 Yann Guidon / YGDES
Yann Guidon / YGDESAfter the explorations with #YGREC-РЭС15-bis, I reached several limits and I decided to scale it down as much as possible. And this one will be implemented both with relays and VHDL, since the YGREC8 is a great replacement for Microchip's PICs.
A significant reduction of the register set's size is required so I/O must be managed differently, through specific instructions. The register map is now:
- D1 <= for NOP
- A1
- D2
- A2
- R1
- R2
- R3
- PC <= for INV
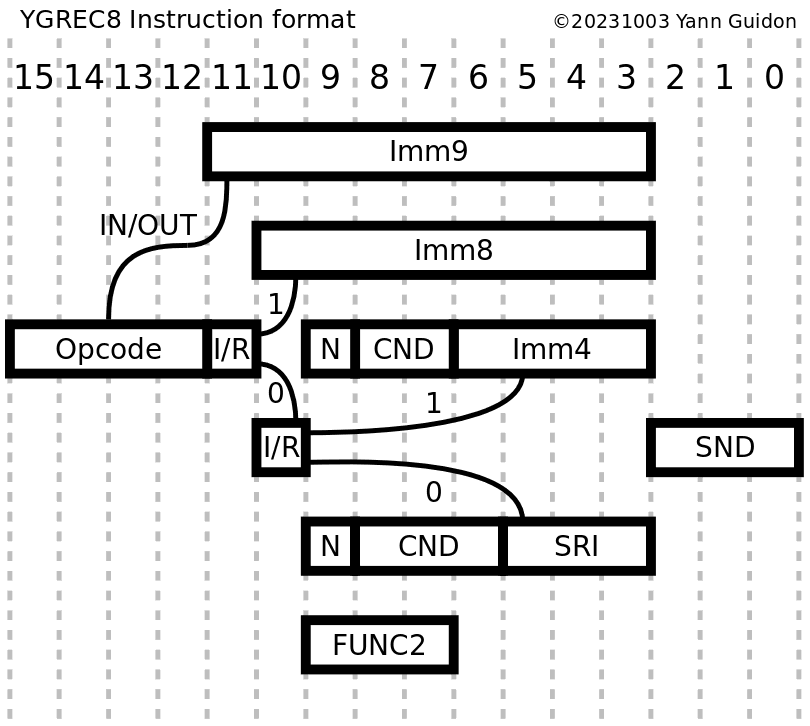
The instruction word is shrunk down to 16 bits. It is still reminiscent of the YGREC16 older brother but I had to make clear cuts... The YGREC8 is a 1R1W machine (like x86) instead of the RISCy YGREC16, to remove one field. Speed should be decent, with a pretty short critical datapath, and all the instructions execute in one clock cycle (except the LDCx instructions and computed writes to PC).
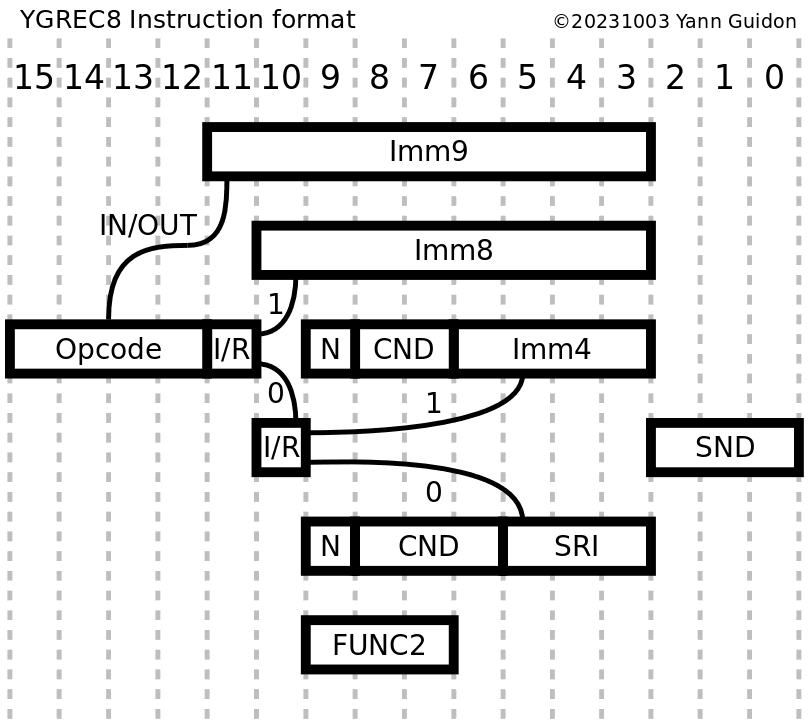
The fields have evolved with time (I have tried various locations and sizes). For example:
20171116: The latest evolution of the instruction format has added a 9-bits immediate field address for the I/O instructions.
