zpekic
zpekic-
Running serial CPU at 25MHz!
09/06/2022 at 04:40 • 0 commentsAs noted in other logs, it was difficult to run the CPU at >2MHz or so, most likely due to R/L/C impedances and skewed signals from 6+ in wires from the PMODs to breadboard holding the 2 physical MT8816 ICs.
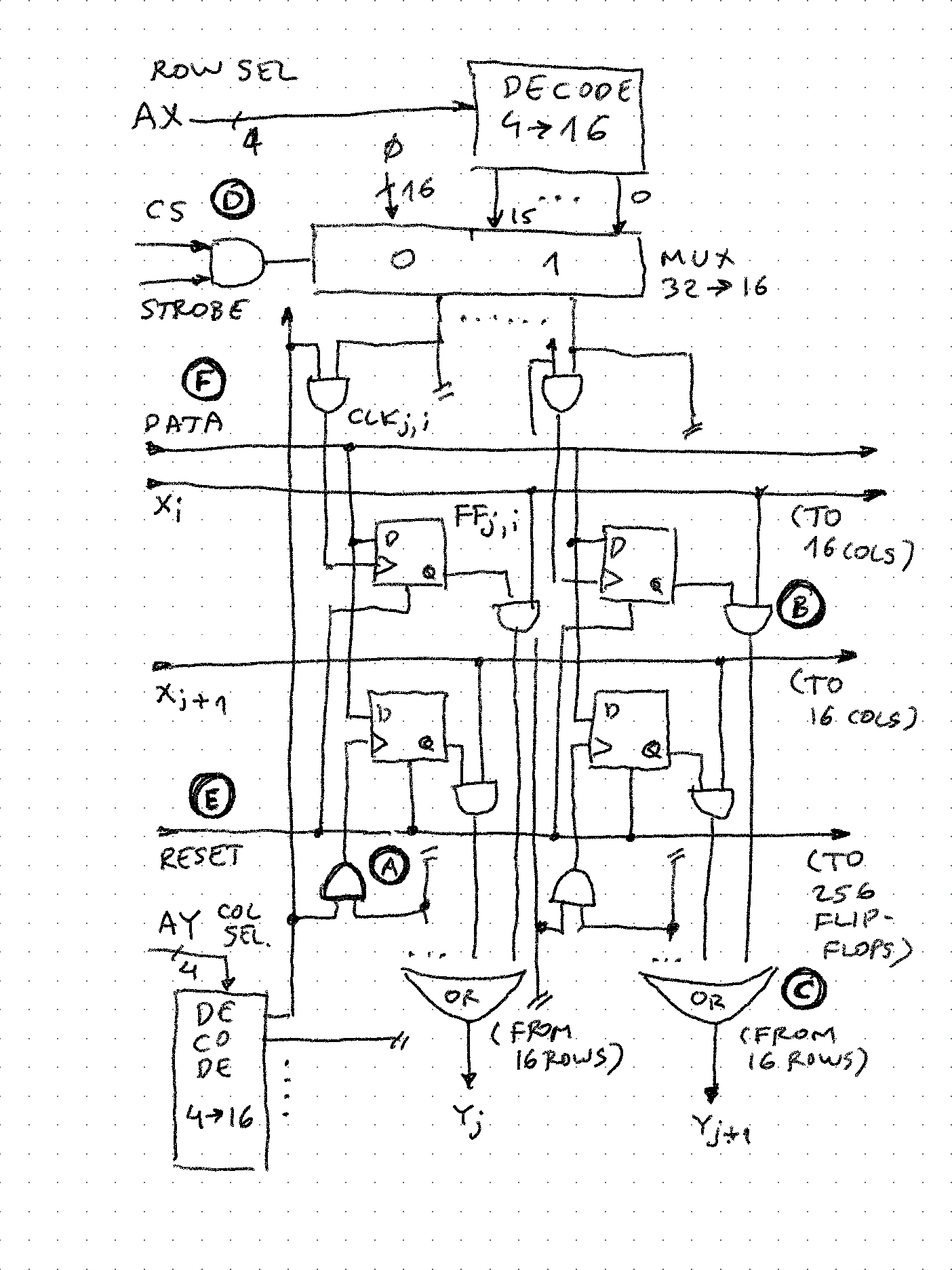
But what if the switch matrix was inside the FPGA, not outside, how fast could it run? To try that out, I developed a "virtual replacement" for the 16*16 switch matrix, and called it (very original!) MT16x16.
Replacing a true analog switch array with FPGA would be only possible using very fancy and expensive FPGA chips which have analog paths. Luckily, MT8816 in this design is used as a "wired or" not really analog, so it is possible to create 256 D-type flip-flops, each controlling an AND gate connected to a row input (X), and 16 of these OR'd together make up a column output (Y):
![]()
Noted on the schema above:
- (A) - the clock for each flip-flop is generated by 2 input AND that registers the coincidence of row and column selection. This way only at most 1 FF can take the DATA input (same as real MT8816)
- (B) - FF output (traditionally marked Q like in classic 7474) is used as an "enable" signal to AND with the input row X
- (C) - 16 outputs of AND gates (B) are then OR'd together to form output column Y. The "wired OR" becomes clear - if at least 1 FF in the column is "set" and its X input line is high, the output of column will be high.
- (D) - while column decode (AY) is always active, row decode is only active when CS (chip select) and STROBE signals are both high. Outside component drives these signals from microcode, but enables them only during 4-phase clock phase 1 (to insure right signal levels are propagated before clocking the FFs)
- (E) - reset signal is routed to 265 FFs - this is very bad design in FPGAs are routing resources are limited, but it worked. Outside component also drives reset signal from microcode and phased clock to prevent misfiring (microcode only used 2 bits to encode set, clear, reset all and nop - in hindsight this was a bad design decision because probably with 1 hot encoding (and just 2 bits more wide microcode word) the 4-phase clock would not be necessary.
- (F) - data input is also routed to all 256 FFs
In VHDL code, this 16*16 matrix is generated and interconnected using 2 generate loops. The column Y OR is pulled out of inner loop to make sure all ANDs are parallel and not stacked serially.
With external wires eliminated, CPU can be driven up to 25MHz clock frequency (microcode execution at 6.25MHz due to 4 phase clock). This means that an integer square root of 32-bit number takes typically 16305 to 94195 cycles which means 2.6 to 15ms.
CPU frequency is selected using switches 2..0 on the FPGA board. This gives 8 choices, the upper 4 of which select operation using internal matrix, and lower 4 with external (slower, but more fun!) MT8816 chips:
-- select the clock with sw_clksel select mt_cnt <= ss_cnt when "000", -- single step freq_2048(9 downto 8) when "001", -- 4Hz -- EXTERNAL MT8816 freq_2048(5 downto 4) when "010", -- 64Hz -- EXTERNAL MT8816 freq_50M(5 downto 4) when "011", -- 1.5625MHz -- EXTERNAL MT8816 freq_50M(4 downto 3) when "100", -- 3.125MHz -- INTERNAL MT16x16 freq_50M(3 downto 2) when "101", -- 6.25MHz -- INTERNAL MT16x16 freq_50M(2 downto 1) when "110", -- 12.5MHz -- INTERNAL MT16x16 freq_50M(1 downto 0) when others; -- 25MHz -- INTERNAL MT16x16Given that state of the matrix is reset and changed during the instruction execution (in other words, switch matrix state does not contain data to preserve from one operation to the next), it is possible to switch use of internal/external and back between instructions. Theoretically, it could be possible even to change the use while calculating an operation (because switch on/off commands are sent to both matrices regardless of which one is in use), but I haven't tried it and might fail due to glitches during such switch.
-
Operations: Q (integer square root)
05/08/2022 at 02:36 • 0 commentsWith integer division, comparison, subtraction already implemented, it was possible to squeeze in integer square root as the algorithm can reuse these operations. Note:
- all values in TOS are treated as positive (unsigned) integers, so it will never generate an error (root of negative numbers)
- taking the root of full 32-bit numbers is possible
- CPU has only 2 counters - bitcnt and loopcnt - the third "level of loop" does not use a counter in the CPU, but simply comparison with value executed in previous iteration
The algorithm uses Heron's method described here. For implementation reference, see to microcode lines 293 to 322 approx.
- First, argument in TOS ("S") is duplicated on the stack, dup() subroutine is used for this
- TOS is then shifted down (halved)
- If zero flag of TOS is set, we are trying isqrt(0) so bail with result 0 (but after 1 stack pop to not leave already duplicated argument in NOS)
- Note that 1 shifted down is also 0, which would give false result isqrt(1) = 0 - this is caught in div() subroutine by examining the delay status bit
- Now the stack is prepared to contain: X0, S, *, *, *, *, X0 - where X0 = S/2
- heron_step() is invoked to calculate the first iterative guess ("X1") which appears in TOS upon return
- root_loop: new "X1" and old "X0" iteration results are compared. This boils down to comparison between TOS and R7, which is a simple subtract with result not stored anywhere, just carry bit examined
- if carry flag is set (X1 >= X0), iterations are over and result in R7 is copied to TOS, bail.
