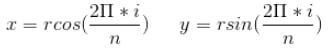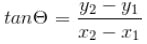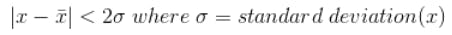Use Android Studio to open this project and update the workspace file with the location and API version of the SDK and NDK.
Set “def nativeBuildSystem” in build.gradle to ‘none’
Download quantized Mobilenet-SSD TF Lite model from here and unzip mobilenet_ssd.tflite to assets folder,
Copy frozen_inference_graph.pb and label_map.pbtxtto the “assets” folder above. Edit the label file to reflect the classes to be identified.
Update the variables TF_OD_API_MODEL_FILE and TF_OD_API_LABELS_FILE in DetectorActivity.java to the above filenames with prefix “file:///android_asset/”
Build the bundle as an APK file using Android Studio and install it on your Android mobile. Execute TF-Detect app to start object detection. The mobile camera would turn on and detect objects in real-time.
I have taken 300 images of household chairs, annotated them, and did the above steps to deploy on Android mobile to prove the concept. See the mobile is able to detect generic chairs in real-time.
Mobile able to detect custom chairs inside house in real-time
You can train the object detection model on your local if you have GPU. If not, you can do in EdgeImpulse or Roboflow to host the dataset to Colab. Data cleansingandaugmentation are easier done with Roboflow, and you can export the data in multiple formats. Implementation of some object detection models is also given here in roboflow models. Alternatively, you can extend the pre-trained models in OpenVINO model zoo by following the steps here.
These are the steps followed to do custom object detection on Raspberry Pi.
Custom Object Detection on Pi
It is possible to train an object detection model with your custom annotated data and do hardware optimization using OpenVINO and deploy on Pi, as long as the layers are supported by OpenVINO. By doing so, we can deploy an object detection model on RPi, to locate custom objects.
1. First, choose an efficient object detection model such as SSD-Mobilenet, Efficientdet, Tiny-YOLO, YOLOX, etc which are targeted for low power hardware. I have experimentedwith all the mentioned models on RPi 4B and SSD-Mobilenet fetched maximum FPS.
2. Do transfer learning of object detection models with your custom data
3. Convert the trained *.pb file to Intermediate representation - *.xml and *.bin using Model Optimizer.
Probably the only downside of the mathematical method may be, sensitivity to extreme lighting conditions or the need for an external object (other than your body), to trigger the alarm. To address this drawback, we can also use gesture recognition models optimized by OpenVINOto recognize sign languages and trigger alerts. You can also train a custom gesture of your own, as explained here.
"Help Please" Gesture to trigger an alarm
However, some layers of such OpenVINO models are not supported by MYRIAD device as given in the table here. Hence, this module needs to be hosted on a remote server as an API.
After doing object localization and tracking, we need to detect the gesture made using the object. The gesture needs to be simple so that it is efficient to detect. Let's define the gesture to be circular motion and then try to detect the same.
i)Auto-Correlated Slope Matching
Generate ’n’ points along the circumference of a circle, with radius = r
Compute slopes of the line connecting each point in the sequence,
Generate point cloud using any of the object localization Methods above. For each frame, add the center of the localized object to the point cloud.
Compute slopes of the line connecting each point in the sequence.
Compute correlation of slope curves generated in the above steps.
Find the index of the maxima of the correlation curve using np.argmax()
Rotate the point cloud queue by index value for the best match
Compute circle similarity = 1- cosine distance between point clouds
If correlation > threshold, then the circle is detected and alert triggered.
Upon implementation, the above algorithm is found working. But in practice, the distance between the localized points varies based on rotation speed and FPS. Another neat and simpler solution would be to use Linear Algebra to check whether the movement of points is convex or concave.
ii) ConcavityEstimationusing Vector Algebra
If all the vectors in the point cloud is concave, then it represents circular motion.
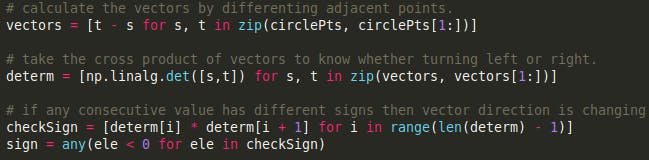
Compute the vectors by differencing adjacent points.
Compute vector length using np.linalg.norm
Exclude the outlier vectors by defining boundary distribution
If the distance between points < threshold, then ignore the motion
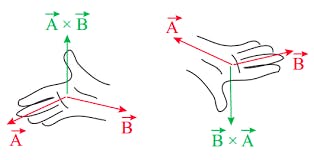
Take the cross product of vectors to detect left or right turns.