20180112: Imm9 is now removed again...
20181024: changed the names of some fields
20181101: modified the conditions to change Imm3 into Imm4
20180112: Imm9 back again ! (for speed/latency reasons, no register operand is provided, an indirect IO register is used instead, and having more IO space is more desirable, otherwise only imm4 is available if a register operand is used)
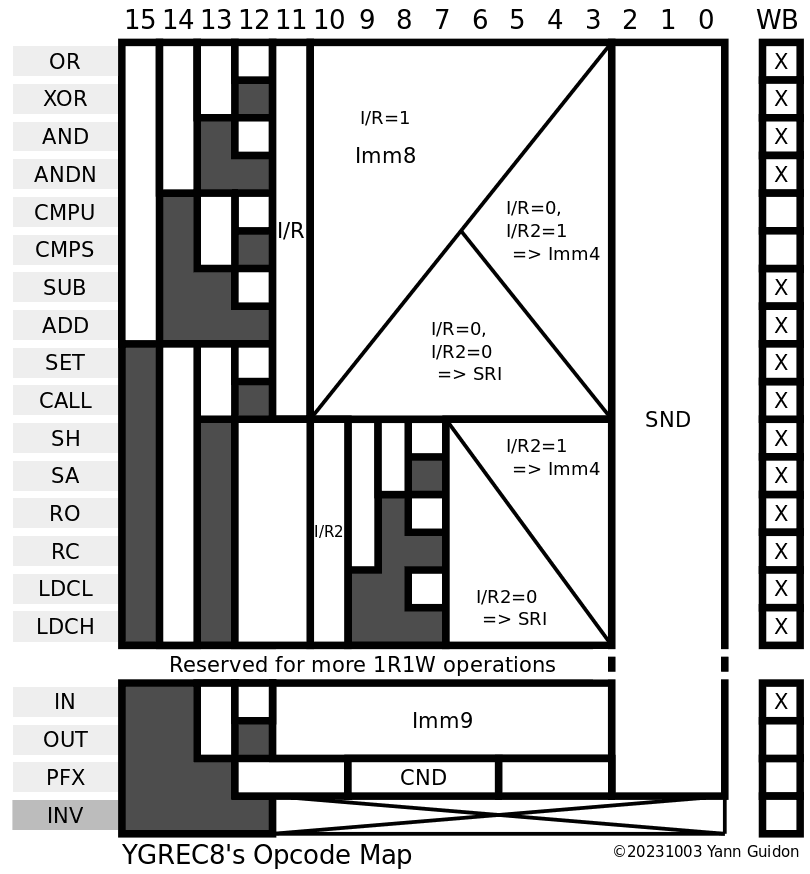
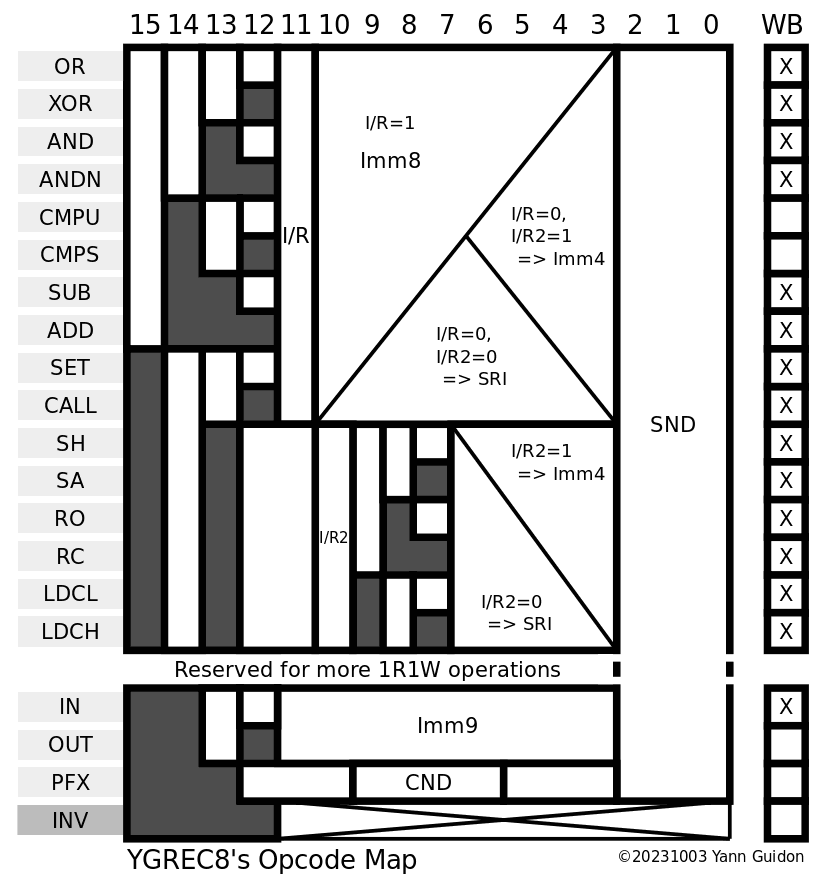
There are 18 useful opcodes (as many as EDSAC plus INV, and the pseudo-opcodes HLT and NOP), and most share two instruction forms : either an IMM8 field, or a source & condition field. The source field can be a register or a short immediate field (4 bits only but essential for conditional short jumps or increments/decrements).
The main opcode field has 4 bits and the following values:
Logic group :
- OR
- XOR
- AND
- ANDN
Arithmetic group:
- CMPU
- CMPS
- SUB
- ADD
Deprecated:
Beware : There is no point to ADD 0, so ADD with short immediate (Imm4) will skip the value 0 and the range is now from -8 to -1 and +1 to +8. (see 17. Basic assembly programming idioms)
Shift group (optional)
- SH/SA direction is sign of shift, I/R(bit9) is Logic/Arithmetic flag.
- RO/RC direction is sign of shift, I/R(bit 9) allows carry to be rotated.
Control group:
- IN,
- OUT (yes, the system is so small that a specific I/O channel system is required, unlike #YGREC16 - YG's 16bits Relay Electric Computer that uses register-mapped I/O)
- LDCL/LDCH
- SET
- CALL (maps to OVL and HLT)
The COND field has 3 bits (for Imm4) or 4 bits, more than YGREC16, so we can add more direct binary input signals. CALL is moved to the opcodes so one more code is available. All conditions can be negated so we have :
- Always
- C (Carry)
- S (Sign, MSB)
- Z (Zero, all bits cleared)
- B0, B1, B2, B3 (for register-register form, we can select 4 bits to test from user-defined sources)
(notice the mnemotechnic trick: ACSZ are in alphabetical order)
Instruction code 0000h should map to NOP, and the NEVER condition, hence ALWAYS is coded as 1.
Instruction code FFFFh should map to INV, which traps or reboots the CPU (through the overlay mechanism): condition is implicitly ALWAYS because it's a IMM8 format.
Overall, it's still orthogonal and very simple to decode, despite the added complexity of dealing with 1R1W code.
