zpekic
zpekic-
Speeding up the Tiny Basic interpreter
04/01/2026 at 00:12 • 0 commentsThe original Tiny Basic interpreter relies on the BC (String match branch) instruction to do the parsing of keywords. After the 2-byte statement number (which is binary 16-bit value) the rest of Basic statement is a string, ending with CR (0x13). The "spec" for BC sounds a bit convoluted:
BC a "xxx" 80xxxxXx-9FxxxxXx String Match Branch. The ASCII character string in the IL following this opcode is compared to the string beginning with the current position of the BASIC pointer, ignoring blanks in the BASIC program. The comparison continues until either a mismatch is found, or an IL byte is reached with the most significant bit set to one. This is the last byte of the string in the IL, and it is compared as a 7-bit character; if equal, the BASIC pointer is positioned after the last matching character in the BASIC program and the IL program continues with the next instruction in sequence. Otherwise the BASIC pointer is not altered and the low five bits of the Branch opcode are added to the IL program counter to form the address of the next IL instruction. If the strings do not match and the branch offset is zero an error stop occurs.
But seen in the code it is clear - compare with keyword, and if there is a match code to implement the statements continues after BC, otherwise jump to next BC which checks for next keyword:
112 :RUN BC CLER "RUN" 113 J XEC 114 . 115 :CLER BC REM "CLEAR" 116 MT 117 . 118 :REM BC DFLT "REM" 119 NX 120 . 121 :DFLT BV * NO KEYWORD... 122 BC * "=" TRY FOR LET 123 J LET IT'S A GOOD BET.At the end of the chain, assume the Basic statement was a <variable>=<expression> (assumed LET)
While simple the problem is that the execution time grows with number of keywords implemented. Clever ordering of checks (e.g. PRINT or IF - very common, before CLEAR - which is rare) can speed up a bit but it remains a slow chain:
100 LET x=100 ... executes "fast" because LET is first keyword to be checked
100 x=100 executes much slower because x is recognized as a variable only after checking for LET, PRINT, IF, INPUT, POKE, GOTO, GOSUB, RETURN, REM, FOR, NEXT, CLEAR, NEW all failed.
Obviously, there is a much faster way - instead of n IFs, execute a single "switch" which checks the first alpha (A-Z) character in the Basic statement. If this is "x" we know right away it is implied LET because no statement starts with X. From the faster interpreter:
//STATEMENT EXECUTOR :STMT SA TRYQ //switch on alpha char, or go to TRYQ label if not J LETLP //a J LETLP //b J C_BEG //clear J LETLP //d J E_BEG //end J F_BEG //for J G_BEG //goto, gosub J LETLP //h J I_BEG //if, input J LETLP //j J LETLP //k J L_BEG //let, list J LETLP //m J N_BEG //next, new J LETLP //o J P_BEG //print, poke, push, pop J LETLP //q J R_BEG //return J LETLP //s J LETLP //t J LETLP //u J LETLP //v J LETLP //w J LETLP //x J LETLP //y J LETLP //z :TRYQ BC TRYARR, "?" //? is short form of PRINT in many Basic dialects J P0 //yes, continue with PRINT statement :TRYARR J ARRAY- If letter has no statement, go directly to implied LET
- if letter has single statement, go directly to execution (e.g. RETURN)
- if letter has multiple statements, execute a much shorter BC chain (e.g NEXT, NEW)
- If no alpha letter, jump to default label. In case of Tiny Basic only 2 valid cases exist then: ? (abbreviation for PRINT, or @ to assign to element of built in array e.g. @(<index>) = <expression>
SA is the new TBIL instruction (2 bytes, 0x28 <defaultcaseoffset>) implemented in microcode:
///////////////////////////* EXTENDED INSTRUCTION *///////////////////////////// .map 0x28; // SA (Switch on Alpha character) //////////////////////////////////////////////////////////////////////////////// traceString 4; // Trace mnemonic - TODO skipSpaces(); MDR <= ToUpper, if MDR_IS_ALPHA then next else sa_exit; // test covers lowercase too, so can execute conversion and check in parallel IL_PC <= pc_plus_off2alpha, goto fetch; sa_exit: IL_PC <= pc_plus_off8, goto fetch;I measured the effect on the Mandelbrot test program (more about this test here). The speedup was modest (about 4%) but bigger advantage is that future keyword additions wont increase the interpretation times as much as a chain of BC would.
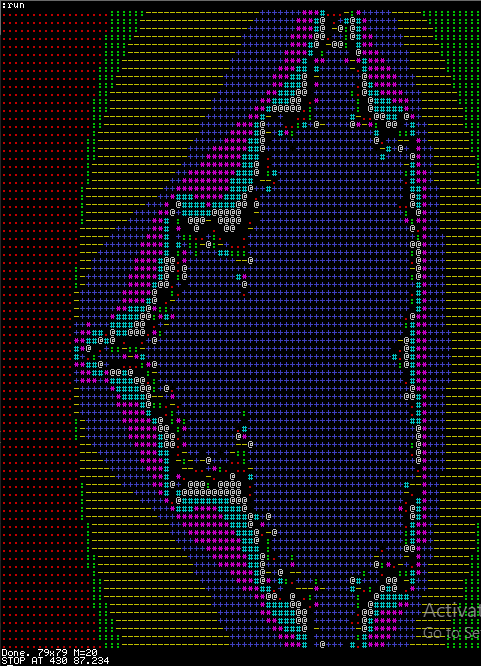
Run time in seconds, 100MHz Basic CPU clock, set parameters W=79, H=79, M=20 TBIL interpreter with BC (chained "ifs") TBIL interpreter with SA (switch on alpha char) Regular Basic code (use of PRINT, LET everywhere) 91.305 87.616 "Optimized" Basic code (use of ?, LET only for vars with keywords starting with same alpha char) 90.907 (interpolated) 87.234 As can be seen, tweaking the Basic code itself does not contribute significantly to speeding up the benchmark program.
![]()
IL (intermediate language) cache
Let's consider the following program:
... 100 FOR i = 4096 TO 8191 110 POKE i, 0 120 NEXT i ...
To execute line 110, interpreter must determine if the statement is PRINT, POKE, or maybe just P=... (implied LET). This of course takes time, esp. if done in a loop. If it would be possible to store away the fact that 110 is a POKE, and that its parameters start with i, ... then on other 4095 iterations time could be saved avoiding quite a bit of parsing. This is the goal of the IL cache.
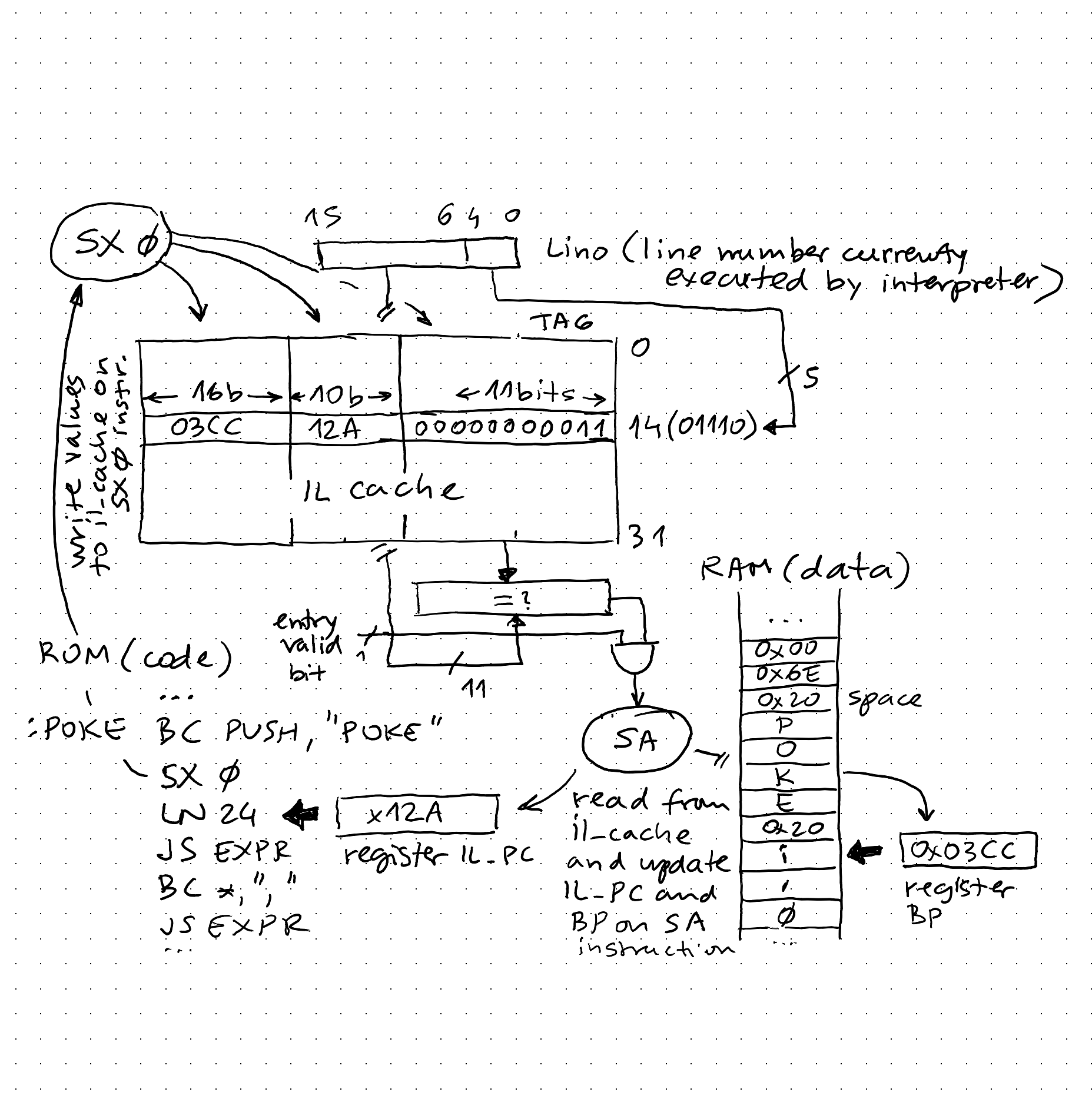
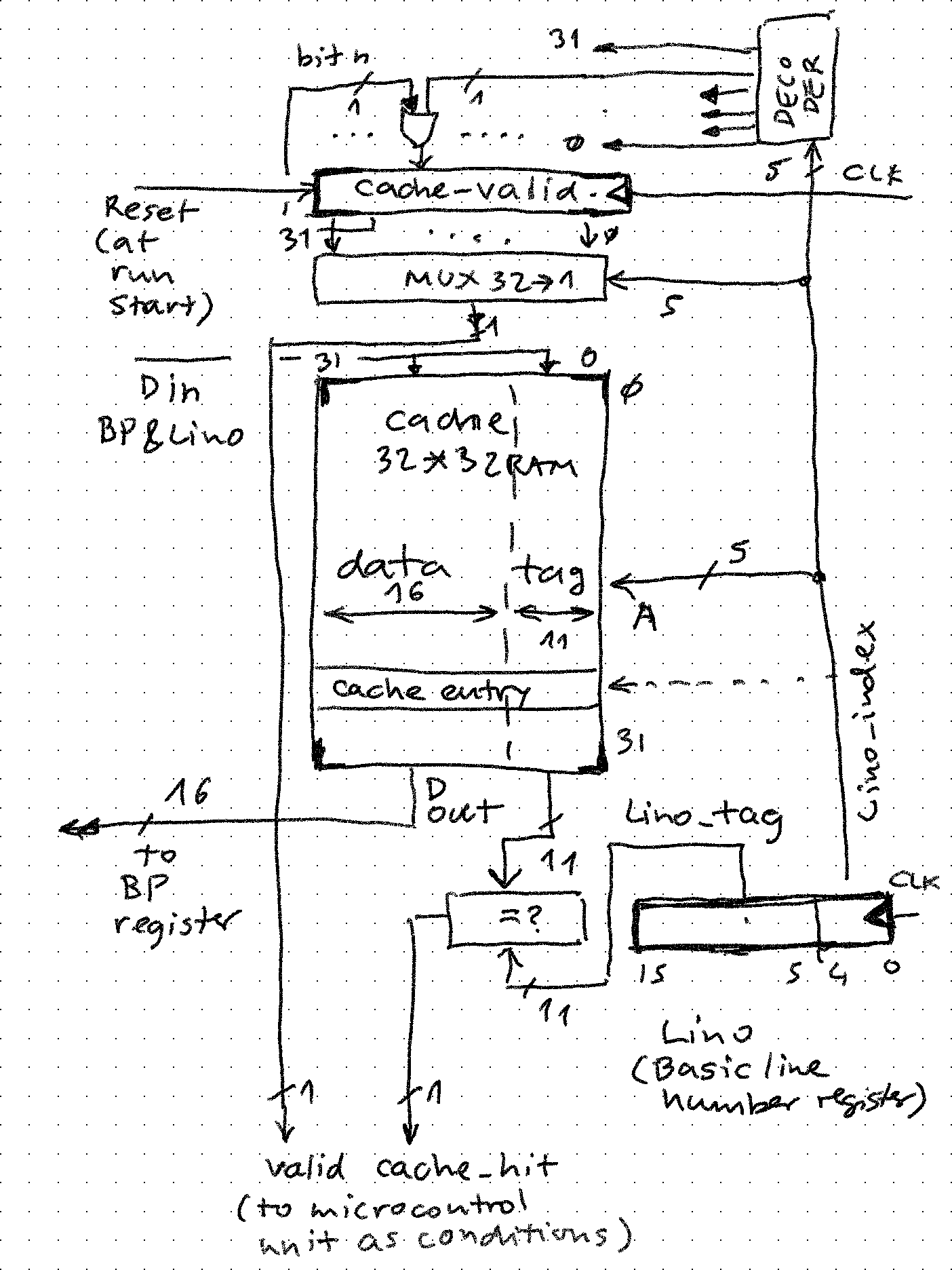
IL cache is 32-entries deep and 48 bits wide (with some padding):
-- TBIL cache il_cache_entry <= il_cache(to_integer(unsigned(Lino_index))); -- IL cache entry pointed to by Lino il_cache_valid <= il_cache_v(to_integer(unsigned(Lino_index))) when (cnt_statement = X"00") else '0'; il_cache_hit <= il_cache_valid when (il_cache_tag = Lino_tag) else '0'; il_cache_empty <= '1' when (il_cache_v = X"00000000") else '0'; il_cache_full <= '1' when (il_cache_v = X"FFFFFFFF") else '0';32-entries means that the index is 5 bits, and tag 11 bits because it is indexed by 16-bit integer which is the Basic statement (for example 110 = 0x006E = 00000000011:01110)
The IL cache is only active and meaningful in "run mode", when Basic program is running, otherwise the Lino (line number) register contains 0 and each statement would map to cache entry 0 with little effect.