If any consecutive value has a different sign, then the direction is changing. Hence, compute a rolling multiplication.
Find out the location of direction change (where ever indices are negative)
Compute the variance of negative indices
If all rolling multiplication values > 0, then motion is circular
If the variance of negative indices > threshold, then motion is non-circular
If % of negative values > threshold, then motion is non-circular
Based on the 3 conditions above, the circular gesture is detected.
From the experiments, it became clear that we can use Object Color Masking (to detect an object) and use efficient algebra-based concavity estimation (to detect a gesture). If the object is far, then only a small circle would be seen. So we need to scale up the vectors based on object depth, not to miss the gesture. For the purpose of the demo, we will deploy these algorithms on an RPi with a camera and see how it performs. Now let's see the gesture detection mathematical hack as code.
# loop over the set of tracked pointsfor i in range(1, len(pts)):
# if either of the tracked points are None, ignore themif pts[i - 1] isNoneor pts[i] isNone:
continue# otherwise, compute the thickness of the line and draw the connecting lines
thickness = int(np.sqrt(args["buffer"] / float(i + 1)) * 2.5)
cv2.line(frame, pts[i - 1], pts[i], (0, 0, 255), thickness)
isCirclePts = [p for p in pts if p isnotNone]
if (len(isCirclePts) > 30):
vectors = [np.subtract(t, s) for s, t in
zip(isCirclePts, isCirclePts[1:])]
vectors = [vector for vector in vectors
if np.linalg.norm(vector) > 5]
# To find concavity, check vector direction using Right Hand rule
determ = [np.linalg.det([s, t])
for s, t in zip (vectors, vectors[1:])]
directionChange = [determ[i] * determ[i + 1]
for i in range (len(determ) - 1)]
# when the movement of the object is # insignificant, consider it stationaryif len(directionChange) < 10:
alarmTriggered = Falsecontinue
In order to do gesture recognition, first, we need to identify or localize the object used to signal the gesture. 3 different methods are implemented and compared as below.
i) Object Detection
I have used hardware optimized YOLO to detect, say a cell phone, and easily get 5-6 FPS on 4GB Raspberry Pi 4B with Movidius NCS 2. We trained YOLO to detect a custom object such as a hand. But the solution is not ideal as NCS stickwill hike up the product price (vanilla YOLO gives hardly 1 FPS on 4GB RPi 4B).
ii) Multi-scale Template Matching
Template Matching is a 2D-convolution-based method for searching and finding the location of a template image, in a larger image. We can make template matching translation-invariant and scale-invariant as well.
Generate binary mask of template image, using adaptive thresholding.
Grab the frame from the cam and generate its binary mask
Generate linearly spaced points between 0 and 1 in a list, x.
Iteratively resize the input frame by a factor of elements in x.
Do match template using cv2.matchTemplate.
Find the location of the matched area and draw a rectangle.
Hand Detection using Multi-Scale template matching
But to detect gesture, which is a sequence of movements of an object, we need stable detection across all frames. Experiments proved hand template multi-scale matching is not so consistent to detect an object in every frame. Moreover, template matching is not ideal if you are trying to match rotated objects or objects that exhibit non-affine transformations.
iii) Object Color Masking using Computer Vision
It is very compute-efficient to create a mask for a particular color to identify the object based on its color. We can then check thesizeand shape of the contour to confirm the find. It would be prudent to use an object with a distinct color to avoid false positives.
This method is not only highly efficient and accurate but it also paves the way to do gesture recognition using pure mathematical models, making it an ideal solution on the Edge. Hence, this method is chosen for object localization.
Any access control or attendance system needs to be fake-proof. It's possible to cheat the above system by showing a photo of a registered person. How can we differentiate a real human vs a photo?
We can treat "liveness detection" as a binary classification problem and train a CNN to distinguish real faces from fake ones. But this would be expensive on the edge. Alternatively, we can detect spoofing,
1. In 3D: Using light reflections on the face. Might be overkill on edge devices.
2. In 2D: We can do eyewink detection in 2D images. Feasible on edge devices.
To detect eye winks, it's most efficient to monitor the change in white pixel count around the eye region. But it's not as reliable as monitoring the EAR (Eye Aspect Ratio). If the Eye Aspect Ratio rises and falls periodically then it's a real human, otherwise fake. The rise and fall can be detected by fitting a sigmoid or inverse sigmoid curve.