- root_cont: "new" X1 value becomes "old" X0 (which means R7 <= TOS)
- new X1 guess is obtained using heron_step() and proceed to step 7.
heron_step() subroutine implements the following calculation:
x1 = ( x0 + s / x0 ) / 2;
which is:
TOS <= (NOS + DIV(NOS, R7)) >> 1
// used as step in integer square root heron_step: nuke, matrix_nop1(); connect row_r7 to col_tos, div2(max, set); // X0, S, S, ?, ?, ?, ?, X0 divmod(same); // mod, div, S, ?, ?, ?, ?, X0 nuke, matrix_nop1(); disconnect row_nos from col_nos; connect row_r2 to col_nos; // NOS <= R2 (S) connect row_nos to col_adc1; connect row_r7 to col_adc2; // TOS <= R7 + NOS connect row_sum to col_tos, c_flag <= zero, div2(max, set); // NOTE terrible fall-through!! // shift TOS >> 1 shift_down: prep_shift(); shift_dloop: STATUS = busy_using_mt, opr = m2_m2_np, z_flags <= update, d_flag <= column, if bitcnt_is_zero then return; bitcnt <= dec, goto shift_dloop; -
Operations: +, - (also BCD addition)
05/01/2022 at 03:44 • 0 comments(Refer to microcode for description)
Adding and substracting is done in a typical 2's complement fashion:
- Add: clear carry before operation, add from LSB to MSB with carry propagating
- Subtract: set carry before operation (which is +1), negate one operand, execute same like add
+ (TOS <= TOS + NOS, pop stack)
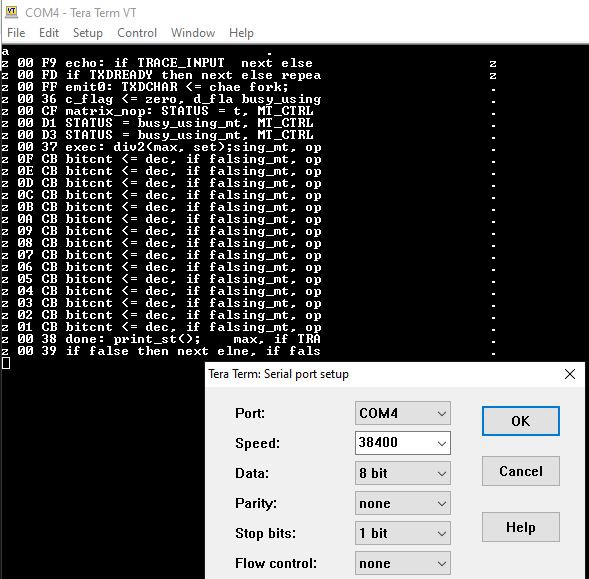
Microcode trace, 16-bit, tracing of instruction enabled ("ti") of result disabled ("tr"). Fields are:
- input register contents (+ ASCII in this case)
- contents of loopcnt and bitcnt (loopcnt is not used, this is a O(n) operation)
- microcode counter value
- truncated microcode source line (to save on "debug" memory, but still easily recognizable)
- CPU output register (instruction at 0x05 calls subroutine to send input register, and then returns to 0x06, branches to + entry point which is at 0xDC)
+ 00 05 echo(input); then emit e + + 00 FC emit: if TXDSEND then else repea + + 00 FE if TXDREADY then nextr_zero, if + + 00 06 if true then fork els STATUS = b . + 00 DC matrix_pop: STATUS = t, MT_CTRL . + 00 DE STATUS = busy_using_mt, MT_CTRL . + 00 E0 STATUS = busy_using_mt, MT_CTRL . + 00 3B add: STATUS = busy_usng_mt, MT_C . + 00 3D STATUS = busy_using_m . + 0F CA div2: STATUS = busy_use then nex . + 0E CA div2: STATUS = busy_use then nex . + 0D CA div2: STATUS = busy_use then nex . + 0C CA div2: STATUS = busy_use then nex . + 0B CA div2: STATUS = busy_use then nex . + 0A CA div2: STATUS = busy_use then nex . + 09 CA div2: STATUS = busy_use then nex . + 08 CA div2: STATUS = busy_use then nex . + 07 CA div2: STATUS = busy_use then nex . + 06 CA div2: STATUS = busy_use then nex . + 05 CA div2: STATUS = busy_use then nex . + 04 CA div2: STATUS = busy_use then nex . + 03 CA div2: STATUS = busy_use then nex . + 02 CA div2: STATUS = busy_use then nex . + 01 CA div2: STATUS = busy_use then nex . + 00 CA div2: STATUS = busy_u . + 00 F3 print_st: loopcnt <= se nextchar . . 00 11 nextchar: STATUS = doThe matrix is simple, TOS and NOS are inputs to adder, and sum (adder output row) is fed into TOS. All other registers are "popped" (Rx <= Rx-1, R7 <= 0)
The resulting carry is correct, and implementing overflow status bit would be simple too (V = Cn xor Cn-1), but it is not done in this design.
![]()
- (TOS <= TOS - NOS, pop stack)
TOS is connected to one input of adder, but NOS goes through inverter. Implementing NOS - TOS would just to re-wire TOS to go through the inverter.
![]()
Tracing 16-bit subtraction with "tr" (trace result) enabled - this prints out 4 hex characters for the value of TOS. Loopcnt register is used for this, while bitcnt remains 0.
- 00 05 echo(input); then emit e - - 00 FF emit0: TXDCHAR <= chae fork; . - 00 3E minus: c_flag <= one,busy_using_ . - 00 DD STATUS = busy_using_mt, MT_CTRL . - 00 DF STATUS = busy_using_mt, MT_CTRL . - 00 E1 STATUS = busy_using_mt, MT_CTRL . - 00 40 STATUS = busy_using_mng_mt, MT_C . - 00 3D STATUS = busy_using_m . - 0F CA div2: STATUS = busy_use then nex . - 0E CA div2: STATUS = busy_use then nex . - 0D CA div2: STATUS = busy_use then nex . - 0C CA div2: STATUS = busy_use then nex . - 0B CA div2: STATUS = busy_use then nex . - 0A CA div2: STATUS = busy_use then nex . - 09 CA div2: STATUS = busy_use then nex . - 08 CA div2: STATUS = busy_use then nex . - 07 CA div2: STATUS = busy_use then nex . - 06 CA div2: STATUS = busy_use then nex . - 05 CA div2: STATUS = busy_use then nex . - 04 CA div2: STATUS = busy_use then nex . - 03 CA div2: STATUS = busy_use then nex . - 02 CA div2: STATUS = busy_use then nex . - 01 CA div2: STATUS = busy_use then nex . - 00 CA div2: STATUS = busy_u . - 00 F3 print_st: loopcnt <= _crlf(); . - 00 FA print_crlf: emit(char next else . - 00 FD if TXDREADY then next else repea . - 00 FF emit0: TXDCHAR <= cha . - 00 FC emit: if TXDSEND then else repea . - 00 FE if TXDREADY then nextr_zero, if . - 00 F5 st_loop: selreg = int next else F - 00 FD if TXDREADY then next else repea F - 00 FF emit0: TXDCHAR <= chainc; . - 00 F7 if loopcnt_nibble theinc; . - 00 F7 if loopcnt_nibble theinc; . - 00 F7 if loopcnt_nibble theinc; . - 00 F7 if loopcnt_nibble theen print_cr . - 00 F5 st_loop: selreg = int next else B - 00 FD if TXDREADY then next else repea B - 00 FF emit0: TXDCHAR <= chainc; . - 00 F7 if loopcnt_nibble theinc; . - 00 F7 if loopcnt_nibble theinc; . - 00 F7 if loopcnt_nibble theinc; . - 00 F7 if loopcnt_nibble theen print_cr . - 00 F5 st_loop: selreg = int next else B - 00 FD if TXDREADY then next else repea B - 00 FF emit0: TXDCHAR <= chainc; . - 00 F7 if loopcnt_nibble theinc; . - 00 F7 if loopcnt_nibble theinc; . - 00 F7 if loopcnt_nibble theinc; . - 00 F7 if loopcnt_nibble theen print_cr . - 00 F5 st_loop: selreg = int next else A - 00 FD if TXDREADY then next else repea A - 00 FF emit0: TXDCHAR <= chainc; . - 00 F7 if loopcnt_nibble theinc; . - 00 F7 if loopcnt_nibble theinc; . - 00 F7 if loopcnt_nibble theinc; . - 00 F7 if loopcnt_nibble theen print_cr . - 00 FA print_crlf: emit(char next else . - 00 FD if TXDREADY then next else repea . - 00 FF emit0: TXDCHAR <= cha . - 00 FC emit: if TXDSEND then else repea . - 00 FE if TXDREADY then nextr_zero, if . - 00 39 if false then next elne, if fals .(there is a but, loopcnt is actually not displayed correctly in the trace above, will be fixed)
BCD addition
TO BE CONTINUED...
-
Operations: *, /
05/01/2022 at 02:09 • 0 commentsThese two operations are similar in following ways:
- produce results of size 2*n (in case of division, n bits for div, n bits for mod)
- bottom of stack is destroyed due to need for a temporary register
- unsigned - operands are assumed to be positive integers in range 0 ... 2^(n-1)
* (TOS:NOS <= TOS * NOS)
A classic shift-add algorithm is used, as described here for example.
Microcode lines 360-390 implement the steps:
- prep_regs() subroutine moves TOS to R7 and clears TOS. TOS which is now 0, and NOS can be imagined as one long 2*n (e.g. 32 or 64 bit) register where the shift and add occurs. The "parameter" max passed in looks by syntax as a subroutine input parameter, but it is simply a shorthand for register assignment operation in the same microcode cycle which calls the subroutine. This way when first instruction of subroutine executes, the loopcnt register is set to n-1 (max value). Definition of subroutine can be seen around line 204.
- Single rotation (n operations in subroutine above) also updated the zero bit for register NOS, so if this is set we can bail out as we have x * 0 = 0
- NOS is shifted down to get LSB, which lands in delay status flag. To preserve state of registers a shift up is executed right after (np_d2_d2 is followed by np_m2_m2)
- If LSB was 1, execute add step (m_add_r7)
- The addition can result in carry, so set delay status bit (which will be shifted into MSB of TOS), and proceed with shift of the 32/64 aggregate TOS/NOS register (m_shift1)
- If addition produced no carry, set delay bit to 0 so that will be shifted into MSB of TOS (m_shift0)
- m_shift: note how TOS and NOS are connected together along with delay status bit. A single rotate down step is executed. Because all other registers (R2...R7) get this step too, after n cycles they will be rotated back to original value, only NOS and TOS accumulating the result
- switch matrix connections are reset for next iteration, loopcnt is examined, if zero then iterations are done
- loop counter is decremented and proceed with step 3.
/ (TOS <= NOS div TOS, NOS <= NOS mod TOS)
The unsigned (restoring) binary division algorithm and conceptual design of the hardware for it are described here. The only difference is that all operations in the flow chart are executed serially so need n cycles. The beauty of this setup is that it simultaneously generates div and mod values. For clarity, even register names A, Q, M are used in the microcode (note that using .alias directive makes it easy to give alternative name to any symbol)
Microcode lines 490-530 implement the steps (note the subroutine is factored out so that can be used also as part of square root algorithm):
- prep_regs() subroutine described above is invoked to clear TOS after saving it to R7.
- if NOS was detected as zero, is is divide by zero case, so bail out to error routine (there is a special case when called from square root flagged by delay = 1)
- divloop: Q (NOS) and A (TOS) are connected into a 2*n long register and shifted up (m2_m2_np)
- A <= A - M step is executed. Most of this operation is factored out into a_pm_m() subroutine, but it is called with carry set and with M going through inverter. That way standard A <= A + !M + 1 is achived.
- If step 4 resulted in carry set then it means A >= M, so "M goes into A", and 1 can be shifted into Q
- To not keep other registers same, first all are rotated down (d2_d2_np), then delay bit is connected to Q and all rotated up (lines 515-522).