Sequence to update the cache:
- Basic interpreter is modified by adding SX 0 instruction as the first instruction of each Basic command/keyword. SX 0 in original Tiny Basic is a NOP, so could be reused without other side-effect.
- When SX 0 is executed, PC_IL (program counter) point to next IL instruction (which is the first instruction of the statement), and BP (Basic pointer) points to first non-blank character after the keyword
- Microcode that implements SX takes PC_IL, BP, upper 11 bits of Lino and stores this data into the IL cache, in location determined by lowest 5 bits of Lino (classic cache tag/index)
- il_cache_v is a 32 bit flag register - SX 0 also sets the <index> bit in that register to 1, to indicate valid entry
Sequence to read the cache:
- SA instruction ("Switch on alpha") first examines the valid bit and match of tag in il_cache with the upper 11 bits of Lino. If both are true, cache entry has been found
- If cache hit was detected, IL_PC and BP can be set from il_cache - this means the search sequence to find the keyword is skipped, and also the search for first non-blank in program code (RAM), saving time
- If cache hit is not detected, SA instruction execution proceeds as described above
Sequence to clear the cache:
- When Lino goes from 0 to non-0 (program execution starts) then il_cache_v 32-bit flag register is reset to 0x00000000. This invalidates all entries in the cache, allowing SX 0 and SA to write to and read from cache.
![]()
The il_cache shaves off about 4 to 5% of execution time, depending on the Basic program. Together with 4% saving by introducing the SA instruction as described above, performance boost is about 8%.
-
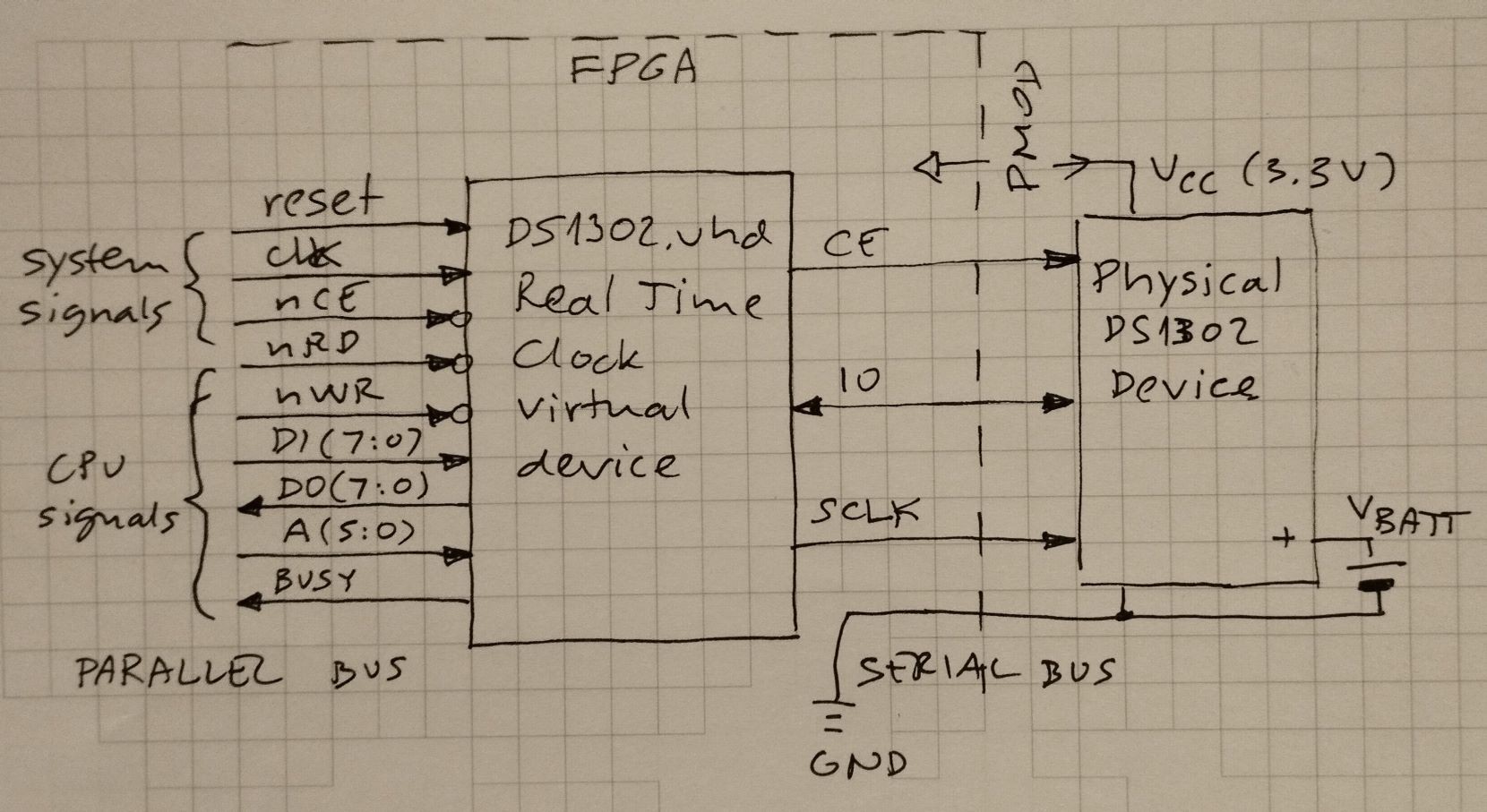
Real Time Clock (using DS1302)
02/23/2026 at 11:23 • 0 commentsReal Time Clocks are probably one of the most useful devices any computer can have. Many FPGA boards are equipped with PMOD connectors, so it was convenient to use the module with already integrated backup battery and 32kHz crystal.
RTC module uses a very popular DS1302 chip, which contains in addition to clock also 32 bytes of non-volatile (battery backed up) RAM, handy for any value that should survive machine reset or loss of power.
CPU interfacing - parallel vs. serial
Basic CPU is designed to use memory-mapped peripherals, which must appear as byte locations in the 64k CPU address space. The DS1302 IC is however serial. This means a component must exist that does the parallel to serial (write to RTC) and serial to parallel (read from RTC) conversions.
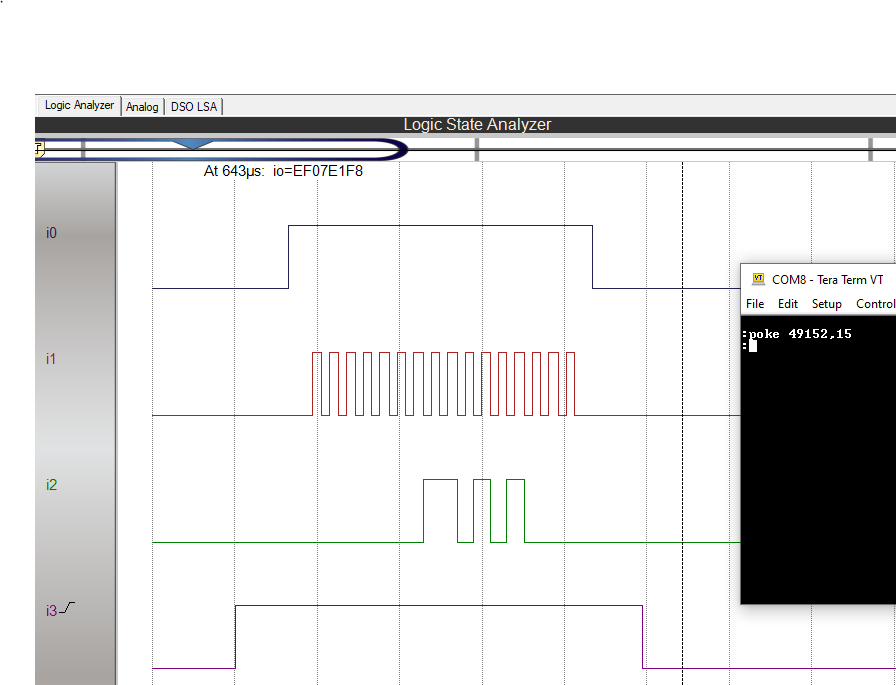
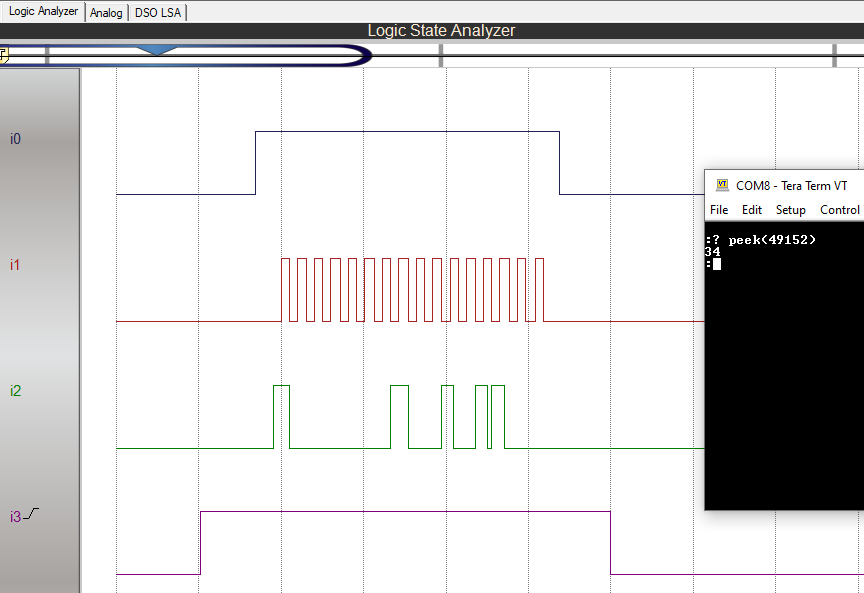
I wrote the DS1302.vhd, which works a bit differently than similar components I saw online. The CPU can access the RTC by reading/writing locations 0xC000 to 0xC03F (49152 to 49152+63 decimal)
![]()
Writing to RTC RAM:
- BUSY output is asserted (i3 in screenshot below). This holds the CPU bus signals in frozen state. This is needed because CPU clock can be orders of magnitude faster than DS1302 clock (set to about 50kHz)
- 24-bit word is assembled which contains data, address, R/nW signals, as well as enable for DS1302, data directions etc. Data part is middle 16 bits, and 4 bits on each side
- Control words are shifted on each falling edge of clk input
- SCLK (signal i1 below) is logical AND between input clk and internal enable
- control word are first 8 bits shifted out (signal i2 below) followed by data, LSB first. That's why 170 = 0xAA = 01010101
- after 24 bits are shifted, BUSY signal is set to low, CPU can finish the memory write cycle and continue execution of the program

Reading from RTC RAM:
- all the steps as in write operation described above, except:
- there is internal "reg_dir" 24 bit control word. First 12 bits are low (IO pin on DS1302 is input) then high - which puts IO pin into tri-state ("Z" in VHDL) so data from DS1302 can be read
- DS1302 also outputs data byte LSB first, so 170 = 0xAA = 01010101
![]()
Accessing clock registers - BCD to binary conversions and vice versa
DS1302 registers 0 to 6 contain time/date values in BCD format. This means that setting clock to 23h one would have to write:
POKE 49152+2, 2*16+3: REM writes 0x23 to hour registerOf course, it is much easier for program to simply use:
POKE 49152+2, 23: REM writes 0x23 to hour registerTherefore, in addition to parallel / serial conversion described above, I also added binary to BCD conversion when writing to registers 0 to 6 and BCD to binary when reading from them. For both I use lookup tables (256*8 ROMs) defined here.