This project is more than an ISA or one implementation : the goal is to become a platform. See log 82. Project organisation

Logs:
1. Honey, I forgot the MOV
2. Small progress
3. Breakpoints !
4. The YGREC debug system
5. YGREC in VHDL, ALU redesign
6. ALU in VHDL, day 2
7. Programming the YGREC8
8. And a shifter, and a register set...
9. I/O registers
10. Timer(s)
11. Structure update
12. Instruction cycle counter
13. First synthesis
14. Coloration syntaxique pour Nano
15. Assembly language and syntax
16. Inspect and control the core
17. Basic assembly programming idioms
18. Constant tables in program space
19. Trap/Interrupt vector table
20. Automated upload...

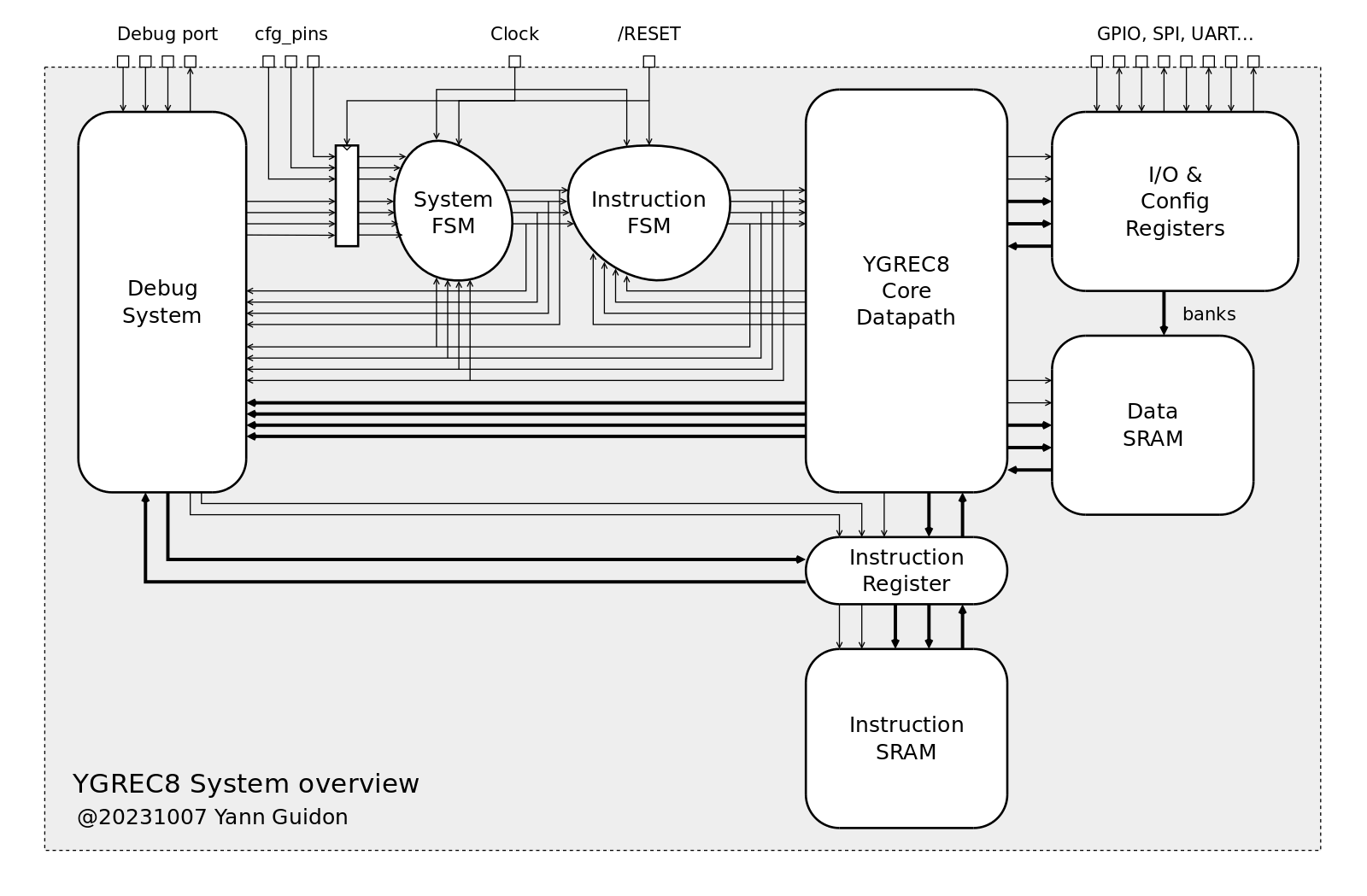
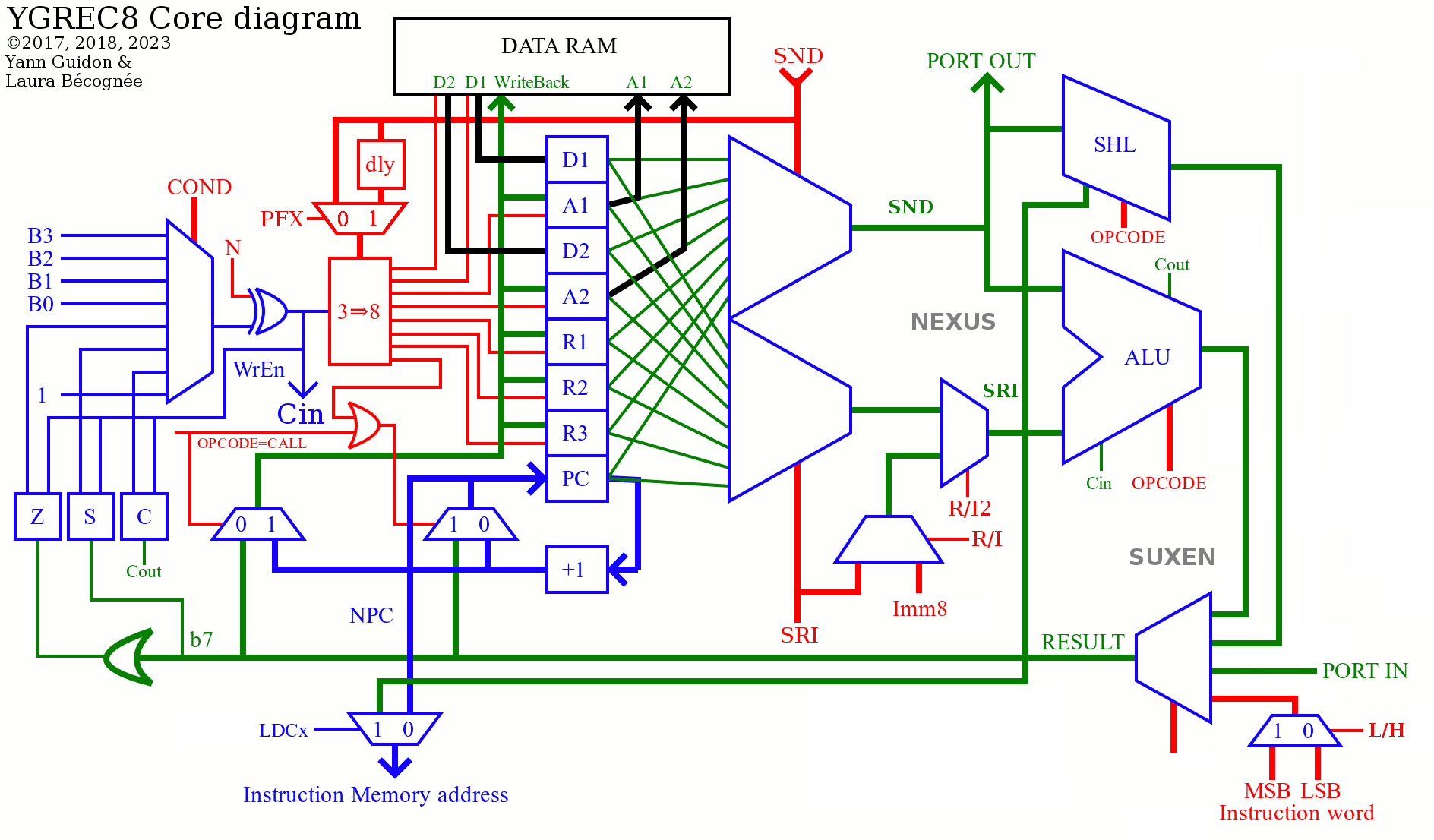


TODO: LDCC selects the high/low byte with the carry flag for example