- div_next: if loopcnt reached zero, means algorithm is done, so return is executed, otherwise decrement loopcnt and go to step 3
- restore_a: If step 4 resulted in no carry, means "M doesn't go into A" so we need to restore the value of A. Again, a_pm_m() is used for this, but with carry zero, so A <= A + M + 0
- proceed with step 7
-
Operations: Z, S, U, R, N, <enter>
04/27/2022 at 05:44 • 0 commentsFollowing stack operations have much in common:
- Turn all switches off (remember, MT8816 has a RESET signal so this can be done for all 256 at once, in one microcycle)
- Set up the 16*16 matrix according to the operation below
- Drive all registers around for a full round-trip (16 or 32 clock cycles)
Refer to the microcode for explanations below.
N[uke]
This is the simplest operation, all working registers are set to zero, with the "nuke" alias:
nuke .alias STATUS = busy_using_mt, MT_CTRL = clear;When the STATUS microcode field is busy_using_mt, external "hardware window" on VGA has no access because the CPU is driving and picking up the switch matrix signals. MT_CTRL field is clear, which generates RESET signal for both MT8816 ICs.
MT_RESET <= 'Z' when ((mt_ctrl(8) and mt_ctrl(9)) = '1') else '0';![]()
Z[ero]
Another simple operation, the nop1() subroutine connects Rx to Rx where x = 1..7, leaving R0 (TOS) unconnected. Because of pull-down to low, it means after a round trip of bits TOS will be cleared and all other registers unaffected.
Along with Nuke, Zero is the only command that also resets the error code register to zero ("no error") after divide by zero or invalid command errors.
// TOS <= 0, ERR <= 0 ------------------------------------- .map 'z'; // "zero" .map 'Z'; // -------------------------------------------------------- reset_flags, errcode <= ok, nuke, matrix_nop1(); // no switch on TOS means pull down, so it 0 exec: div2(max, set); // 16 or 32 * done: print_st(); // output stack top goto nextchar; // go for next commandNote that due to both lower-case and upper-case Z pointing to same microcode entry point, commands are case-insensitive.
// rotate all registers right (LSB first) through switch matrix; div2: STATUS = busy_using_mt, opr = d2_d2_d2, c_flag <= adder, z_flags <= update, if bitcnt_is_zero then return; bitcnt <= dec, goto div2;div2() subroutine uses the value of bitcnt register (which is initialized to value "max" resolving to either 15 or 31) and then executes a loop n time with registers driven to d2_d2_d2 control signals - so they all shift down and MSB bit is picked up from switch matrix.
![]()
S[wap]
Similar to nop, but TOS and NOS switches are swapped. Any number of registers could be swapped, copied, cleared etc. in one n-bit roundtrip.
![]()
[d]U[plicate]
TOS and NOS are clear, both will pick up value from TOS. Other registers are hooked up to "next one": R2 to R3, R4 to R5 etc. which means they will be "pushed" down, and R7 will be lost.
If "nop" is the diagonal, "push" is diagonal moved to right, and "pop" to left 1 register position. No stack pointer is needed.
![]()
R[otate]
It is like push, but R7 is connected to R0. This could be also viewed as one long 8*n length shift register, with n shifts all values are "moved" around.
![]()
<enter>
A simple push - because TOS is not connected to anything, it will get the "pull down" value of 0.
![]()
Sample execution of these commands - note "tr" (trace result) option that emits operation ASCII code before, and TOS value after the operation
-
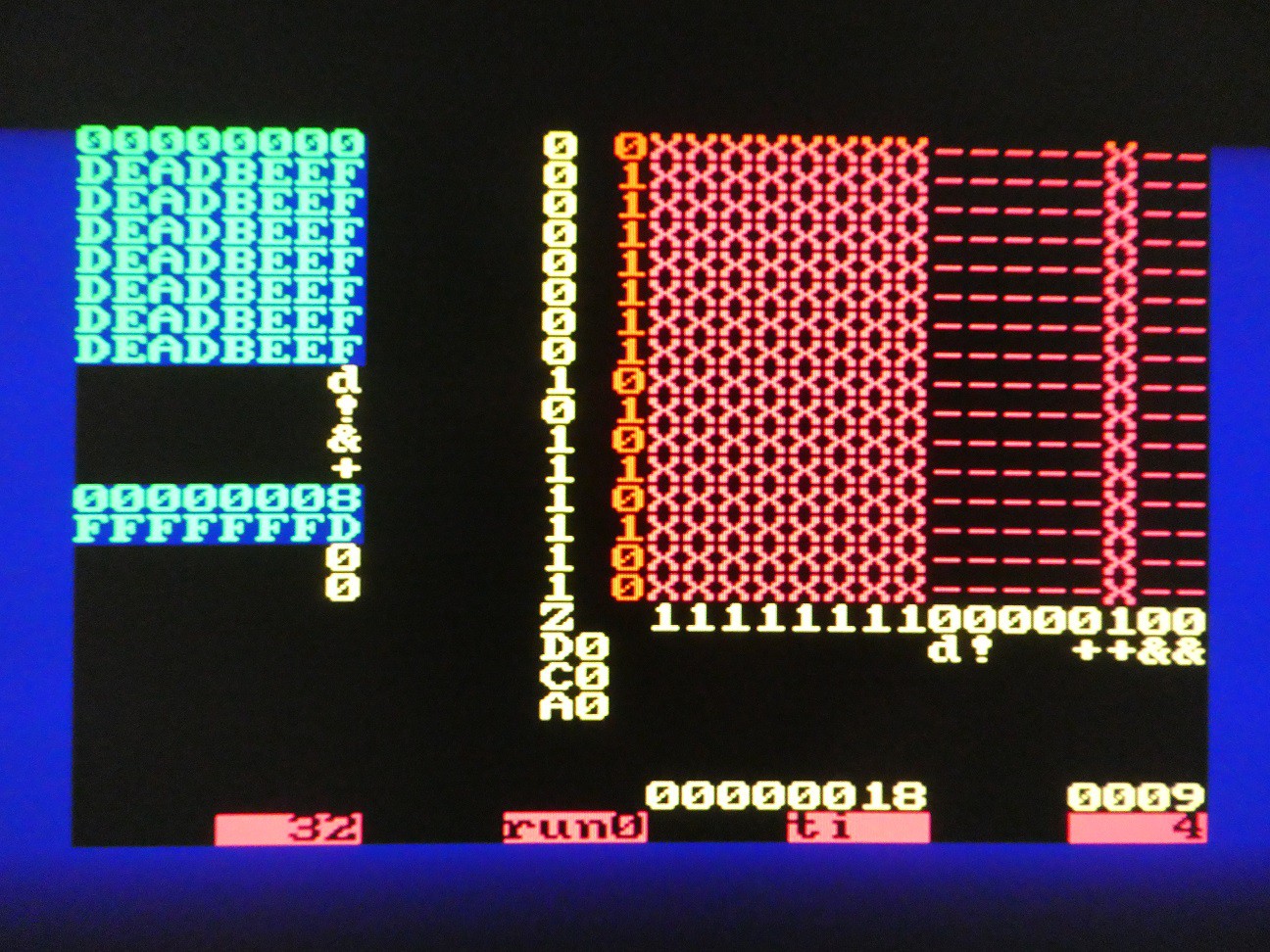
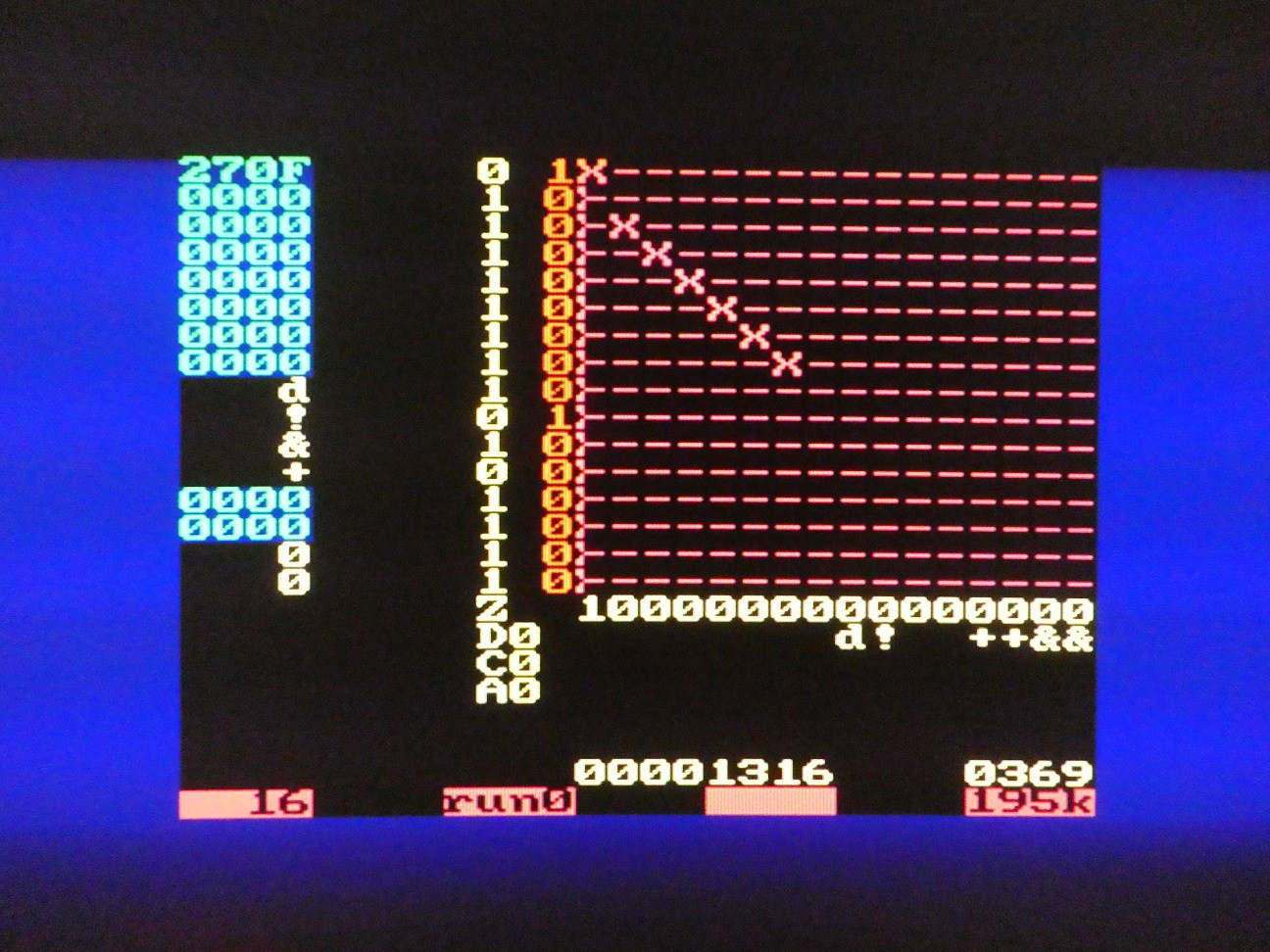
Operations: # (binary to BCD), $ (BCD to binary)
04/27/2022 at 05:13 • 0 commentsAlgorithm used:
- Binary to BCD conversion (note that result may be truncated, for example converting FFFF will result in 5535 in 16-bit mode)
- BCD to binary conversion (note that is invalid BCD digits are in TOS, no error will be thrown but result will be meaningless)
Both of these use adjacent shift registers and 1 - bit shift and (optional) correction steps which make them convenient for serial CPU.