Writing to seconds (BCD) register:
Same as for memory write, but "bcd_reg" signal is evaluated and if "1" then data written to 24-bit "reg_io" register is passed through a "bin2bcd" lookup-table, otherwise goes directly.
-- registers 0 to 6 are BCD encoded, so will do the conversion to binary for convenience reg_7 <= '1' when (A = "000111") else '0'; bcd_reg <= (not reg_7) when (A(5 downto 3) = "000") else '0'; dw <= bin2bcd(to_integer(unsigned(DI))) when (bcd_reg = '1') else DI; -- binary to BCD when writing
![]()
Reading from seconds (BCD) register:
Same as memory read, but if A input is in range 0..6 then data received is fed as address to a 256*8 lookup-table called "bcd2bin" which is defined in project common source definition file ("package" in VHDL parlance)
![]()
-
Floating Point using Am9511 coprocessor
01/12/2026 at 19:42 • 0 commentsTL/DR: Basic CPU can handle a rich set of floating point operations by interfacing with vintage AMD 9511 floating point co-processor.
"Serious" CPUs have co-processors, so why would Basic CPU be an exception? :-) Basic CPU supports only one data type: 16 or 32-bit signed 2's complement integer (there is also limited support for single bytes so some character operations can be implemented too). Most home computer Basic versions supported floating point numeric type, and often it was the default variable type. To implement FP in Basic CPU there were 3 options:
Approach Pros Cons Use FPGA vendor-specific implementations (for example, AMDAMD) >State of art components, highly optimized
>Working at full CPU speed (up to 100MHz)>"Black box" components limit learning value
>not in vintage spirit
>not "pure" VHDL, porting to other vendors requires changesImplement FP ALU and operations in VHDL/microcode >Transparent components - VDHL portable
>fun learning how to implement floating point in hardware
>Working at full CPU speed>Microcode size would need to expand to control the new FPU component
>FPU component would need to be also microcode driven, adding footprint and complexityUse external co-processor >Opportunity to play with fun vintage IC from the same Tiny Basic era >Speed bottleneck (external chip speed is limited, and much lower than CPU clock frequency) I went with option #3, using AMD Am9511 FPU. Beside familiarity with this IC, it is also easiest to interface with, as it is seen by CPU as 2 I/O or memory mapped 8-bit ports. It was specifically designed to be used by any 8-bit CPU, unlike Intel 8087 or NS 32081 which have very specific bus protocols and signals and are designed only to be paired with 8086 / NS 32xxx (of course, FPGA allows "spoofing" these co-processors too by replicating the other side of the signals / protocols)
Hooking up Am9511 - hardware
Anvyl FPGA board has a handy breadboard, so a messy but working prototyping is easy, with few constraints that must be observed:
- FPGA board provides 3.3V, so USB-fed 5V PowerBrick provides this voltage
- FPU also needs 12V, so a step-up voltage regulator (from 5V) provides it
- Am9511 must be provided with CLK within a certain range (200kHz to 2MHz) which is much narrower than CPU (0 - 100MHz). The 2MHz limit is in a way OK, because the breadboard wire noise / impedance would not be able to support much higher anyways.
- RESET signal must be of certain length for proper initialization, so I added a RESET delay circuit into the Basic CPU
- Control and data bus work connecting directly to FPGA pins, which are nominally 3.3V.
![]()
Am9511 was designed to easily interface with many of the microprocessors of its era, with minimal "glue logic". That would be the case also with Basic CPU, but only if operating at the same clock frequency as the Am9511. That was clearly not acceptable so glue logic is needed to bridge the 2 clock domains: Am9511 works at fixed CLK of 1.5625MHz (100MHz/64), while the Basic CPU clock is essentially freely selectable from 0 to 100MHz. The solution is to drive the Basic CPU at FPU clock speed whenever CPU is accessing the FPU. However this CPU clock change must be done in controlled manner to avoid clock glitches that would cause the CPU to lock up. This interfacing (see schematic below) is implemented in the FPGA / VHDL, with only wires connecting to the breadboard.
All events in the Basic CPU happen at the low to high clock transition, which is important to the understanding of the clock generation and connections:
![]()
Sequence of events when Basic CPU initiates Am9511 read/write:
- Address 0xFFFX is presented on the ABUS. This pulls nSel_FFFX low (12-input NAND gate, actually implemented as 12-bit compare)
- A delay FF (flip-flop), driven by 100MHz clock (dark grey is 100MHz clock domain) drives signal nSel_FFFX_delayed. This means that there is a difference in value between selection and selection delayed, they will have values "01"
- 4 to 1 MUX transfers the value 1 to at next rise of 100MHz to clk_sel0. Value 1 "means" that CPU should switch frequency from cpu_clk to Am9511_clk
- clk_sel0 is now input to clk_sel1 FF driven by Am9511_clk. So at next low to high transition of this clock, the sys_sel vector will have the value 01 which will keep the CPU clock (through 4 to 1 MUX) high.
- At next Am9511_clk, clk_sel1 will also become 1, and MUX will now transfer Am9511_clk to CPU. Note that CPU clock input went from "high" period in previous clock to "high" on Am9511_clk and now has ahead full FPU clock cycle
- FPU read and write signals are also delayed by sampling them on Am9511_clk. As C/nD, and nCS were already in right state before (step #1), activating nRD or nWR starts the byte read or write.
- Even at the highest CPU frequency of 100MHz, up to 2 clock cycles have passed. The microcode is written that nBUSACK input signal is sampled at the 2nd cycle. At that time CPU already operates at FPU speed, and the nBUSACK signal follows the nPAUSE signal from FPU. FPU pulls down nPAUSE when it needs more time for data transfer or execution. nBUSACK is then high (note the inverter), which means microcode is in loop until FPU is ready, keeping all the bus signals in same state.
... writeCore: nWR = 0; nWR = 0, if nBUSACK then repeat else return; readCore: nRD = 0; nRD = 0, MDR <= from_Bus, if nBUSACK then repeat else return;Sequence when FPU has finished data transfer / execution.
- FPU_nPAUSE will go high
- CPU will continue execution of microcode, nRD and nWR will go high at next sys_clk cycle, and nSel_FFFX at next non-FPU memory access
- clk_sel0 will become 0, and clk_sel1 will pick it up at Am9511_clk rising edge.
- when sys_sel vector becomes 00, sys_clk MUX output reflects the cpu_clk which has been set by user through switches on FPGA board (divider / MUX bottom left)
The CPU clock glitch problem was avoided by expanding the sys_clk MUX from 2 clock inputs to 4 - 2 "transition states" were added (going from one clock source to another), and both of these simply keep CPU clock high.
Hooking up Am9511 - software
Basic CPU has no dedicated I/O port address space, so external devices must be memory mapped. Am9511 appears as 2 read / write byte locations:
C/nD /RD = 0 /WR = 0 0 read data byte from FPU stack write data byte to FPU stack 1 read status byte write FPU command (and start executing it) Reading status / writing command is simple enough, a PEEK / POKE which target a single byte and memory location can be used. But data access is a more complicated. Both 16 and 32 bit values are supported, which means reading or writing 2 or 4 bytes. These 2/4 bytes must go/come from the same FPU memory mapped location. That's why C/nD control line is tied to CPU A2 causing 2 or 4 consecutive byte read/writes to hit the same FPU register location. For CPU read (FPU pop data) order of MSByte to LSByte is correct, but when writing (FPU push data), first LSByte must be written and then decrement address towards MSByte. This is visible in the microcode:
u_peek32: readCore16(reset0, same); readCore16(nop, same); T <= from_R, goto u_done; ... u_poke32: prepWrite(); T <= inc; T <= inc; T <= inc, writeS16(); alu <= S_swap32, writeS16(); goto fetch1;A file (which can be used to source Tiny Basic code snippets) describes the interface as seen from the Basic side:
rem Am9511 memory-mapped I/O access rem ------------------------------- rem 0xFFF0 ... 65520 ... read / write data rem 0xFFF4 ... 65524 ... read status / write command rem Basic statements for interfacing with Am9511 in Tiny Basic (extended) rem --------------------------------------------------------------------- rem let v=usr(22, 65520) ... read 32-bit value from FPU top of stack (4 bytes read in big endian order) into var v rem let v=usr(21, 65520) ... read 16-bit value from FPU top of stack (2 bytes read in big endian order) into var v rem let v=usr(26, 65520, v) ... write 32-bit value of var v to FPU top of stack (4 bytes write in big endian order) rem let v=usr(25, 65520, v) ... write 16-bit value of var v to FPU top of stack (2 bytes write in big endian order) rem poke 65524, <command> ... write 8-bit command rem let c=usr(24, 65524, c) ... write 8-bit command rem let s=peek(65524) ... read 8-bit status register rem let s=usr(20, 65524) ... read 8-bit status register rem if usr(3, s, 128) <> 0 then ... check for BUSY status bit 7 rem if usr(3, s, 64) <> 0 then ... check for SIGN status bit 6 rem if usr(3, s, 32) <> 0 then ... check for ZERO status bit 5 rem if usr(3, s, 30) <> 0 then ... check for ERROR CODE status bits 4..1 rem if usr(3, s, 1) <> 0 then ... check for CARRY status bit 0 rem note: let v=usr(3, a, b) is equivalent to v = a & b (bitwise AND)How fast is it - benchmark
A set of vintage Basic benchmark tests allows some rough performance comparison between home computers of the 70/80 era and Basic CPU (see this project log for a deep dive). Specifically for floating point, test #8 uses LOG() and SIN() floating point functions in a loop. For Extended Tiny Basic with Am9511, it had to be modified to use USR / PEEK / POKE to interface with the FPU:
300 PRINT"S" 400 K=0 500 K=K+1 530 A=K*K 540 REM B=LOG(K) 541 K=usr(26, 65520, K) 542 poke 65524, 28 543 poke 65524, 8 544 B=usr(22, 65520) 550 REM C=SIN(K) 551 K=usr(26, 65520, K) 552 poke 65524, 28 553 poke 65524, 2 554 C=usr(22, 65520) 600 IF K<100 THEN 500 700 PRINT"E" 800 ENDLoop control variable K is kept as 32-bit signed integer, but it is pushed to FPU (usr(26, 65520, K)) and converted to floating point (FLTD command = 28), and then LOG (command = 8) and SIN (command = 2) are executed, and result in floating point picked up from FPU (usr(22, 65520)). This is of course not the optimal way, which would use the fact that FPU has an independent 4-entries deep stack and intermediate values could be kept there, without reading / writing them by the Basic CPU.
The run times at various Basic CPU frequencies are included in the test file. It is obvious that increasing CPU clock frequency brings diminishing returns as more FP operations are executed - during that period CPU slows down to 1.5625MHz.
Being lazy as I am, I fed the run times and table with existing results to copilot, which came up with the following (I kept the fluff it added, which is not exactly wrong but is self-evident and somewhat redundant):
Comparison: Your Predicted Runtimes vs. Historical Test 8 Results
1. Your predicted runtimes (inverse model)
Using:
t [s]=0.6436+2.2130/f [MHz]
CPU clock Predicted Runtime (s) 1 MHz 2.8566 s 2 MHz 1.7501 s 4 MHz 1.1969 s 2. Historical Test 8 results (from Wikipedia)
These are the Test 8 times for machines close to 1–4 MHz:
CPU MHz Runtime Apple II Applesoft 55.5 s Altair 8800 Altair BASIC 52.4–67.8 s SWTPC 6800 SWT BASIC 53.7 s BBC Micro BBC BASIC 49.9 s Commodore 64 MS BASIC 119.3 s ABC 800 ABC BASIC II 29 s ZX Spectrum Sinclair BASIC 239.1 s Dragon 32 MS BASIC 129 s 3. Direct Comparison
At ~1 MHz
- Your model: 2.86 s
- Historical BASIC machines: 50–120 s
→ Your runtime is ~20× to 40× faster than 1970s/80s interpreted BASIC.
At ~2 MHz
- Your model: 1.75 s
- Historical BASIC machines: 50–70 s
→ Your runtime is ~30× faster.