Identifying open vs closed eye based on the count of white pixels
Instead, we can always use Deep Learning or ML techniques to classify an eye image as open or closed. But it's advisable, in the interest of efficiency, to use a numerical solution when you code for edge devices. See how the spread of non-zero pixels in the histogram takes a sudden dip when an eye is closed.
Histogram Spread during Left Eye Wink
We have used a parametric curve fit algorithm to fit a sigmoid or inverse sigmoid functionat the tail end of the above curve to detect eye open or close events. The person is a real human if any such event occurred.
Inverse Sigmoid Curve Fitting: Left and Right Eye Wink
# Code to fit the inverse sigmoid curve to tail end of signaldefsigmoid(x, L ,x0, k, b):
y = L / (1 + np.exp(k*(x-x0)))+b
return (y)
defisCurveSigmoid(pixelCounts, count):try:
xIndex = len(pixelCounts)
p0 = [max(pixelCounts), np.median(xIndex),1,min(pixelCounts)] # this is an mandatory initial guess
popt, pcov = curve_fit(sigmoid, list(range(xIndex)), pixelCounts, p0, method='lm', maxfev=5000)
yVals = sigmoid(list(range(xIndex)), *popt)
# May have to check for a value much less than Median to avoid false positives.if np.median(yVals[:10]) - np.median(yVals[-10:]) > 15:
print('Event Triggered...')
returnTrueexcept Exception as err:
print(traceback.format_exc())
returnFalsedeffindCurveFit(eye, image, pixelCount, frame_count, numFrames = 50):
triggerEvent = Falseif (len(image) == 0):
return pixelCount, False# Convert to gray scale as histogram works well on 256 values.
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# calculate frequency of pixels in range 0-255
histg = cv2.calcHist([gray],[0],None,[256],[0,256])
# hack to know whether eye is closed or not.# more spread of pixels in a histogram signifies an opened eye
activePixels = np.count_nonzero(histg)
pixelCount.append(activePixels)
if len(pixelCount) > numFrames and frame_count % 15 == 0:
if isCurveSigmoid(pixelCount[-numFrames+10:], len(pixelCount)):
print('Event Triggered...')
pixelCount.clear()
plt.clf()
triggerEvent = Truereturn pixelCount, triggerEvent
The information about identified persons in subsequent frames is published via MQTT, if they are not detected in the last 'n' frames. Another MQTT client subscribed to the 'attendance' topic, will receive this information. On the reception side, the information is collated and inserted into a MySQL database that serves as the attendance register.
See the auto-generatedentry register database on the MQTT reception side.
Database view of Door Entry register
We can extend the system by pushing the data to the cloud or by building a front end to track or analyze the above data.
We need to find out the distance to the person from the door. This can be estimated using a proximity sensor or by using LIDAR along with the subtending angles. As we have already integrated LIDAR for other solutions, here we intend to estimate depth using LIDAR by computing the median distance of LIDAR laser points between two subtending angles, based onLIDAR -Picamposition (triangulation)
defgetObjectDistance(angle_min, angle_max):
minDist = 0
lidar = RPLidar(None, PORT_NAME)
try:
for scan in lidar_scans(lidar):
for (_, angle, distance) in scan:
scan_data[min([359, floor(angle)])] = distance
# fetching all non zero distance values between subtended angles
allDists = [scan_data[i] for i in range(360)
if i >= angle_min and i <= angle_max and scan_data[i] > 0]
# if half the distance values are filled in then breakif (2 * len(allDists) > angle_max - angle_min):
minDist = np.min(allDists)
lidar.stop()
lidar.disconnect()
return minDist
except KeyboardInterrupt:
print('Stoping LIDAR Scan')
First, I have assembled the system as shown below. During the initial setup, the system built an image database of known persons. During the registration process, an affine transformation is applied after detecting the facial landmarks of the person, to get the frontal view. These images are saved and later compared, to identify the person.
Assembled Gadget: RPi with LiDAR and NCS2 on batteryThe face recognition models done in OpenVINO are deployed to RPi, which is integrated with a Pi Cam and LIDAR. If the person is identified and is near to the door, then the 'door open' event is triggered. If someone is near the door but not recognized then a message should be pushed to the security's mobile. This is simulated by flashing 'green' and 'red' lights respectively, on a Pimoroni Blinkt! controlled using MQTT messages.
In order to avoid repeated triggers, the message gets published only when the same person is not found in the last 'n' frames. This is implemented with a double-ended queue to store identified information. If the person is identified, then the greeting message is pushed via the eSpeak text-to-speech synthesizer. Prior to this, the voice configuration setup was done in Pi.
