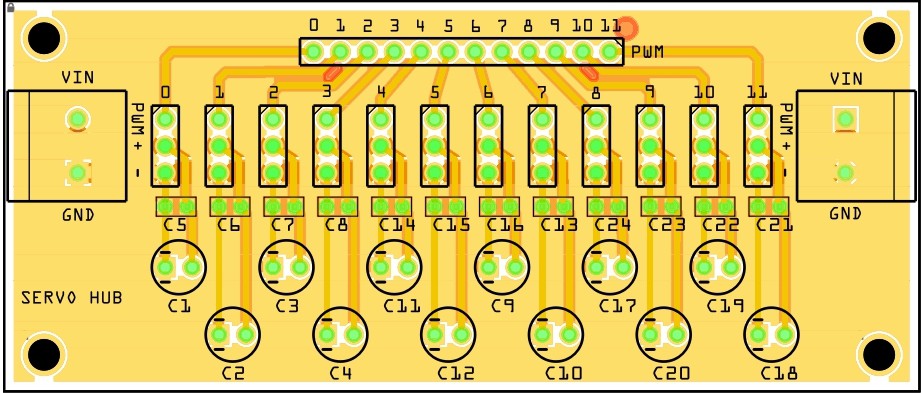
![]() To avoid any servo jitter I designed a special power rail for the servos. Basically every servo has its own decoupling and filter capacitor:
To avoid any servo jitter I designed a special power rail for the servos. Basically every servo has its own decoupling and filter capacitor:![]()
Bare PCB:
![]()
And populated PCB:
![]()
In general analog servos are more prone to jitter even with sufficient power supply so I will replace all MG 995 by its digital version MG946R.
-
Building the differential wheeled robot base
04/07/2016 at 18:41 • 2 commentsUsed a coping saw again to cut out the bottom and top plate of the differential wheeled robot base. No human walking. Murphy is using a kind of wheel chair to move forward - or in any other direction. A plain old differential wheeled robot.
Material 2 mm aluminum sheet. Cut out the two parts separately, then screwed them together, grinded and sanded them till they matched perfectly.
![]()
Holders for the HC-SR04 ultrasonic sensors, which are placed on the three front and back edges of the bottom plate, will be 3-D printed as it is quite difficult to drill 18 mm holes accurately with a simple drill press I have. There is always a lot of shift at such big drilling diameters.
![]()
![]()
Robot will move slow, because organic chemistry is usually slow (beside explosive chemistry and such). Slowness of organic reactions is a necessary condition for a longer life span of organisms. We human beings are driven and controlled by organic processes beside a little electrochemistry. Suppose digestion of a meal would be according to inorganic reactions finished in a couple of seconds or minutes. A few hundred calories would be released at once, and a part of the muscle apparatus would positively burn under the immense heat or damaged otherwise. A short time after cooling occurred the organism would suffer from hunger again and new food intake would be needed.
