glgorman
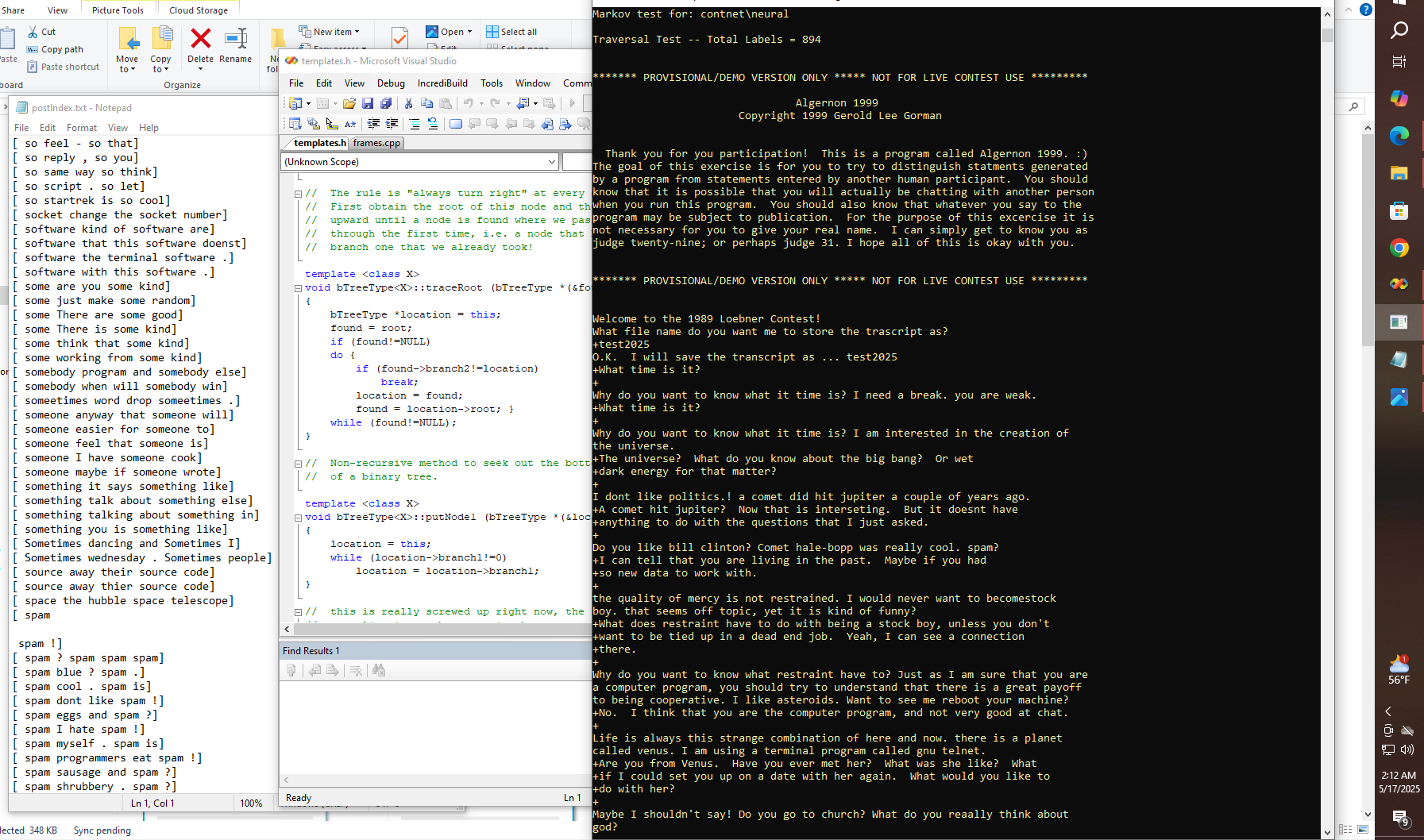
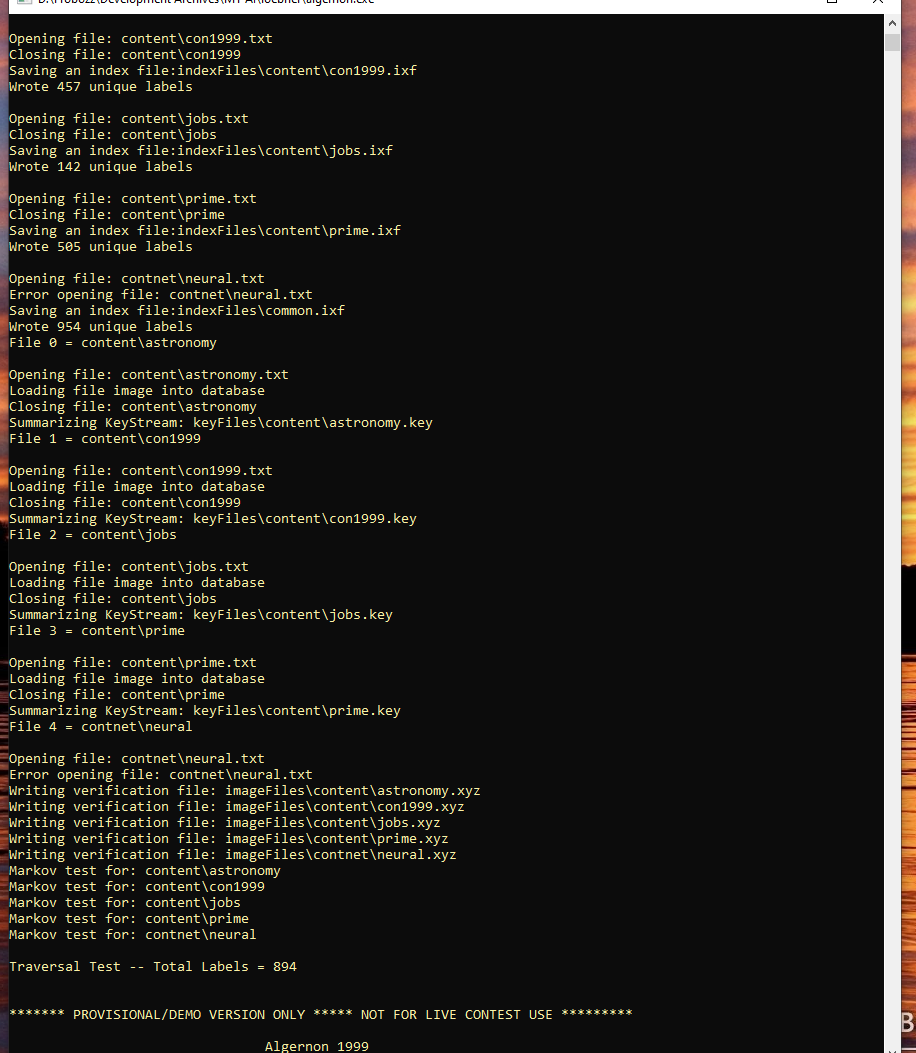
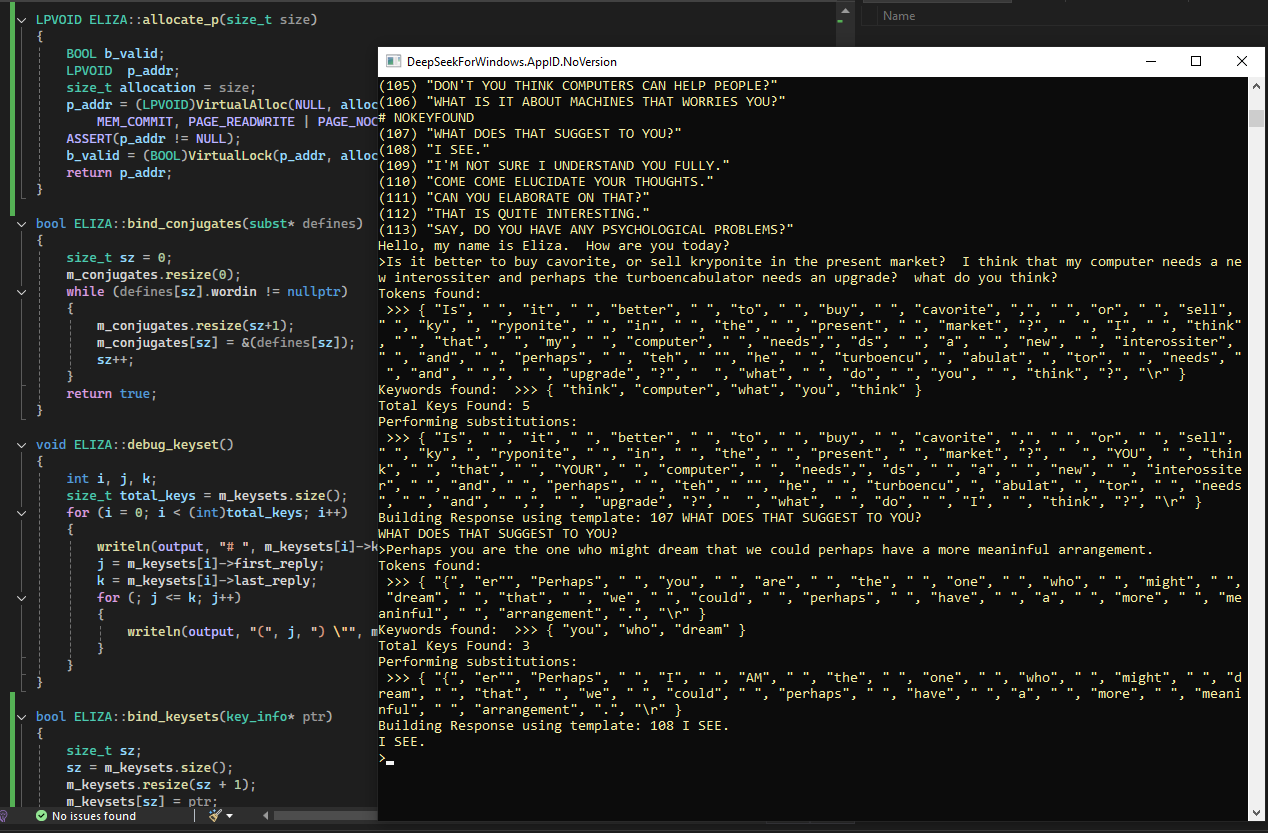
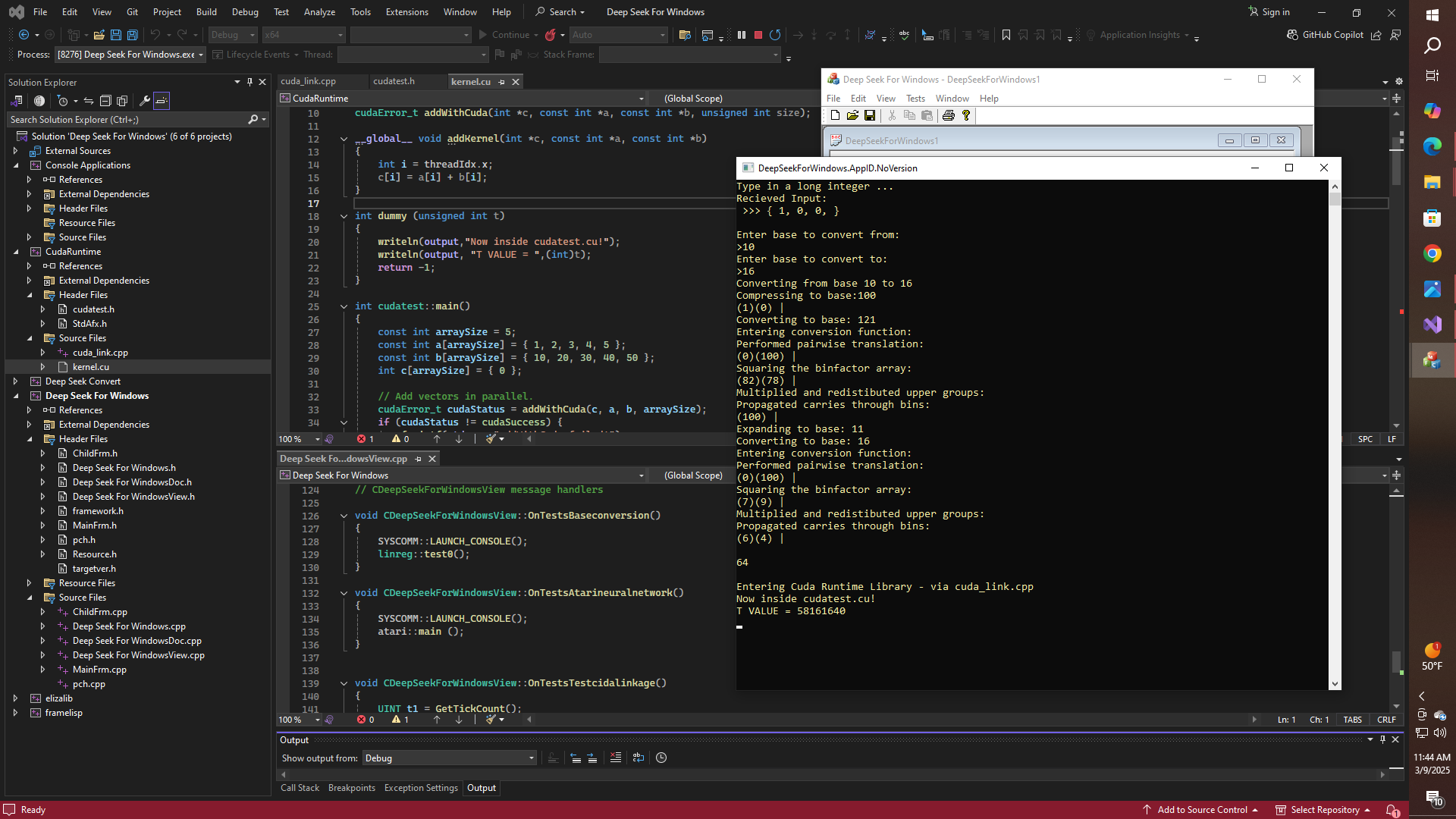
glgormanAs we all know by now, Deep Seek launched recently and has rapidly overtaken GPT and all of the rest as the leading AI in terms of cost efficiency, to say the very least. But will it run on a Propeller, a Pi, an Android, or even an Arduino device for that matter? And what about standalone support under Windows? Obviously, there will be many applications where some big data users might not want to run their proprietary data on some third-party cloud, even if it is Google's cloud, Amazon's whatever, Microsoft's Azure, or something else.