# - TOS (BCD) <= TOS (binary)
(refer to microcode lines 419-448 , more details to come...)
$ - TOS (binary) <= TOS (BCD)
(refer to microcode lines 394-414 , more details to come...)
Example: converting 9999 to 270F and vice versa
-
Operations: 0..9, A..F (entering digits)
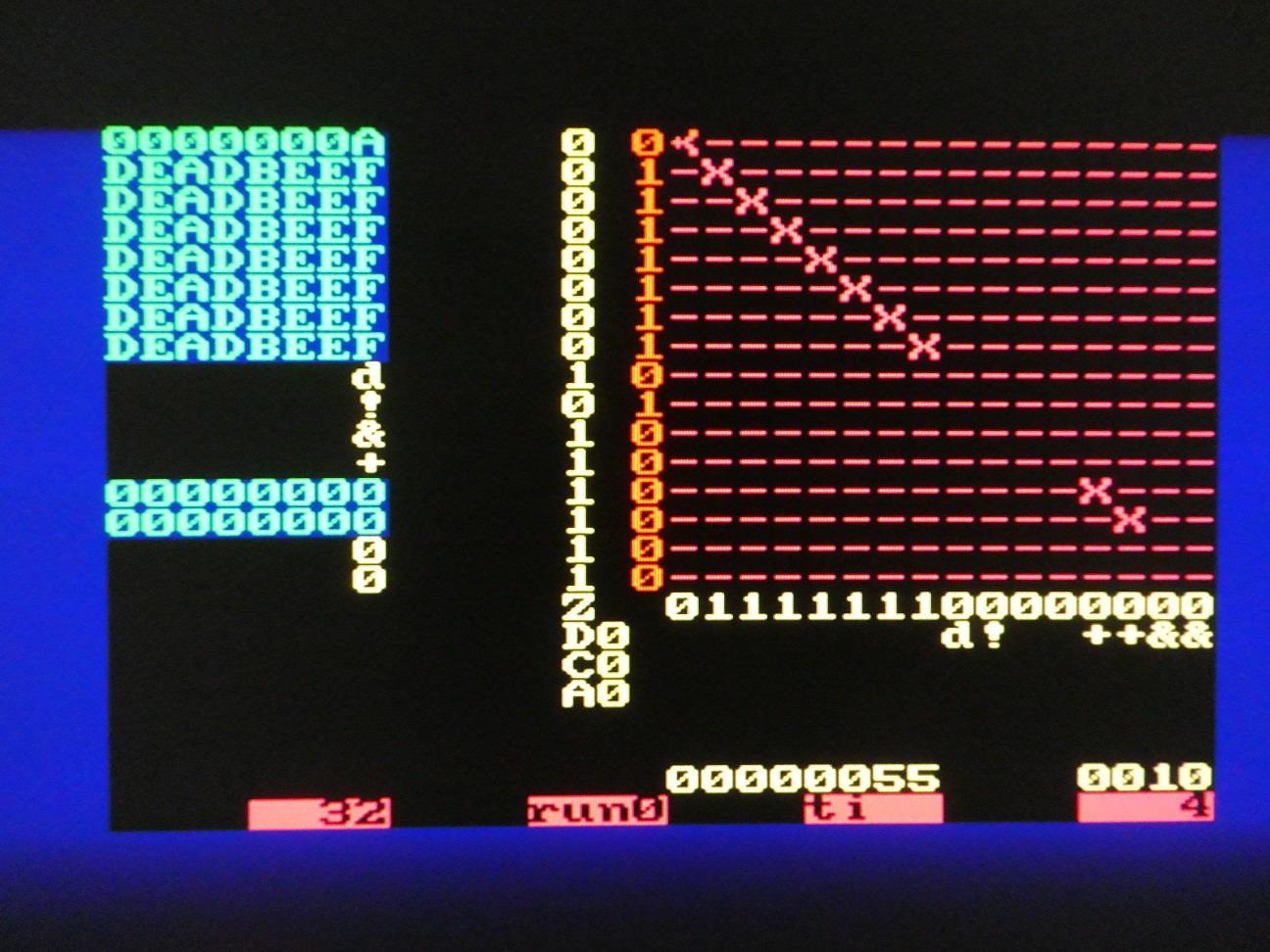
04/27/2022 at 04:34 • 0 commentsLike in most calculators, digits are entered the TOS (top of stack) register from right, pushing all other digits up for 4 bits, with MSN (most significant nibble) lost.
There are many ways to accomplish this, but the approach here is a bit complicated because the optimization was done to minimize microcode needed:
- When entering digits, the input register ("instruction register") contains the ASCII code of the digit
- First, R12 and R13 are loaded (these are parallel loadable) - R12 with bit reverse of lower 4 bits of ASCII code (e.g. A = 0x41 = 01000001 so with 1000) and R13 with a correction value which is 1101 (.data value alias)
- R12 and R13 are connected to inputs of the adder, and TOS as output, carry is cleared, nop1() matrix is set up for rest of registers
- 4 shifts down are made for all registers except TOS which is shifted up - this way the 4 bits of correct value appear in LSN of TOS (opr = m2_d2_d2)
- bitcnt is now loaded with n - 4
- all registers (except TOS which is not shifted) are shifted down until bitcnt is 0. This means that they are shifted n times, so they remain with same value (opr = np_d2_d2)
... .map 'a'; .map 'A'; .map 'e'; .map 'E'; data 0b1101, goto hexchar; // correction from reverse ASCII is 11 ... hexchar: load_bitcnt 3, c_flag <= zero, nuke, matrix_nop1(); connect row_const to col_adc1; connect row_direct to col_adc2; connect row_sum to col_tos; STATUS = busy_using_mt, opr = m2_d2_d2, bitcnt <= dec, if bitcnt_is_zero then next else repeat; disconnect row_sum from col_tos, bitcnt <= max; connect row_tos to col_tos, bitcnt <= dec; bitcnt <= dec; bitcnt <= dec; bitcnt <= dec; STATUS = busy_using_mt, opr = np_d2_d2, bitcnt <= dec, if bitcnt_is_zero then nextchar else repeat;State before shifts:
![]()
State after the shifts (digit A was entered, switch is position 0, 0 could be stayed off):
![]()
-
Everybody loves benchmarks! The numbers are in!
04/25/2022 at 03:43 • 0 commentsWhen calculations are done 1 bit at a time, one should probably not expect blazing speed.
To measure the clock cycles per operations, I simply baked a 8-digit BCD counter into the system and increment it at each cycle, and reset to 0 at each new instruction. This is in top-level file of the design:
-- count clock cycles per instruction cclkcnt: bcdcounter Port map ( reset => (RESET or i_new), clk => hc_clk, enable => (hc_status(1) and hc_txdready), -- only count when status is "busy" and not waiting for UART value => c_cnt ); i_new <= hc_status(1) when (hc_status_old = status_ready) else '0'; on_hc_clk: process(hc_clk) begin if (rising_edge(hc_clk)) then hc_status_old <= hc_status; end if; end process;i_new is the pulse (on hc_clk clock cycle wide) that gets generated when a new instruction execution starts. This is detected because CPU status goes from STATUS_READY to any of the STATUS_BUSY (bit(1) of status field is 1). The status is generated at each and every microinstruction (and unless stated otherwise, will be "busy"):
// Component interface signals STATUS .valfield 2 values ready, // waiting for input character done, // input processed, will go ready on next clock cycle busy, // processing busy_using_mt default busy; // processing and needing the MT_8816hx_txdready is the signal that comes back from UART sender. Because at 38400Hz (typically) this is slower than CPU speed, this wait time is excluded from the count (during this time counting is disabled).