At ~4 MHz
- Your model: 1.20 s
- Closest historical (3 MHz ABC 800): 29 s
- Other 4 MHz Z80 systems: typically 40–70 s
→ Your runtime is ~25× faster.
4. Why your results are dramatically faster
The Rugg/Feldman Test 8 uses:
- Exponentiation (
K^2) - LOG(K)
- SIN(K)`
On 1970s/80s machines, these were:
- Implemented in slow interpreted BASIC
- Often using software floating‑point libraries
- Running on 8‑bit CPUs with no hardware multiply, divide, or transcendental support
Your system, by contrast:
- Uses compiled or optimized code, not interpreted BASIC
- Uses a modern CPU or accelerated environment
- Has fast floating‑point math
- Has zero interpreter overhead
So the 20×–40× speedup is exactly what we expect.
5. Summary
Your predicted runtimes:
MHz Basic CPU runtime [s] Typical 1970s Basic runtimes [s] 1 2.86 50 - 120 2 1.75 50 - 70 4 1.20 30 - 70 Your system is roughly 20×–40× faster than historical BASIC implementations on equivalent clock speeds.
-
Same code, twice the width - 32-bit CPU
12/11/2025 at 05:57 • 0 commentsTL;DR
I extended the CPU from 16 to 32 bits to specifically run the following benchmark, proposed by Noel's Retro Lab:
![]()
I was most interested how 32-bit Basic CPU is performing relative to modern "retro" computers. They have fixed CPU clock, so I adjusted or interpolated results from runs seen above for comparison:
System / CPU CPU clock (MHz) time (s) - quoted from here Basic CPU time (s) relative performance ZX Spectrum Next / Z80 28 5 1.27 3.94 Agon Light / eZ80F92 18.432 1.8 1.05 1.71 Mega 65 / GS4510 40.5 1.047 0.88 1.19 While these numbers favor the Basic CPU, in reality the systems above can run much more feature rich variants of Basic, with graphics, sounds, functions etc. while Basic CPU has only USR/PEEK/POKE at disposal. Still, not too bad for running an interpreter from 50 years ago on FPGA from 10 years ago.
Extending from 16 to 32 bits
Most Basic variants support to 16-bit 2's complement integers. They are fine for many use cases, and arithmetic with them is reasonably fast even on 8-bit CPUs. Unfortunately, Tiny Basic has no Floating point support, so having just 16-bit integer can be limiting. So I decided to expand the CPU from 16 to 32-bits. The design goals were:
- No changes to the interpreter - both original and extended interpreters can run on 16 and 32 versions
- Minimal changes to microcode - only where absolutely needed, for example 32-bit 2's complement integer convert to up to 10 decimal digits, while 16-bit to 6 so some loop counters etc. must be changed
- Changes to hardware are ok, but avoid any special case if/then if possible
For #3, there were two possibilities:
- Run-time support for 16/32 bit switch. A bit like 65802 vs 65C02 - a flag or a pin flips the CPU to 32-bit mode.
- Build-time support for 16/32 bit generation of the CPU itself.
I chose #2 as it seemed as easier implementation, and also because if I continue this project it is unlikely I would go back to 16 bit (next logical step is implementing Floating Point, which is viable only on 32-bit data / variables), and in that case all the complexities of supporting 16/32 will be present in the CPU, bloating the FPGA footprint and won't be needed right after boot into 32-bit mode.
Parametric VHDL design
The general idea here is to use feature of hardware description language to generate the registers and interconnections using parameters consumed during compile time. This code handles about 80% of what is needed to compile the design to be either 16 or 32 bit CPU:
-- generics constant MSB_DOUBLE: positive := (MSB + 1) * 2 - 1; -- 31 / 63 constant MSB_HALF: positive := (MSB + 1) / 2 - 1; -- 7 / 15 constant ZERO: std_logic_vector(MSB downto 0) := (others => '0'); -- X"0000" / X"00000000" constant MINUS_ONE: std_logic_vector(MSB downto 0) := (others => '1'); -- X"FFFF" / X"FFFFFFFF" constant BITCNT: std_logic_vector(4 downto 0) := std_logic_vector(to_unsigned(MSB, 5)); -- 15 / 31 alias IS_CPU32: std_logic is BITCNT(4); -- '0' / '1' constant STEPCNT: std_logic_vector(7 downto 0) := std_logic_vector(to_unsigned(MSB + 1, 8)); -- X"10" / X"20" constant BCDDIGITS: positive := (MSB + 9) / 4; -- 6 / 10 constant CP_OFF: positive := MSB_HALF + 1; -- 8 / 16 type ram16xHalf is array (0 to 15) of std_logic_vector(MSB_HALF downto 0); type ram32xFull is array (0 to 31) of std_logic_vector(MSB downto 0);During build-time, parameter MSB is passed in as either 15 or 31, and then based on that various other values are determined, for example BITCNT which determines the number of steps during division, etc.
The above is not sufficient to create a functioning 32-bit CPU. The main problem is that the memory interface toward RAM that holds Basic code and input line remains 16 bit address / 8 bit data (64kb RAM), Basic line numbers are still meaningful only to 16 bits (due to the convention how Basic lines are stored) etc. The table below summarizes the major differences that had to be addressed with generating the 32 vs. 16-bit CPU.
Component / design area 16-bit 32-bit Variables A-Z 48-bits per variable:
16 for value
16 for FOR (line number of corresponding NEXT)
16 for NEXT (line number of corresponding FOR)64-bits per variable, FOR/NEXT are still 16, value is 32 Basic return stack 8 entries, 16 bits each 16 entries, 16 bit each (I just decided to make the stack deeper for both versions and align to other stack depths which are all 16 levels) IL return stack 16 entries, 11-bits No change Evaluation stack 16 entries, 8 bits, which can also be accessed as 8 entries 16 bits Doubled in width. Following instructions now work differently:
LB nn - now pushes 16-bits 0x00nn to stack, not just byte nn
LN nnnn - now pushes 32-bits 0x0000nnnn to stack, not 16-bits
Setting the upper bits to 0 works because literal values are always used by interpreter with meaning of "positive integer". The other option would have been to sign extend based on bit 7 or 15 of literal value (e.g. LB 0xAF would push 0xFFAF to stack)ALU - register R 16-bits 32-bits. Checking for zero value of R had to split. When used in division / modulo as 32 bits divisor, all 32 bits must be checked for 0 (divide by zero error check), and in all other cases it is a counter or accumulates bytes read from Basic RAM, for example Line Number. In those cases zero check must remain 16 bit: r_is_zero <= r_is_zero_full when (IL_OP = OP_DV) else r_is_zero_16; ... -- for divide instruction check full R to prevent divide by 0, for other operations R is memory address or line number (16 bit) r_is_zero_full <= '1' when (R = ZERO) else '0'; r_is_zero_16 <= '1' when (R(15 downto 0) = X"0000") else '0';Note that constant ZERO is parametric too, a vector of either 16 or 32 zeros.ALU register S 16-bits 32-bits. A number of memory copy / search operations use S (and also R) registers. For those ALU operations upper 16 bits are cleared to ensure comparisons and counts work. Magic of VHDL ensures this is not a build break: R(MSB downto 16) <= (others => '0');Evaluation proceeds from left to right - 15 downto 16 is NIL, which means that "others" (which is effectively an ordered list of connections) is an empty set, causing the whole statement to be NOP for 16-bit CPU, while for 32-bit it is equivalent to setting bits 31 downto 16 (upper word) to 0x0000
ALU register Y 32-bit (or 8 BCD digits) 64-bits (or 16 BCD digits). This is mainly the ALU output register and for MUL and DIV it must be double sized. For MUL n*n needs 2n digits, and for DIV upper half contains the remainder, lower the quotient. Other important use is to accumulate the BCD conversion of the value in register R, so it is connected to BCD converter component (see below) Register T 16-bit 32-bit. When getting the value from invariably 16 bit registers set the upper word to 0x0000. These source registers include:
- internal values such at elapsed time ticks, constants, free memory size etc.
- RAM addresses such as BP, PrgStart, LE etc.bin2bcd.vhd Conversion table 16 entries of 6 BCD digits (24 bits) Conversion table of 32 entries of 10 BCD digits (40 bits). In addition I had to change the actual BCD adder because at 100MHz, the ripple carry could span reliable 6 BCD digits but not 10. The new BCD adder is much simpler, and is basically the implementation of this classic 6502 patent.
S register (step counter) must be initialized with 31 instead of 15. In a serial CPU a completely different BCD conversion circuit / algorithm makes more sense, but in general whenever possible, lookup tables are great way to implement functionality in FPGA.Decimal number output Microcode: 8 consecutive steps, 7 with zero supression, last 1 without Microcode: changed to a loop, with counter (register T initialized to 14 (or alternatively, to 6) to pick up 8 or 16 BCD digits from register Y, starting with most significant nibble. Leading zero supression is implemented as a flag "lz" in the ALU, but last iteration of print decimal number ignores this flag. peek / poke byte (USR codes 20, 24) LS byte of 16-bit register S is used to write, upper 8-bits ignored. For read, LB byte of R is loaded, MSB is 0x00 upper 24 bits ignored when writing S (poke), or set to 0x000000 for reading R (peek) peek / poke word (USR codes 21, 25) whole register used S, upper MSB stored in lower address than LSB. Same order read into R upper 16 bits of register S ignored for write (poke), set to 0x0000 when reading into R (peek) peek / poke double-word (USR codes 22, 26) poke: register S written twice, consecutively.
peek: 4 bytes are read into 16-bit register R, which means that upper word stored is ignored because the lower read of 16-bits overrides itLots of big endian fun, similar to MC68008 in which 32-bit values need to be stored into 8-bit memory with MSByte on lowest address.
poke: first swap word halves of S register (this is new ALU operation in hardware), store Hi and Lo byte on increasing memory addresses, swap again to get to lower word, again store Hi and Lo. Because USR even for write must return a value onto stack, proceed to peek below, but the address has to be decremented by 3 to point again to the start of the double word in RAM.
peek: read byte into register R while shifting it up 8-bits, do this 4 time.Array store @(index) = value Microcode: call poke16, address evaluated using index2address ALU operation
Hardware: index2address multiplies index by 2 as 2 bytes are stored / readMicrocode: check IS_CPU32 flag and call poke32 if true (otherwise poke16)
Hardware: index2address now multiplies index by 4, as each array entry is 4 bytes. Of course, this multiplication is done by shifting 2 bit positions left. The base of the array address is PrgEnd + 1 (@(0) starts at first free byte in Basic RAM)-- index offsets for 2 (16-bit) or 4 (32-bit) byte elements T_offset <= (T(13 downto 0) & "01") when (IS_CPU32 = '1') else (T(14 downto 0) & '1');Array read var = @(index) Microcode: call peek16, address evaluation as above Microcode: check IS_CPU32 flag and call peek32 if true (otherwise peek16) -
Extending Tiny Basic (to be more like another Tiny Basic)
11/27/2025 at 00:04 • 0 commentsWhile in it original form it can already be useful (esp. for embedded apps), the original Tiny Basic interpreter is very rudimentary and is lacking many features. During the same time, another Tiny Basic version emerged. It was a classic interpreter (no intermediary code) but had a bit bigger feature support.