Robot torso mounted on the upper plate, enjoying the beauty of an orchid:
![]() Bottom plate with metal gear-motors 25D x 56L mm, LP 12V, 48 CPR encoder, 80 x 10 mm Pololu wheels and free turning casters finished:
Bottom plate with metal gear-motors 25D x 56L mm, LP 12V, 48 CPR encoder, 80 x 10 mm Pololu wheels and free turning casters finished:![]()
![]()
Battery, motor driver, Arduino and 5 V DC-DC-converter attached to perform first drive tests:
![]()
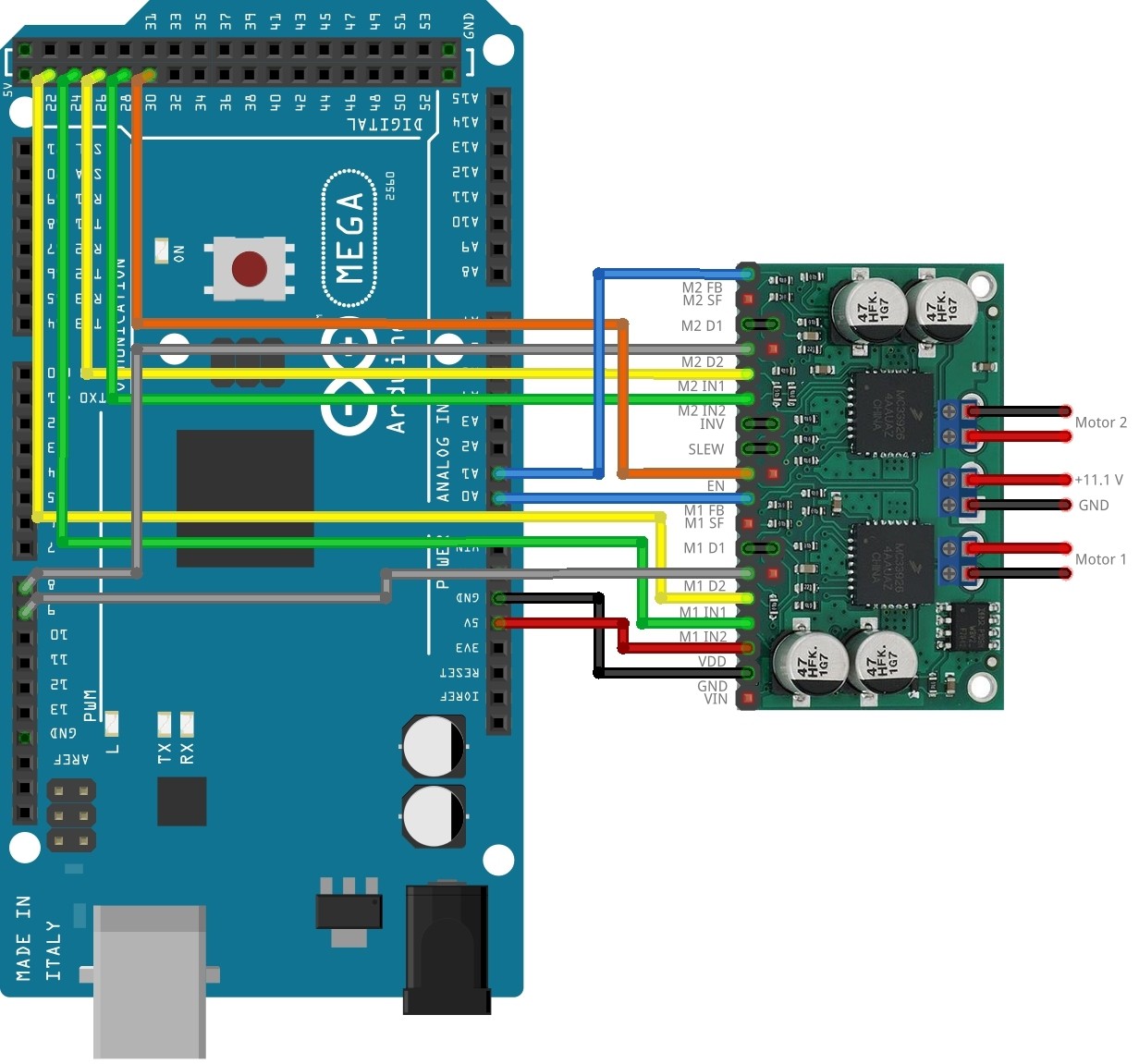
Wiring diagram dual mc33926 motor driver carrier/Arduino Mega:
![]() Ultrasonic sensors, 6 V DC-DC converter, ON/OFF switch and accelerometer added:
Ultrasonic sensors, 6 V DC-DC converter, ON/OFF switch and accelerometer added:![]()
![]()
![]()
Wiring of the ultrasonic sensors completed:
![]()
Nearly finished robot base:
![]()
-
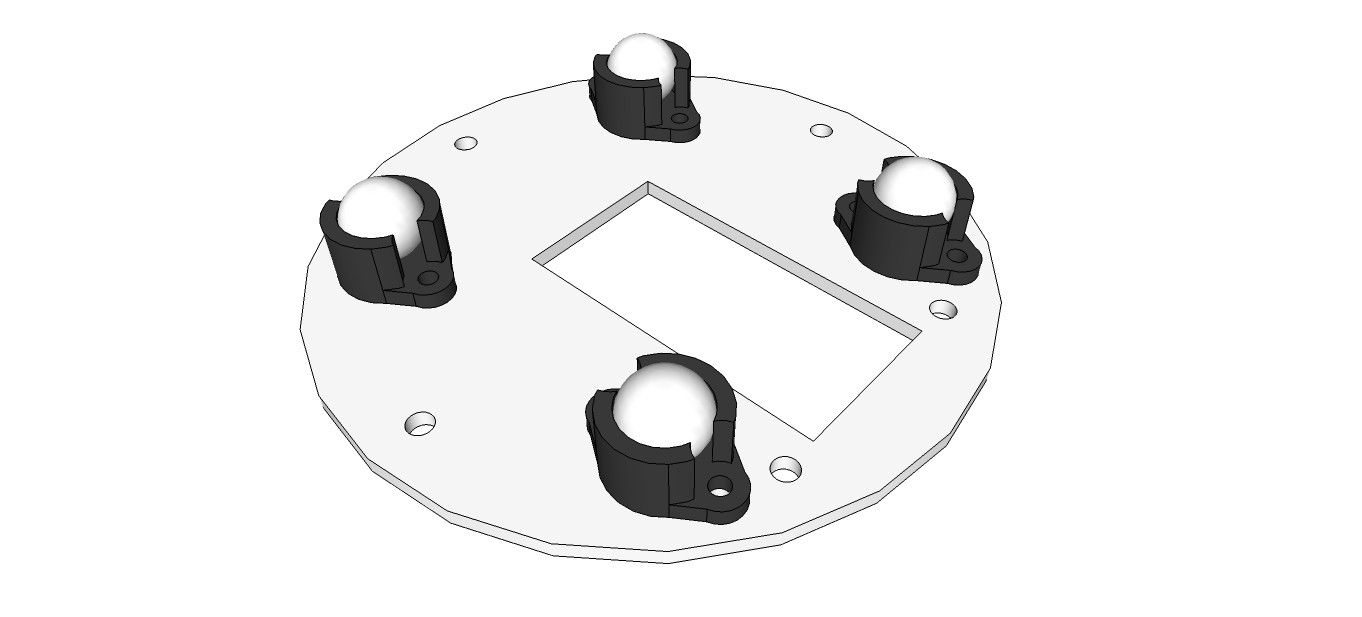
Building the base rotate unit
04/04/2016 at 16:41 • 0 commentsI started with a quick sketch to get components and boreholes placed:
![]()
Next I cut out two discs dia. 80 mm from a 3 mm aluminum sheet with a coping saw. A metal lathe or a laser cutter would have been nice, but I don't own one of these machines, so a lot of grinding and sanding was required. The trick is to fix the discs with a screw and a nut on the chuck of a drill press and use a file and sanding paper to smooth the edges while they are rotating.
![]()
Further progress:
![]()
![]()
Base rotate unit successfully assembled on upper body:
![]()
Humanoid robot named Murphy
Created to explore new ways of artificial intelligence















 Ultrasonic sensors
Ultrasonic sensors