Finally, the value of the counter is fed into the "hardware window" to display to VGA:
![]()
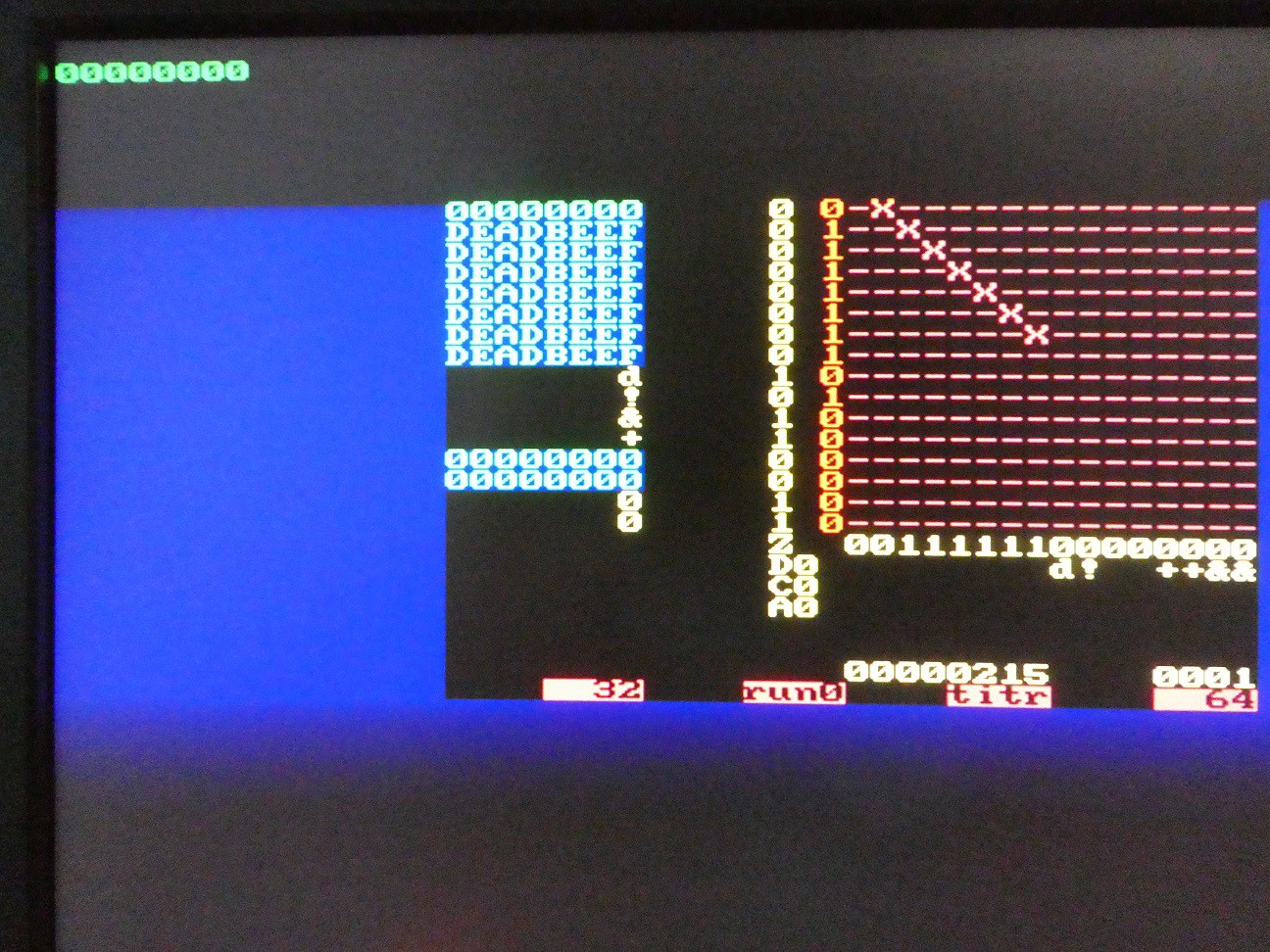
(measurement converting 9999 to binary in 16-bit mode, with tracing input and tracing output disabled, clock 195kHz)
Operation 16-bit 32-bit Notes 0..F (enter digit into TOS) 36 52 ENTER (push registers down, clear TOS) 47 79 Z (clear TOS) 46 78 N (clear all regs) 39 71 R (rotate registers) 47 79 U (duplicate TOS) 48 80 S (swap TOS and NOS) 48 80 < (shift TOS up) 50 82 > (shift TOS down) 50 82 + (add TOS + NOS) 48 80 - (sub TOS - NOS) 49 81 * (multiply TOS * NOS) 51 786 83
2578Best: TOS = 0
Typical: all other/ (TOS / NOS) 95
1384127
4830Best: TOS = 0 (divide by 0 detected)
Typical: all other# (convert to BCD) 1529 5493 for arg 9999/99999999 $ (convert to binary) 1316 4656 for result from above Q (integer square root of TOS) 16305 94195 Worst: max argument General observations:
- As expected, when n bits need to be traversed once, the time is n + overhead, therefore O(n)
- For other operations, time is O(n^2)
- Algorithms have much overhead because in the middle of calculations switches must be turned on and off
- Some operations take same time regardless of the number of registers! For example R, N - while for parallel CPUs these would be O(r)
How to improve performance:
- In order to save microcode space, the pattern used is to turn off all switches ("nuke" alias in microcode) then set the matrix (e.g. nop() for diagonals etc.) and then turn on/off the differences. Instead, the exact switch states from step before could be analyzed and only differences applied
- Division could be optimized by simultaneously generating both outcomes of the divide step and pick one instead of substract/restore used here. Again, the optimization was for less code so more operations can fit into 256 words of microcode. Division is used in Heron's iterative method to calculate isqrt() so that would benefit a lot too.
- Speed up setting up the switches: for example two switch matrixes could be used, one to use for calculations, while during that time in the background another is set up for next step. This way most of the switch overhead could be eliminated, and just driving bits serially would remain.
-
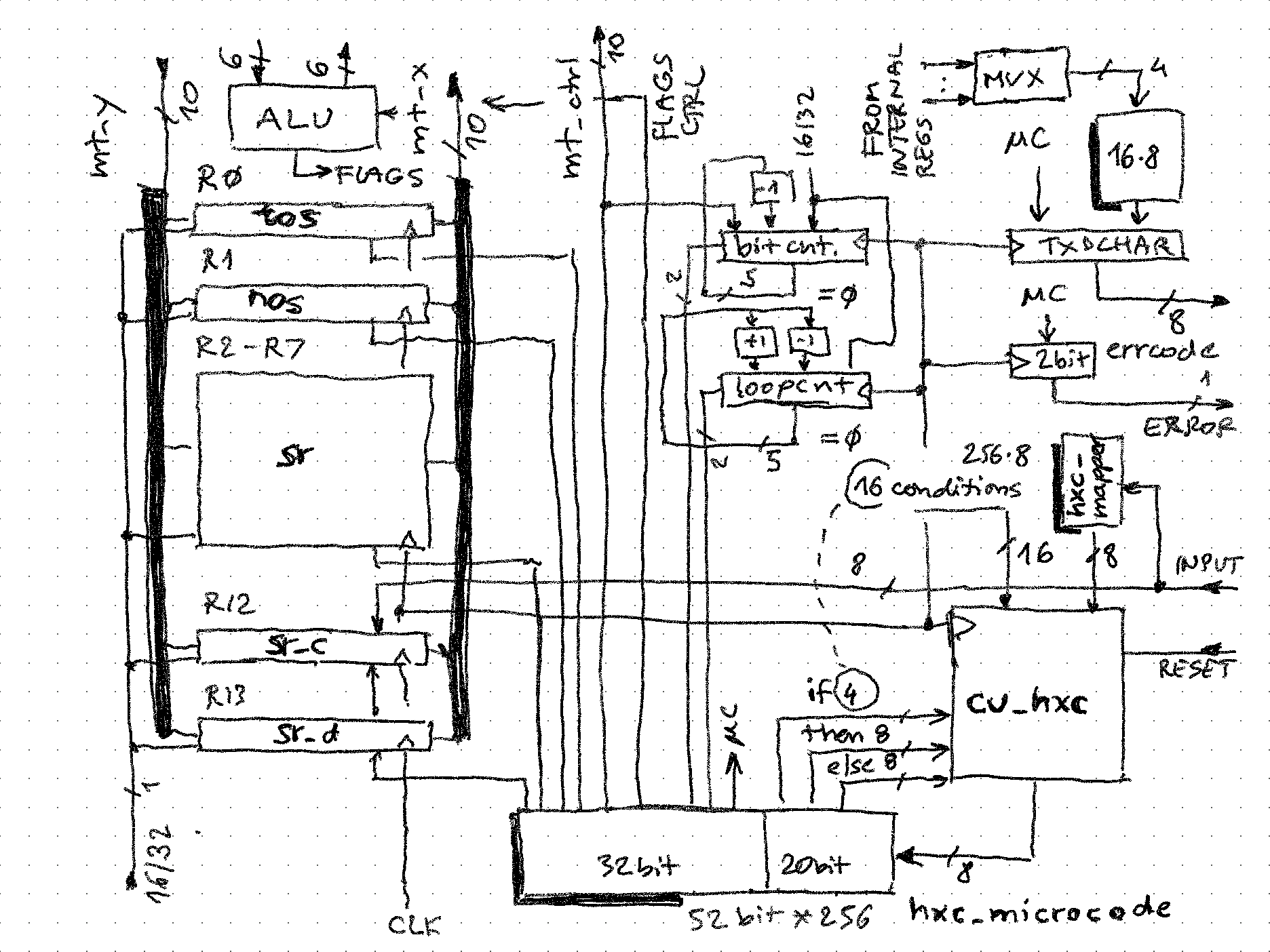
CPU internals
04/25/2022 at 00:48 • 0 commentsCore of the calculator is a micro-coded CPU. For micro-code refresher, see:
- https://hackaday.io/project/172073-microcoding-for-fpgas/log/179214-microcode-compiler-in-fpga-toolchain
- https://hackaday.io/project/172073-microcoding-for-fpgas/log/178442-standardized-control-unit-and-microcode-layout
Lots of its code has been autogenerated by running the mcc compiler on the microcode. This simplified schema shows the main elements:
![]()
A successful microcode compiler run will generate 4 VHDL files useful to be included in the project:
.code 8, 52, hexcalc_code.mif, hexcalc_code.cgf, hexcalc_code.coe, hxc:hexcalc_code.vhd, hexcalc_code.hex, hexcalc_code.bin, 8; .mapper 8, 8, hexcalc_map.mif, hexcalc_map.cgf, hexcalc_map.coe, hxc:hexcalc_map.vhd, hexcalc_map.hex, hexcalc_map.bin, 1; .controller hexcalc_control_unit.vhd, 8; .symbol 8, 256, hexcalc_sym.mif, hexcalc_sym.cgf, hexcalc_sym.coe, hxc:hexcalc_sym.vhd, hexcalc_sym.hex, hexcalc_sym.bin, 32;cu_hxc (hexcalc_control_unit)
This is autogenerated microcode controller unit. It consumes 20 bits of the microcode width for its operation - 4 to select one out of 16 conditions, and 8 each for "then" and "else" branch targets. This means that at each microinstruction a conditional program flow instruction can be executed, or an unconditional subroutine call.
hxc_microcode
The resulting microcode address (8 bits) selects the 52-bit wide microinstruction. Therefore 32-bits are available to drive the control signals of the remaining components in the CPU, and some (such as STATUS field) drive directly signals going out from the CPU.
hxc_uinstruction <= hxc_microcode(to_integer(unsigned(ui_address))); -- copy to file containing the control unit. TODO is typically replace with 'ui_address' control unit outputhxc_mapper
256*8 lookup memory - the address is the value of the instruction register, and the output the 1st word of the microcode routine implementing it. This is easiest to see in the .mif file which is also generated.
Symbol file hexcalc_sym.vhd is consumed one structural level up by the tracer unit, so it in not included inside the CPU.
Data registers
CPU has 8 "program accessible" registers (R0...R7). They support:
- no operation
- shifting in from either side
- 1 output bit from either side
- holding 16 or 32 bits (CPU is agnostic of the length)
In addition there are two internal registers of the same size, which:
- support all shift operations like R0..R7
- allow parallel loading
Registers 0 and 1 (TOS and NOS) can be driven independently, while R2+ all together. To save microcode bit width, the combinations needed for the algorithms are collapsed into 8 cases:
// shift register operations in format: TOS_NOS_Other opr .valfield 3 values np_np_np, // no shifts np_np_ld, // only effects 0xC[onstant] and 0xD[ata] m2_d2_d2, // TOS shift up, NOS and other regs shift down np_m2_m2, d2_d2_d2, d2_d2_np, // used for multiplication np_d2_d2, m2_m2_np default np_np_np;bitcnt
This is a 5-bit counter primarily used to count bits in simple operations where single traversal of bits is needed. Microcode does not know the value of bitcount, just that it can be loaded with maximum value (which is 15 or 31), that it can be decremented, or examined if zero (bitcnt_is_zero condition). This means microcode is agnostic to the length of registers, if bitcnt and loopcnt would hold 255 max, and registers of that length, 256-bit numbers could be handled, and 64-digit BCDs converted to binary!
loopcnt
Similar to bitcnt, but outer loop when iterations are needed (conversions bin <-> BCD, mul, div). It is also loaded with 15 or 31 (note how mode32 input signal selector is used), but can be also incremented in addition to decrementing.