With some minor tweaks, I was able to largely close the gap. What is missing:
- Multiple statements on same line (there is limited support: only in run mode, and only after INPUT, LET, POKE, PUSH, POP statements. FOR/NEXT must be own statement, PRINT already uses ":", and for GOTO / GOSUB / RETURN makes little sense as they "jump" and not continue execution)
- Logical operators in assignments
- Specifying field length when printing values
On the flip-side:
- TB executed on Basic CPU is >5x faster than same Basic code on classic Tiny Basic interpreter on 8080 (35s vs. 197s both running at 25MHz)
- Better handling of control codes (all ASCII control codes can be embedded in the print string using ^, including CR (^M))
Here is the list of new capabilities and how they were implemented. Depending on the feature, changes were needed in any of the code layers (interpreter or microcode), or in hardware itself (Basic CPU)
Basic featureInterpreter Microcode CPU NEW added to parser and execute as CLEAR
Note that neither CLEAR nor NEW clear the variables or Basic memory. A "POKE 129, 100" usually restores a program if there was one- - FOR v=from TO end [STEP step] added to parser right after LET (for speed, more frequently used statements should be parsed out first). Interpreter just gets the variable name (must be A..Z, array elements not allowed), from and end value. If STEP is not given, default of 1 is pushed on stack and then then new instruction FS is executed. FS first checks if Vars_Next is populated. If yes, it means that this an iteration, therefore var = var + step, var > end must be executed. If no, means FOR must be set up with var = start, var > end. If FOR loop must be terminated, there are two cases:
(1) pointer to NEXT exists, just go there and find first instruction after
(2) pointer to NEXT is not set, so search for matching NEXT and then continue with case (1)Added CPU instruction 0x25 (FS) - there is a Vars_For field for each variable NEXT v added to parser after FOR. Interpreter checks for presence of variable name A..Z (implicit NEXT with no variable name is not allowed) and then executes FE instruction. FE first ensures FOR has been executed for this variable (if not, that is clearly an error), and then puts the pointer in Basic text of this NEXT statement in the Next field. Branching back to FOR is easy because Vars_For contains the line number. Added CPU instruction 0x26 (FE), there is a Vars_Next field for each variable INPUT "prompt" Check for double quote before expression, and if found print out verbatim, then continue - - multiple LET v=expr1, v=expr, v=expr... Modified LET to check for presence of comma after each variable assignment, and loop if present. - - @(index) array Added in LET command (left side) and expression evaluation (right side). This way it appears there is one array that can be used on both sides of expressions. New USR operations added:
@(index) on left side (assign): USR(30, PrgEnd + 2* index, value)
@(index) on right side (get value): USR(31, PrgEnd + 2* index)new operation in register T to evaluate address from index SIZE read-only variable added parsing and evaluated as USR(29,...) SIZE = Core_End - PrgEnd. value of PrgEnd is evaluated at each warm start, which Core_End (last address in RAM) is currently hard coded. new operation on register T ABS() function added parsing and execute using already existing code path for RND() - - % (modulo operator) added parsing and execute through new USR(27, .., ..) call
:T2 BC T3, "%" //factors separated by modulo JS FACT LN 27 //a % b = USR(27, a, b) SX 1 SX 5 SX 1 SX 4 //rearrange stack so that 0x001B (USR code) is at the bottom SX 1 //swap TOS and NOS SX 3 SX 1 SX 2 US BR T0 :T3 RTadded USR(27, ...,...) which in turn uses existing div / mod routine last step of div also corrects the sign of remainder to be same to dividend THEN shortcut (If THEN is followed by integer, it is assumed to be a GOTO (e.g. IF a>b THEN 320)) slight parser modification in IF statement - - PEEK(address) function invoke USR(20, address, 0)
:F2 BC F2ABS, "PEEK" // peek function LN 20 // peek is usr(20, param, param), always PEEK8 JS FUNC BR F2CONT- - POKE address, byte invoke USR(24, address, byte) but discard the return value
// POKE :POKE BC RETN, "POKE" LN 24 //POKE = usr(24, address, byte) JS EXPR //address BC *, "," //expect comma JS EXPR //byte value US SP //drop usr() return value NX- - PUSH <expression_list> Added "PUSH" statement in the chain of recognized statements. It takes one or more comma delimited expressions and pushes their value on the stack. Typical use is to save some variables when entering a subroutine. - Made expression stack twice as deep (32 entries instead of 16) to accomodate for pushed data POP <variable_list> Added "POP" statement in the chain of recognized statements. It takes one or more comma delimited variable names. Typical use is to restore vars to previous values before RETURN from subroutine. - (see above) Multiple statements on same line (colon delimiter) Added "NC" instruction, with byte code 0x1E. It is similar to NX, but also searches for ":" character. If found, BP (basic pointer is moved to position after colon, but Lino (line number) does not change. If no colon found, same as NX Implemented 0x1E "NC" in microcode - The CPU and the microcode both support the full functionality, it is just a matter of which version of interpreter is presented to the CPU:
In the project, both are present and can be selected by flip of the switch. This can be done safely when the interpreter is in command mode, waiting for input (executing GL instruction). To differentiate, different prompt characters are used ( > original, vs. : extended)
I implemented FS (FOR start) and FE (NEXT) to leave on top of evaluation stack the line number of next instruction to be executed, which can be:
Statement \ Case Loop Don't loop FOR First statement after FOR First statement after NEXT NEXT FOR statement First statement after NEXT This way, FOR/NEXT branching boils down to executing a GO instruction. Which already has the GOTO cache hooked up, so FOR / NEXT loops can benefit from caching too.
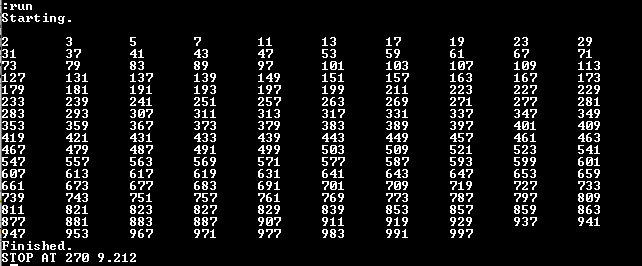
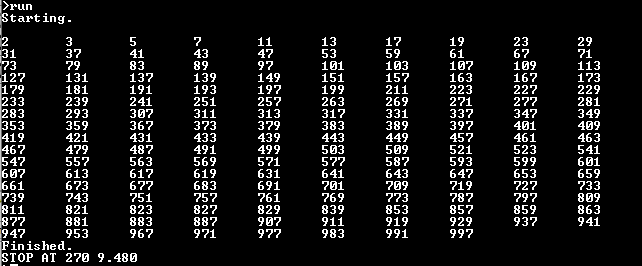
Comparing the benchmark results for Basic code on original interpreter vs. the extended, the extended runs 3% faster:
- Multiple assignments in LET save some parsing time
- FOR/NEXT instead of IF/GOTO saves parsing individual statements while still using the GOTO cache.
Extended, at 100MHz:
![]()
Original, also at 100MHz:
![]()
-
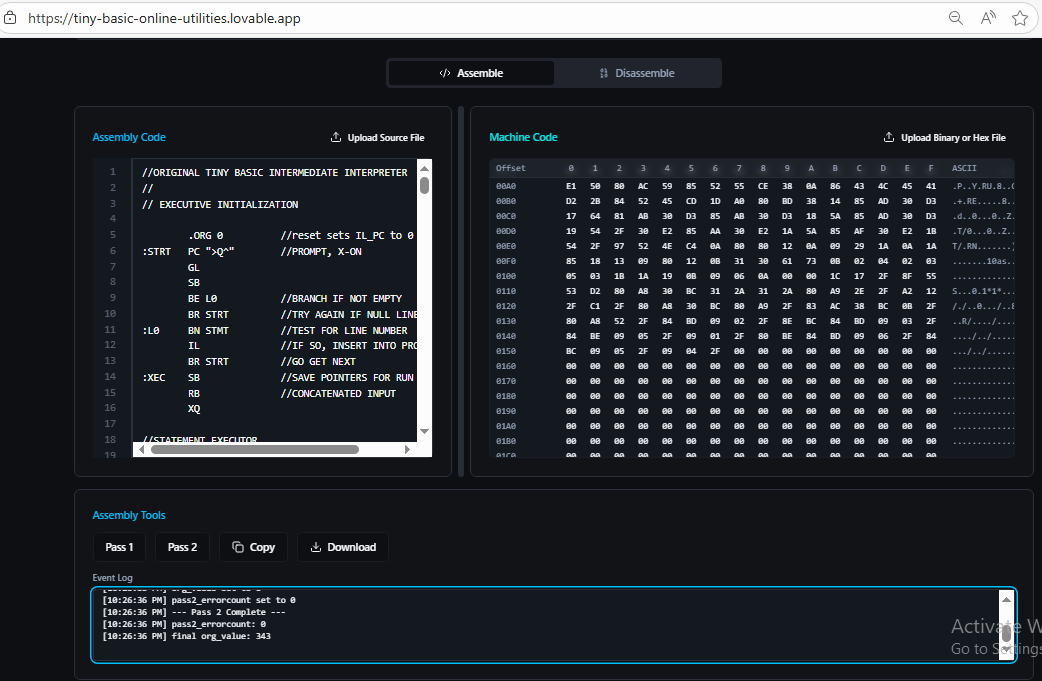
Vibe coding an assembler / disassembler
11/23/2025 at 06:30 • 0 commentsNote: the online utilities presented here are in progress, but the assembly part seems to be working, disassembler probably coming over the holidays, time permitting.
My goal is to extend the Tiny Basic somewhat, to make it a bit more powerful and/or align it with other Basic dialects. For example, this could mean addition of:
- FOR / NEXT loops
- INPUT statement with prompt
- multiple statements on a line (delimited by colon)
- support for DATA / READ / RESTORE
- parsing of integers in hex and/or binary format
- possibly others...
for all of the above - beside microcode changes - I also need to modify the interpreter itself, which is written in TBIL. To do that, obviously a TBIL assembler is needed. For this part of the project, to jump 50 years from 1976 (when Tiny Basic was introduced) to 2026 (almost there!) I decided to use some AI vibe coding. There are many such platforms, I am most familiar with Lovable. I created an online assembler / disassembler tool which allows TBIL source code to be assembled (2 pass) into binary / hex / vhdl file I could use to provide as code to the Basic CPU.
![]()
Steps to try out the assembler:
- Navigate to online app
- Download the original version of interpreter
- Modify the interpreter, syntax is pretty obvious (only change from documented interpreter is that I use comma between branch target and "text" strings)
- Copy and/or upload the *.tba file using the "Upload source..." button
- Click Pass 1 button (observe if there are any errors)
- If no errors, click Pass 2 button (observe the action log)
- Binary code in hex format should appear in .... Switch to "Disassembly" mode to reveal the download options in .hex, .bin or .vhdl formats
The source code of the app is here. All changes have been done by lovable dev bot, purely through "vibe coding". I did a similar vibe coding online tool about 6 months ago and I see certain improvements. At that time, often after changes there would be a build break. When I developed this new app, there was no build break at all.
Vibe coding is still just .. coding
What this means is that all the good coding advices still apply. Most notably, everything about planning and designing the app before writing the actual code. In this case the UX of the app is rather boilerplate, using a one-page layout with standard controls such as editable text boxes, file upload / download, resizable panels, buttons etc. The AI tool shines with this part (although the code it produces is still bloated and slow, requires targeted prompting to refactor it into a leaner implementation), but where it obviously needs serious prompting is the business logic. After all, there is no proliferation of TBIL assemblers from 40+ years ago it can learn from :-) I put effort to explain exactly what needs to be done for each line of source code in both pass1 and pass2 of the assembler. I also included some links for context. Therefore, when I asked it to implement assembly pass 1 and 2 it was "on rails" and fairly successful, with only minor tweaks needed.