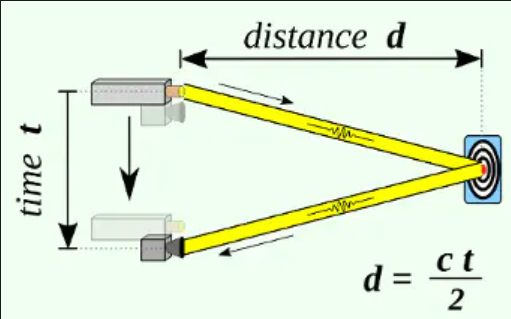
LIDAR uses laser beams to compute distance based on reflection time.
Laser Range-Finding [1]. c = Speed of Light.
Cameras generally have higher resolution than LiDAR but cameras have a limited FOV and can't estimate distance. While rotating LIDAR has a 360° field of view, Pi Cam has only 62x48 degreesHorizontal x Vertical FoV. As we deal with multiple sensors here, we need to employ visual fusion techniques to integrate the sensor output, to get the distance and angle of an obstacle in front of the vehicle. Let's first discuss the theoretical foundation of sensor fusion before hands-on implementation.
The Sensor Fusion Idea
Each sensor has its own advantages and disadvantages. Take, for instance, RADARs are low in resolution, but are good at measurement without a line of sight. In an autonomous car, often a combination of LiDARs, RADARs, and Cameras are used to perceive the environment. This way we can compensate for the disadvantages, by combining the advantages of all sensors.
Camera: excellent to understand a scene or to classify objects
LIDAR: excellent to estimate distances using pulsed laser waves
RADAR: can measure the speed of obstacles using Doppler Effect
The camera is a 2D Sensor from which features like bounding boxes, traffic lights, lane divisions can be identified. LIDAR is a 3D Sensor that outputs a set of point clouds. The fusion technique finds a correspondence between points detected by LIDAR and points detected by the camera. To use LiDARs and Cameras in unison to build ADAS, the 3D sensor output needs to be fused with 2D sensor output by doing the following steps.
Project the LiDAR point clouds (3D) onto the 2D image
Do object detection using an algorithm like YOLOv4
Match the ROI to find the interested LiDAR projected points
Objects classified and measured with LIDAR-Cam Fusion by doing 3 steps
When a raw image from a cam is merged with raw data from RADAR or LIDAR then it's called Low-Level Fusion or Early Fusion. In Late Fusion, detection is done before the fusion. However, there are many challenges to projecting the 3D LIDAR point cloud on a 2D image. The relative orientation and translation between the two sensors must be considered in performing fusion.
Rotation: The coordinate system of LIDAR and Camera can be different. Distance on the LIDAR may be on the z-axis, while it is x-axis on the camera. We need to apply rotation on the LIDAR point cloud to make the coordinate system the same, i.e. multiply each LIDAR point with theRotation matrix.
To make LIDAR and Camera Coordinate Systems the same, we need to rotate
Translation: In an autonomous car, the LIDAR can be at the center top and the camera on the sides. The position of LIDAR and camera in each installation can be different. Based on the relative sensor position, we need to translate LIDAR Points by multiplying with a Translation matrix.
Stereo Rectification: For stereo camera setup, we need todo Stereo Rectificationto make the left and right images co-planar. Thus, we need to multiply with matrix R0 to align everything along the horizontal Epipolar line.
Intrinsic calibration: Calibration is the step where you tell your camera how to convert a point in the 3D world into a pixel. To account for this, we need to multiply with an intrinsic calibration matrix containing factory calibrated values.
P Matrix: Intrinsic calibration matrix. f = Focal Length. c = Optical Center
To sum it up, we need to multiply LIDAR points with all the 4 matrices to project on the camera image.
To project a point X in 3D onto a point Y in 2D,
LIDAR-Camera Projection Formula
P = Camera Intrinsic Calibration matrix
R0 = Stereo Rectification matrix
R|t = Rotation & Translation to go from LIDAR to Camera
X = Point in 3D space
Y = Point in 2D Image
Note that we have combined both the rigid body transformations, rotation, and translation, in one matrix, R|t. Putting it together, the 3 matrices, P, R0, and R|t account for extrinsic and intrinsic calibration to project LIDAR points onto the camera image. However, the matrix values highly depend on our custom sensor installation.
This is just one piece of the puzzle. Our aim is to augment any cheap car with an end-to-end collision avoidance systemand smart surround view. This would include our choice of sensors, sensor positions, data capture, custom visual fusion, and object detection, coupled with a data analysis node, to do synchronization across sensors in order to trigger driver-assist warnings to avoid danger.
 Anand Uthaman
Anand Uthaman