Non-standard register lengths could be implemented (e.g. 24 or 48 bits etc.) under the condition that a proper wrap-around for these registers occurs ( 0 - 1 = 47, 23 + 1 = 0 etc.)
Much of the code for these have been also auto-generated by mcc:
---- Start boilerplate code (use with utmost caution!) update_loopcnt: process(clk, hxc_loopcnt) begin if (rising_edge(clk)) then case hxc_loopcnt is -- when loopcnt_same => -- loopcnt <= loopcnt; when loopcnt_max => loopcnt <= mode32 & X"F"; -- 31 or 15 when loopcnt_inc => loopcnt <= std_logic_vector(unsigned(loopcnt) + 1); when loopcnt_dec => loopcnt <= std_logic_vector(unsigned(loopcnt) - 1); when others => null; end case; end if; end process; ---- End boilerplate codeTXDCHAR
CPU can generate an output ASCII stream, one character at a time. To save on microcode width, only few characters are supported, such as CR, LF, space, E, R, R. These are generated through a MUX which feeds these direct ASCII values. 8 of the 16 MUX sources come through a hex-to-ASCII lookup table, that way 8 hex values from inside the CPU can be selected and streamed out. Essentially, CPU is doing its own tracing under microcode control.
errcode
CPU recognizes 2 error conditions:
- invalid instruction (ASCII code not mapped onto an operation)
- divide by zero
To have the proper register semantics, two more states are needed:
- no change
- no error
This gives 4 states, so register is 2 bits long. Only Z, N and reset signal clear the error.
ALU
This is as simple as it gets, few logic gates:
-- ALU! row_delay <= d_flag; row_not <= not col_not; row_and <= col_and1 and col_and2; row_sum <= c_flag xor (col_adc1 xor col_adc2); -- 1 bit full adder sum -- 12 is constant register -- 13 is data register mt_x(14) <= '0'; mt_x(15) <= '0';Value of some switch matrix column wires are combined using not / and gates and fed back to switch matrix rows.
The adder has additional third signal which the value of previous carry, and the row_delay is hooked up to a flag value which can capture the state of single bit in some previous bit cycle time. Typical use is preserving the value of bit shifted out from a register.
FLAGS
Some classic CPU flags are present:
- c_flag - standard carry flag for 2's complement operations - based on microcode control, it can be set (e.g. before sub), cleared (e.g. before add), updated (from adder outputs), or left unchanged
- d_flag - delay flag for shift operations
- a_flag - updated along the carry flag to indicate BCD carry. Not used in this design (full BCD add has been tested and the microcode is included but commented out)
- z_flags - each register has its own (so it is a vector of 16 bit values). Updating them is a bit different than with parallel processors - first they are set to 1 ("assume 0") and then when a 1 is detected from the register output, it is cleared and stays cleared.
carry, delay and zero flags for TOS, NOS registers (and "AND row") can be inspected (their value is available to the microcode) which allows arithmetic algorithms to work.
seq_cond: .if 4 values true, // hard-code to 1 input_is_zero, // do not process 0x00 input char TRACE_INPUT, TRACE_RESULT, TXDREADY, TXDSEND, bitcnt_is_zero, loopcnt_is_zero, d_flag_is_set, c_flag_is_set, z_flagand_is_set, loopcnt_is_max, z_flagtos_is_set, z_flagnos_is_set, //daa_flag_is_set, loopcnt_nibble, false // hard-code to 0 default true; -
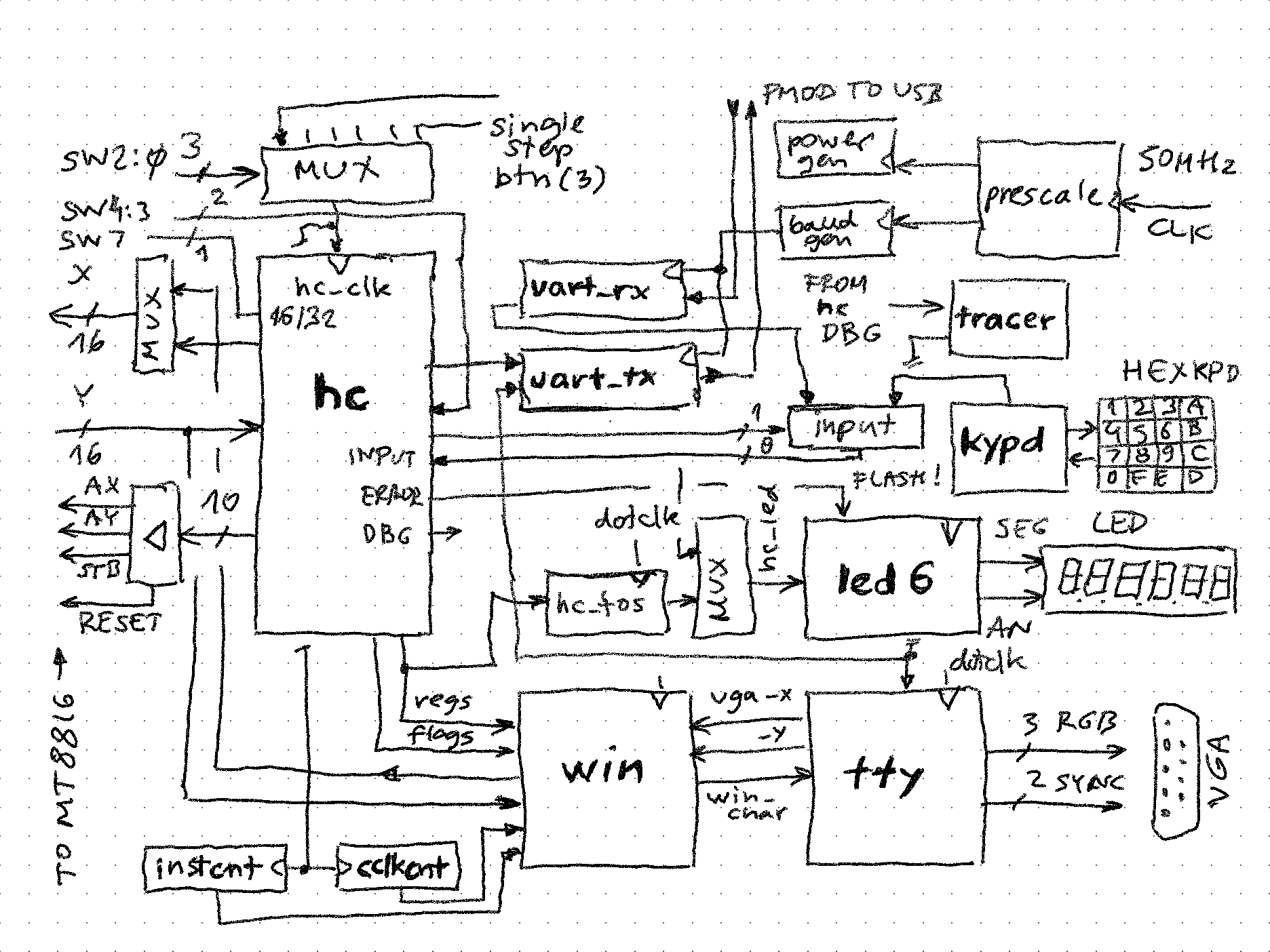
System overview
04/24/2022 at 18:27 • 0 commentsThe calculator/CPU cannot function on its own, without being embedded in a system that gives it the I/O, clock, outside hardware connections etc. on the FPGA board.
The top-level object that does this is sys_sbc8816.vhd![]()
(simplified schema, bolded names correspond to components in the source code)
Why is this so complicated? The reason is that lots of debugging components have been added to the design:
- win - this allows generating a "hardware window" that shows all the 256 switch states (which are in external MT8816 chips), as well as the state of CPU regs and flags
- tty - allows CPU to "write" top of stack, errors etc. to VGA
- tracer - allows showing (part of) microcode as being executed
- uart_rx and uart_tx - commands to CPU can come from USB serial, and microcode tracing and/or result display can go to USB too - so a terminal app can be used to interact
For the basic operation of the calculator, only 3 components are needed:
- hc - the calculator itself with its hardware connections to MT8816s
- kypd - allows entry of 0-F digits and all the commands (button(3) + digit == command)
- led6 - displays TOS (top of stack) to 6 7-segment LEDs (too bad Anvyl doesn't have 8 of these for full 32-bits, I didn't bother installing the "scrolling" of 6 digit window of 8 digit display yet)
Clock generation
All clocks derive from 100MHz clock integrated on the Anvyl board. From this, 3 separate paths are taken:
- Simple division by two (signal freq_50M) used by VGA (25MHz dot frequency for 640*480) and further down for CPU and other places
- Pre-scaling to generate 2^n frequency, which goes down to 1Hz eventually (signal freq_2048)
- Pre-scaling to generate baudrates - switches on board select a divide value from prescale_lookup table for UART send and recive (typically 38400bps)
CPU clock is selectable using switches 2..0. 0 selects single step (useful for much painful debugging), and 7 is full-speed. In addition speeds 0..3 enable tracing the microcode.
-- select the clock with sw_clksel select mt_cnt <= ss_cnt when "000", -- single step freq_2048(9 downto 8) when "001", -- 4Hz freq_2048(7 downto 6) when "010", -- 16Hz freq_2048(5 downto 4) when "011", -- 64Hz freq_50M(8 downto 7) when "100", -- 0.195312 freq_50M(7 downto 6) when "101", -- 0.390625 freq_50M(6 downto 5) when "110", -- 0.781250 freq_50M(5 downto 4) when others; -- 1.5625MHz -- 4 phase clock to activate strobe at right time phi0 <= '1' when (mt_cnt = "00") else '0'; phi1 <= '1' when (mt_cnt = "01") else '0'; phi2 <= '1' when (mt_cnt = "10") else '0'; phi3 <= '1' when (mt_cnt = "11") else '0'; -- single step cnt on_button3: process(button(3), ss_cnt) begin if (rising_edge(button(3))) then ss_cnt <= std_logic_vector(unsigned(ss_cnt) + 1); end if; end process;MT8816 control signals have some requirement of setup and hold times before/after STB, so these are achieved by using a 4-phase clock, and activating control signals at their duty cycle.