The original text of the instructions I provided ("knowledge" in Lovable parlance) is below. I also asked it to extract it as markdown document file and check it in. I organized the "knowledge" into:
- Links for more context (targeted sources as generic "Tiny Basic" would completely confuse it)
- Concepts. Each concept is as clearly defined as possible and includes "action" when applicable (what to do when concept is encountered)
- Steps for pass 1, organized by assembly instruction
- Steps for pass 2, organized by assembly instruction
http://www.ittybittycomputers.com/IttyBitty/TinyBasic/TBEK.txt https://hackaday.io/project/204482-celebrating-50-years-of-tiny-basic http://www.ittybittycomputers.com/IttyBitty/TinyBasic/ DEFINITIONS USED FOR ASSEMBLY PASS1 AND PASS2: octaldigit octaldigit is single digit in range 0 to 7 (inclusive). Represents values 0 to 7 constant constant is decimal, hex (prefixed 0X, valid digits are decimal and A, B, C, D, E, D), or binary (prefixed by 0B, valid digits are 0, 1) integer. If any of these are prefixed by '-' (minus sign) then value is 0-constant (evaluate as 2's complement integers) expression expression is a string of one or more constants with operators + - * / (integer division) % (integer modulo) between them. Action when encountered: expression_value is evaluated by parsing the expression using common operation precedence which can be changed using parenthesis ( and ). If expression_value cannot be evaluated log error and stop processing. "text" or 'text' text is any number of characters (each character is 8-bit US ASCII) between single or double quotes. Empty text (nothing between the quotes) is not allowed and if detected generates error. Action when text is detected: text_transformed string is generated from text using following rules: last character in text is copied over by adding 128 to its ASCII code if character sequence ^^ is detected, only single ^ is copied over to text_transformed if character sequence A^ to Z^ is detected then single character is copied to text_transformed which equals ASCII code of upper case character minus 64 (so M^ is copied over as value 13) otherwise each character is copied from text to text_transformed, verbatim without changing the case length of text_transformed is count of characters, which is always >0 and equals the number of bytes to represent the string in standard 8-bit ASCII :label label is string that must start with : (colon) and contain up to 8 alphanumeric characters or _. Label cannot stand by itself on the line. Label cannot start with _ or number after the colon. Label must be at the beginning of the line to be valid, or not be present on the line at all. Action when valid label is encountered: label is upper-cased label_dictionary is checked if key with value of the label exists, if yes log error and stop processing label is added to label_dictionary as key (without the : character), and the value is a structure that contains line_number and org_value //comment comment is any string that starts with two consecutive / characters. Action on comment: when encountered, comment is removed or ignored starting with first / onwards to the end of string or line, and processing continues on the remaining string. target target must be a valid key in the label_dictionary, otherwise error is reported and processing stops. Action when target is detected: target_value is assigned to be equal to org_value stored in the label_dictionary entry under the target key. target_value is then checked to be in range 0 to 2047 (inclusive), otherwise log error and stop processing. relativebranch relativebranch must be a valid key in the label dictionary, or character * (asterisk). If relativebranch is * character then the relativebranch_value is 0. If relativebranch is a label, then there are 2 cases: if org value of label is >= org value then relativebranch_value = org value of the label - current org value + 31. if org value label is <= org value then relativebranch_value = org value of the label - current org value + 31 In all cases if relativebranch_value > 63 or less than 0 then log error and stop processing. forwardbranch forwardbranch must be a valid key in the label dictionary, or character * (asterisk). If forwardbranch is * character then the forwardbranch_value is 0. If forwardbranch is a label, then the forwardbranch_value equals org_value of the label - current org_value - 1. If forward_branch value is >31 then log error and stop processing. LSB(value) returns (value AND 0xFF) AND is a logical AND operation, check resulting value to be in range 0 to 255, if not log error and stop processing MSB(value) returns (value AND 0xFF00) / 256 AND is a logical AND operation, check resulting value to be in range 0 to 255, if not log error and stop processing PROCESSING OF EACH LINE WHEN EXECUTING ASSEMBLY PASS1: copy current line (from loaded assembly file) to lineString remove comment from lineString (see definition of comment) remove leading and trailing blanks (space and tabs) from lineString convert lineString to upper case except anything under single or double quotes (see definition of "text" and 'text') if lineString is empty, stop processing if lineString contains label, process label, remove label from lineString validate that lineString is not empty, if it is the log error in activity log Recognize following content in the lineString (UPPERCASE with optional parameters), action to take is below each. If the content does not match any of the below, log error in activity log with line number. .ORG expression org_value = expression_value. If the new org_value is less than previous, log error and stop processing SX octaldigit org_value = org_value + 1 NO org_value = org_value + 1 LB expression org_value = org_value + 2 LN expression org_value = org_value + 3 DS org_value = org_value + 1 SP org_value = org_value + 1 SB org_value = org_value + 1 RB org_value = org_value + 1 FV org_value = org_value + 1 SV org_value = org_value + 1 GS org_value = org_value + 1 RS org_value = org_value + 1 GO org_value = org_value + 1 NE org_value = org_value + 1 AD org_value = org_value + 1 SU org_value = org_value + 1 MP org_value = org_value + 1 DV org_value = org_value + 1 CP org_value = org_value + 1 NX org_value = org_value + 1 LS org_value = org_value + 1 PN org_value = org_value + 1 PQ org_value = org_value + 1 PT org_value = org_value + 1 NL org_value = org_value + 1 PC "text" org_value = org_value + 1+ lengthOf(text_transformed) GL org_value = org_value + 1 IL org_value = org_value + 1 MT org_value = org_value + 1 XQ org_value = org_value + 1 WS org_value = org_value + 1 US org_value = org_value + 1 RT org_value = org_value + 1 JS target org_value = org_value + 2 J target org_value = org_value + 2 BR relativebranch org_value = org_value + 1 BC forwardbranch, "text" org_value = org_value + 1 + lengthOf(text_transformed) BV forwardbranch org_value = org_value + 1 BN forwardbranch org_value = org_value + 1 BE forwardbranch org_value = org_value + 1 FS org_value = org_value + 1 FE org_value = org_value + 1 PROCESSING OF EACH LINE WHEN EXECUTING ASSEMBLY PASS2: copy current line (from loaded assembly file) to lineString remove comment from lineString (see definition of comment) remove leading and trailing blanks (space and tabs) from lineString convert lineString to upper case except anything under single or double quotes (see definition of "text" and 'text') if lineString is empty, stop processing if lineString contains label, check that label exists as key in the label_dictionary (created in pass1). If not, log error and stop processing validate that lineString is not empty, if it is the log error in activity log Recognize following content in the lineString (UPPERCASE with optional parameters), action to take is below each. If the content does not match any of the below, log error in activity log with line number. Every instruction below writes 1 or more consecutive bytes to "machine code" binary array. .ORG expression org_value = expression_value. If the new org_value is less than previous, log error and stop processing Machine code not changed SX octaldigit Write byte (0x00+octalDigit) to machine code at org_value, increment org_value NO Write byte 0x08 to machine code at org_value, increment org_value LB expression Write byte 0x09 to machine code at org_value, increment org_value Write byte LSB(expression_value) to machine code at org_value, increment org_value LN expression Write byte 0x0A to machine code at org_value, increment org_value Write byte MSB(expression_value) to machine code at org_value, increment org_value Write byte LSB(expression_value) to machine code at org_value, increment org_value DS Write byte 0x0B to machine code at org_value, increment org_value SP Write byte 0x0C to machine code at org_value, increment org_value SB Write byte 0x10 to machine code at org_value, increment org_value RB Write byte 0x11 to machine code at org_value, increment org_value FV Write byte 0x12 to machine code at org_value, increment org_value SV Write byte 0x13 to machine code at org_value, increment org_value GS Write byte 0x14 to machine code at org_value, increment org_value RS Write byte 0x15 to machine code at org_value, increment org_value GO Write byte 0x16 to machine code at org_value, increment org_value NE Write byte 0x17 to machine code at org_value, increment org_value AD Write byte 0x18 to machine code at org_value, increment org_value SU Write byte 0x19 to machine code at org_value, increment org_value MP Write byte 0x1A to machine code at org_value, increment org_value DV Write byte 0x1B to machine code at org_value, increment org_value CP Write byte 0x1C to machine code at org_value, increment org_value NX Write byte 0x1D to machine code at org_value, increment org_value LS Write byte 0x1F to machine code at org_value, increment org_value PN Write byte 0x20 to machine code at org_value, increment org_value PQ Write byte 0x21 to machine code at org_value, increment org_value PT Write byte 0x22 to machine code at org_value, increment org_value NL Write byte 0x23 to machine code at org_value, increment org_value PC "text" Write byte 0x24 to machine code at org_value, increment org_value Write every byte of text_transformed starting with position 0, increment org_value after each write GL Write byte 0x27 to machine code at org_value, increment org_value IL Write byte 0x2A to machine code at org_value, increment org_value MT Write byte 0x2B to machine code at org_value, increment org_value XQ Write byte 0x2C to machine code at org_value, increment org_value WS Write byte 0x2D to machine code at org_value, increment org_value US Write byte 0x2E to machine code at org_value, increment org_value RT Write byte 0x2F to machine code at org_value, increment org_value JS target Write byte (0x30 + (0x07 AND MSB(target_value)) to machine code at org_value, increment org_value Write byte LSB(target_value) to machine code at org_value, increment org_value J target Write byte (0x38 + (0x07 AND MSB(target_value)) to machine code at org_value, increment org_value Write byte LSB(target_value) to machine code at org_value, increment org_value BR relativebranch Write byte (0x40 + (0x3F AND LSB(relativebranch_value)) to machine code at org_value, increment org_value BC forwardbranch, "text" Write byte (0x80 + (0x1F AND LSB(forwardbranch_value)) to machine code at org_value, increment org_value Write every byte of text_transformed starting with position 0, increment org_value after each write BV forwardbranch Write byte (0xA0 + (0x1F AND LSB(forwardbranch_value)) to machine code at org_value, increment org_value BN forwardbranch Write byte (0xC0 + (0x1F AND LSB(forwardbranch_value)) to machine code at org_value, increment org_value BE forwardbranch Write byte (0xE0 + (0x1F AND LSB(forwardbranch_value)) to machine code at org_value, increment org_value FS Write byte 0x25 to machine code at org_value, increment org_value FE Write byte 0x26 to machine code at org_value, increment org_valueNote that FS and FE are "extended" instructions, not present in original TBIL, but I needed them to implement FOR/NEXT loop in extended version. Out of total of 256 op-codes 248 are used in original TBIL (very high % of utilization!), 250 in extended, leaving 6 free. Out of these 6, 5 could be used for implementing additional statements, but 1 should be left as an "prefix", to allow 2 byte op-codes, similar to Z80.
-
"Hello World!" demo
11/18/2025 at 18:38 • 0 commentsWhat would a CPU project be without a "Hello World" demo? :-)
I originally introduced VGA display as a debugging tool to visualize content of Basic input line and program (esp. GL and IL instructions), as described here. But once display surface exists, why not use it as simple text-based screen output?
Tiny Basic system currently implements 2k RAM mapped to address space 0x0000 to 0x07FF. If the program is shorter than that, whatever remains can be used as "window" for example 8*64 in size, starting at RAM location 0x0600 or 1536 decimal.
![]()
For the demo to work, 2 additional capabilities were needed:
- Ability to access Basic RAM (classic PEEK and POKE)
- Ability to read the font definition for the characters in the scroll, and "magnify" them by 8X so that 8*8 pixel becomes 8*8 character.
Memory mapping
Total Basic memory space is 64k, leaving 62k open in the system. I used the top 4k to access same character generator ROM VGA controller uses (two copies of this ROM are now in the design). This char gen has 8*8 font similar to C64, but I also added representation of control characters 0x00-0x1F which help with debugging (note CR in memory display above after each Basic statement). From the outside, the char gen appears to hold 256 characters, but the capacity is only 1k, ASCII codes 0x80..0xFF are inverse duplicates of 0x00..0x7F.
sel_hi4k <= '1' when (A(15 downto 12) = X"F") else '0'; memData <= pattern when (sel_hi4k = '1') else ram(to_integer(unsigned(A(10 downto 0)))); D <= memData when ((nBUSACK or nRD) = '0') else "ZZZZZZZZ"; -- Character generator ROM handy for the marquee demo chargen: entity work.chargen_rom port map ( a => A(10 downto 0), -- 256 chars (128 duplicated, upper 128 reversed) * 8 bytes per char pattern => pattern );USR() function
The original Tiny Basic ran on a number of microprocessors from 1970ies/80ies. To allow extensibility, each implementation of TBIL interpreter was supposed to define and implement the r = USR(a, p1, p2) call from Tiny Basic, where:
- a - address of the native (assembler / machine code) routine to call
- p1 - required parameter
- p2 - optional parameter
- r - result
All of the above were 16-bit values. For example:
argument \ CPU 6502 6800 1802 a JSR a JSR a R3=a, P=3, X=2 p1 MSB=X, LSB=Y (to be verified!) X (16-bit) R8 p2 A A RA r MSB=A, LSB=Y, RTS to return A, RTS to return MSB=RA.1, LSB=D, SEP 5 to return At minimum, implementing PEEK / POKE was expected, but any other (such as direct reading of keyboard etc.) was possible. Only option for Basic CPU was to implement in microcode some of the most useful USR calls, and these are also used in the Scroll demo Basic program.
Currently implemented:
Function a p1 p2 r used in demo? Logical 0 .. 7 16-bit word 16-bit word p1 op p2 a = 3, which is logic AND operation PEEK8 20 address of byte to update N/A M[a] yes PEEK16 21 address of word (on any byte boundary) N/A 256*M[a]+M[a+1] no POKE8 24 address of byte 8-bit value to write to memory addressed by a (upper 8-bit of the value is ignored) p2 yes POKE16 25 address of word (on any byte boundary) 16-bit value to be written to a in big endian representation p2 no To save on the "switch" statement that would take precious microcode, all binary logic operations are implemented with the same expression, controlled by 3 lowest bits of parameter a.
(omitted) when T_binop => -- S operation -- 0 T NOR R -- 1 T NOR /R -- 2 /T NOR R -- 3 T AND R -- 4 T OR S -- 5 T OR /S -- 6 /T OR S -- 7 T NAND R T <= S2 xor ((S1 xor T) nor (S0 xor R)); (omitted) -- masks for T_binop S0 <= (others => S(0)); S1 <= (others => S(1)); S2 <= (others => S(2)); -
Chasing performance
11/17/2025 at 06:21 • 0 commentsI was really curious how the Basic CPU will perform in comparison with classic CPUs of the home computer era and put some effort into optimizing the design with that goal in mind. Based on the benchmark tests, the goal has been only partially achieved. While in some cases the speed up of factor 4 to 8 looks noteworthy, my suspicion is that those Basic interpreters by default work with software - implemented floating point for the benchmark test (haven't explored them in depth), while other group showing more modest gain of 1.5 to 2X are "integer Basic" implementations, and a more fair comparison.
CPU performance optimizations I used:
Clock frequency
A bit of "cheating" going on here - whole design is inside the FPGA which allows it to work at maximum available hardware clock frequency of 100MHz. Most importantly, the "core" RAM (Basic input buffer and program store) can be accessed in 1 or 2 clock cycles (so 10 or 20ns):
writeCore: nWR = 0, if nBUSACK then repeat else return; readCore: nRD = 0, if nBUSACK then repeat else next; nRD = 0, MDR <= from_Bus, back;This would clearly be impossible if the RAM is outside of the FPGA, even on the same board. Depending on the CPU clock and memory speed, one or more wait cycles would need to be added. Anvyl board has a breadboard section, so in future I may move the Basic core memory to a 62256 type device and experiment for example how many wait cycles does a 70ns vs. 120ns memory chip need.