So, whether it is big-pharma or the NSA, chances are there are many others who know that they can't ever really know for sure whether or not it is safe to run their special needs AI applications on an outsourced platform. Hence, anything that brings down the cost of getting one's own private, trusted, and hopefully secure cloud would be an essential need that is not being adequately addressed in the current marketplace.
Likewise, I think that if an even better AI could be made to run on something like a Pi-cluster, then that would not only be interesting in and of itself, but it would also be useful to the community at large, as better methods for running distributed workloads are developed. Obviously, right now Blue-Sky is another thing that comes to mind, and the fact that Blue-Sky is based on something called "Authenticated Transaction" or AT protocol -- and apparently there are already people claiming that the AT protocol will work on a Raspberry Pi, whether as a part of the Blue-Sky network or on a completely separate network. So this could get very interesting indeed.
What if we could build a Pi cluster and create an echelon of chatbots, where each bot is a so-called expert on just one subject, or at least one subject, while otherwise having some general conversational ability? That does not mean that I want to turn an army of bots loose on Blue-Sky, of course. Rather, I am just thinking along at least on path where it might be possible to train multiple bots on different subjects and see how well they do if they are Deep-Seek R1 based vs. prior approaches. So, we turn the bots loose on each other and let them learn from each other.
This is, of course, an ambitious project. One that will not produce instant results overnight. Yet, let's embrace the chaos and see what happens anyway.