Instruction input
The CPU / calculator executes instructions which are 8-bit ASCII character code. These characters can come from:
- 16-key hex keypad. The state of button(3) is appended to 4-bit generated by this keyboard to lookup the ASCII code in a 32*8 bit ROM
- UART RX, connected to PMOD and USB - this way a host machine keyboard can be used
Both of these generate a strobe pulse, and first one received wins, loading the ASCII value into input register. This is actually the "instruction register" of the CPU. This register holds the character until CPU clears it (instruction is executed).
key <= rx_ready or kypd_keypressed; input_clear <= '1' when (hc_status = status_done) else reset; on_key: process(key, kypd_hex, kypd_shift, rx_char, input_clear) begin if (input_clear = '1') then input <= X"00"; else if (rising_edge(key)) then if (kypd_keypressed = '1') then input <= kypd2ascii(to_integer(unsigned(kypd_shift & kypd_hex))); else input <= rx_char; end if; end if; end if; end process;Inside the microcode there is simple loop waiting until input register !=0, meaning new character has been received. The input register could be replaced with a FIFO queue.
// indicate availability and wait for start signal // --------------------------------------------------------------------------- deadloop: STATUS = ready, if input_is_zero then repeat else next; echo(input); if true then fork else fork; // jump to entry point per character code (see .map statements below)Serial text output path
Two components can generate a stream of text (lines + CR + LF sequence):
- CPU can echo the input char processed if "trace input" (switch(4)) is turned on, and also print TOS if "trace result" (switch(3)) is turned on. Error number (and input) is also always streamed out in case of error
- Tracer can generate a line containing some select data and part of microinstruction address and source code
![]()
Two components can handle these stream:
- TTY - "prints" the stream to 80*60 character RAM which is then displayed on VGA. The description of this component is here, but for this design it is expanded to handle the character coming from "hardware window"
- UART TX - connected to PMOD and then USB to display it on terminal window as seen above
Which source goes to which destination can be selected with switch(6..5)
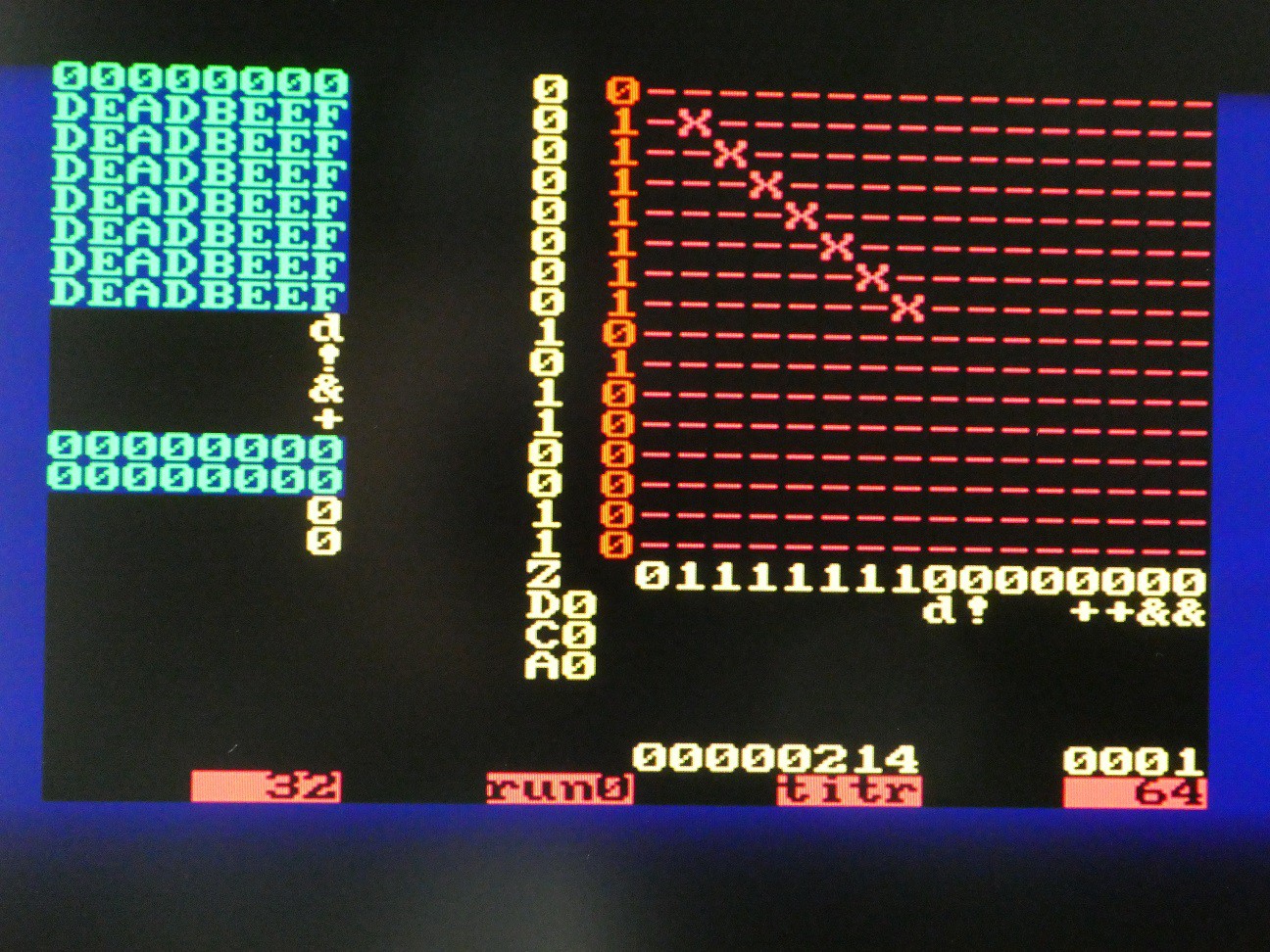
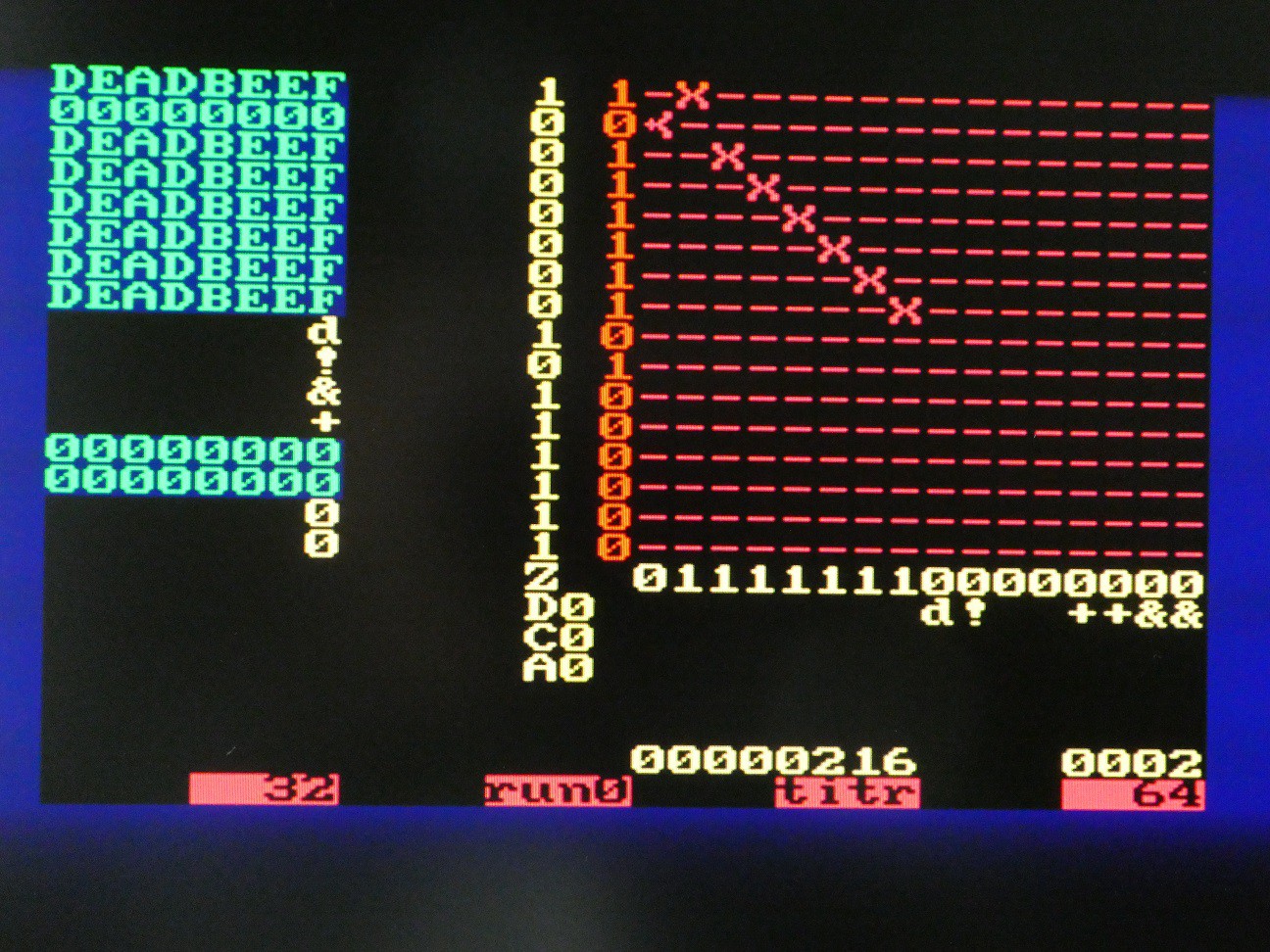
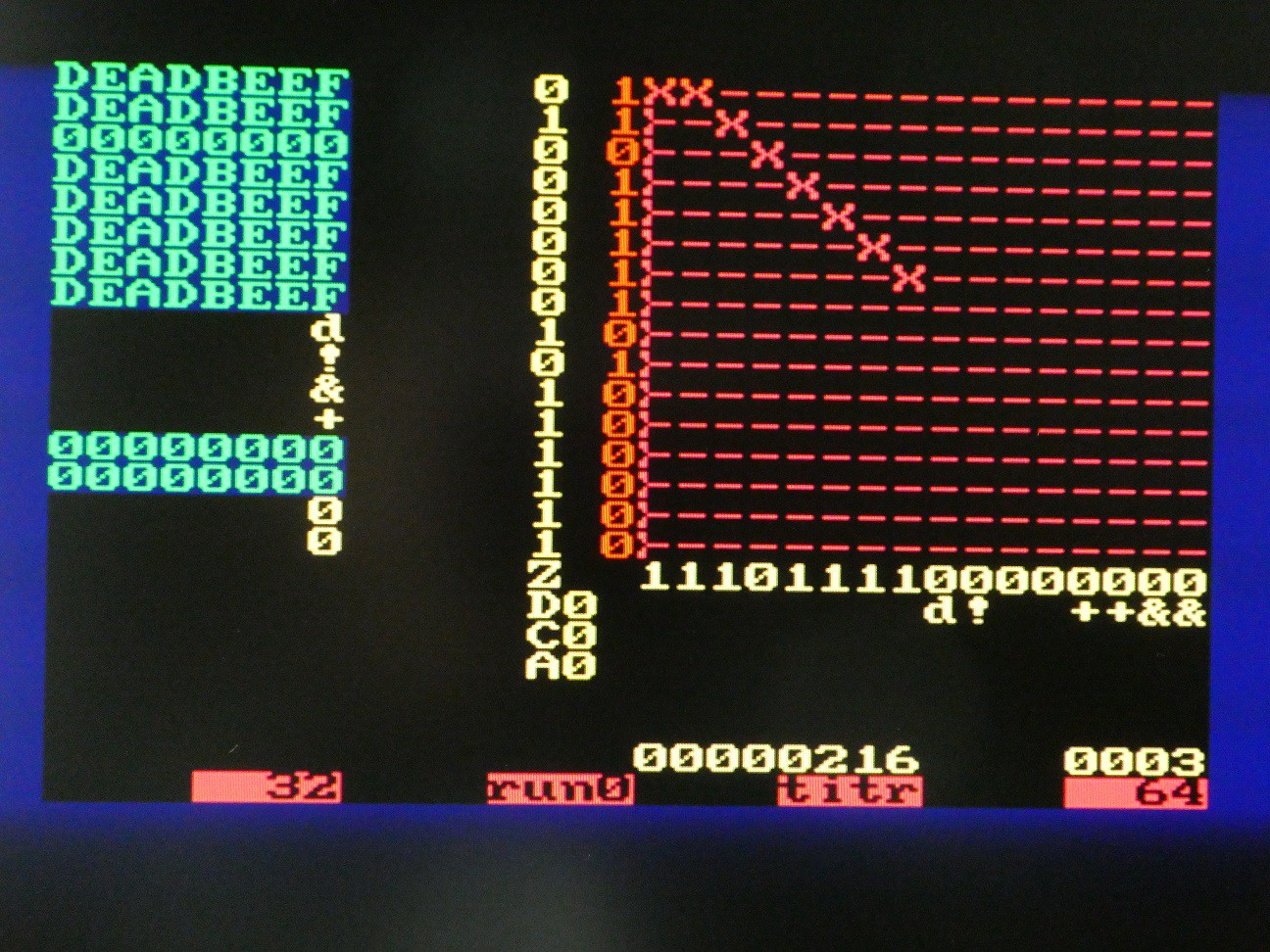
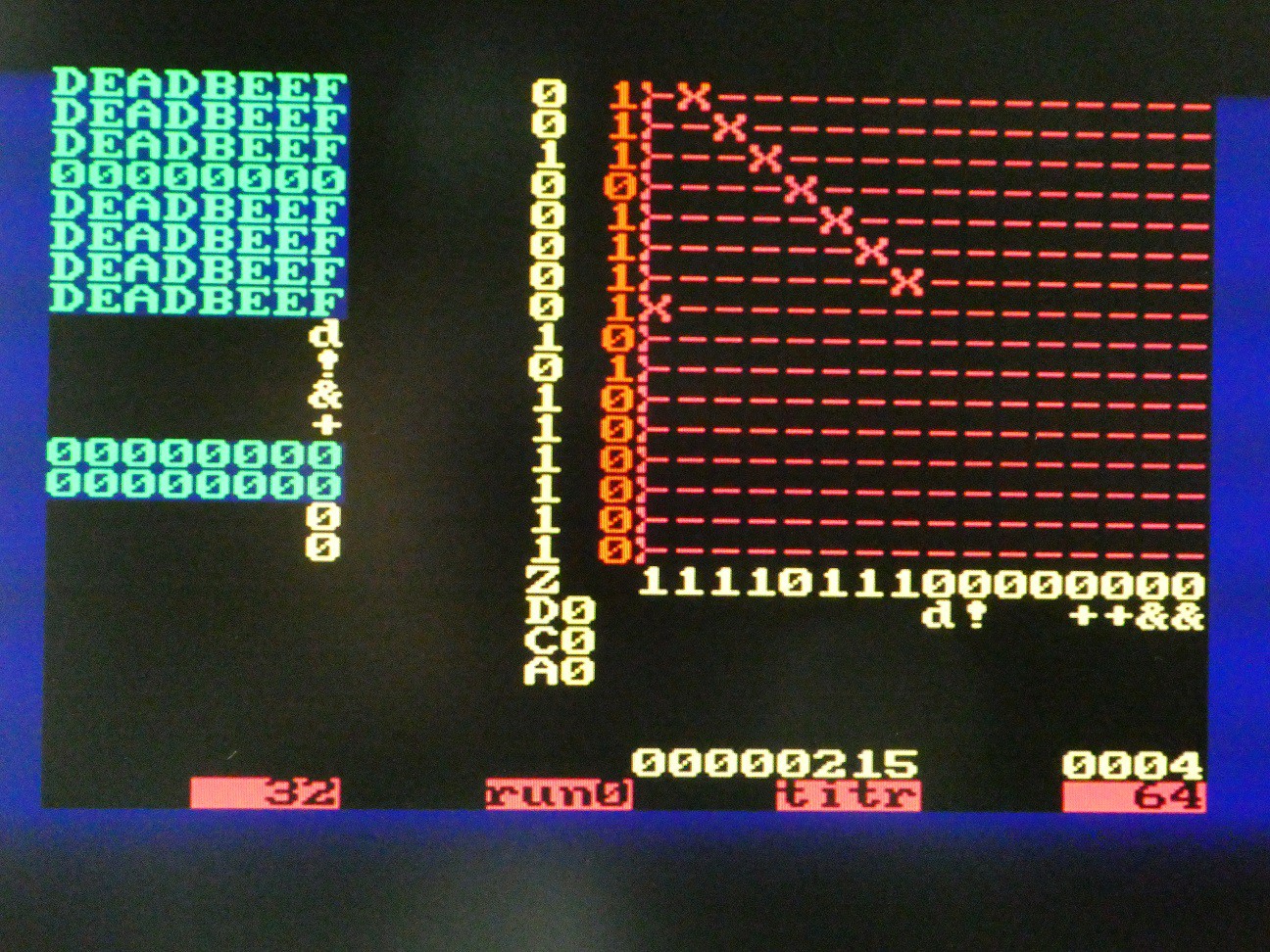
Visualizing CPU state
It is very useful for debugging and also to explain the concept to see the internals of the CPU, as execution is unfolding. There are few problems:
- 16*16 switch matrix is "logically" inside the CPU but physically it is outside. This is solved by "hardware window" component generating the row activation signals for MT8816 when CPU is not using it, one screen row at the time, and as column is known too, pick up the on/off state in X/Y matrix