Other limiting factor is I/O speed. Currently, max I/O serial speed is 38400 bps. Sending and receiving 1 byte over such channels takes at least 10-bit times, during which CPU has to wait for the ready signal.
outChar: if CHAROUT_READY then next else repeat; // sync with baudrate clock if CHAROUT_READY then return else repeat;FIFO queue on both input and output would help, but their implementation belongs to the Ser2Par and Par2Ser components, not the CPU (except for the trace serial output, but that one is only active up to 4kHz CPU frequency so not much gained there).
Cycle overlap
Basic CPU is a CISC processor, and pipelining is not traditionally their strength. However a very limited opportunity of overlap is used between execute and fetch in few instructions. Note that the fetch cycle has two entry points:
fetch: traceString 51; // CR, LF, then trace Basic line number (in hex, for speed) fetch1: traceString 2; // trace IL_PC and future opcode IL_OP <= from_interpreter, IL_PC <= inc, traceSDepth; // load opcode, advance IL_PC, indent by stack depth IL code if tracing is on T <= zero, alu <= reset0, if IL_A_VALID then fork else INTERNAL_ERR; // jump to entry point implementing the opcode (or break if we went into the weeds)Most instructions finish their execute cycle and then branch back to "fetch" (no overlap). Few have the opportunity to execute "traceString 51" operation while in parallel doing other operations, and when done can branch to "fetch1" - this is a 1 clock cycle overlap. This could be utilized more, but tracing at the beginning of fetch cycle is very convenient debug tool, so this was an engineering compromise between 2 important goals (troubleshooting and performance).
//////////////////////////////////////////////////////////////////////////////// .map 0x12; // FV (Fetch Variable) //////////////////////////////////////////////////////////////////////////////// traceString 36; // trace mnemonic Vars <= indexFromExpStack, if STACK_IS_EMPTY then ESTACK_ERR; // get index (variable name A-Z) T <= from_vars, ExpStack <= pop1, traceString 51; // T <= Vars(index) ExpStack <= push_TWord, goto fetch1; // push onto stack, go to 2rd fetch entry point as we overlapped 1 cycleParallel operations
Basic CPU uses "horizontal microcode" with fairly wide control word of 80 bits:
- Microprogram execution control: 5 bits to select 32 conditions, 9 bits to branch to "THEN" case, 9 bits for "ELSE" - total of 23 bits, conceptually 1 field
- "direct fields" that provide immediate data for the microinstruction being executed: 11 bits, 5 independent fields
- "register fields" define the transfer of data into the registers at the end of current microinstruction - 46 bits in 22 fields
In theory, all 28 fields could independently specify an operation in parallel, so that all components within the CPU work in parallel. Obviously, Basic CPU is far from this ideal goal. Execution control is by definition engaged in every microcycle, but in average only 1 or two others. One of the better ones is this one:
directByte = ' ', writeCore(InlEnd, from_microcode), InlEnd <= inc;Following operations are being executed in same clock cycle:
- MAR register is loaded with value from InlEnd register
- MDR register is loaded with immediate value carried in the directByte field
- InlEnd register is incremented
- Microprogram counter is loaded with the address of "writeCore" routine, while the return stack pointed by microprogram stack pointer is loaded with current address + 1 (subroutine call can be done in 1 clock cycle due to design of the control unit)
4 operations, far cry from the 20+ possible. Interestingly, the MCC compiler could easily provide static microcode effectiveness analysis by counting the average parallelization (not currently implemented). Even better would be during runtime, when microinstructions executed more would carry more weight in the metric.
Algorithm optimizations
Copying 1 byte in the core memory takes 5 clock cycles:
//--- copy Y bytes in Core memory from S to R --- copyCore: T <= from_S, if Y_ZERO then return; // bail if no bytes left to copy readCore(T); T <= from_R; writeCore(T, same); //traceALU(); alu <= copy_next, goto copyCore; // Y--, R and S incremented / decremented based on directionIt is easy to see how this could be collapsed to 3: allow the MAR register to be loaded directly from S and R registers, instead of going through T. Turns out this optimization would be costly (addition of 1 control bit to the microcode control word width) and also not necessary: memory copy is only used when inserting lines into the program, which happens in command mode (usually human interaction) and would not speed up the Basic program.
However there are some other places that impact execution speed and I tried to optimize them:
- Signed division: 18 cycles typically (set up, 16 iterations, sign correction)
- Binary to BCD conversion: 1 + 16 max (set up, up to 16 iterations but bail when only zeros remain in the source binary number)
- Signed multiplication: 1 cycle (using the combinatorial multiplier in the FPGA)
- Other arithmetic operations: 1 cycle
(actual instruction times are longer due to stack push / pop overhead, tracing etc.)
GOTO cache
This component is the single most significant perf accelerator. Depending on structure of the program, up to 2-3X faster runs with GOTO cache on. The reason is easy to see. Structure of Basic program is as follows:
- 0 to n (limited by core memory size) lines / statements:
Line number statement text, ASCII as entered 0x0D 2 bytes, 1 word in big endian format n bytes 1 byte - 2 consecutive bytes of 0x00 (or one word with value 0)
In order to execute GOTO / GOSUB, whole memory must be searched from beginning, first reading and checking the word (for target number match), then all bytes following until 0x0D (carriage return) and then continue until:
- found and execute the jump / subroutine call
- found line number 0 (end of program) - report an error
A simple 1-way, 32-entry direct-mapped cache allows avoiding this traversal and providing the address of the target statement start leading to a dramatic perf improvement.
![]()
How does it work:
- 32 bit cache_valid register is cleared when Basic program starts to run (condition detected by hardware by checking the before / after value of Lino (line number register). If it goes from 0 to !0, reset
- Target line number for a GOTO is pulled from stack and lands in Lino register
- Last 5 bits of Lino are used to look up the valid bit in cache_valid (simple 32 to 1 MUX) and the entry in the cache (address presented to 32-word cache memory). For example in case of GOTO 100, 5th bit and 5th entry in cache would be selected
- Each entry (frame) contains data and tag. Tag is compared with upper 11 bits of Lino (value of 0b11 in case of GOTO 100), and if same cache_hit condition arises. Following cases are possible:
- valid = 0, hit = 0: entry is free, microcode looks for statement 100 and if found stores BP (address found) and upper 11 bits of Lino into the entry. cache_valid bit is flipped to 1. We pay the price of search for statement 100 now but not again (compulsory cache miss)
- valid = 0, hit = 1: same as above, there was junk data from previous Basic program run
- valid = 1, hit = 0: this entry has already been occupied by some other GOTO. For example in simple cache like this (no associativity, no purge) if GOTO 900 were executed first, it would take the entry and sit there until end of program (conflict miss)
- valid = 1, hit = 1: skip looking for beginning of statement 100, load BP with cache data (cache hit)
Microcode needs to just examine these two conditions and take proper path:
//////////////////////////////////////////////////////////////////////////////// .map 0x16; // GO (GOTO) //////////////////////////////////////////////////////////////////////////////// traceString 45; // Trace mnemonic IL_PC <= XQhere, if STACK_IS_EMPTY then ESTACK_ERR; // IL_PC <= XQhere, check stack alu <= R_fromStack, ExpStack <= pop2; T <= from_R; Lino <= T, if R_IS_ZERO then NOPROG_ERR; // once Lino is set, CACHE_HIT and CACHE_VALID are meaningful // traceLino; if CACHE_VALID then go_cvalid; // INVALID: the cache entry is free, find target and store in cache (and stay there until end of run) findLino(Prog_start); alu <= cache_store, goto fetch; // cache[Lino(4:0)] <= Lino & BP, cache_valid[Lino(4:0)] <= 1 go_cvalid: T <= Cache_Data, if CACHE_HIT then next else go_cmiss; // VALID HIT: pick it up and use it BP <= T, goto fetch; // VALID MISS: other GOTO already used the entry, no attempt to kick it out, take the perf penalty go_cmiss: findLino(Prog_start); goto fetch;Given the impact of cache on performance, I may in future improve the cache by implementing some of the well-known cache design choices:
- Add associativity (simply the entry for GOTO 100 can go to 2, maybe 4 slots instead of 1)
- Add purge policy (each entry has some time to live, or miss count after which it gets replaced - imagine GOTO 100 taking the entry first, but then later GOTO 900 is executed in a loop thousand times - it would be beneficial for address of 900 be stored in the cache)
- Possibly split GOTO and GOSUB caches - simplest but provides benefit only for programs with subroutines
- Any combination of the above
Implementing proper cache would require measuring hits/misses during runs of various benchmark programs. Implementing such hardware is easy but devising and running such programs isn't. Right now, I am happy with 3 blinkenlights:
- cache empty - green LED
- cache not empty - yellow LED
- cache full - red LED
-- GOTO cache cache_empty <= '1' when (cache_valid = X"00000000") else '0'; -- all 32 entries free cache_full <= '1' when (cache_valid = X"FFFFFFFF") else '0'; -- all 32 entries used cache_entry <= cache(to_integer(unsigned(Lino_index))); -- data/tag cache entry pointed to by Lino cache_hit <= '1' when (cache_tag = Lino_tag) else '0'; -
Debugging
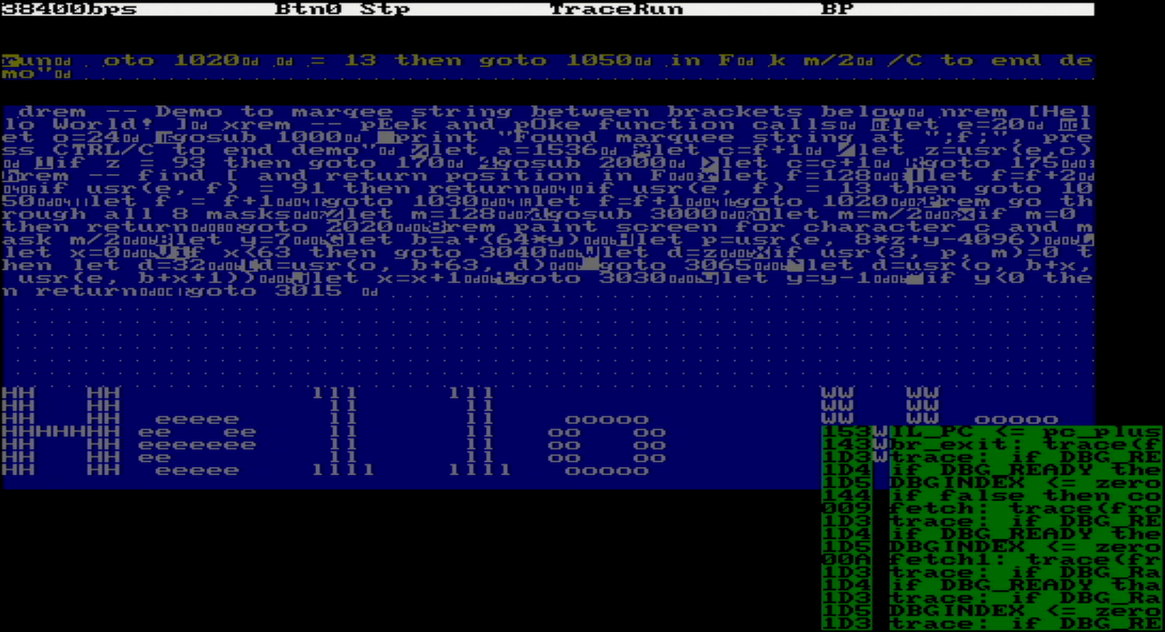
11/14/2025 at 02:46 • 0 commentsComplex programmable logic designs are opaque. Unless this opaqueness is turned into transparency, the design and the whole project will fail. I use mainly two methods to peek into the (quite literally) little black box of FPGA:
- Create generic components and test them in separately or inherit them from projects in which their already worked. Examples in this project that I reused (with some modifications):
- Microcode control unit
- Binary to BCD converter
- 7-seg LED display unit
- Serial to parallel and parallel to serial components
- VGA controller
- Button / switch debouncer(s)
- Build into the project itself as many as possible debug features, starting with simpler (LEDs, buttons) towards more complex (serial debug, VGA) as the project progresses
component \ visualization LEDs, 7-seg LEDs Serial output VGA serial to parallel input LEDs Echo of input buffer during GL Input buffer hardware window CPU register T traceT(); microcode subroutine Displayed using block cursor at the locations it points to CPU registers BP, LS, LE, PrgEnd 7-seg LEDs traceBP(); Underline cursor shown at location pointed by register ALU registers - traceALU(); - CPU return stack - displayed as indentation of each IL operation - Microcode execution (program counter can be displayed) - Hardware window, using symbols from symbols ROM produced by microcode compiler IL execution - Each IL instruction traced with mnemonic and parameters - Command line - - Hardware window Basic program - - Hardware window GOTO cache Only empty/used/full state on LEDs - - Armed with the above, I was able to visualize and debug the 3 layers of code:
- Microcode executes TBIL instructions
- TBIL instructions execute Basic interpreter
- Basic interpreter executes user's Basic program
Two components important for debugging merit some discussion as they are useful and generic enough for other programmable logic projects too:
Serial Tracer
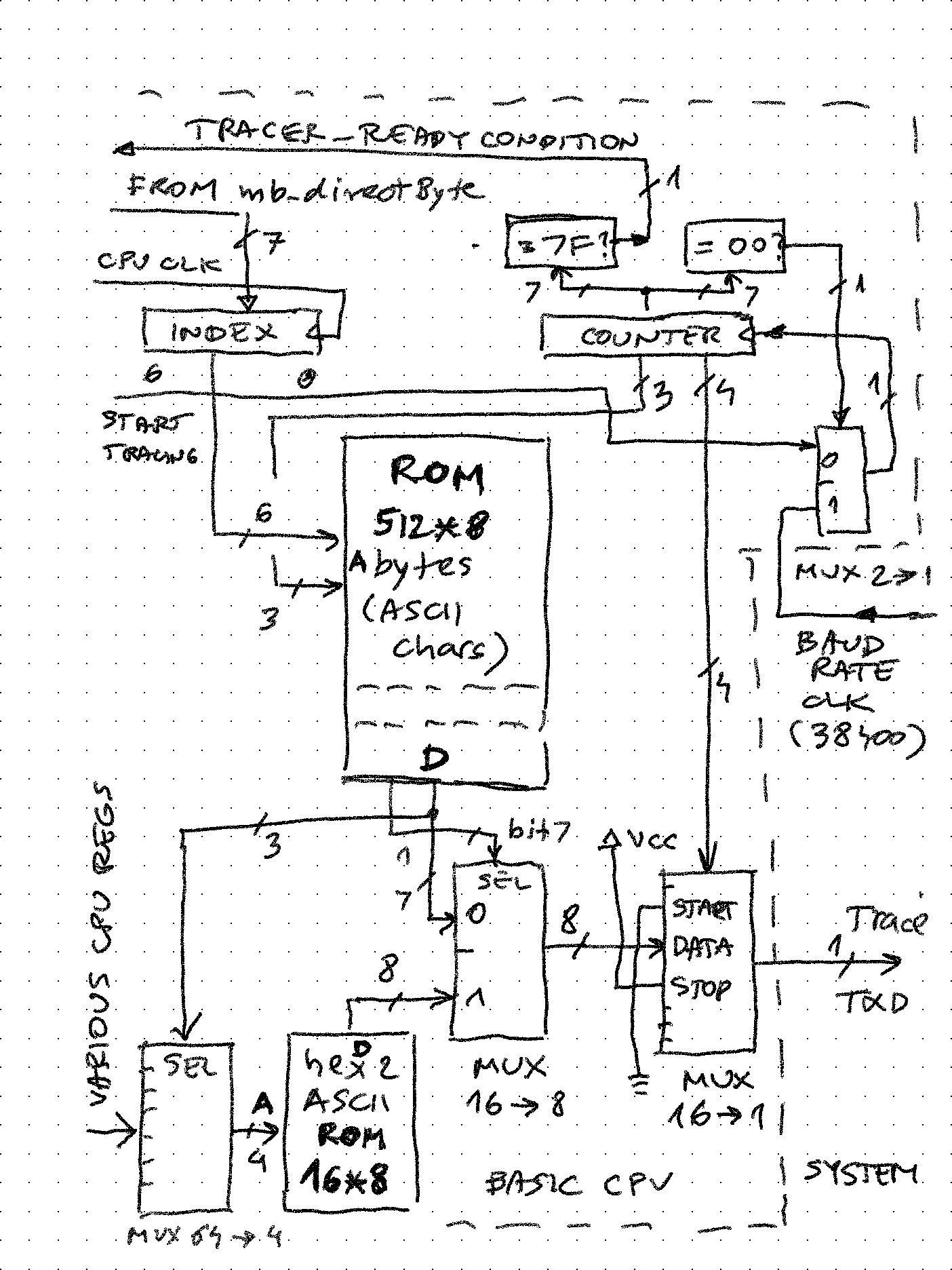
Basic CPU has an output - only serial port which outputs a constant stream of trace data, whenever microcode includes a call to the "traceString nn" subroutine. nn is a number from 0 to 63 (can be easily expanded to 127) which is an index into an 8-byte string which will be output on this port. While the trace output is ongoing, microcode execution is waiting for it to finish (good opportunity to add an outgoing FIFO here)
trace: if DBG_READY then next else repeat; // sync with baudrate clock that drives UART if DBG_READY then next else repeat; DBGINDEX <= zero, back; // clear the serial debug output register and return![]()
Central part is the 512 byte ROM organized as 64 entries of 8 ASCII characters. When desired entry number is stored into the index register, the 7-bit counter resets to 0 and starts counting up, driven by the baudrate clock. Lower 4 bits of this counter are connected to a 16 to 1 MUX. This MUX drives the serial output line, by selecting the start ("space"), data, and stop ("mark") bits. The upper 3 bits select 1 out of 8 characters in that ROM entry. For extra capability, if the character stored has bit 7 set, it doesn't go directly to output, but selects 1 out of 16 inputs that tap into various values in the Basic CPU. The 4-bit hex value is converted using a look-up table into ASCII, and it sent out to trace_txd output.
For example, entry #2 in the ROM is equivalent to C# "string.format()" such as $"{IL_PC:X3}: {IL_OP:X2}"
X"80", X"81", X"82", c(':'), c(' '), X"83", X"84", c(' '), -- aaa xx:Hardware window
The VGA controller generates a 640*480, 50Hz signal using 25MHz dot clock. The screen is divided into 80 columns and 60 rows, and these two values are fed into and consumed by "hardware window" components. They simply check if the current horizontal and vertical position of the screen pixel is inside their coordinates. If yes, they convert it to a memory address based on window size and memory base address. The resulting address is used to fetch ASCII char from memory and displayed (each window can have own background and foreground colors)
Here is the definition of input line and program code windows (note their base addresses):
inpwin: entity work.hwindow Generic map ( top => X"08", left => X"08", width => X"40", height => X"02" ) Port map ( enable => '1', x => x80, y => y60, m_base => X"0000", m_cursor => cpu_debug(15 downto 0), -- outputs char_addr => inp_addr, cursor_hit => inp_cursor, active => inp_active ); prgwin: entity work.hwindow Generic map ( top => X"0C", left => X"08", width => X"40", height => X"1E" ) Port map ( enable => '1', x => x80, y => y60, m_base => X"0080", m_cursor => cpu_debug(15 downto 0), -- outputs char_addr => prg_addr, cursor_hit => prg_cursor, active => prg_active );And how they look on VGA screen (this program is loaded into RAM, and "list 100,999" command is issued):
![]()
The "magic" here is the "active" output signals. Because these two windows share the same "core" memory, the active one decides which "char_addr" will drive the address MUX of that memory. It could be both (in case of overlapped windows), but same signals are also fed to an equivalent of a "74x148" priority encoder to arbitrate which window is top of view stack etc. This is all hardcoded now, but could be made programmable (essentially creating text based "sprites" that could be moved and resized on the screen)
- Create generic components and test them in separately or inherit them from projects in which their already worked. Examples in this project that I reused (with some modifications):
-
Lies, damn lies, and ... benchmarks!
11/13/2025 at 19:11 • 0 commentsCall to action: if you are reading this and have a working retro-computer with any CPU running Tiny Basic (esp. the version with TBIL) please run the same benchmark test and share the results here!
Update 2025-11-27
@msolajic also ran the benchmark on a computer very special and dear to all enthusiasts from ex-Yugoslavia: the Galaksija.
Update 2025-11-26
Running the benchmark in "extended" mode using FOR/NEXT loops improves performance about 3% but the data in tables below are for "original" version of the Tiny Basic interpreter.
Update 2025-11-23 / 27
@msolajic graciously ran the 1000-primes benchmark on some additional retro-computers. Here are the results and comparison with Basic CPU (see table at the bottom of this project log)
As soon as the CPU started semi-working, I set out to measure and improve the performance. To be precise, I added the elapsed run timer into the CPU. It is driven by 1kHz clock (so has 1ms resolution of "ticks"). It is started when Lino register (holding the line of executing statement) goes from 0 to != (program execution starts) and stops when it goes back to 0.
-- counting ticks (typically 1ms) while the program is running (to be displayed at the end of execution on_clk_tick: process(clk_tick, reset) begin if (reset = '1') then cnt_tick <= (others => '0'); cnt_tick1000 <= (others => '0'); lino_tick <= (others => '0'); else if (rising_edge(clk_tick)) then lino_tick <= Lino; if (is_runmode = '1') then if (lino_tick = X"0000") then -- going from stopped to running, reset counters cnt_tick <= (others => '0'); cnt_tick1000 <= (others => '0'); else -- when running, load increment counters if (cnt_tick = X"03E7") then -- wrap around at 1000 cnt_tick <= (others => '0'); cnt_tick1000 <= std_logic_vector(unsigned(cnt_tick1000) + 1); else cnt_tick <= std_logic_vector(unsigned(cnt_tick) + 1); end if; end if; end if; end if; end if; end process;At the end of program execution, the value of these 2 counters (seconds and milliseconds elapsed) is displayed:
![]()
For benchmark, I used the "find first 1000 primes" test which has the advantage of simplicity and portability. Because this version has no FOR/NEXT (I plan to implement it), the test had to slightly change and replace that with IF/GOTO.
There are two variations of the test code:
- Without GOSUB (proposed here, modified Basic program here)
- With GOSUB (proposed here, modified Basic program here) - not surprisingly, it is about 20% slower across all clock frequencies.
Below is the direct comparison with my previous Tiny Basic project. Meaningless (because it is different interpreter and CPU) but still fun:
Clock frequency 25MHz 25MHz Acceleration Serial I/O 38400 baud, 8N1 38400 baud, 8N1 1 CPU Am9080 (implemented using Am2901 bit slices) Basic CPU N/A Tiny Basic version Native assembler interpreter Intermediate language based N/A Run time (s) 197 36.58 5.32 Going back to the original article from 1980, I attempted to compare by reducing the Basic CPU clock speed to be same as those systems.
Clock (MHz) CPU Basic version Run time (s) Basic CPU run time (s) Acceleration 1 6502 Level I Basic 1346 906 1.48 2 6502 Level I Basic 680 453 1.50 2 6502 Applesoft II Basic 960 453 2.12 2 Z80 Level II Basic 1928 453 4.26 2.4576 80C85 Microsoft Basic (Tandy 102) 2080 366 5.68 3 8085 StarDOS Basic 1438 302 4.76 3 9900 Super Basic 3.0 585 302 1.94 4 Z80 Zilog Basic 1864 227 8.21 4 Z80 Level III Basic 955 227 4.20 5 8086 Business Basic 1020 182 5.60 6 4*Am2901 HBASIC+ 143 152 0.94 As can be seen, Basic CPU is faster than all compared systems, except AMD's own HEX-29 system / CPU which was a showcase of their own bit-slice technology. Interestingly, it is also controlled by similar "horizontal" micro-code just like the Basic CPU. This CPU has been described in the classic "Bit-slice Microprocessor Design" book.
Update 2025-11-20: with some tweaks in microcode, I improved the perf numbers above by about 1-2%. More info about perf here.
Clock CPU Basic version Run time (s) Basic CPU run time (s) Acceleration 1MHz 6510 Commodore Basic (C64) 1086 906 1.2 3.072MHz Z80 Galaksija Basic (Galaksija, video generation off) 2700 293 9.2 3.5MHz Z80 Sinclair Basic (ZX Spectrum) 1536 253 6.07 7.328MHz Z80 Microsoft ROM Basic V4.7B (Grant Searle Z80 SBC) 349 172 2.02 6.144MHz (0 wait state DRAM) HD64180 Basic-80 V5.22 (TIM-011B) 446 147 3.03 6.144MHz (1 wait state DRAM) HD64180 Basic-80 V5.22 (TIM-011B) 506 147 3.44 18.432MHz Z8S180 Basic-80 V5.21 (S131 SBC) 146 107 1.36 18.432MHz Z8S180 Microsoft ROM Basic V4.7B (S131 SBC) 139 107 1.30
CPU running Basic
Celebrating 50 years of Tiny Basic by implementing a custom micro-coded 16/32-bit CPU that executes it directly (up to 100MHz)