- There is lots of registers inside the CPU - 8 32-bit general purpose, 16-bit zero flags, C, D, A flags. To avoid excessive connections, a multiplexing approach is used. The window is 32*32 and each of these 1024 location is described by a mask that selects a particular input, and then passes it through binary to ASCII or hex to ASCII lookup tables.
-- hardware window that shows the system state win: hardwin Port map( left => X"18", -- col 24, TODO make it dynamic top => X"10", -- row 16, TODO make it dynamic vga_x => vga_x, vga_y => vga_y, active => win_active, matrix => win_matrix, char => win_char, index => win_index, win_x => win_x, win_y => win_y, sy_cnt => sy_cnt, switch => switch, -- display the modes in the last row of the window mt_x => hc_mt_x(to_integer(unsigned(win_y(3 downto 0)))), mt_y => mt_y(to_integer(unsigned(win_x(3 downto 0)))), mt_c => hc_carry, mt_d => hc_delay, mt_daa => hc_daa, mt_z => hc_zero(to_integer(unsigned(win_y(3 downto 0)))), mt_hex => hc_reg );The key are values vga_x (0 to 79) and vga_y (0 to 59) that are generated by VGA controller. If these values fall within the 32*32 where the window is positioned (note the "top, left" offset of origin), win_active is '1' and win_x and win_y are valid - these are fed to CPU to extract a particular value from the register (e.g. 1 : 7 means least significant nibble from register 1). The hardwin component then internally generates ASCII representation which is output as win_char. If it is !=0, this character takes precedence over the one on same location in video RAM, so it appears that window floats above scrollable text screen.
The win_char is externally overriden in 16-bit mode and for the first 4 columns of the window to 0x00, meaning that it will be "chopped off" to hide upper 16-bits of the 8 registers:
-- if in 16-bit mode, simply chop off first four columns from hardware window (register bits 31..16) win_char_x <= X"00" when ((sw_32 = '0') and (win_x(4 downto 2) = "000")) else win_char;To show TOS on the 7-segment LED as an old fashioned calculator should, the hc_reg value should be intercepted at the right time, when win_y (row) is 0 and win_x (column) is 0...7, except 0 is most significant nibble, 7 least (only 2 to 7 are needed as the board has only 6 LEDs not 8). At those right moments, the values are captured into hc_tos display register which feeds the 7-seg using the led6:sixdigitsevensegmentled component in a standard multiplexed fashion.
-- catch stacktop appearing to display it on the 7seg LED on_dot_clk: process(dot_clk, win_x, win_y, hc_reg) begin if (rising_edge(dot_clk)) then if (win_y = "00000") then case win_x is when "00010" => hc_tos(23 downto 20) <= hc_reg; when "00011" => hc_tos(19 downto 16) <= hc_reg; when "00100" => hc_tos(15 downto 12) <= hc_reg; when "00101" => hc_tos(11 downto 8) <= hc_reg; when "00110" => hc_tos(7 downto 4) <= hc_reg; when "00111" => hc_tos(3 downto 0) <= hc_reg; when others => null; end case; end if; end if; end process;
Bit-serial CPU based on crossbar switch
256 switches and few shift registers to implement a working 16 or 32-bit integer arithmetic calculator (+, -, *, /, isqrt, BCD / bin conv..)